

Code Completion, Episode 1: Scenarios and Requirements

Have you ever wondered what happens in the IDE when you start typing a new word and the code completion popup appears? The popup that’s displayed uses machine learning under the hood by default for Java, Python, Ruby, JavaScript, TypeScript, Go, and Scala. This technology can also be manually enabled for other languages in the settings:
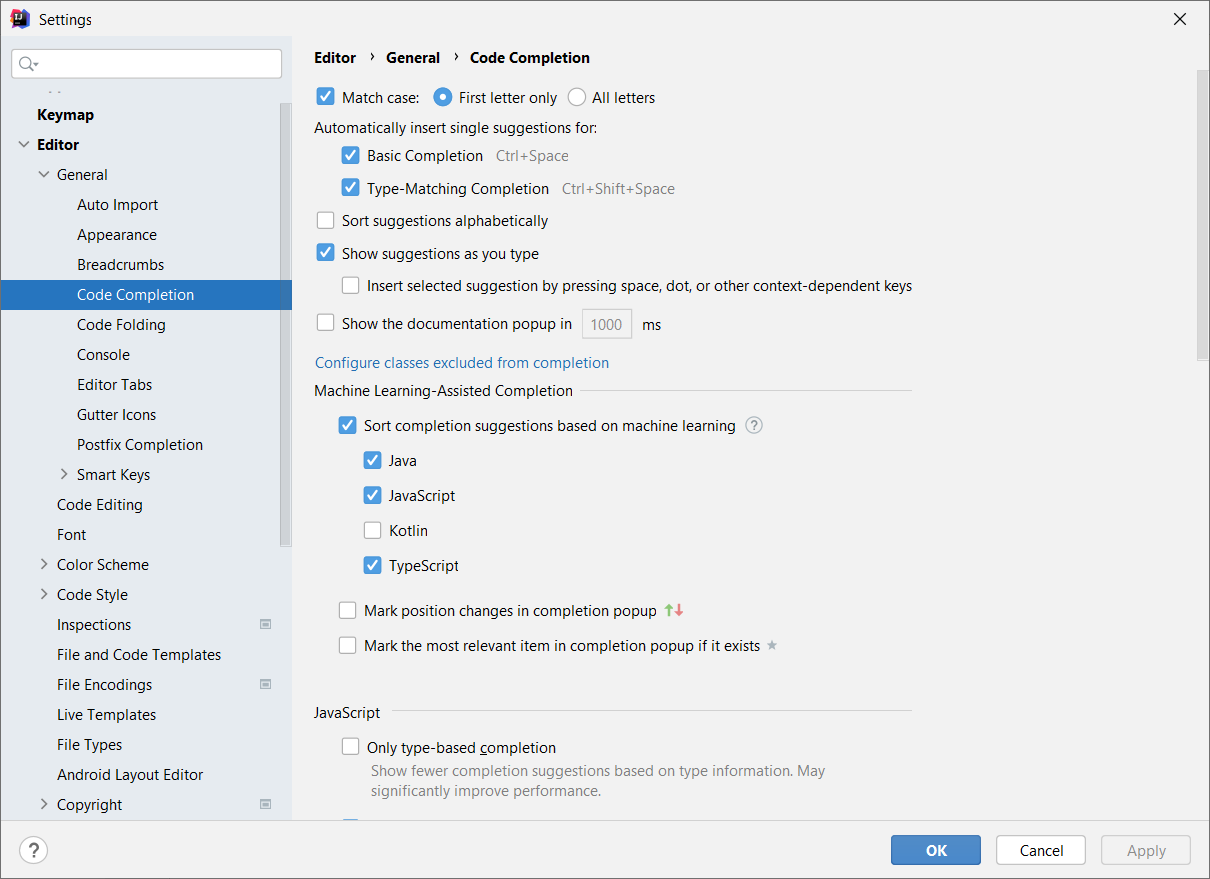
We would love to hear your feedback on ML-based completion, your unusual usage scenarios, and general observations related to code completion.
