

Fleet
More Than a Code Editor
Fleet Below Deck, Part IV – Distributed Transactions

This is a multipart series on building Fleet, a next-generation IDE by JetBrains.
- Part I – Architecture Overview
- Part II – Breaking Down the Editor
- Part III – State Management
- Part IV – Distributed Transactions
- Part V – The Story of Code Completion
- Part VI – UI with Noria
In Part III of this series, we focused on how we represent, store, and change elements of Fleet’s state. In this part, we’ll talk about Fleet as a distributed IDE and how it guarantees the consistency of data across all of its distributed components.
Fleet is a platform for real-time remote collaboration between developers. This is an exciting area of technology! Let’s start by discussing issues we could face while working in a distributed environment.
Issues with distributed operations
Imagine we have two users, user A and user B. They are both working with the same document in Fleet, but on different machines. Using network channels introduces random delays – each user receives information about the other user’s activities at different times. How should Fleet handle that?
To illustrate how Fleet works in a distributed environment, we’ll use several simplified sample scenarios:
- Scenario 1: User A renames a file via Fleet’s interface. User B’s UI is updated.
- Scenario 2: User A renames a file via Fleet’s interface. At the same time, user B appends a word to the document. Both UIs are updated.
- Scenario 3: User A opens a parenthesis in a function call, then invokes Fleet’s command to balance parentheses. At the same time user B removes the opening parenthesis. There are no more parenthesis to balance! Who is going to win the race?
After reading about state management in Fleet, we know that all the scenarios above boil down to changing Fleet’s state. Fleet updates values of the attributes for the corresponding entities and provides a new state snapshot. All of the UI elements are then updated with the new values.
If we look a little further, all user actions in these scenarios are compiled into sequences of instructions. Instructions may be as simple as adding or removing a value. They can also work on the attributes or the whole entities. It’s these sequences of instructions that travel across the network to other Fleet instances.
Fleet executes instructions in transactions (to provide atomicity, consistency, isolation, and durability) and provides new state snapshots as a result. We also know that Fleet records the novelty of the change for every transaction (sets of additions and removals of datoms) and uses read-tracking and query reactivity to update affected UI elements.
Putting this into the context of our scenarios, for Scenario 1, Fleet could have an instruction for renaming a file. If user A renames a file via the Files view, this instruction is executed and changes the file address for the opened file document (changing the corresponding attribute’s value):
- [18 :fileAddress "~/file.kt"] + [18 :fileAddress "~/newFile.kt"]
It also results in changing the document tab name (updating the UI element). The same instruction should be executed for user B, updating UI elements on user B’s machine.
In Scenario 2, in addition to the action above, user B’s Fleet instance executes an instruction resulting in the following change:
- [19 :text ""] + [19 :text "hello"]
We expect the final content of “hello” and the renamed file in both Fleet’s instances.
As for Scenario 3, the situation is a bit different. Suppose both users start with text “val x = f(“. Executing a parenthesis-balancing command by user A could result in the following changes:
- [19 :text "val x = f("]
+ [19 :text "val x = f()"]
If user B removes the opening parenthesis, we observe the following:
- [19 :text "val x = f("]
+ [19 :text "val x = f"]
If we execute the parenthesis-balancing instruction now, from the new initial state, there should be no changes at all. Depending on the actual timing of user A’s and user B’s editing actions, and given random networking delays, we can get different final results. Understanding how Fleet’s machinery works below deck is essential to understand what’s going on here.
A note on a distributed state
Until now, we have assumed that we have only one state. We mentioned in the previous part that there is one Kernel, a component responsible for transitions between state snapshots and providing a reference to the most recent one. In fact, Fleet is distributed, meaning there are many states and kernels. Every frontend component has its own state and its own kernel. Part of their states are local, but there’s also a shared state that is managed by Workspace (see Part I for an overview). Workspace has its own kernel too. The main goal of the Workspace’s kernel is to synchronize the state between all the frontends.
