

Datalore
Collaborative data science platform for teams
5 façons de collaborer efficacement pour les équipes de science des données

Les projets de science des données sont composés de nombreux éléments, parmi lesquels des notebooks, des données, des environnements, des scripts, et travailler ensemble efficacement sur un tel projet peut représenter un défi pour une équipe.
Dans cet article, nous vous présentons 5 techniques de collaboration qui permettent de simplifier le travail et d’améliorer la productivité des équipes spécialisées en sciences des données.

Partager facilement le code et les artefacts essentiels
Dès le début d’un projet de science des données, la difficulté liée au partage de documents avec les autres membres de l’équipe peut affecter la collaboration. Le partage d’un notebook Jupyter requiert également le partage d’une grande quantité d’éléments de contexte : l’environnement, les données et les connexions de données. Vous n’avez pas besoin de tout cela si vous rechercher seulement de l’aide pour la transformation des données par exemple. Et si partager des notebook Jupyter pouvait être aussi facile que partager des Google Docs ?
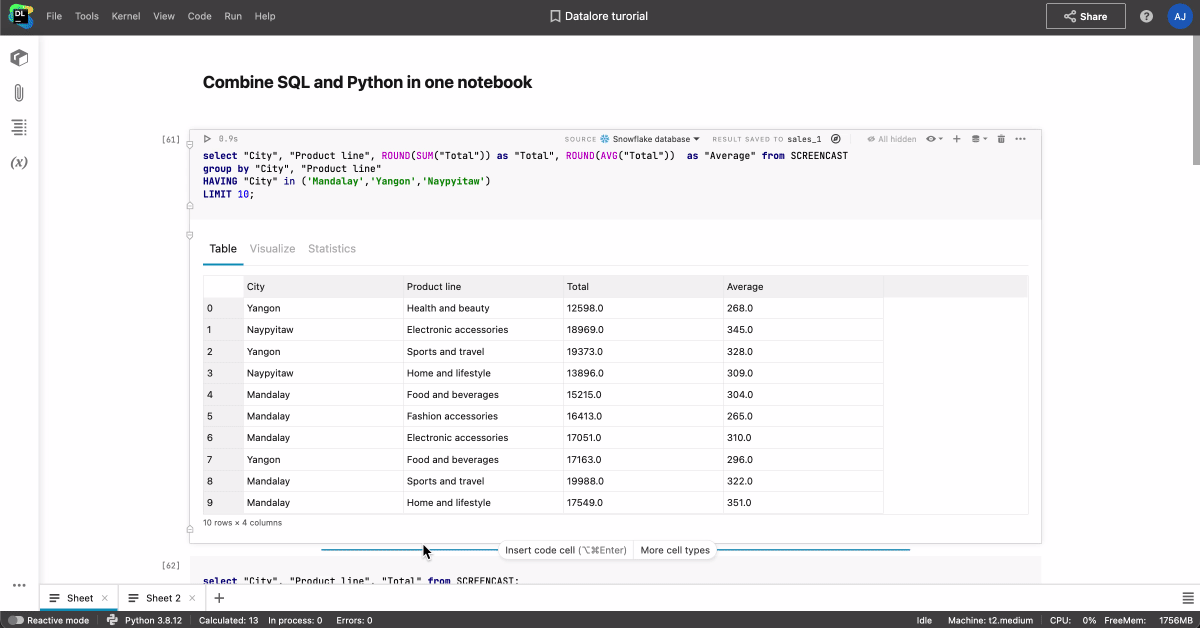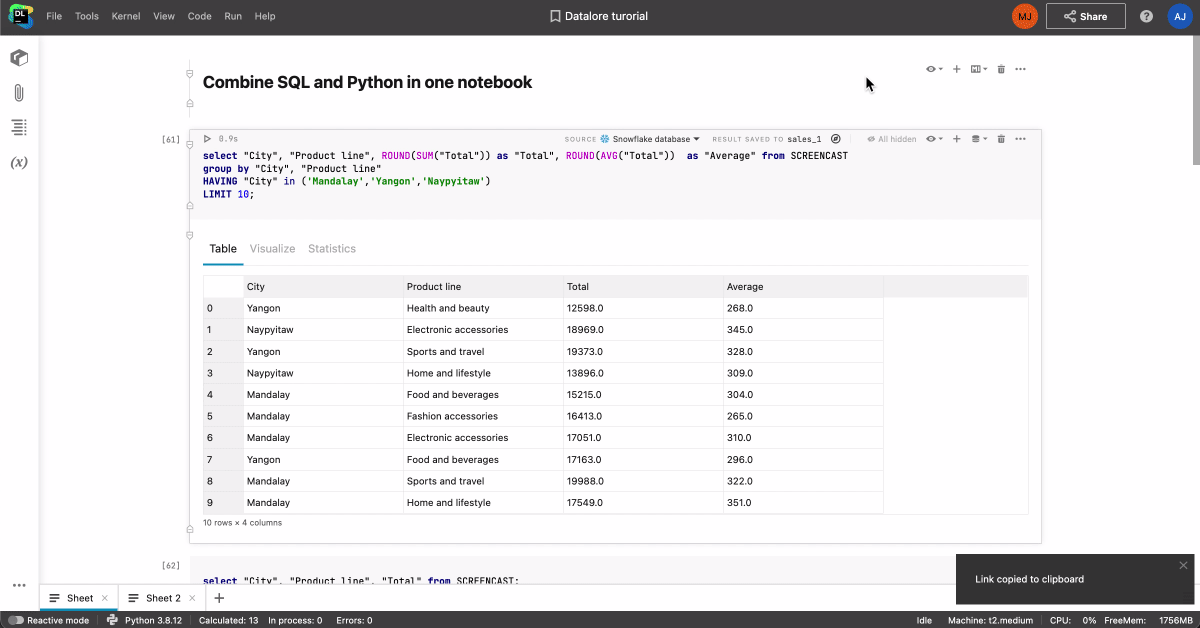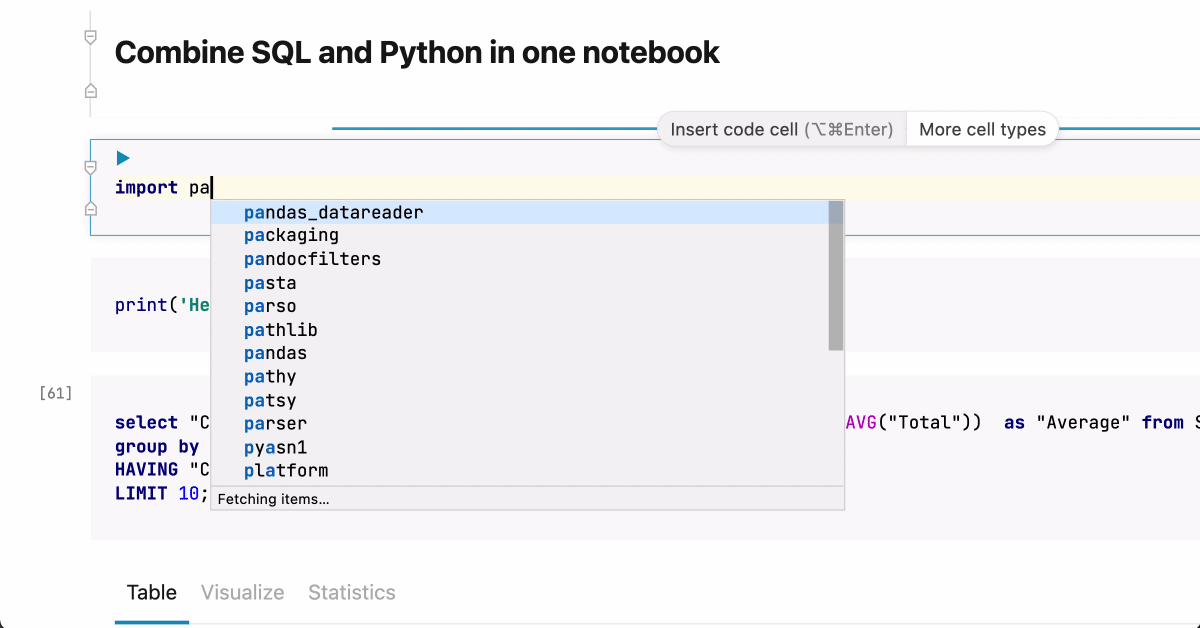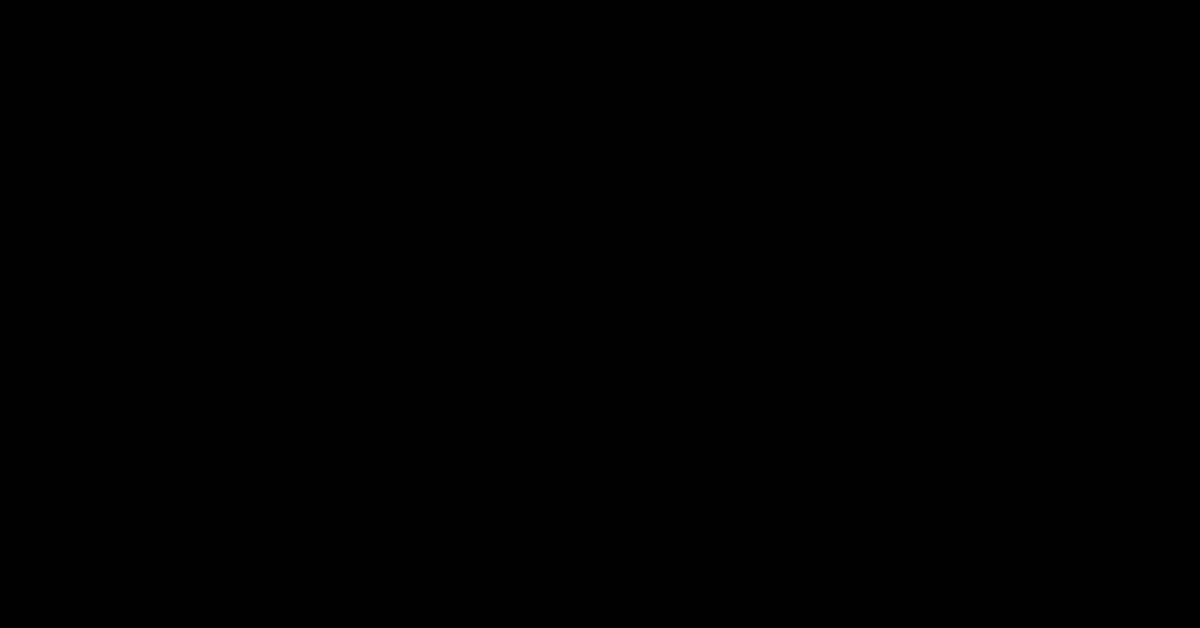
