

Python du point de vue du réseau neuronal

Le plugin de saisie semi-automatique complète de ligne de code pour Python est maintenant disponible en version bêta publique. Dans cet article, nous présentons une partie des technologies et des algorithmes utilisés pour la création de ce plugin et partageons des statistiques sur la programmation en Python que nous avons collectées au cours de ce processus.
Qu’est-ce que la « saisie semi-automatique complète d’une ligne de code » ?
Vous connaissez déjà sans doute la saisie semi-automatique ou complétion de code, qui suggère le mot suivant celui que l’utilisateur saisit. Si ce n’est pas le cas, nous lui avons consacré une série d’articles que vous pouvez consulter (un, deux, trois, quatre).
La saisie semi-automatique complète de ligne de code va plus loin en suggérant de plus grands fragments de code. Entre autres, elle complète les paramètres d’appel de méthode pour vous ou écrit le texte du message d’erreur. En termes d’expérience utilisateur, elle est proche de la saisie semi-automatique standard et utilise la même fenêtre contextuelle pour présenter les résultats :
Toutefois, la technologie utilisée pour cette forme étendue de saisie semi-automatique est fondamentalement différente.
La saisie semi-automatique standard utilise l’analyse statique pour déterminer les classes, méthodes, variables de champ et mots-clés visibles depuis l’emplacement actuel, et s’appuie sur le machine learning pour sélectionner les meilleures recommandations. La sélection du meilleur élément à partir d’un ensemble prédéfini est un exemple de modélisation discriminative. La saisie semi-automatique complète de ligne de code fournit quant à elle un nouveau bloc de code comprenant plusieurs « mots ». L’écriture de code s’assimile à un processus créatif et fait un usage plus intensif des calculs. On parle alors de modélisation générative. Les réseaux neuronaux constituent un outil de modélisation générative typique, que nous utilisons également.
Voyons plus en détails ce qu’est la saisie semi-automatique complète de ligne de code et quelles sont les principales caractéristiques de son fonctionnement. La question sur laquelle nous nous penchons plus particulièrement aujourd’hui est : comment un réseau neuronal perçoit-il votre programme ?
Les algorithmes fonctionnant avec des langages de programmation utilisent tout un ensemble de techniques provenant du traitement du langage naturel. Au lieu d’utiliser les mots du langage d’origine, le réseau neuronal a recours à une séquence de jetons appartenant à un vocabulaire spécial. L’algorithme construit le vocabulaire en utilisant le processus d’encodage par paire d’octets. Nous allons tout d’abord voir un exemple en anglais simple, puis examiner comment cela fonctionne en Python.
Encodage par paire d’octets dans les langages naturels
L’algorithme construit le vocabulaire au début de la phase d’apprentissage et rassemble les statistiques à partir des textes utilisés pour l’apprentissage. L’ensemble de jetons ne change pas après cela et reste identique tout au long du traitement pendant la phase d’exploitation.
Imaginons que le seul texte en anglais disponible pour l’apprentissage soit le dicton suivant :

Ce dicton peut se vérifier ou pas. Quoi qu’il en soit, il contient plusieurs mots qui se répètent, ce qui aide à comprendre l’algorithme. Quels types de jetons pourrons-nous en retirer pour une utilisation ultérieure ? Nous initialisons la liste de jetons avec chacune des lettres (symboles) de notre phrase d’apprentissage :
[i, f, y, o, u, a, l, w, s, d, h, t, g, e]
Notez que Unicode code chacune de ces lettres comme un octet unique, de sorte que les symboles et les octets sont ici équivalents.
Nous n’incluons pas d’espace, mais nous pouvons l’utiliser comme séparateur naturel de jetons. Ce détail aura son importance par la suite.
Après l’initialisation, nous développons le vocabulaire de façon itérative. Nous recherchons la concaténation la plus fréquente pour les deux entrées existantes et la désignons comme un nouveau jeton. Dans notre exemple, « you » et « always » sont répétés quatre fois, mais nous ne pouvons pas encore les ajouter, car aucun d’eux n’est une concaténation de deux entrées. Nous devons procéder étape par étape, et le premier candidat est « yo ». Une fois le premier jeton défini, il devient insécable, et nous ne pouvons plus utiliser ses éléments séparément. Ainsi, « ou » ne pourra jamais devenir un jeton, car cela demanderait de fractionner « yo ».