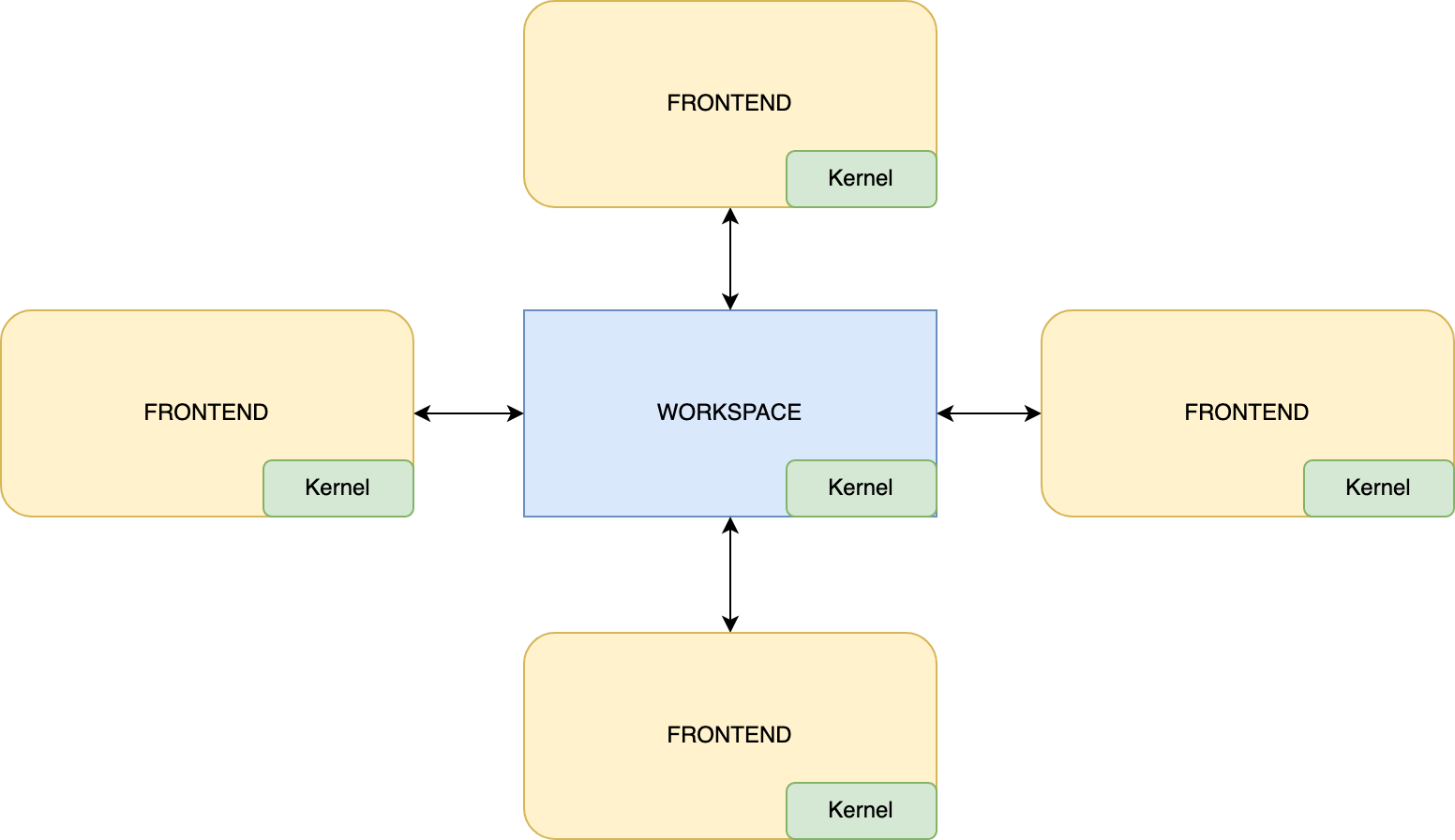
The Workspace may run on one of the developers’ machines or somewhere in the cloud. This makes our state distributed, and creates a lot of complications, including needing to synchronize the state over the internet. The good news is that the absence of reader locks, immutability, and transaction mechanisms make all of the problems solvable.