Avec Datalore, vous pouvez partager des notebooks et y donner accès en mode visualisation ou édition simplement via un lien ou une invitation par e-mail, et toutes les données jointes et les intégrations de données, l’environnement et les états de calculs sont automatiquement partagés. Cette méthode est particulièrement adaptée lorsque vous entraînez un modèle de machine learning ou de deep learning depuis longtemps et souhaitez pouvoir partager la progression en temps réel.
Datalore est une plateforme collaborative pour les équipes de science des données et de BI. Vous pouvez essayer Datalore Community et Datalore Professional en ligne, hébergés par JetBrains, ou installer Datalore Enterprise en tant que solution auto-hébergée dans votre cloud privé ou sur site.
Lorsque l’un de vos collaborateurs accède au notebook, vous voyez apparaître son icône et son curseur en temps réel. En cliquant sur son icône, vous pouvez commencer à le suivre automatiquement. Vous pouvez également collaborer en temps réel sur les scripts Python et les fichiers de données joints au notebook.
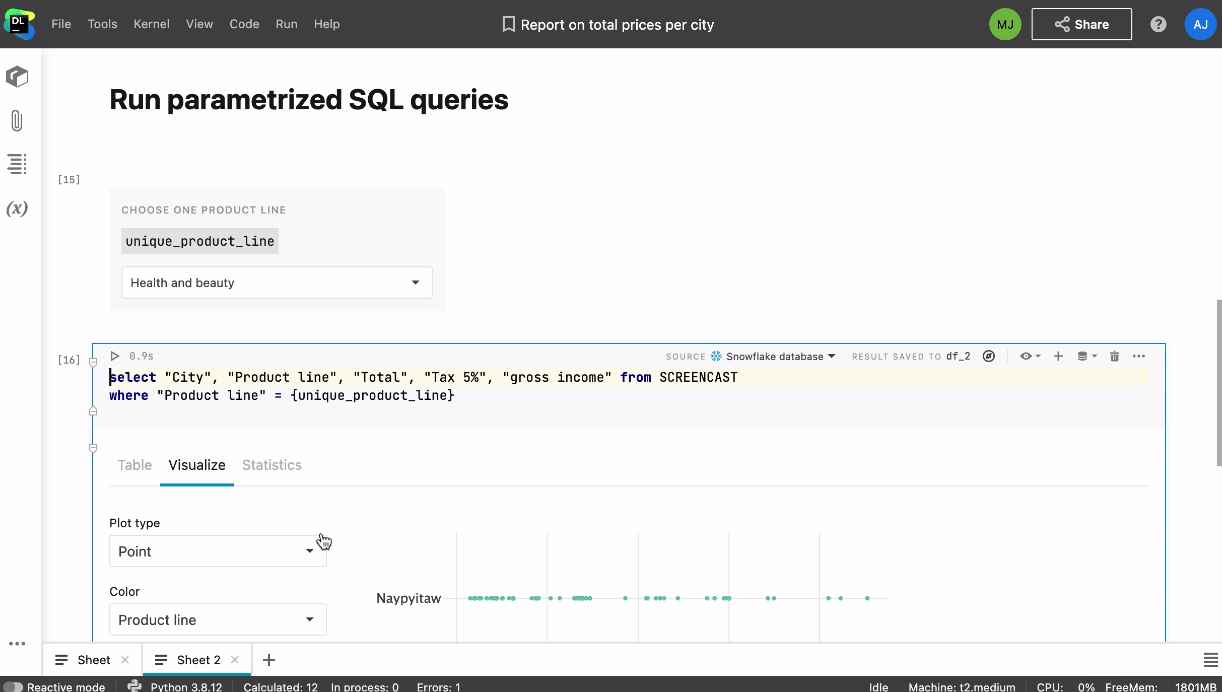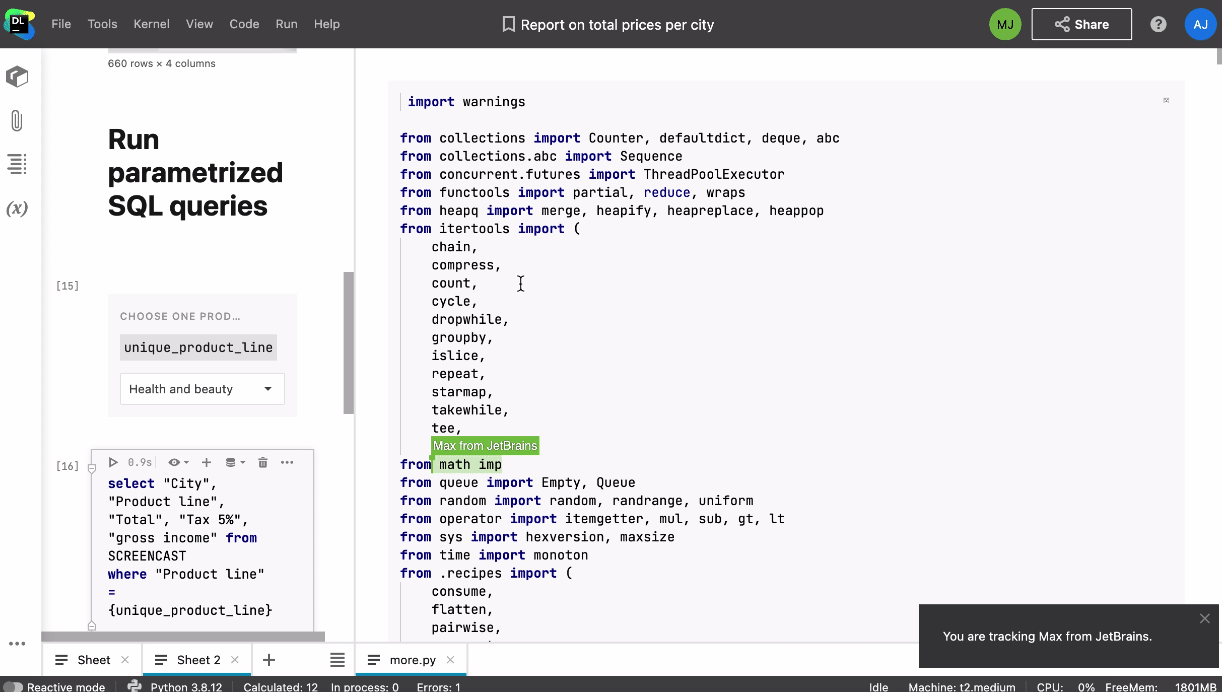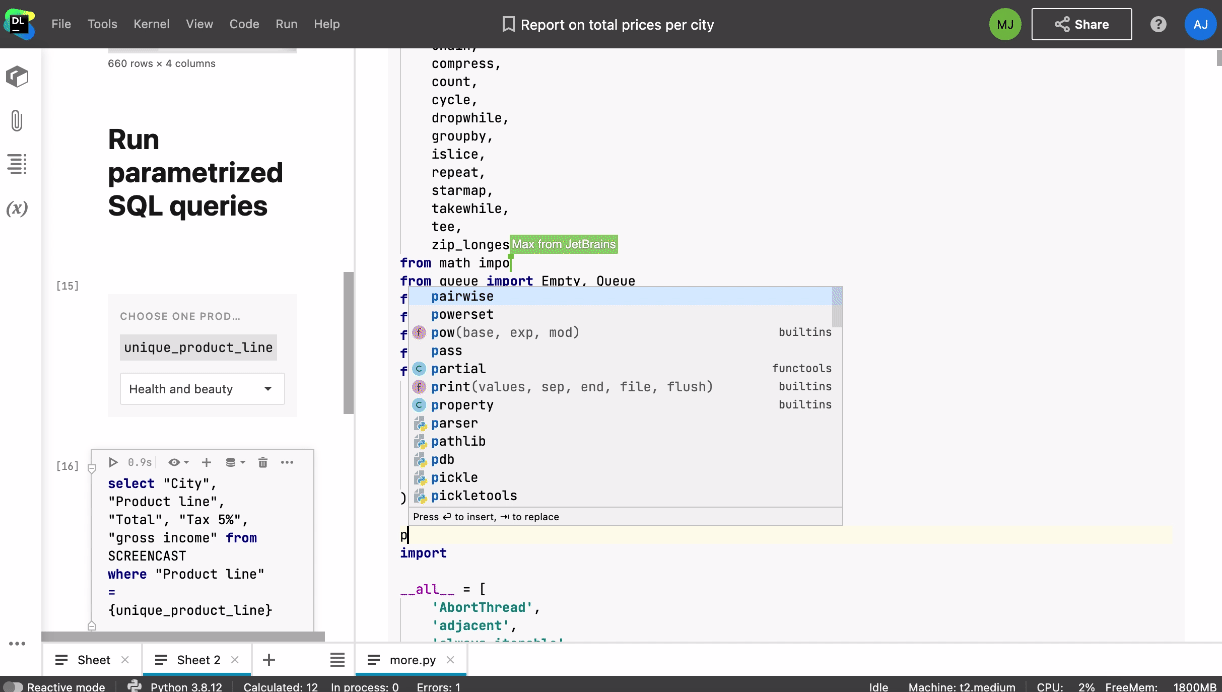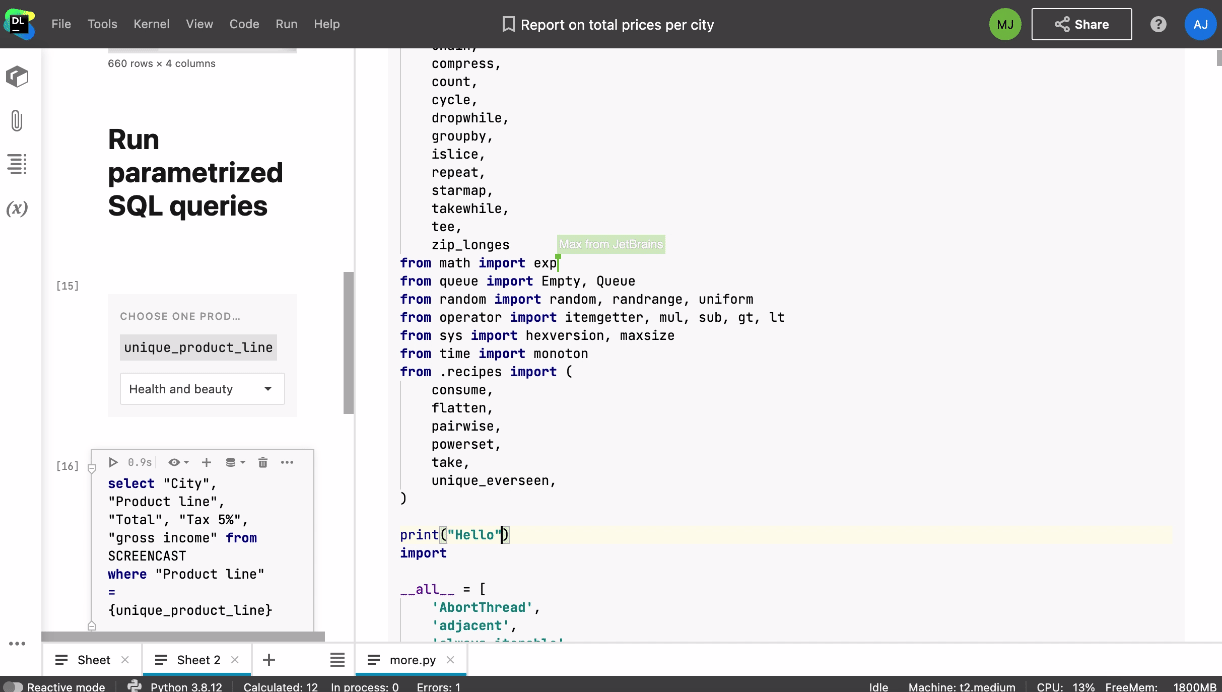
Il est possible d’accéder à un notebook partagé aussi bien en temps réel que lorsque les autres membres de l’équipe sont hors ligne. Vous n’avez pas vous soucier des conséquences modification dans le notebook car les actions sont enregistrées dans l’historique, ce qui permet d’effectuer un suivi continu des modifications et de revenir à un point de contrôle personnalisé ou automatique.
Si vous préférez utiliser des notebook Jupyter open source, vous pouvez les partager par un lien et collaborer en temps réel après avoir installé un plugin Yjs sur votre serveur. Cependant, ce plugin ne permet pas de gérer les rôles et autorisations, ne propose pas de suivi des collaborateurs et des différences de versions en temps réel, et vos mots de passe de base de données ou autres informations d’identification sont exposés et peuvent être récupérés par les membres de votre équipe.
Demander un essai gratuit de 30 jours
Créer une base de connaissances pour les projets de science des données
Si les membres de votre équipe effectuent souvent des tâches répétitives, vous pouvez créer une base de connaissances avec des modèles de notebook. C’est un moyen simple d’éviter de réinventer un processus qu’un collègue a déjà développé.
Dans Datalore, vous pouvez créer un espace de travail partagé pour votre équipe et stocker tous vos modèles de notebooks et ensembles de données essentiels. Grâce à la configuration tout-en-un de Datalore, ces modèles peuvent inclure un environnement configuré, des descriptions Markdown appropriées, un code de modèle documenté, et même une connexion à une base de données ou à un stockage cloud pertinent. Les data scientists peuvent ensuite cloner ces notebooks sur leurs espaces de travail personnels et commencer à les exploiter.
