

Fleet
More Than a Code Editor
Fleet 后台探秘,第四部分 – 分布式事务

在本系列博文中,我们将以多个部分为您介绍构建 Fleet 这款由 JetBrains 打造的下一代 IDE。
本系列第三部分重点介绍了如何表示、存储和更改 Fleet 状态的元素。 在此部分中,我们将讨论作为分布式 IDE 的 Fleet,以及它如何保证数据在所有分布式组件之间的一致性。
Fleet 是供开发者进行实时远程协作的平台。 这是一个令人兴奋的技术领域。 我们先来分析在分布式环境中可能面临的问题。
分布式操作的问题
假设两个用户,用户 A 和用户 B。他们在 Fleet 中处理同一个文档,但使用不同的机器。 使用网络信道会引入随机延迟,导致每个用户在不同时间收到其他用户的活动信息。 Fleet 应该如何处理?
为了阐明 Fleet 在分布式环境中的运作方式,我们将使用几个经过简化的示例场景:
- 场景 1:用户 A 通过 Fleet 的界面重命名文件。 用户 B 的 UI 得到更新。
- 场景 2:用户 A 通过 Fleet 的界面重命名文件。 同时,用户 B 将一个字词追加到文档。 两个 UI 都得到更新。
- 场景 3:用户 A 在函数调用中打开一个圆括号,然后调用 Fleet 的命令平衡圆括号。 同时,用户 B 移除了左圆括号。 这样就没有圆括号可以平衡了! 最后会得到什么结果?
了解过 Fleet 中的状态管理后,我们知道上述场景都是在更改 Fleet 的状态。 Fleet 更新相应实体的特性值并提供新的状态快照。 然后,所有 UI 元素将使用新值进行更新。