Nous répétons cette étape pour trouver d’autres concaténations de jetons fréquentes et les ajouter au vocabulaire. L’algorithme arrivera à « you » et « always » avant de traiter d’autres paires de symboles, telles que « wh » et « at », qui n’apparaissent que deux fois. Un vocabulaire de taille 32 (puissance de deux) peut se présenter comme suit :
[i, f, y, o, u, a, l, w, s, d, h, t, g, e, yo, ys, al, ays, ways, you, always, at, wh, what, if, il, id, ot, wil, do, did, ge]
Tout nouveau jeton ajouté est une concaténation de deux autres jetons, ce qui s’appelle un encodage de paire.
À ce stade, pour éviter toute confusion, il est utile de clarifier les choses concernant le concept de jeton : nous appellerons « mot » un élément lexical de langage, tandis que nous appellerons « jeton » une entrée de vocabulaire obtenue par encodage de paire d’octets. Certains jetons ne sont pas des mots (par exemple ays). Il peut également y avoir des mots qui ne sont pas des jetons (par exemple : will et get. Nous avons arrêté la génération du vocabulaire avant de les inclure.)
Le réseau neuronal prend une entrée et génère une sortie en termes de jetons, non de mots. Les ressources de calcul requises dépendent de l’étendue du vocabulaire. Cette astuce nous permet de limiter la taille de la valeur voulue au lieu d’utiliser tous les mots du langage.
La quantité de jetons dans l’entrée est également essentielle pour la qualité et les performances. L’algorithme peut ne prendre en considération qu’un seul fragment u texte (appelé « contexte ») pour lequel il doit générer la suite. En utilisant des jetons étendus, il devient possible de prendre de plus gros morceaux de texte en tant qu’entrée. Heureusement, les langages de programmation offrent des options supplémentaires pour y parvenir.
Du langage naturel aux langages de programmation
Les auteurs de systèmes de traitement du langage naturel utilisent généralement les limites des mots en tant que limites absolues entre les jetons. La séquence « John Smith » est plus fréquente en anglais que « Trantor », surtout lorsqu’il s’agit de non-fiction. Cependant, « Trantor » peut théoriquement devenir un jeton dans le cadre d’un vocabulaire beaucoup plus large, car il s’agit d’un seul mot. Cela n’est pas possible pour « John Smith », qui est en deux mots. Les jetons du langage naturel ne dépassent généralement pas les limites des mots.
Avec les langages de programmation, la séparation naturelle des jetons se fait au niveau de l’analyseur lexical : le mot se termine là où il est possible d’insérer un espace. Une variable, une constante et un mot-clé de langage n’ont pas de liens entre eux.
Nous pensions pouvoir faire mieux pour les langages de programmation. Prenons l’expression Python classique suivante :
for i in range(
Elle inclut de nombreux éléments lexicaux différents, dont deux mots-clés de langage, une variable et une fonction. Pourtant, le programmeur Python (encore débutant) en moi pense que for i in range( devrait être une seule entrée dans le vocabulaire. Le réseau neuronal devrait utiliser une seule itération d’inférence au lieu de quatre ou cinq pour faire une prédiction, afin de préserver la capacité de calcul de votre ordinateur portable pour le contenu entre parenthèses.
L’idée générale consiste à délimiter les jetons par des sauts de ligne au lieu d’éléments lexicaux. Notre objectif étant la saisie semi-automatique d’une ligne de code, l’utilisation de la ligne comme unité de jeton est naturelle.
La taille de notre vocabulaire est limitée à 16 384, une autre puissance de 2 très pratique. Nous avons initialisé le processus avec des caractères Unicode couvrant 99,99 % du texte et commencé à traiter les référentiels Python avec des licences permissives.
Dans les sections suivantes, vous allez découvrir les 16 384 constructions Python les plus populaires.
Problèmes dans le vocabulaire
L’inspection visuelle du vocabulaire a permis d’identifier quelques problèmes systémiques. Statistiquement, certaines entrées sont prévisibles, mais leur inclusion présente des inconvénients.