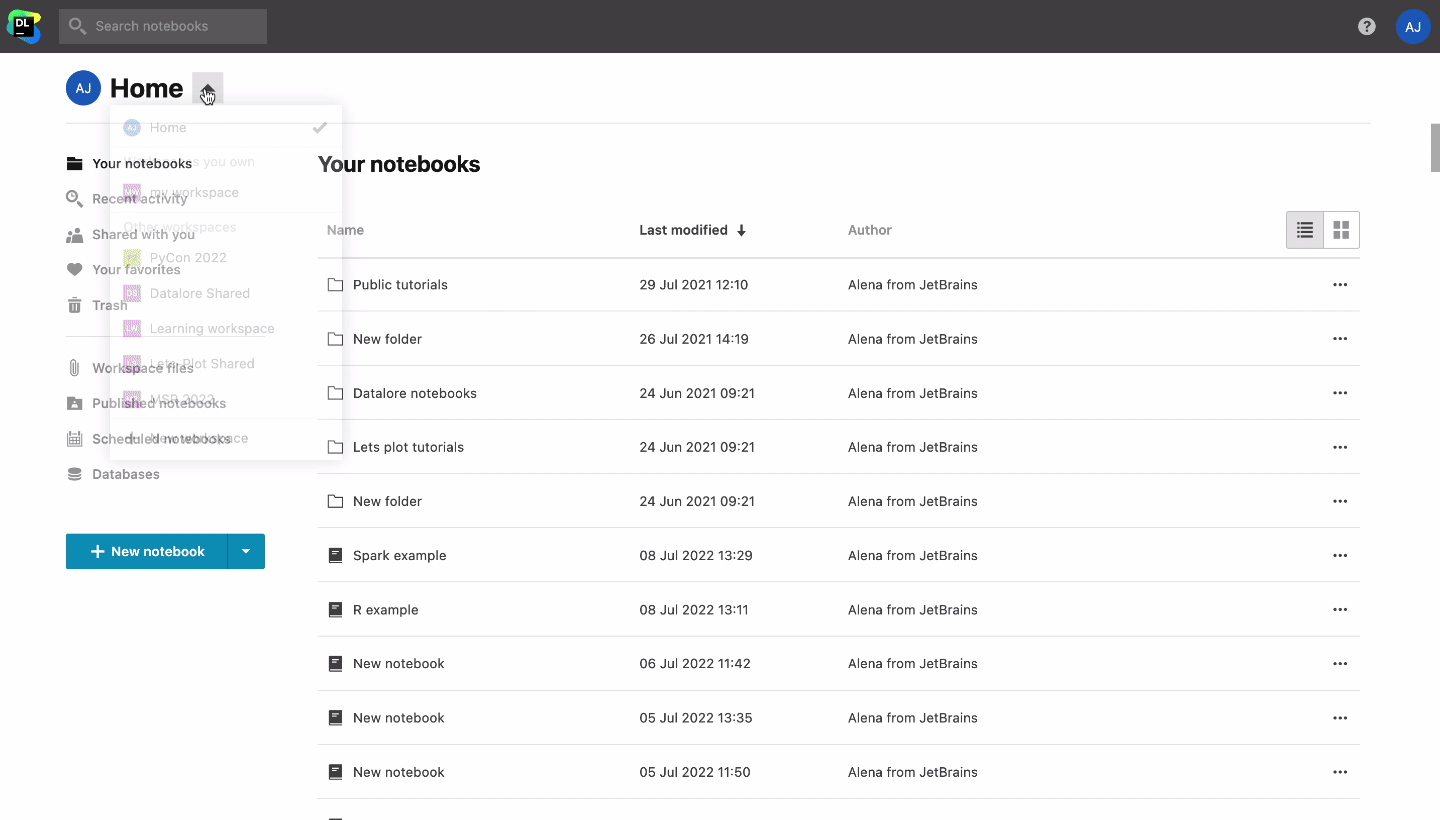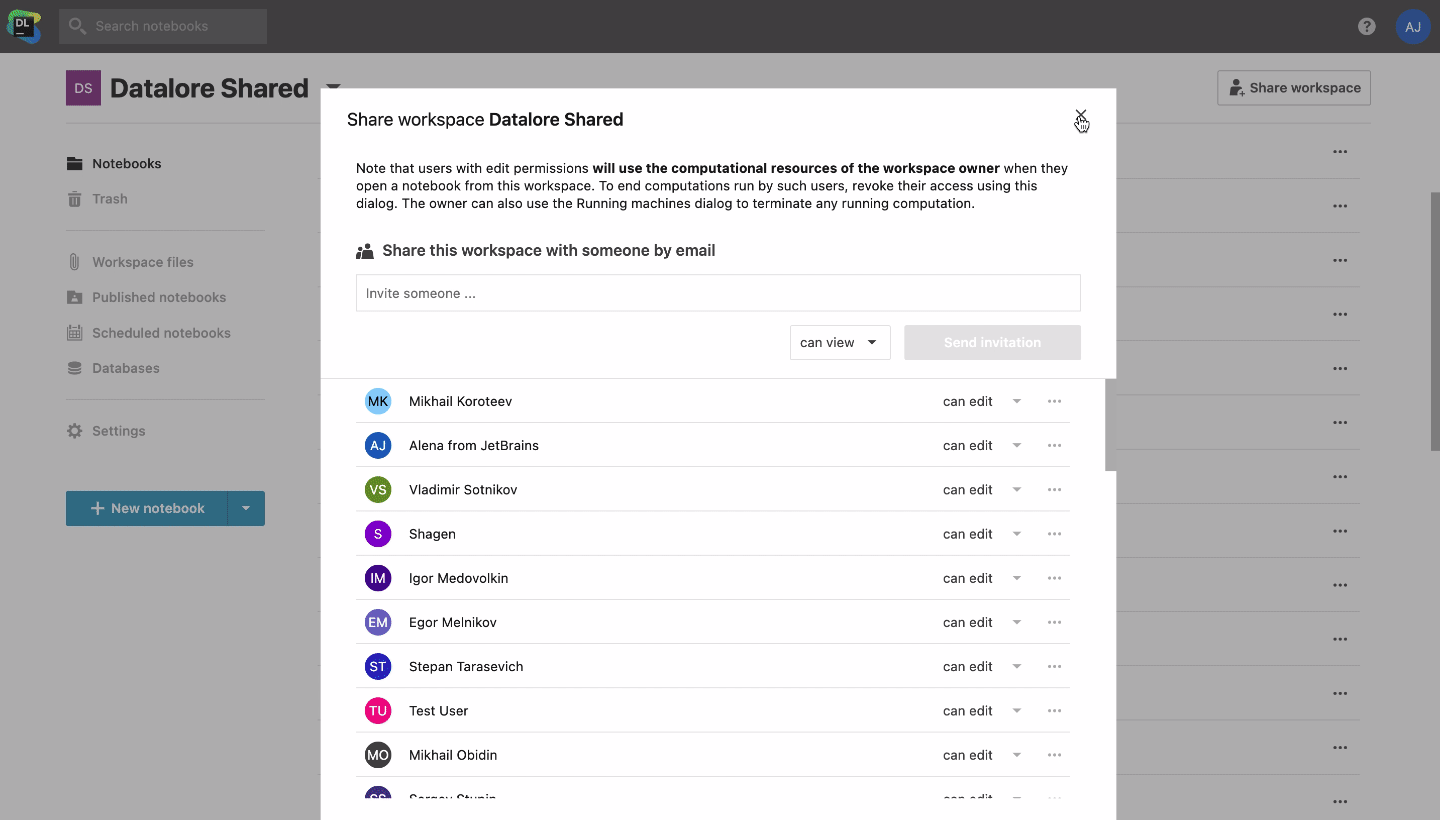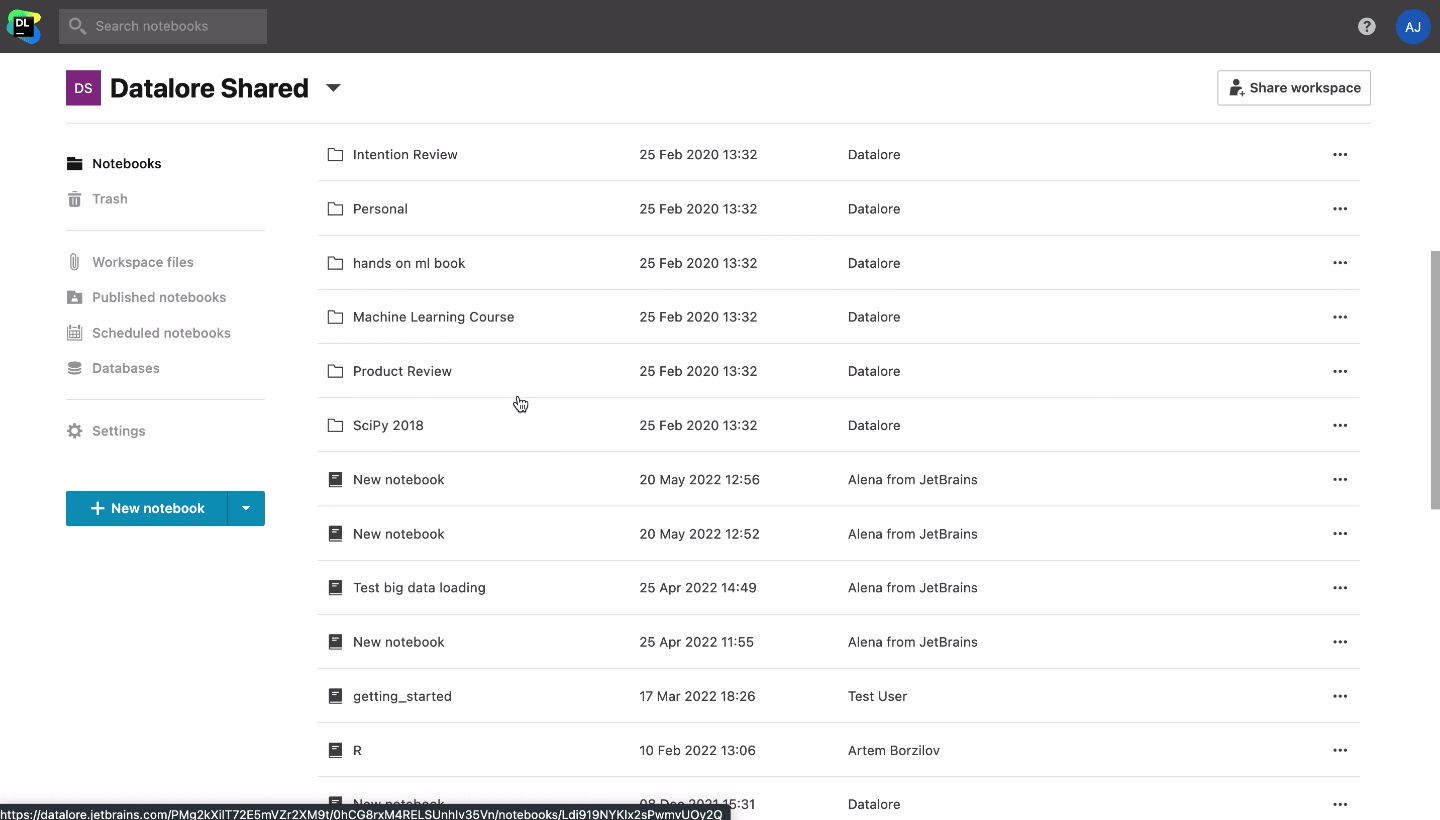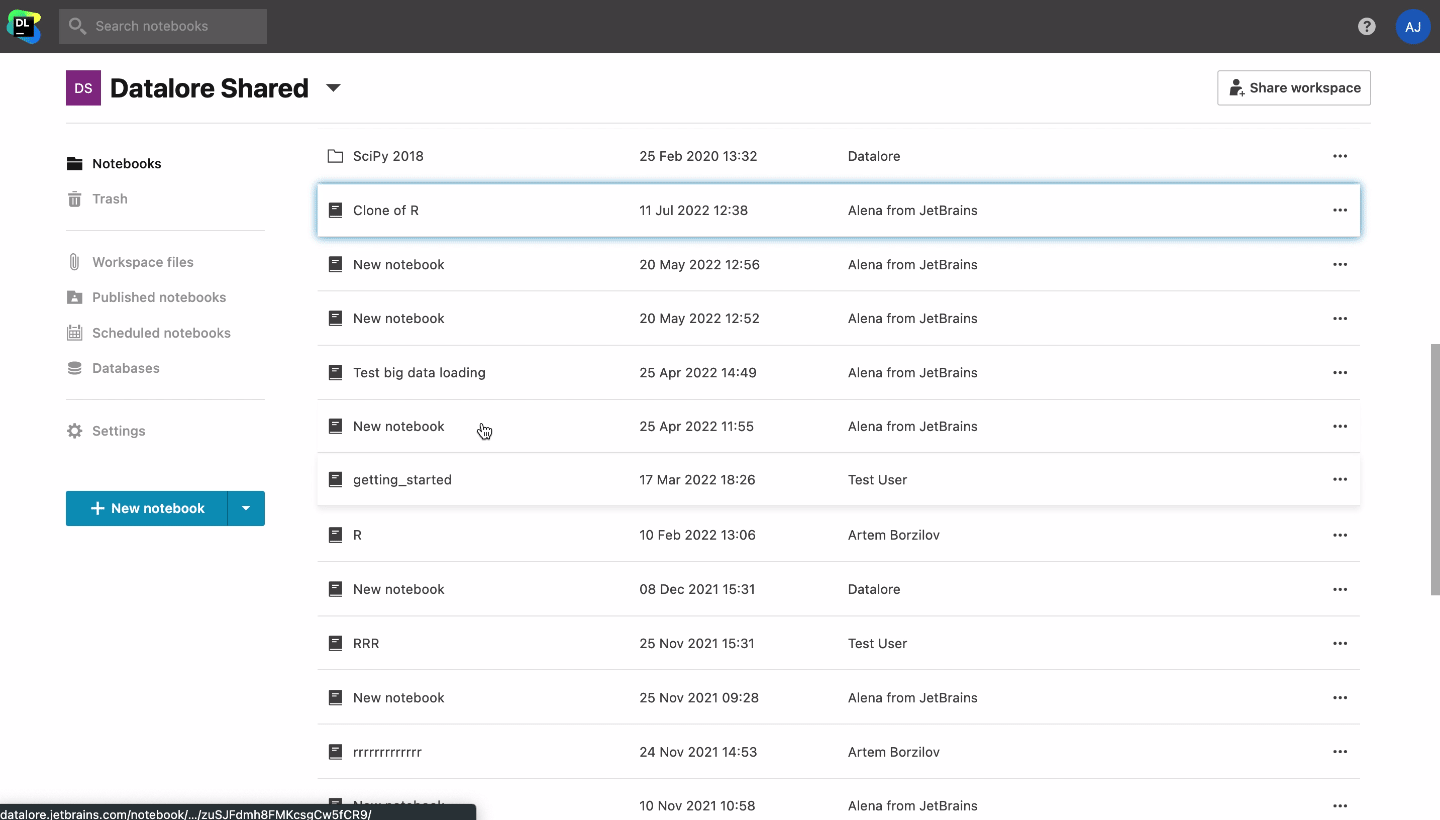
L’existence d’une base de connaissances facilite également l’intégration des nouveaux membres à l’équipe, car tous les ensembles de données, notebooks et configurations d’environnement essentiels sont disponibles au même endroit.
Écrire du code en pensant à la reproductibilité
Comprendre le code de quelqu’un d’autre peut être difficile, mais résoudre les bugs de vos collègues est encore plus compliqué. Vous trouverez ci-dessous une brève checklist à utiliser pour favoriser la reproductibilité :
- Faites une description tous les 2 ou 3 blocs de code avec une cellule Markdown.