如果我们再进一步,场景中的所有用户动作都被编译成指令(instructions)序列。 指令可能就像添加或移除值一样简单。 它们还可以处理特性或整个实体。 这些指令序列通过网络传输到其他 Fleet 实例。
Fleet 在事务中执行指令(提供原子性、一致性、隔离性和持久性)并提供新的状态快照。 我们还知道,Fleet 会记录每个事务的变化的新颖点(datom 的添加和移除集),并使用读取跟踪和查询反应性更新受影响的 UI 元素。
回到我们的场景,对于场景 1,Fleet 可以有一个重命名文件的指令。 如果用户 A 通过 Files(文件)视图重命名文件,则执行此指令并更改打开的文件文档的文件地址(更改相应特性的值):
- [18 :fileAddress "~/file.kt"] + [18 :fileAddress "~/newFile.kt"]
这还会更改文档选项卡名称(更新 UI 元素)。 同样的指令也应该为用户 B 执行,更新用户 B 机器上的 UI 元素。
在场景 2 中,除了上述动作,用户 B 的 Fleet 实例还会执行一条指令,导致以下更改:
- [19 :text ""] + [19 :text "hello"]
我们预计将得到“hello”的最终内容和两个 Fleet 实例中的重命名文件。
场景 3 就有些不同了。 假设两个用户都以文本 “val x = f(“ 开头。 用户 A 执行圆括号平衡命令可能导致以下更改:
- [19 :text "val x = f("]
+ [19 :text "val x = f()"]
如果用户 B 移除左圆括号,我们会观察到:
- [19 :text "val x = f("]
+ [19 :text "val x = f"]