The ranking of completion suggestions is one of the very first significant ML-based components that we have included in our IDEs, and we thought you might be interested in learning about the long and winding road we had to travel to implement it. In this blog series, we would like to share our motivation for using ML-based algorithms and describe various related aspects:
- Building the data set
- Data protection
- Model training
- A/B testing of desktop applications
- And everything in between
It is incredible just how much is involved in just presenting a simple window like this:
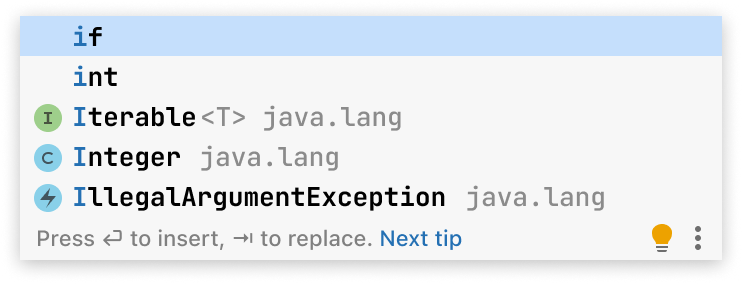
To explain the need for all this machinery, let’s examine this same popup in more detail. What do you think? Is this a good popup or a bad one?
You’re probably saying it depends on where my IDE invoked this instance of completion in the code. Indeed, in its current form, this popup is useless with almost no regard to the context.
To see why it is useless, we need to look at the code completion usage scenarios and requirements first.
What do developers need from code completion?
Easy answer: fewer keystrokes
If you look at the public comparisons of code completion systems, you will notice that, in many cases, the authors compare the number of keystrokes. The fewer keystrokes that are needed, the better. Developers often use veryLongAndMeaningfulIdentifiers and want to bring them up quickly and without typos. Smooth completion likely nudges them towards using even longer and more meaningful identifiers, making smooth completion even more critical.
Therefore, saving on keystrokes is most helpful when it reduces the typing of long tokens created by the user. Vincent Hellendoorn et al. published an article where they investigated which completions are used and which are dismissed most often.
It turns out that developers very rarely complete language keywords and built-in type names. The vast majority of the completions they do use consist of identifiers, with method invocations being predominant, followed by field accesses. And over half of the method invocations deal with intra-project API calls. Local variable names are less popular, perhaps because they are usually short, especially for the variables of built-in types.
Our observations match those of the authors, even though they only studied C# development, whereas we are working with a much more diverse language set.
Who needs completion to obtain an if-statement? Do you remember Pascal? Imagine how many keystrokes we could save on integer and begin! But alas, they are no longer in use.
Type inference has improved in modern languages, and even statically typed ones often don’t require you to provide types explicitly. (Java var declarations, anyone?)
With Python duck typing, we don’t ever need the type names to declare variables. They only appear in explicit castings, like dividing two ints to obtain a float. And every time we have to do such casting, it’s probably because we haven’t used the language properly.
Language keywords and built-in type names are easy to predict, but they don’t help much. There’s no harm in showing them, but we can do better.
Hard answer: cognitive load
If you are reading this, it is likely you are a software developer. You write code, but how much of your time at work is actually spent typing. I bet you read and debug code way more than you write it. And even when you do write code, typing per se is a relatively minor concern.
We want to save time and effort spent on thinking, not just typing.
We help developers in this respect by saving them the trouble of having to remember stuff. Intra-project API calls are responsible for more than half of what people struggle to remember. The language core libraries and third-party APIs are also somewhat important, but nowhere near as important as what happens inside the project. Any time you don’t have to open your colleague’s code or browse the often non-existent documentation to determine whether you need isSetDropAllItemsOnExit() or shouldDropEverythingWhenLeaving(), we’ve done our job well. We’ve saved a sizable chunk of your time and brainpower!
Scenarios of pure exploration are also possible. Developers may invoke completion at the beginning of a new line without inputting anything, just to see “what is available.” What’s the point of doing this? Imagine that you are editing a class with an abstract parent. You might want your IDE to suggest a stub for one of the abstract methods that haven’t been implemented yet.
If we look back at the poor popup example from the beginning of the article, we can now see what’s wrong with it:
It gives us a 2-letter language keyword, a primitive type name, and three pretty trivial items from the core library. It doesn’t have a single suggestion that looks like a potential time-saver. What should we do to get one?