For our sample scenarios from the previous section, the document users A and B work on is also distributed across the network. It is stored in Workspace and replicas are stored in all of the frontend components.
All user editing actions (including typing, parentheses-balancing, and deleting) are executed in the form of Fleet’s instructions in the frontend of the user who initiates them, and also in Workspace and all the other frontends. The corresponding instructions are distributed across all of the frontends via the Workspace’s kernel. As a result of executing them, all of the dependent UI elements everywhere should be updated.
Would you expect the initiator’s UI to wait until the change is confirmed by some remote component? Certainly not – that would introduce an inconvenient delay. The distributed nature of Fleet requires it to fully execute an instruction locally first to make the impression that the user is working with a local state. Chances are that due to other users, the change won’t be confirmed globally. In that case, the local Fleet’s frontend would step back and put things into the state that agrees with the global one at Workspace.
Synchronizing transactions
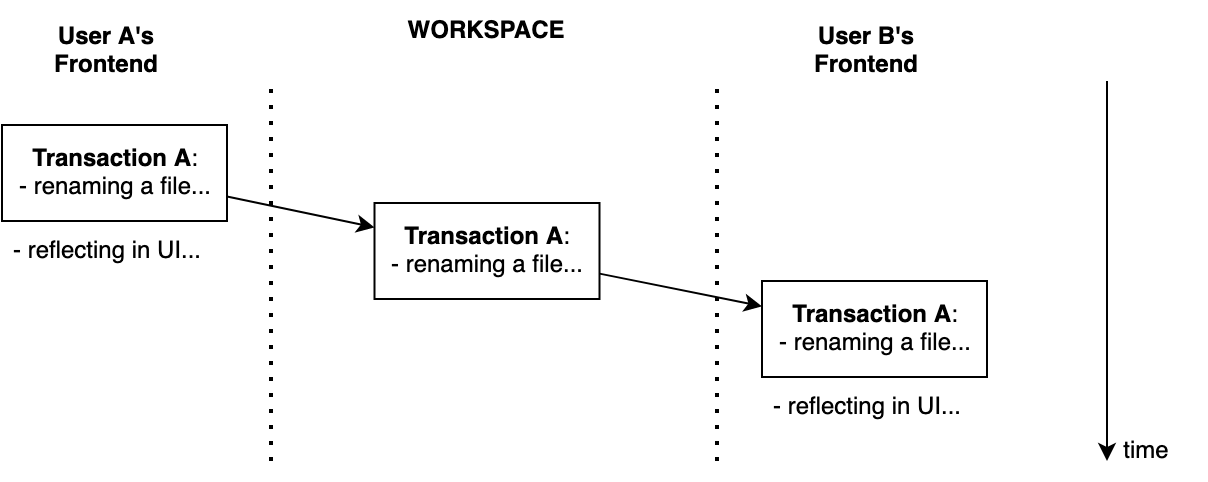
Let’s get back to our sample scenarios. In Scenario 1, user A renames a file. This changes Fleet’s state, so we run a transaction for it and update the affected UI elements. User A’s frontend sends a renaming-file instruction to Workspace. Workspace executes it, checks that everything is ok, and sends it to user B’s frontend. User B’s frontend executes the instruction and reflects changes in user B’s UI. No problem at all.
In Scenario 2, we have both renaming a file and editing content. Depending on which action reaches Workspace first, we may have a different order of transactions, but the final result is going to be the same. In the following diagram, we see that user A is the winner. User A’s transaction is the first one globally.