La première surprise : le chinois
Les 600 jetons environ qui sont apparus après les octets étaient principalement des symboles Unicode pour des caractères n’appartenant pas à l’alphabet latin, tels que les caractères chinois. Le chinois par lui-même était une surprise, mais à part cela, la signification des caractères semble compréhensible.
Par exemple, la première occurrence est le caractère 的. Ce symbole est le plus souvent utilisé comme équivalent du possessif « ‘s » en anglais. D’un point de vue statistique, il s’agit du caractère chinois le plus fréquent. Certains étaient très utilisés dans notre ensemble de données, mais moins dans le langage lui-même. Par exemple, 数 et 码 se rapportent aux chiffres, tandis que 网 signifie « réseau ». Étant donné le contexte de programmation, rien d’anormal ici. Il nous reste seulement à comprendre pourquoi ces symboles sont apparus dans notre vocabulaire.
Les caractères non latins, notamment chinois, russes, japonais, coréens et parfois arabes, viennent des chaînes des docstrings Python. En toute logique, les gens tendent à écrire leur documentation dans leur langue natale.
L’inclusion de caractères n’appartenant pas à l’alphabet latin dans le vocabulaire comporte probablement plus d’inconvénients que d’avantages, car ils occupent un espace qui serait mieux utilisé par des constructs plus courants du langage de programmation. Avec ces caractères, nous avons une meilleure prise en charge des noms de variables Unicode autorisés en Python. Cependant, ils sont rarement utilisés, et lorsqu’ils le sont, c’est principalement pour l’obfuscation de code.
La deuxième surprise : l’indentation
Une autre chose désagréable se produit lorsqu’on fait une recherche grep des mots-clés souvent utilisés en début de ligne dans le vocabulaire, tels que return :
return return return return return
(et beaucoup d’autres occurrences)
Les fragments d’instruction return utiles apparaissent également avec toutes sortes d’indentations de début de ligne et on obtient donc plusieurs copies des jetons suivants dans le vocabulaire :
return self.return Truereturn Falsereturn 0return None
Conserver ces copies peut sembler peu pratique. Lorsque nous appelons la saisie semi-automatique, le caret est rarement au début d’une ligne. L’IDE suit l’indentation et l’utilisateur sera probablement déjà au bon emplacement lorsqu’il commencera à saisir return. Par conséquent, les instructions return avec des espaces de début de ligne ont peu de chances d’être utilisées.
D’un autre côté, cela réduit la longueur du contexte. Chaque retour indenté sera un seul jeton au lieu de plusieurs.
Instruction d’importation
L’un des autres problèmes que nous avons recontrés concernait les instructions d’importation impliquant des frameworks populaires tels que TensorFlow, PyTorch et Django, par exemple :
from tensorflow.python.framework import opsfrom django.conf import settings
De telles instructions apparaissent généralement une fois par fichier et sont généralement proches du début. De plus, les mécanismes de complétion de code et d’importation automatique classiques peuvent s’en charger. D’un autre côté, encore une fois, cela permet de prendre en compte de plus grands morceaux de code lors de la génération des suggestions de saisie semi-automatique. La question de savoir si ces longues instructions d’importation sont requises en tant que jetons reste ouverte.
Examiner les données
Le point à retenir dans cette section est probablement l’importance de l’inspection visuelle des données. Les résultats intermédiaires du traitement statistique des données et des algorithmes basés sur le machine learning peuvent contenir des problèmes systémiques non couverts par les tests mais évidents pour des experts humains.
L’association des statistiques et heuristiques est souvent bien meilleure que les statistiques seules.
Paires de symboles populaires
En faisant défiler la fenêtre vers le bas, nous arrivons aux combinaisons à deux symboles. Il s’agit de comprendre pourquoi elles arrivent en haut de la liste. Certaines proviennent des mots-clés les plus communs du langage, tandis que d’autres résultent de conventions de nommage et d’habitudes de programmation.