- Cliquez sur « Run all » et assurez-vous que le notebook est recalculé sans erreur avant de publier votre travail sous forme de rapport ou de le placer dans un espace de travail partagé. Vous pouvez aussi utiliser Reactive mode dans Datalore pour rendre l’état du notebook cohérent. Vous pouvez en lire plus à ce sujet ici.
- Partagez l’environnement et les données avec le notebook. Datalore gère cette étape par défaut, mais vous devez le faire explicitement si vous utilisez Jupyter en open source.
Si la reproductibilité est importante pour vous, nous vous invitons à regarder l’enregistrement de ce webinaire dans lequel Jodie Burchell partage ses conseils pour une recherche reproductible.
Communiquer efficacement les résultats pour favoriser les décisions fondées sur les données dans toute l’entreprise
Si les notebooks sont idéaux pour effectuer des recherches en science des données, ils ne sont pas le moyen le plus efficace de communiquer des résultats.
Les notebooks bruts contenant des morceaux de code volumineux comprennent beaucoup d’informations non pertinentes pour d’autres parties prenantes du projet, qu’elles aient un profil technique ou non. En général, ils veulent juste savoir ce que vous avez fait, pourquoi vous l’avez fait et quelles sont vos conclusions.
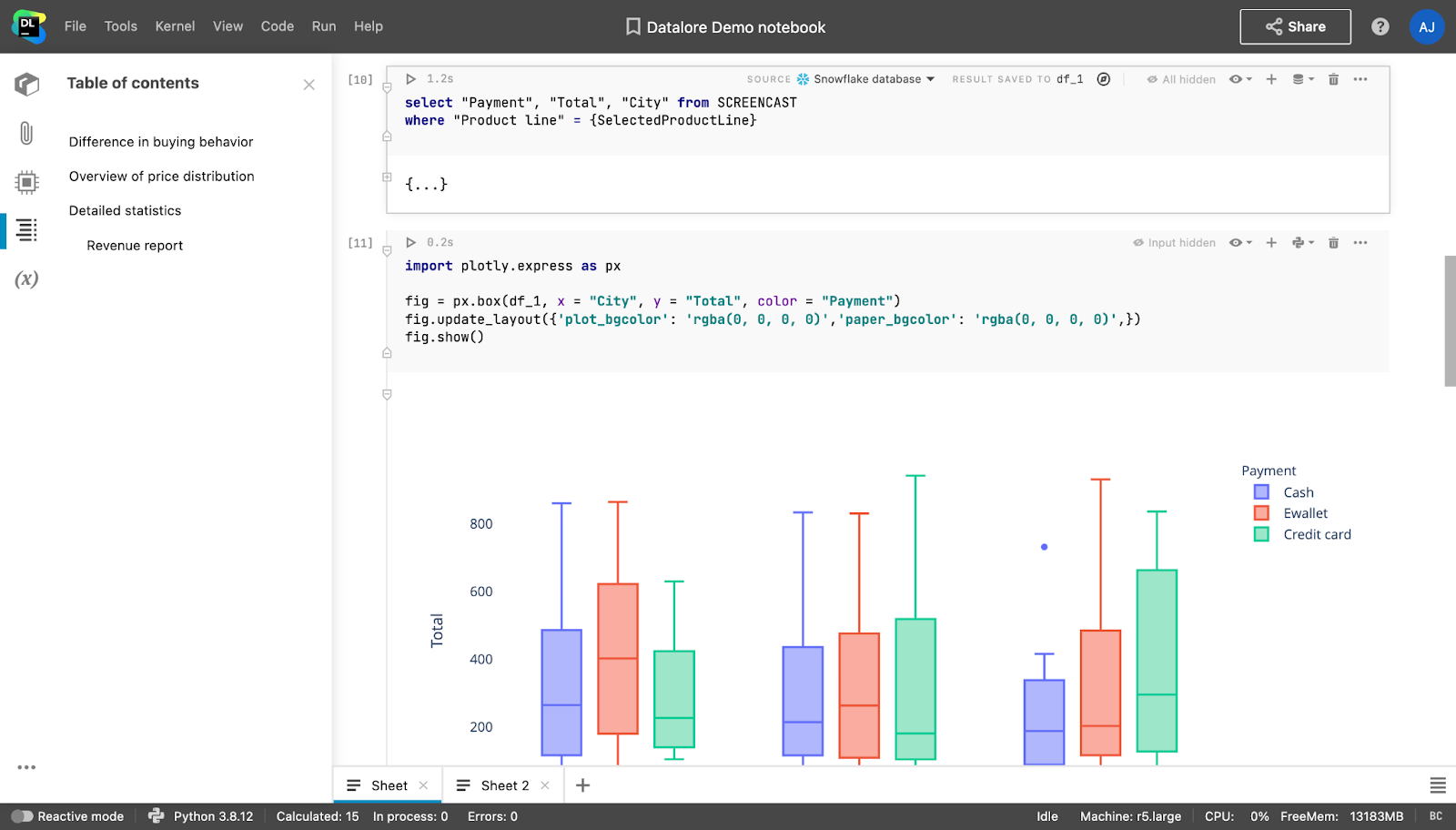
Toutefois, la création de rapports à l’aide d’outils tels que Tableau ou Power BI, ou de packages de création de tableaux de bord comme Dash/Streamlit (Python), Shiny (R), ou avec Google Docs/Microsoft Word, représente un travail supplémentaire considérable. Cela supprime également la connexion entre le notebook et le rapport, ce qui signifie que toute modification apportée au notebook doit être mise à jour manuellement dans le rapport.