Code Completion Requirements
The IDE has to perform two significant steps to find time savers and present them to you:
- Static analysis of the code to find the possible symbols.
- Sorting of the suggestions to put the most relevant first.
We will devote future episodes of this series to the second step: sorting. Here, however, we want to share a few facts about the first one: searching for candidates.
What is the primary requirement for the candidates we find?
Correctness
If we ask random people around the office (or, for the past year, in a conference call), the response we get is that the suggestions must “make sense.” When pressed further, they specify that the completions should be “correct.” Types should match, keywords should be in the appropriate locations, things like that.
Do you want the code you write to be valid? Of course! We also like it when your code can compile. Unfortunately, correctness is overrated. These same people who ask for correctness in a survey require precisely the opposite when they stop speculating about the code and start writing it. Here are a couple of small examples.
Example 1: private method of a superclass
Imagine the following scenario:
public class Parent {
private void doSomething() {...}
}
public class Child extends Parent {
public void enhanceSomething() {
doS| ⇐ caret here
}
}
Do we need to show doSomething() in the popup even though it is a private superclass method and should not be visible from where the caret is? You bet! We often observe that users want to call the method immediately and refactor the parent class to make it protected later.
Worse, the method can have a name like doSomethingSpecialAndBeProudAboutIt(). The user will get mighty annoyed if we make them write it out letter by letter.
Example 2: the wrong keyword
Another typical situation relates to the usage of the extends and implements keywords in Java. You extend a class but implement an interface, so these keywords limit the list of names you can write next.
Developers often don’t remember the exact types of entities they manipulate. Is my ActionRepeater an interface or an abstract class? Should my SmartActionRepeater extend it or implement it? I don’t want to remember all of this, nor do I want to check the documentation. I want to select it from the completion popup and immediately fix the keyword if the initial guess was incorrect.
A fun fact: according to our observations, the (mis)use of these keywords is not symmetric. If a developer chooses “implements,” they are usually confident. When unsure, they prefer “extends.” Therefore, many users requested that the completion popup should show interface names after “extends“.
It is often faster to write formally incorrect code and fix it. However, some developers regularly try to write something they can’t fix. For example, we often have to show void method suggestions even if a return type is required. We have users that don’t stop until that void method is inserted, at which point they either delete or rewrite it.