Savez-vous quelle est la combinaison de deux symboles la plus fréquente en Python (après le double espace blanc, bien sûr) ? C’est virgule+espace blanc, comme ceci : , . Cela fait sens ! Voyons la suite.
se vient principalement de self. En fait, self. est la combinaison à cinq symboles la plus fréquente et l’un des jetons les plus utilisés. Il est plus fréquent que la plupart des séquences à deux et trois symboles, sauf celles qu’il contient.in Youpi ! for i in range(re vient principalement de return.on est un cas intéressant. La plupart de nos noms de variables, de champs, et même de classes, se terminent par « tion », « cion » ou « sion ». « None » et « json » sont deux autres contributeurs importants.te semble mystérieux au premier abord, mais une étude plus approfondie du vocabulaire révèle l’abondance du mot « test » sous différentes formes. Des mots tels que « date », « text », « state », « write » et l’omniprésent « items » contribuent également à la fréquence de ce jeton.= doit être vraiment très populaire. Si l’on change l’ordre, = n’est pas si fréquent. La différence ne peut pas être inférieure au nombre d’opérateurs !=.or vient généralement de mots-clés très utilisés dans le langage, tels que or, for et import.
Combinaisons de symboles complexes
Jetons ignorant les limites
Deux jetons fréquents, s[ et s.append( sont particulièrement représentatifs du travail avec les listes en Python. Nous utilisons généralement des noms de liste au pluriel : jours, marchandises, articles, lignes. Ces jetons illustrent la puissance des statistiques : ils s’affranchissent des limites des éléments lexicaux de Python pour exprimer la façon dont nous parlons anglais dans le code.
Range
Revenons à range, évoqué lorsque nous avons présenté les jetons de ligne complète. A-t-elle été intégrée dans le vocabulaire ? En effet, elle est bien visible :
for i in range(
De plus, il y a une instruction encore plus longue qui est fréquente :
for i in range(len(
Signalons au passage que i est le seul nom de compteur qui soit utilisé assez souvent. Les autres, tels que j et k sont peu utilisés.
Instructions Return
Qu’est-ce que les programmeurs utilisent comme résultats de leurs fonctions ? Il n’y a pas de surprise concernant la fréquence d’utilisation de :
return Falsereturn Truereturn None
Leur fréquence d’utilisation est assez semblable, mais elles arrivent toutes derrière return self. return 0 est un autre exemple de jeton couramment utilisé. Les gens n’utilisent pas 1, 2 ou tout autre chiffre assez souvent pour qu’ils soient visibles dans les statistiques. Autres choses curieuses :
return []return super(return datareturn valuereturn notreturn len(self.
Le dernier jeton est obtenu en combinant return et len(self., car return len( ne figure pas dans le vocabulaire.
Classes
Existe-t-il des combinaisons avec le mot class suffisamment populaires pour faire partie des 16 384 éléments du vocabulaire ? La combinaison qui arrive en tête, et de loin, est class Test. Elle est suivie par deux autres combinaisons, qui arrivent loin derrière :
class Meta:class Base
Les autres jetons significatifs incluant class n’ont pas de lien avec les noms de classes :
classifierclassificationissubclass(@classmethodBase class for
Les deux derniers viennent de la documentation.
Synthèse
Le réseau neuronal utilise le vocabulaire pour représenter le programme d’entrée et construire les suggestions. La représentation du programme est disponible dès maintenant et les algorithmes de génération de code feront l’objet de prochains articles.