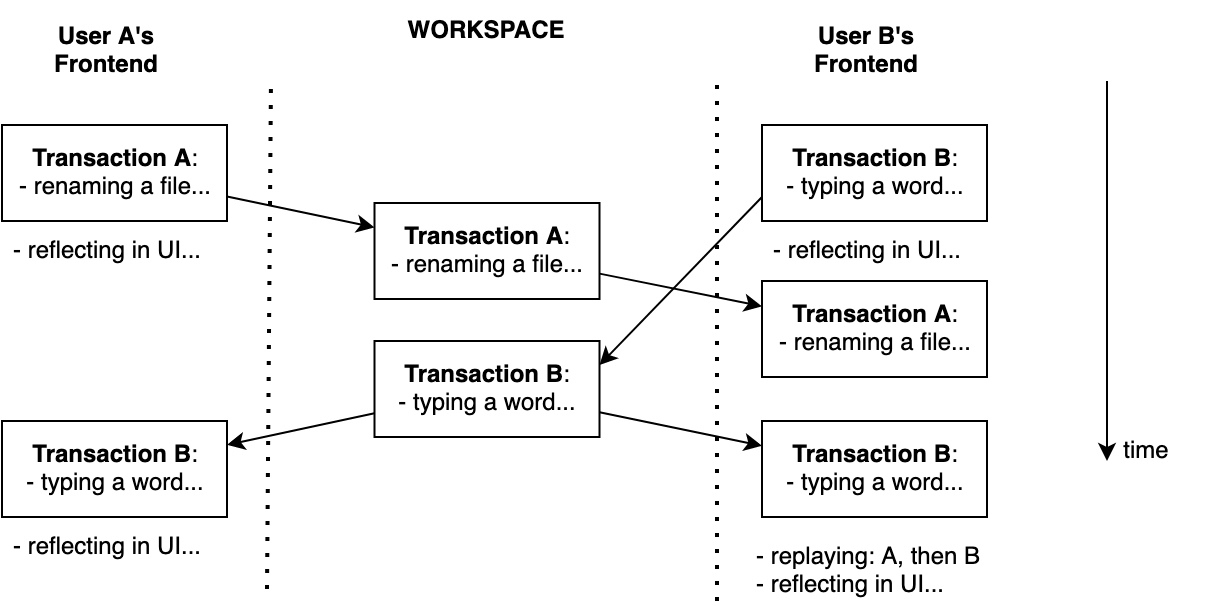
For some time, user B observed the state without Transaction A, but after synchronizing with Workspace, Transaction B was replayed in the right order after Transaction A.
Workspace gets instructions from the frontends in some order, and the sequence becomes finalized. All of the frontends are required to adhere to the final order eventually (though they are allowed to display outdated UI elements for a short time). Thus, they may be forced to replay transactions in the specified order.
What is replaying a transaction? Git users are used to something similar – git-rebase. While replaying a transaction we execute the same instructions, but over the new state. Thanks to state persistence and the fact that we know a bit of the history of transactions unconfirmed by Workspace, this is practical and efficient.
Now let’s move on to Scenario 3 and look deeper into the implementation of the parentheses-balancing command:
- We look at the line — we read the state.
- If there is an opening parenthesis, we add the closing parenthesis — we emit a write instruction.
- If there is no opening parenthesis, we leave the line as it is — we don’t emit any instruction in this case.
The problem is that depending on the state in which we execute this code, the resulting sequence of instructions can be different.
What if Fleet finds itself in the situation like in the following diagram?
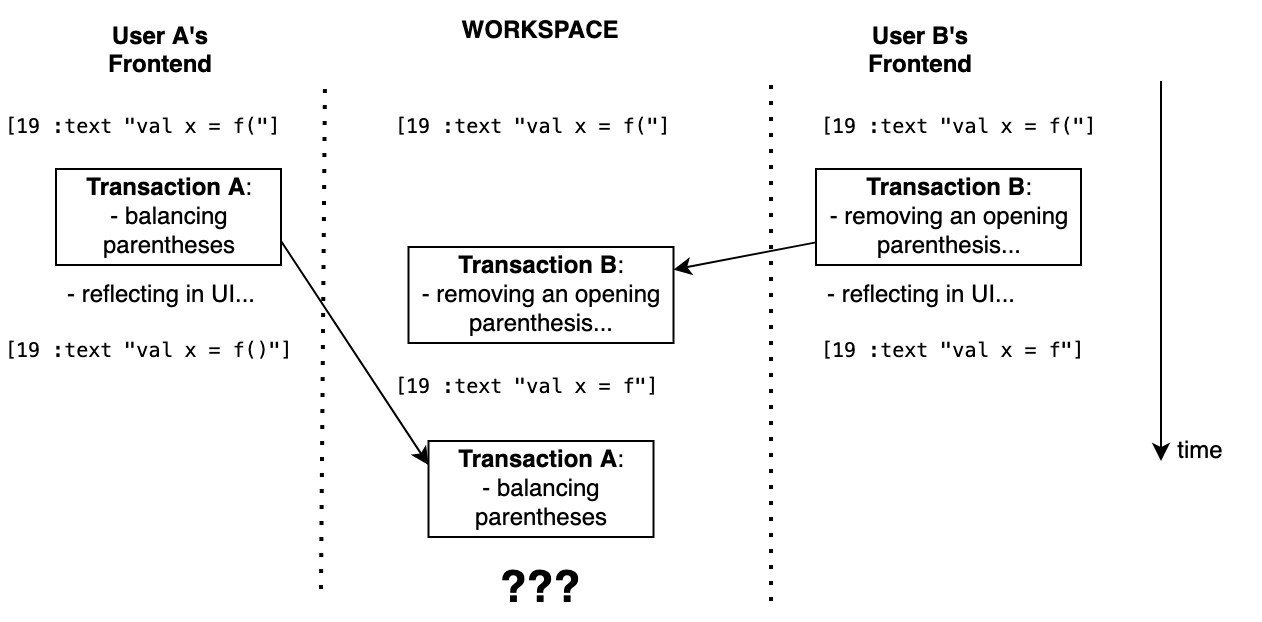
The main problem here is to understand that we are in such a situation. To do that, Fleet uses read validation. Once it’s clear that instructions in the transaction are invalid (based on an outdated state), Fleet forces the Frontend code to regenerate them based on the current state.
Read validation
Our solution is to add a special Validate instruction for every read operation performed while building a transaction. If a transaction is validated for the new state, it doesn’t require special handling. Otherwise, it should be rebuilt.
How can we validate a read operation? Tracking the values we’ve read by computing their hashes is implausible because the values can be huge. Remember that the entire document text is stored as a part of a state. We need something much more efficient.
Remember our datoms, the triples with entity id, attribute, and a value? They are not actually triples – they are quadruples. Sorry for lying all this time! There is a fourth component in them, an integer number called tx, which is responsible for tracking the history of changes of the value in the triple.
Every datom was born inside a transaction. To write it, the corresponding instruction had to read some other datoms. The newly born datom receives its tx value as a result of hashing the transaction id and a sorted sequence of all of the tx’s of the datoms that the instruction had read. Consequently, this tx number records the entire history of the value.
To validate a transaction, we can simply compare the tx numbers, the one we got on the first local run and another one when we play the transaction in the Workspace. Getting different numbers proves the different history of the values that were somehow used for a transaction generation, so we have to invalidate the transaction and rebuild it from scratch using the new state snapshot. One could think of a tx as a data flow trace to a particular value inside the database.
Getting back to Scenario 3, Workspace works as follows:
- It receives, executes, and validates user B’s deleting-an-open-parenthesis.
- It receives and executes user A’s parentheses-balancing instructions, and discovers that it’s no longer valid (wrong tx value of the :text attribute).
- It rebuilds the parentheses-balancing instructions from scratch based on the new state snapshot and executes them (in fact, no changes as there is no opening parenthesis).
- It distributes the final version of the instructions to both frontends and synchronizes global and local states.
Note that user A observed balanced parentheses for some time, but after synchronization, there are no parentheses at all. That’s a win! Or a fail, depending on which side you are on.
Summary
In this fourth part on how we’ve built Fleet, we’ve discussed synchronization issues between distributed frontend components. All of our changes come in the form of sequences of instructions executed in transactions. Workspace receives these instructions from frontends, and executes, validates, and distributes them back. All of the frontends eventually agree on a global state, although they can observe different states for some time.
There is more to come in this series – don’t forget to check later!