Therefore, the completion system must provide tokens that are formally incorrect but still make sense given the context. But this poses a problem: the “correct” suggestions are few and easy to find compared to the “incorrect” ones. We build an abstract syntax tree for each file in the project and enrich it with semantic information, so analyzing the visibility scopes is relatively straightforward. “Incorrect but still makes sense” completions require processing much more data. For example, we have to keep in mind all the core libraries, not just the part explicitly imported in the edited file.
This poses a whole new set of problems. You already know what their common name is, right?
Performance
The completion window should be fast. Users will not wait for seconds to get the list of the suggestions. They will only wait for milliseconds. Our gut feeling of what is acceptable is as follows:
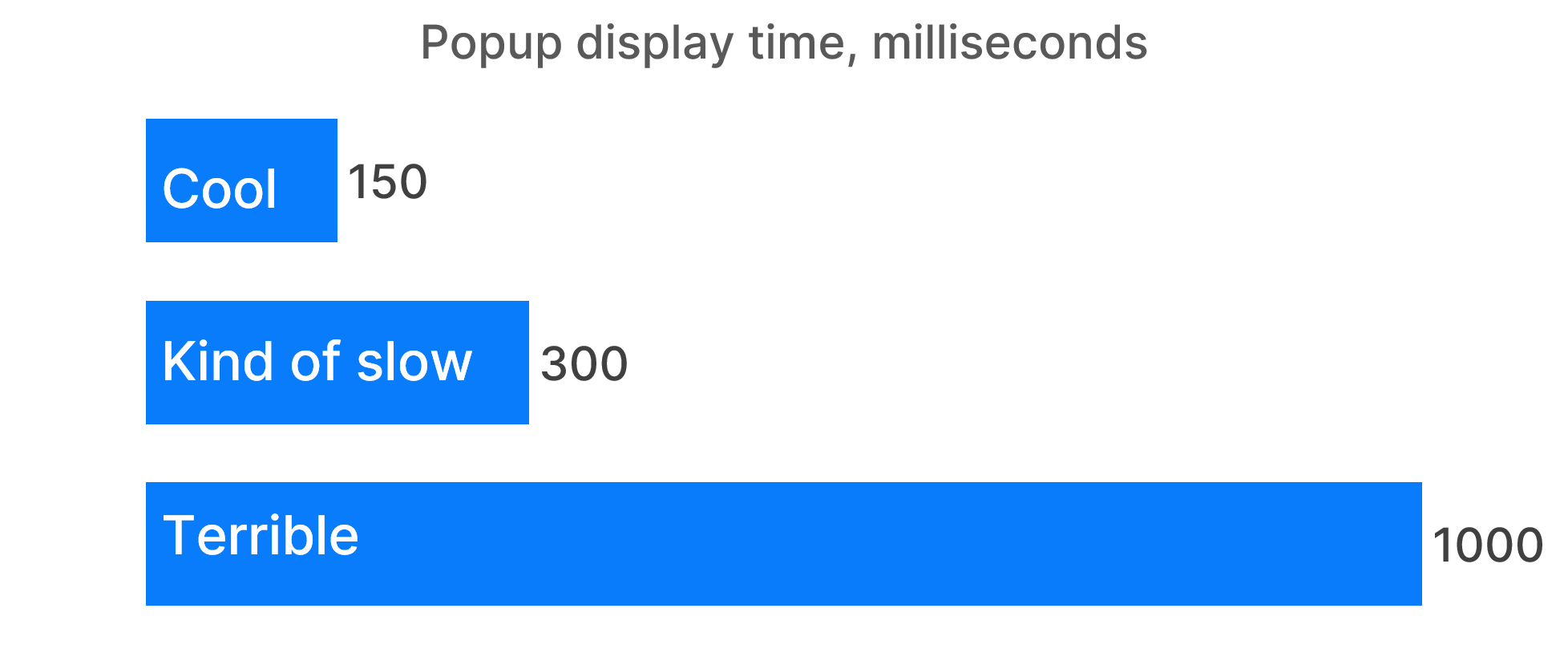
In a perfect world, we would form a list of suggestions, sort it, and present the window to the user within 150 milliseconds. In reality, we have to employ different algorithms for various types of tokens and then merge the results. Typically we gather keywords, variables, classes, member fields, and method calls separately, running routines we call “contributors.” The exact sets of contributors differ between languages, and each IDE may break this down in its own unique way. In the worst case, no suggestion at all may be available, not only at “kind of slow” deadline but even at the “terrible” one.
We set the timeout to 100ms after the first contributor returns a suggestion, at which point we display the popup with whatever we’ve managed to muster at that time.
What do we do if a contributor finds more candidates after the timeout? More specifically, what do we do if the best candidate happens to arrive late? We implement the contributors to return the most relevant items first, but this is not always possible. In some languages, the core libraries are so vast that you just can’t skim through them in time.
Instead of dismissing such a result, we try to edit the already-shown completion popup, but this poses a usability issue. Way more often than is desirable, the suggestion you were ready to confirm will disappear right from under your fingers to be replaced by something you didn’t expect. Naturally, this late arrival gets a lot of hate!
Even if we are highly confident in their quality, any late suggestion will only appear several positions below the currently highlighted item to avoid random selections. We declare the original top of the list “frozen” and never change it.
This trade-off has its flaws. For example, consistency suffers. Depending on how busy the CPU is, the visible top of suggested completions may differ in otherwise similar situations.
Sorting the candidates
Suppose we were lucky, and the contributors returned their respective candidate lists quickly. There are a total of 820 suggestions; how do we select the most relevant of them to construct the first popup? This question brings us to the second step.
The logic governing the top of the candidates’ list is far from straightforward. We had to employ machine learning to improve it past a certain point. In the second episode, we will discuss this logic and see that ML-based algorithms are necessary.
In the meantime, please share your observations about code completion, the scenarios in which you use it, and non-standard requirements that have occurred in your practice.