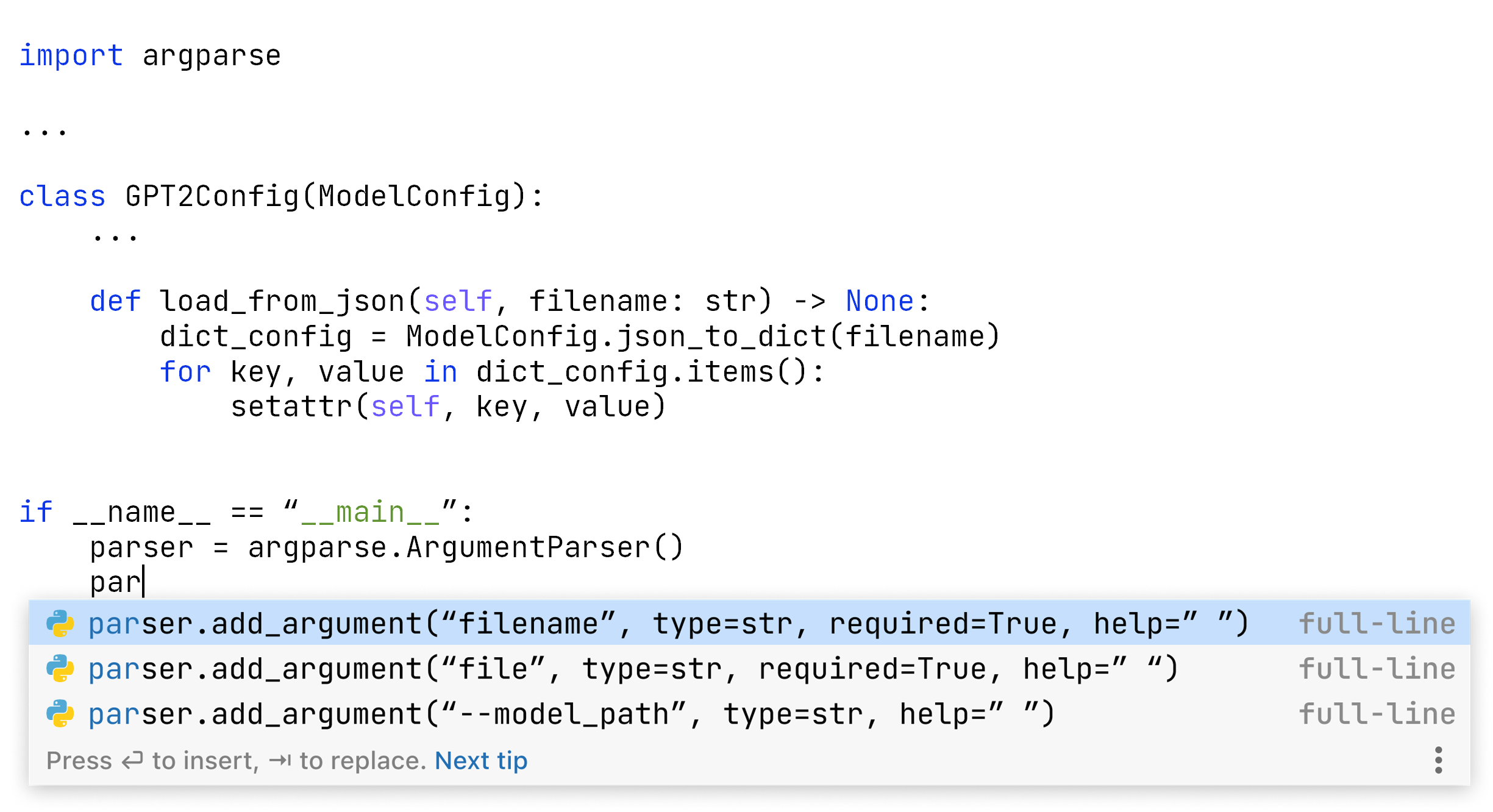
Si nous prenons un fragment simple de code Python et exécutons le générateur de jetons (tokenizer), nous pouvons le voir de la même façon que le réseau neuronal le voit :

Le générateur de jetons transforme ces 3 lignes en 15 jetons. Les modèles basés sur GPT-2 peuvent avoir jusqu’à 1 024 éléments ; notre limite d’utilisation est de 384. Dans notre ensemble de données d’apprentissage, la longueur médiane d’une ligne est de 10 jetons, ce qui est un peu plus long que dans l’exemple ci-dessus. Nous pouvons estimer que le modèle utilise un peu moins de 40 lignes de contexte pour générer les prédictions.
Cet exemple montre également à quel point le « mode de pensée » du réseau neuronal et celui de l’humain sont différents. Nous comprenons que args représente la même chose dans les deux premières lignes. Cependant, l’algorithme les voit différemment, il fractionne même la deuxième ligne.
Essayez le plugin de saisie semi-automatique de ligne de code pour Python
Parcourir et développer le vocabulaire ont fait partie des étapes pour atteindre nos objectifs en termes d’offre produit. Nous prévoyons de proposer davantage d’articles techniques sur la façon dont le réseau neuronal génère du code et comment adapter ses performances aux capacités des ordinateurs portables des utilisateurs.
En attendant, nous vous invitons à essayer le fruit de notre travail, le plugin de saisie semi-automatique complète de ligne de code pour Python :
https://plugins.jetbrains.com/plugin/14823-full-line-code-completion
Auteur de l’article original en anglais :