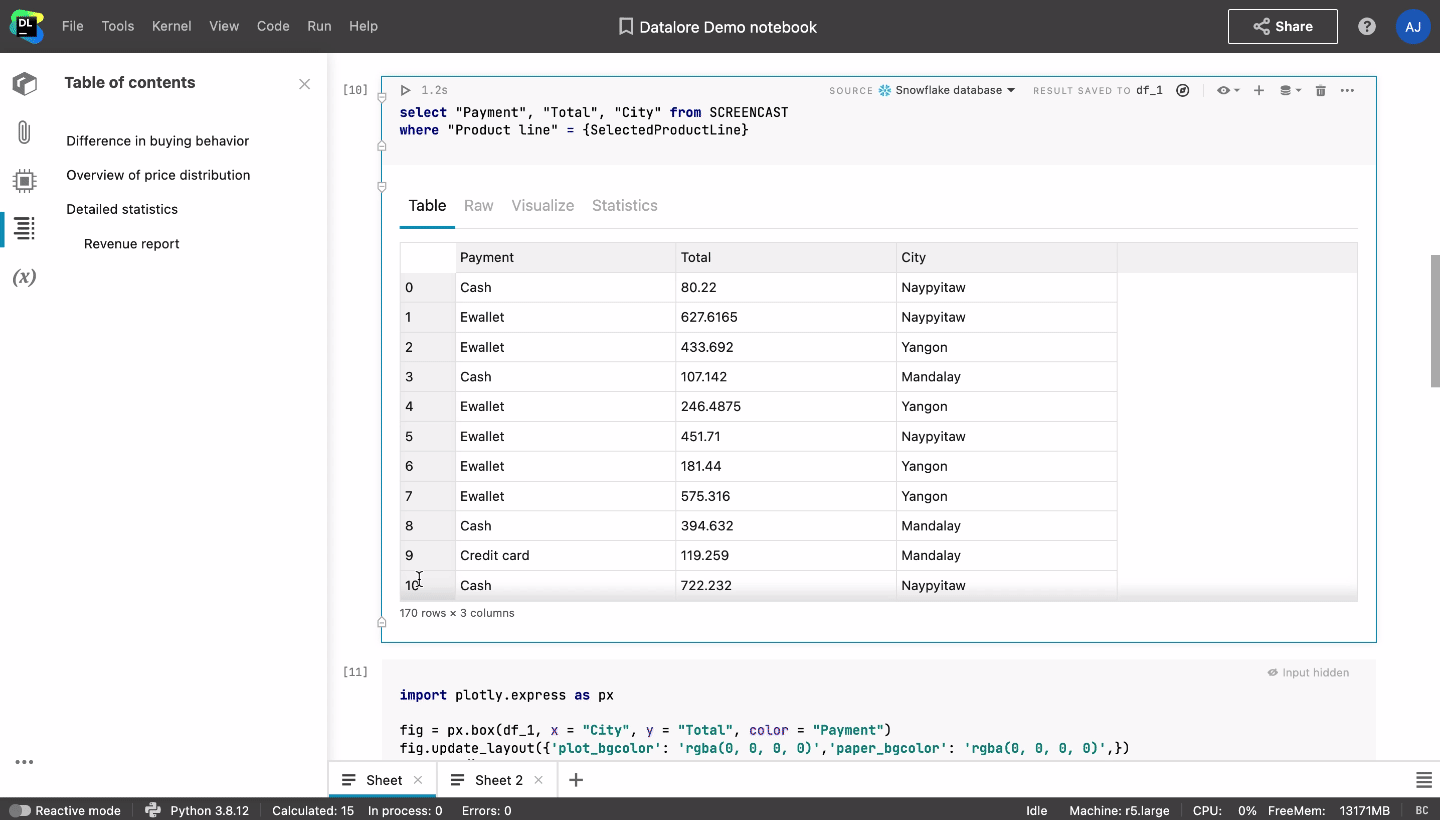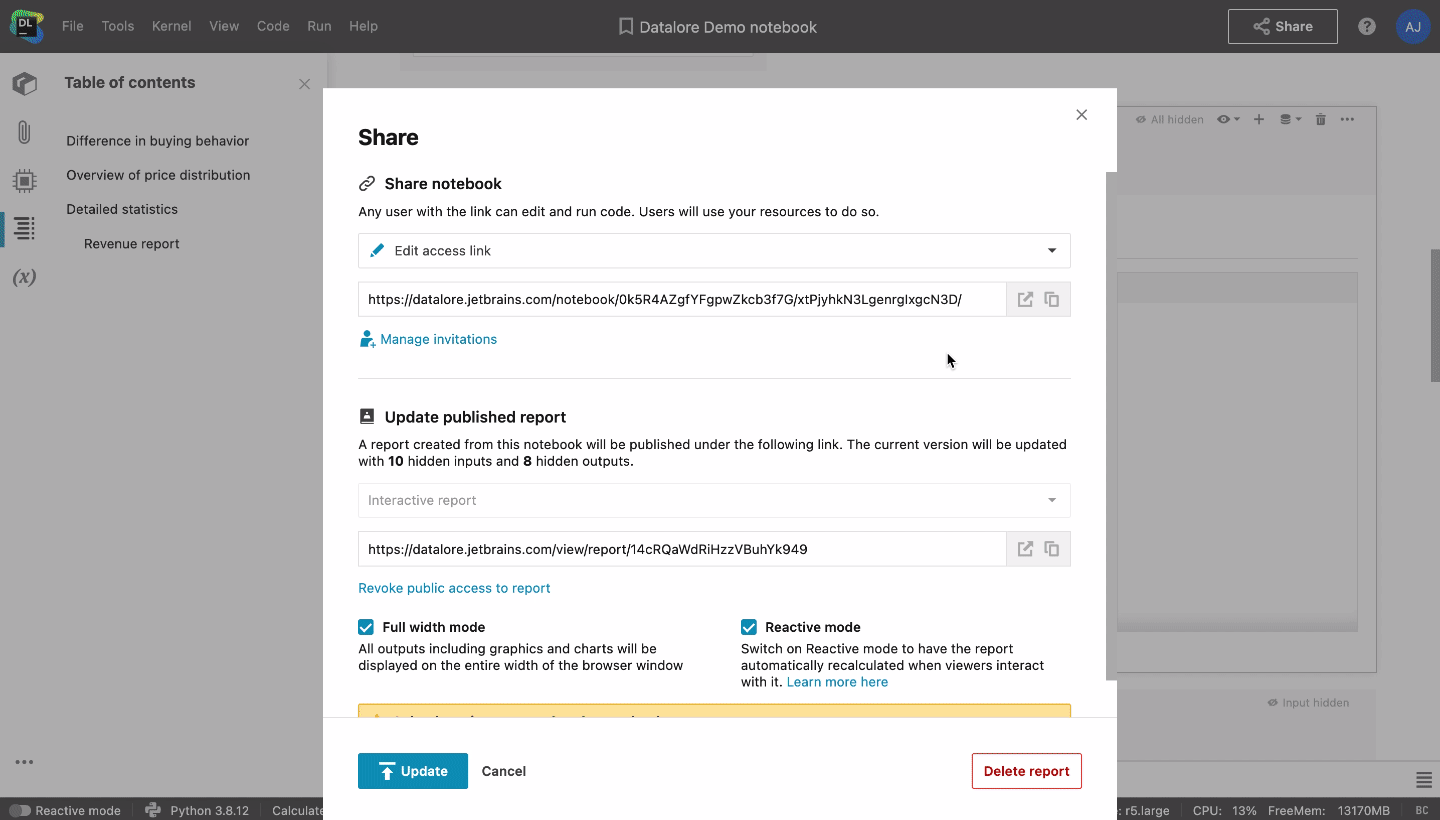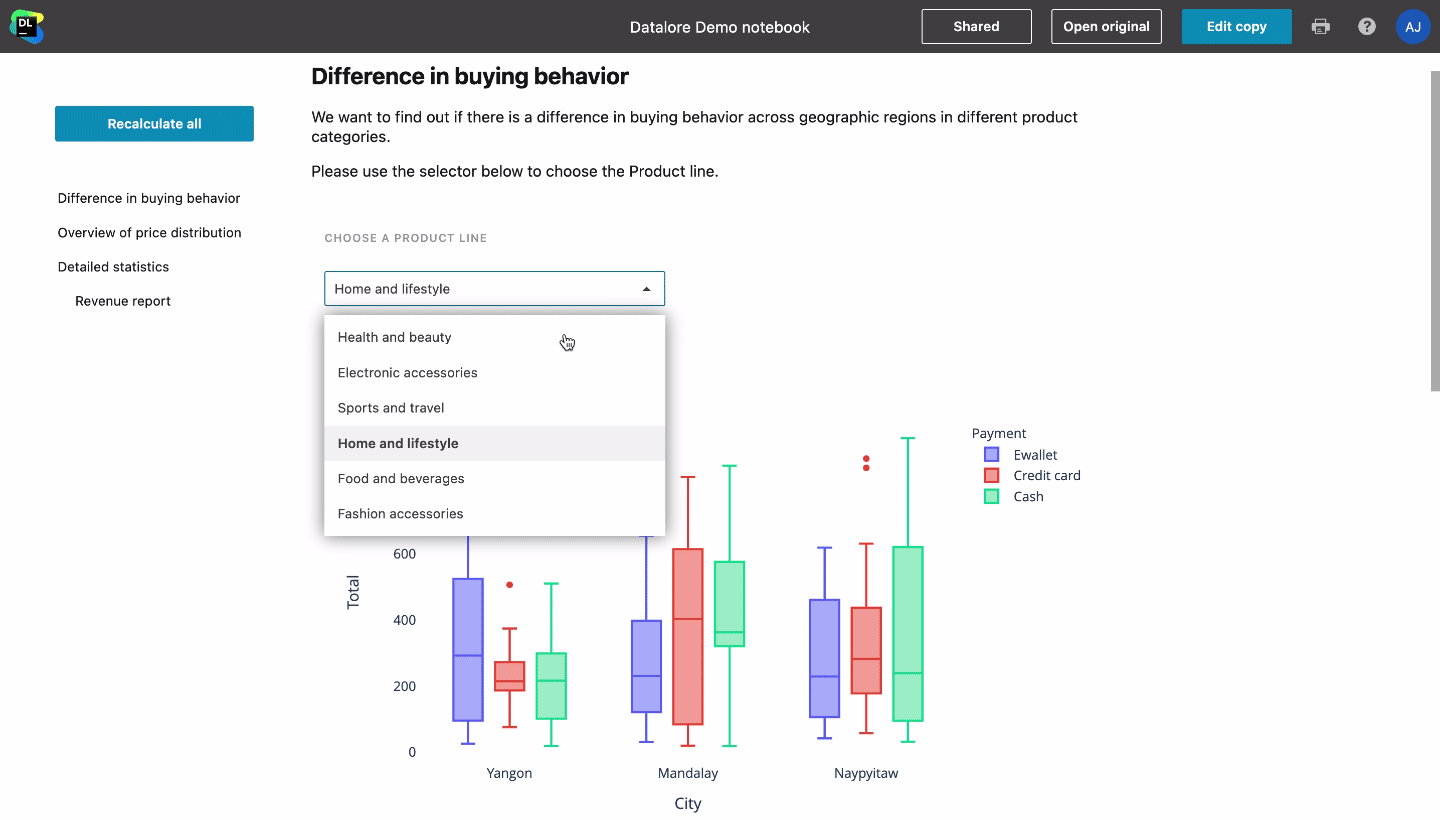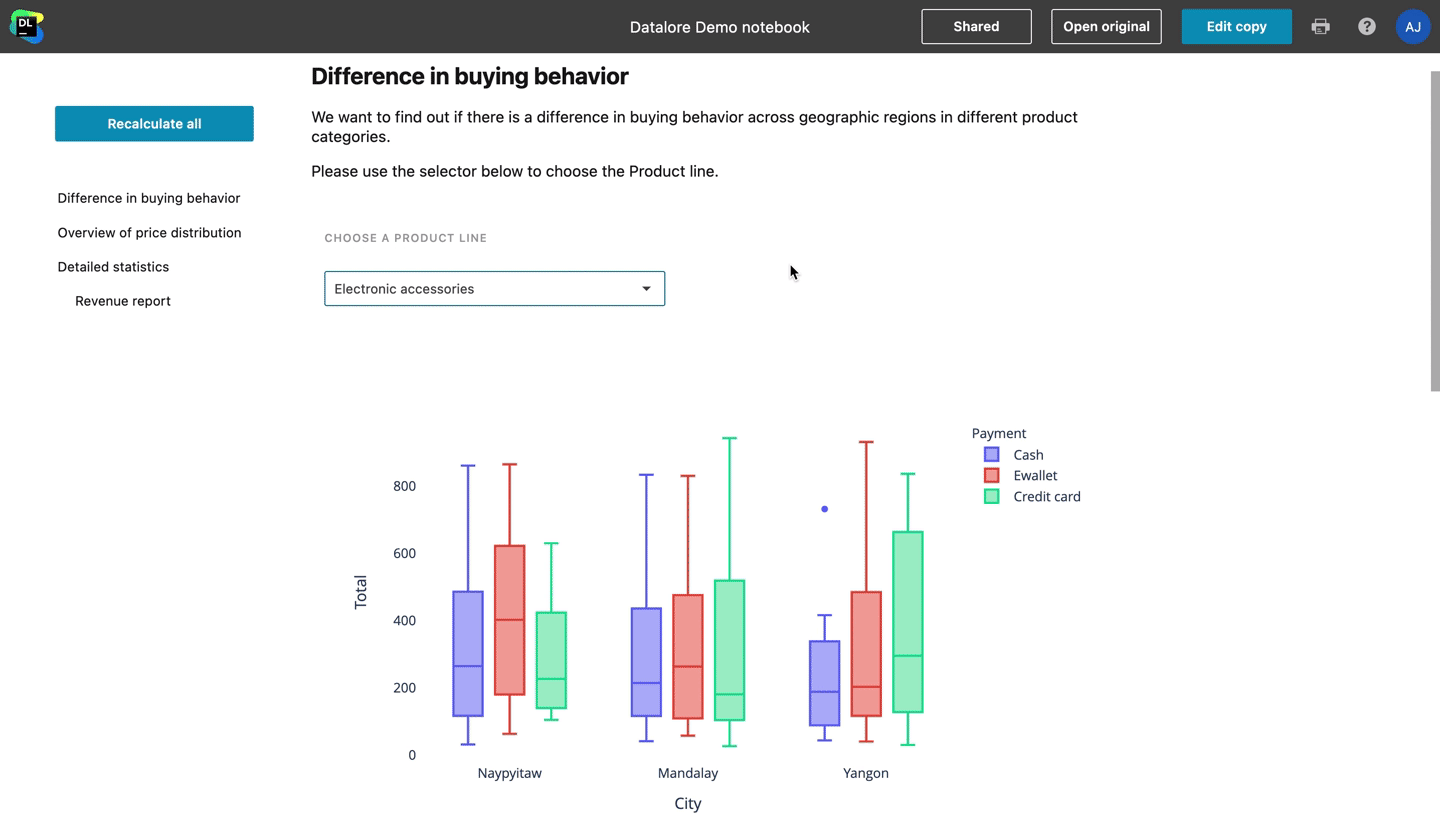
Ces problèmes peuvent être facilement résolus avec Datalore. Les notebooks peuvent y être directement convertis en rapports et vous avez la possibilité de masquer autant d’entrées et de sorties d’un notebook que vous le souhaitez. Les parties prenantes peuvent accéder à ces rapports sans avoir de compte Datalore et interagir avec les listes déroulantes, les curseurs et les diagrammes. Si les parties prenantes disposent d’un compte Datalore et de connaissances de base en Python ou SQL, elles pourront se plonger dans l’analyse en modifiant une copie du rapport.
Du local au cloud
Vous utilisez des notebooks Jupyter installés localement ? Consultez le tableau comparatif ci-dessous afin de connaître les raisons pour lesquelles vous devriez envisager de passer à une plateforme cloud.
| Jupyter local, installé individuellement. | Plateforme cloud, hébergée par votre entreprise ou par un fournisseur SaaS. | |
| Collaboration | Uniquement via Git. La connexion aux données et aux environnements peut être perdue, vous pouvez oublier de valider le dernier état du projet, et envoyer les notebooks avec les sorties peut créer davantage d’encombrement dans le référentiel Git. | Collaboration en temps réel sur les notebooks et les espaces de travail partagés, avec tous les artefacts joints (disponibles dans Datalore). |
| Travail avec le big data | L’extraction de données volumineuses du serveur prend beaucoup de temps et votre machine locale risque de manquer de mémoire. | Vous pouvez faire évoluer la machine sur le cloud et extraire les données sans avoir à dépendre de la vitesse de l’internet. |