如果我们现在执行圆括号平衡指令,从新的初始状态开始,应该不会出现任何变化。 根据用户 A 和用户 B 编辑动作的实际时间,加上随机网络延迟,我们会得到不同的最终结果。 只有了解 Fleet 的运作方式,才能理清这里的情况。
关于分布式状态
我们一直在假设只有一个状态。 上一部分提到一个内核(kernel),这个组件负责状态快照之间的转换并提供对最新快照的引用。 事实上,Fleet 为分布式,具有很多状态和内核。 每个前端组件都有自己的状态和内核。 它们的部分状态属于本地,但也有一个由工作区管理的共享状态(请参阅第一部分了解概述)。 工作区也有自己的内核。 工作区内核的主要目标是在所有前端之间同步状态。
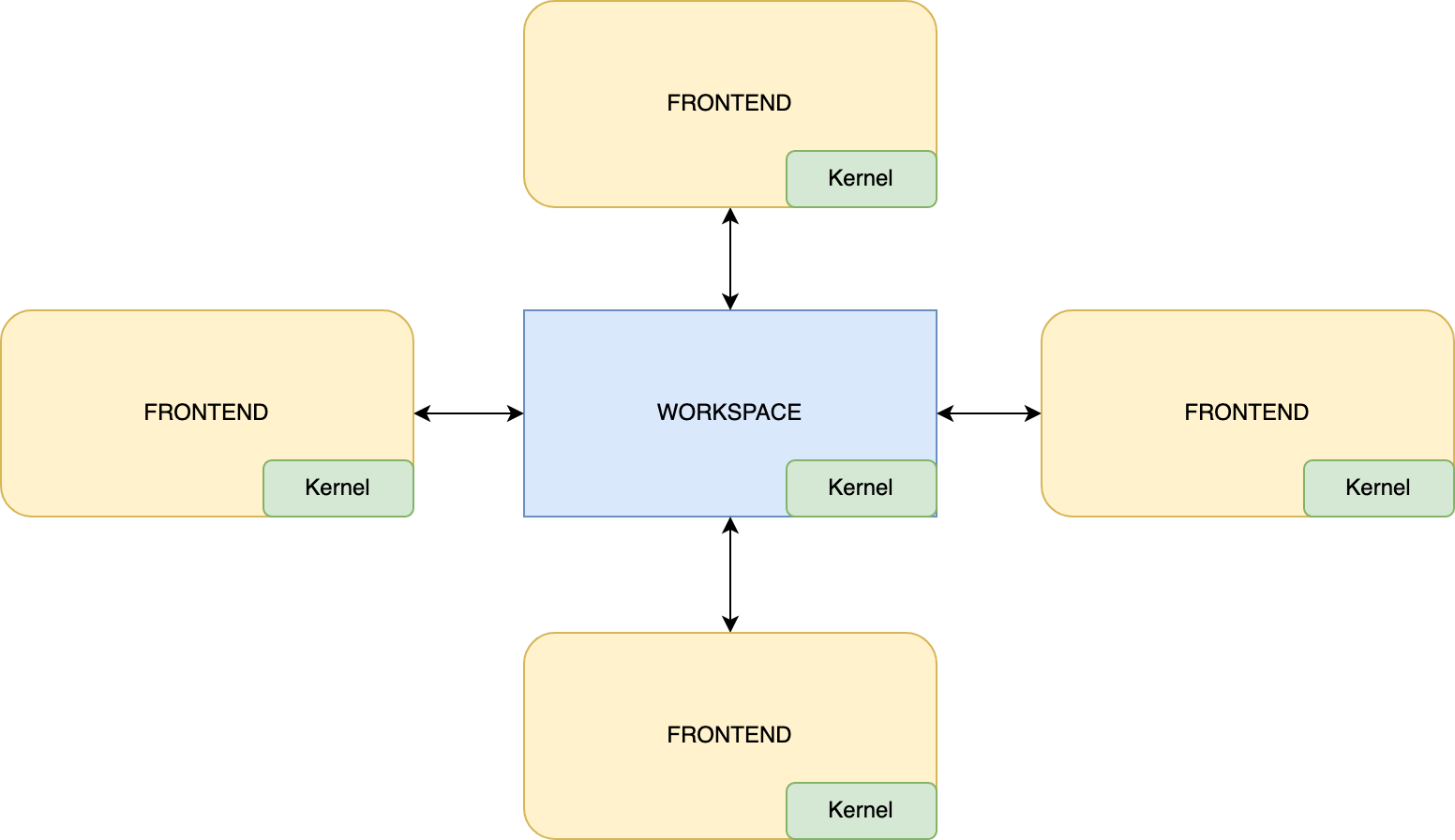
工作区可以在开发者的机器上或云中运行。 这使状态成为分布式,并增加了复杂性,例如需要通过互联网同步状态。 好消息是,没有了读取器锁定、不变性和事务机制,所有问题都可以解决。
对于上一部分中的示例场景,用户 A 和 B 处理的文档也分布在网络上。 它存储在工作区中,副本存储在所有前端组件中。
所有用户编辑动作(包括输入、圆括号平衡和删除)都以 Fleet 指令形式在其用户前端以及工作区和其他前端中执行。 相应指令通过工作区的内核分布在所有前端。 执行后,所有依赖 UI 元素都应该得到更新。
您希望发起者的 UI 等待远程组件确认更改吗? 当然不希望,因为这会带来延迟。 Fleet 的分布式特性要求它首先在本地完全执行指令,给人一种用户正在使用本地状态的印象。 由于存在其他用户,更改可能不会得到全局确认。 在这种情况下,本地 Fleet 的前端会退后一步,使状态与工作区的全局状态一致。
同步事务