| Intégration des nouveaux membres de l’équipe | Chaque nouvel arrivant passe du temps à installer Jupyter, à configurer l’environnement et à extraire des données par lui-même. | Accès en un clic aux projets de l’équipe, avec tout le nécessaire préinstallé. |
| Accès aux machines de calcul | Nécessité de démarrer une machine manuellement et de s’y connecter via SSH. | Facilité d’exécution des calculs sur des serveurs puissants en un clic. |
| Configuration de l’environnement | Chaque utilisateur a des environnements différents, ce qui peut être difficile à gérer. Un nouveau paquet peut nuire à toute l’application et le débogage sera difficile. | Les équipes peuvent créer plusieurs environnements de base avec des dépendances préinstallées. L’application ne sera pas affectée car l’environnement de chaque notebook est isolé. |
Comment puis-je essayer Datalore pour améliorer la collaboration dans mon équipe de science des données ?
Si vous souhaitez essayer Datalore pour votre équipe, vous pouvez opter pour un hébergement cloud privé ou sur site avec le forfait Enterprise. Apprenez-en plus sur Datalore Enterprise et demandez un essai gratuit :
Demander un essai gratuit de 30 jours
Si vous souhaitez utiliser Datalore pour vous-même ou l’essayer rapidement dans le cloud, vous pouvez opter pour les forfaits Datalore Community ou Professional, hébergés par JetBrains.
C’est tout pour le moment ! Suivez notre blog pour plus de conseils et sur Twitter pour nos dernières actualités !
Bonne collaboration !
L’Équipe Datalore
Article original en anglais de :