我们回到示例场景。 在场景 1 中,用户 A 重命名文件。 这改变了 Fleet 的状态,因此我们为它运行事务并更新受影响的 UI 元素。 用户 A 的前端向工作区发送重命名文件指令。 工作区执行指令,确认一切正常,然后将其发送到用户 B 的前端。 用户 B 的前端执行指令并在用户 B 的 UI 中反映更改。 完全没有问题。
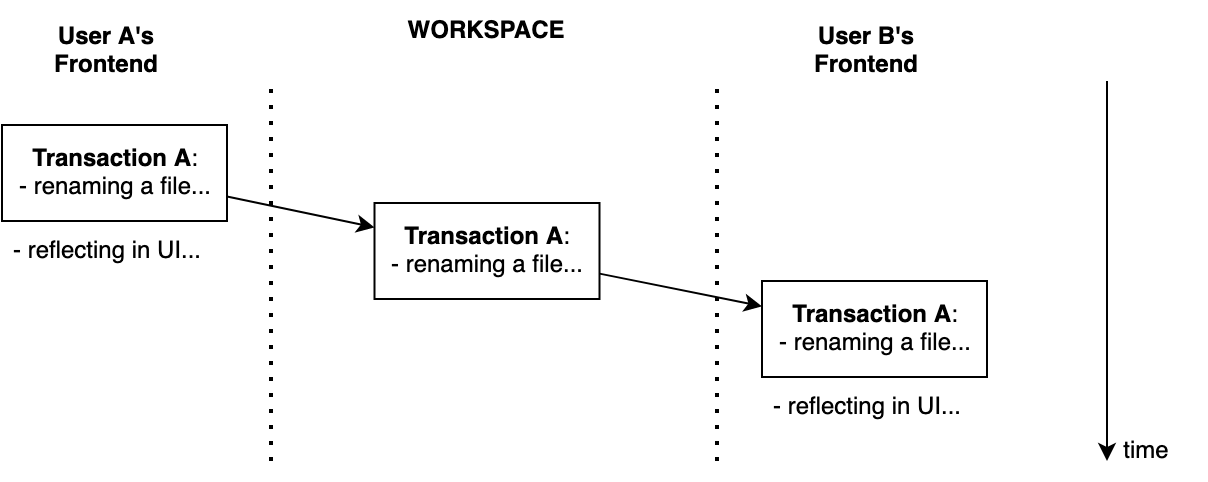
在场景 2 中,我们既重命名文件也编辑内容。 事务顺序根据首先到达工作区的动作而异,但最终结果相同。 如下图所示,最后是用户 A 的结果。 用户 A 的事务是第一个全局事务。
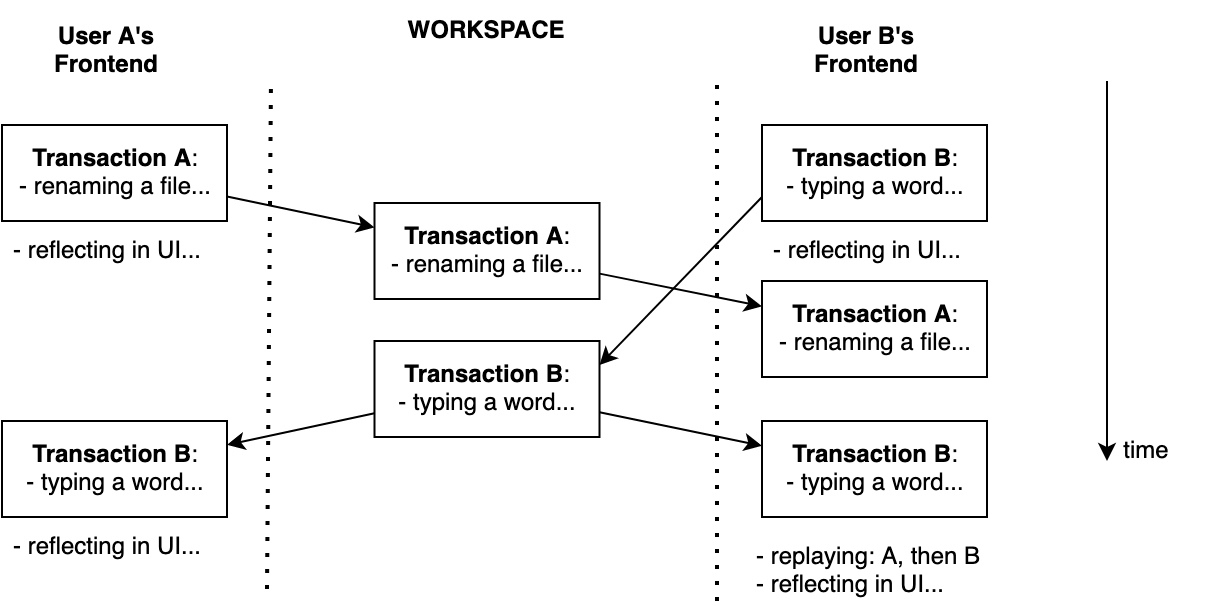
在一段时间内,用户 B 观察到没有事务 A 的状态,但是在与工作区同步后,事务 B 在事务 A 之后以正确的顺序重放。
工作区以某种顺序从前端获取指令,并最终确定为这一顺序。 所有前端最后都必须遵守最终顺序(虽然它们可以在短时间内显示过时的 UI 元素)。 因此,它们可能被迫以指定顺序重放事务。
什么是重放事务? 它与 Git 用户常用的 git-rebase 类似。 重放事务时,我们执行相同的指令,但是在新的状态下。 由于状态持久性以及我们知道一些未经工作区确认的事务历史记录,这既实用又高效。
接下来我们转到场景 3 并深入研究圆括号平衡命令的实现:
- 我们查看行 – 读取状态。
- 如果有左圆括号,则添加右圆括号 – 我们发出写入指令。
- 如果没有左圆括号,则保持原样 – 在这种情况下我们不发出任何指令。
问题在于,根据我们执行此代码的状态,生成的指令序列可能会有所不同。
如果 Fleet 处于下图所示的情况,该怎么办?
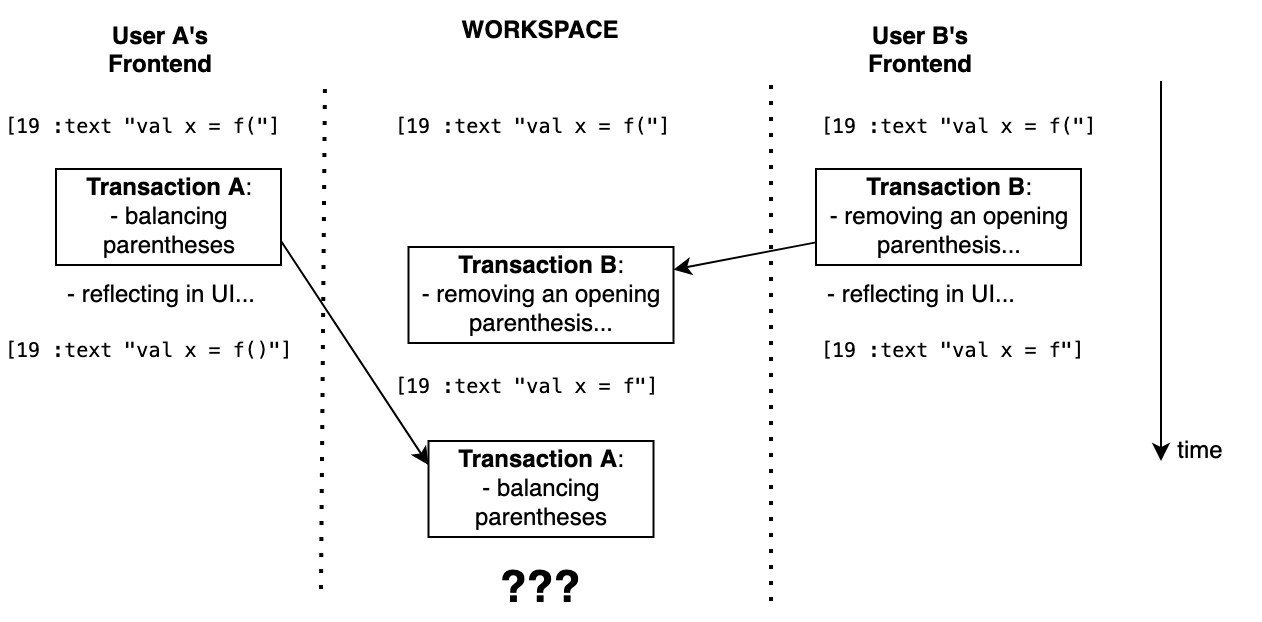
此时的主要问题是如何理解我们处于这样的情况。 为此,Fleet 将使用读取验证(read validation)。 明确事务中的指令无效后(基于过时的状态),Fleet 会强制前端代码根据当前状态重新生成指令。
读取验证
我们的解决方案是为构建事务期间执行的每个读取操作添加一个特殊的 Validate 指令。 如果针对新状态验证了事务,则不需要特殊处理。 否则,应该将其重建。
我们如何验证读取操作? 通过计算哈希值来跟踪读取值是不可信的,因为值可能很大。 请注意,整个文档文本都存储为状态的一部分。 我们需要提高效率。
还记得包含实体 ID、特性和值的三元组 datom 吗? 它们实际上不是三元组,而是四元组。 没错, 其中还有第四个组件,整数 tx,负责跟踪三元组中值的变化历史记录。
每个 datom 都是在事务中诞生的。 要进行写入,相应指令必须读取其他 datom。 新生的 datom 会收到 tx 值,作为事务 ID 哈希处理的结果,以及指令读取的所有 datom 的 tx 排序序列。 最后,此 tx 数字会记录值的整个历史记录。
要验证事务,我们可以直接比较 tx 数字,也就是第一次本地运行获得的数字,以及在工作区中播放事务时获得的数字。 不同的数字表明用于事务生成的值的不同历史记录,因此我们必须使事务失效,再用新的状态快照从头开始重建。 tx 可被视为对数据库中特定值的数据流跟踪记录。
回到场景 3,工作区的工作方式如下:
- 接收、执行并验证用户 B 对左圆括号的删除。
- 接收并执行用户 A 的圆括号平衡指令,发现它不再有效(:text 特性的 tx 值错误)。
- 根据新的状态快照从头开始重建圆括号平衡指令并执行指令(实际并无更改,因为不存在左圆括号)。
- 将指令的最终版本分布到前端并同步全局和本地状态。
请注意,用户 A 观察到一段时间的已平衡圆括号,但是在同步之后就不再有圆括号了。 问题解决! 或者未解决,这就要看您站在哪一边了。
总结
在关于如何构建 Fleet 的第四部分中,我们讨论了分布式前端组件之间的同步问题。 所有更改都采用在事务中执行的指令序列的形式。 工作区从前端接收这些指令,然后将其执行、验证和分布。 所有前端最终都同意一个全局状态,尽管它们会在一段时间里观察到不同的状态。
本系列还有更多内容,请继续关注!
本博文英文原作者:




