

Datalore
Collaborative data science platform for teams
5 Ways to Collaborate Effectively as a Data Science Team
Data science projects can be complex, consisting of many parts, such as notebooks, data, environments, and scripts, and it can be challenging for data science teams to effectively work together on them.
In this post, you will learn 5 modern collaboration techniques for data-driven teams to improve productivity and lower stress.

Share code and essential artifacts easily
Collaboration on data science projects is prone to fail right from the beginning, simply because it is so cumbersome to share materials with other team members. Sharing a Jupyter notebook requires you to share a boatload of context as well: the specific environment, data, and data connections. And that seems like overkill when all you need is help with a data transformation. Wouldn’t it be great if sharing Jupyter notebooks were as easy as sharing Google Docs?
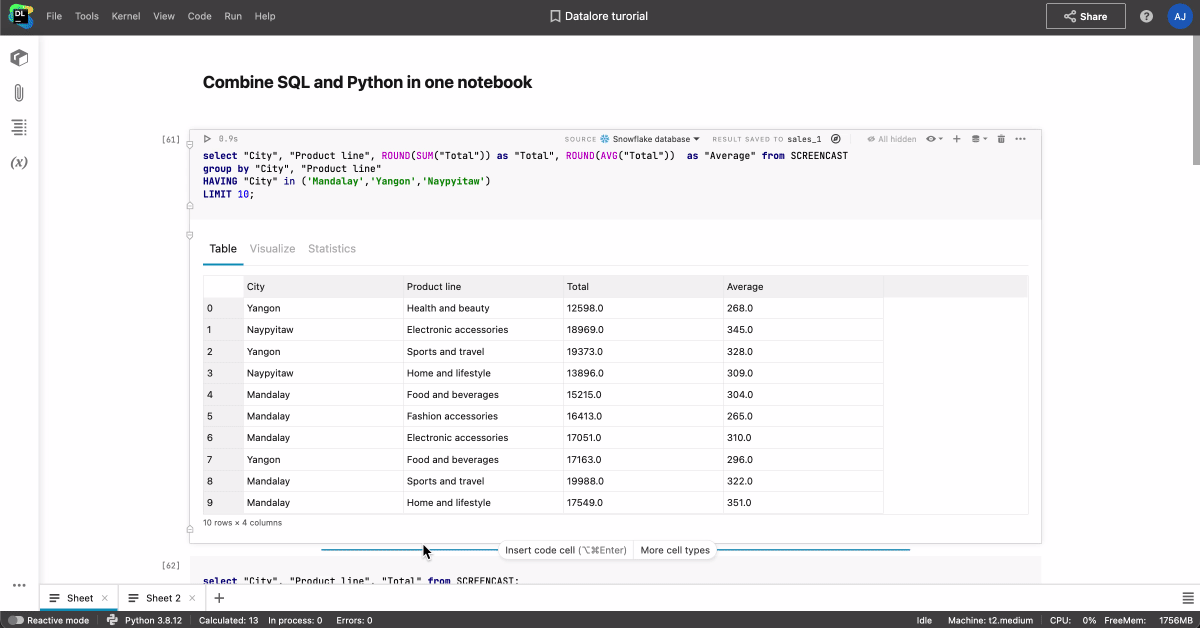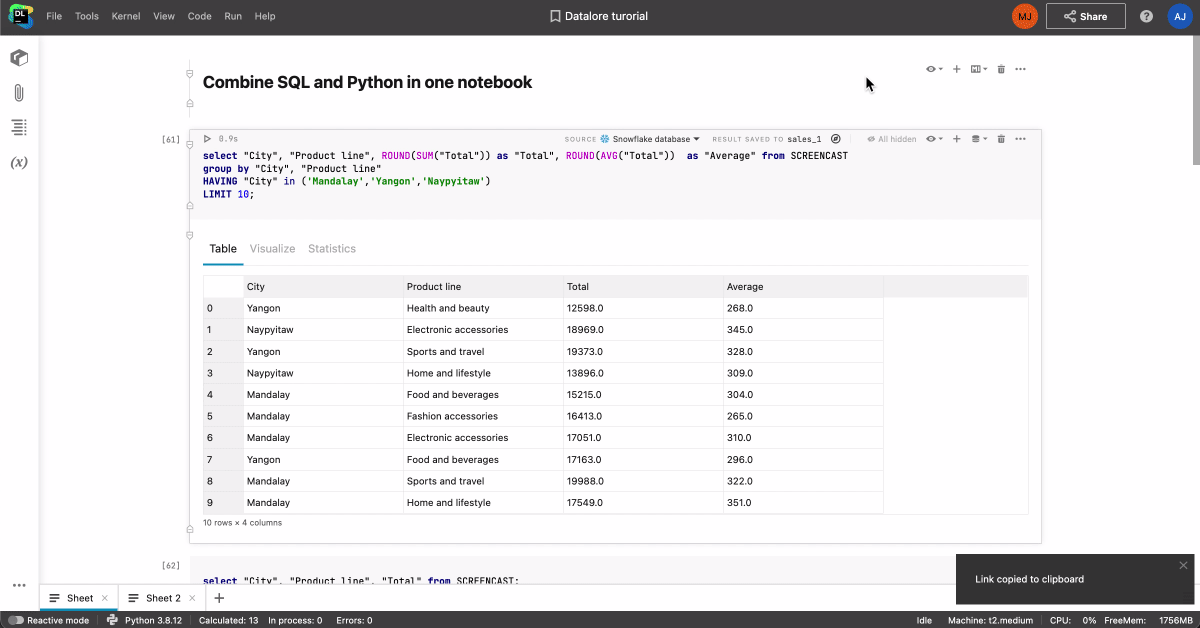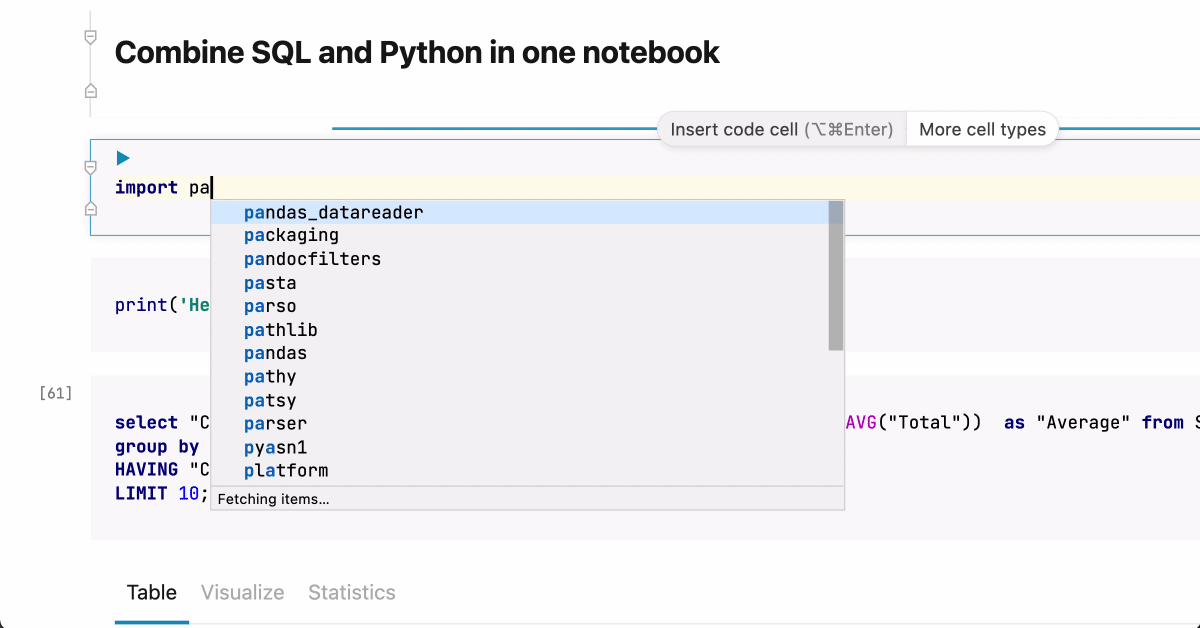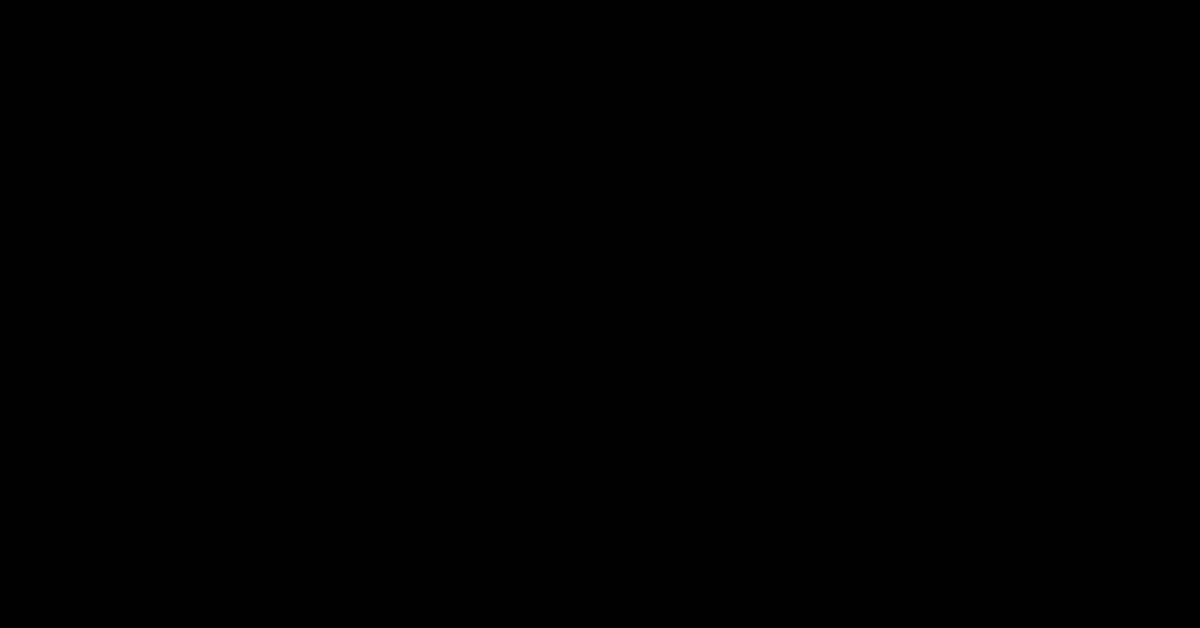
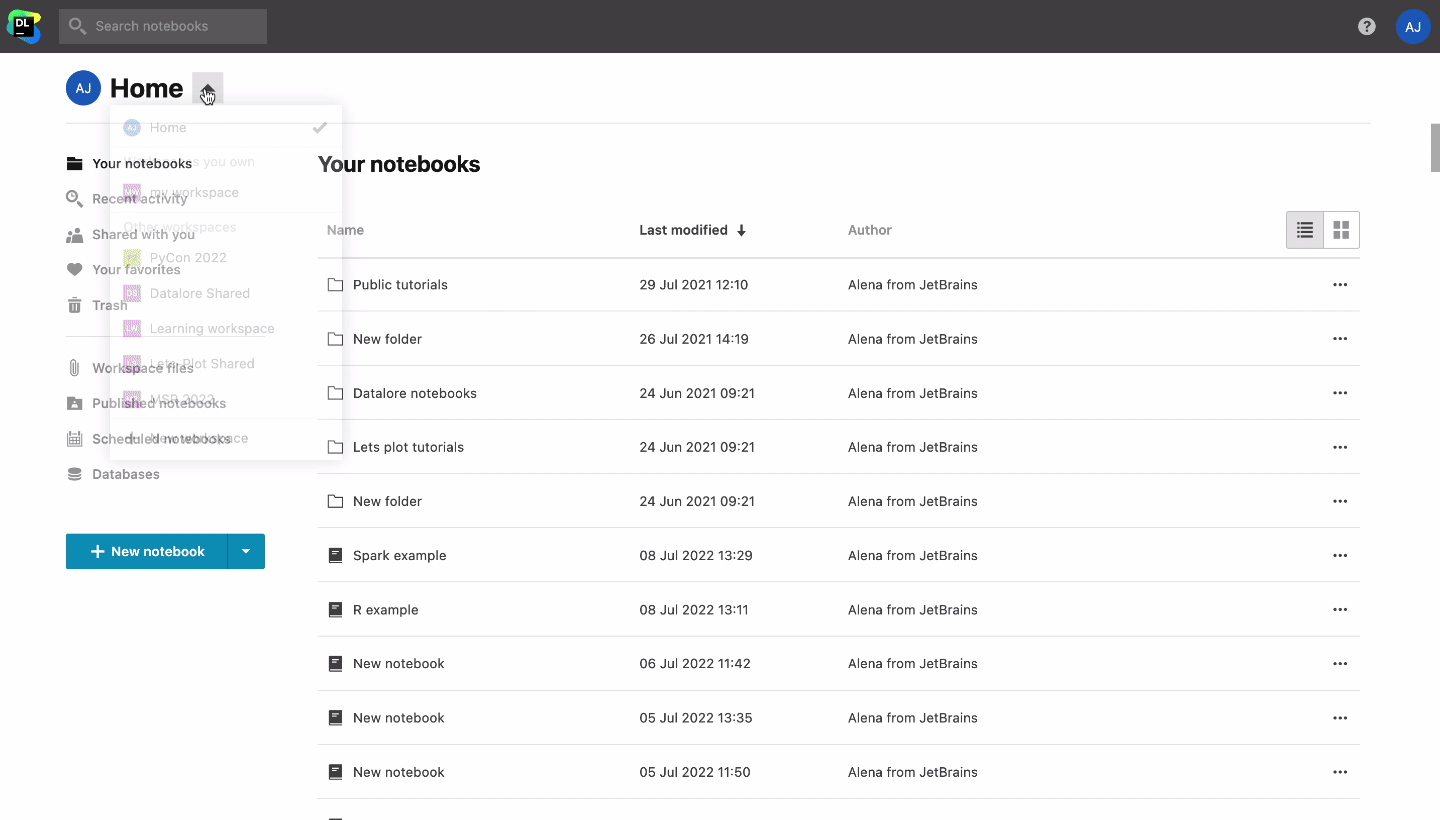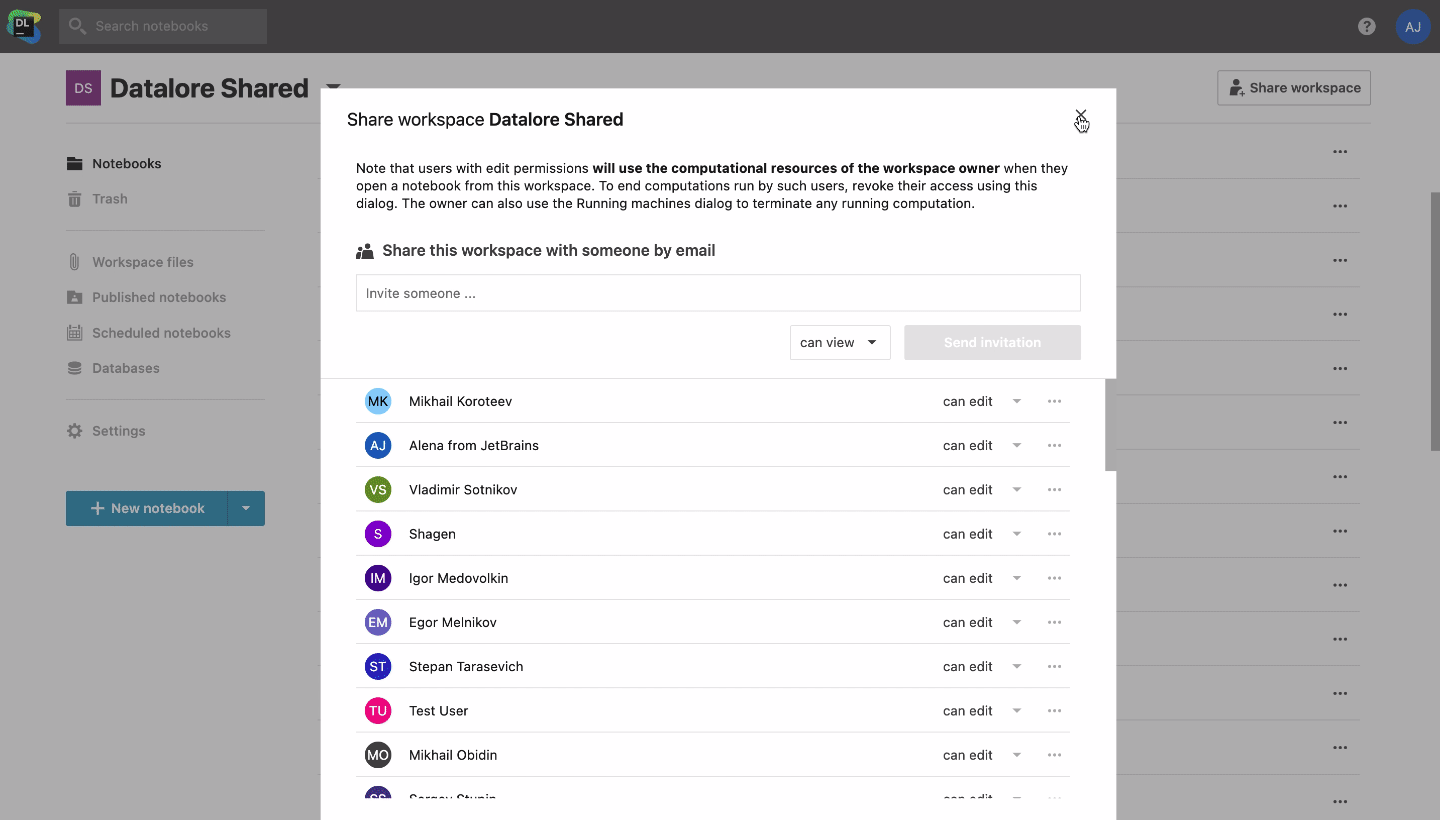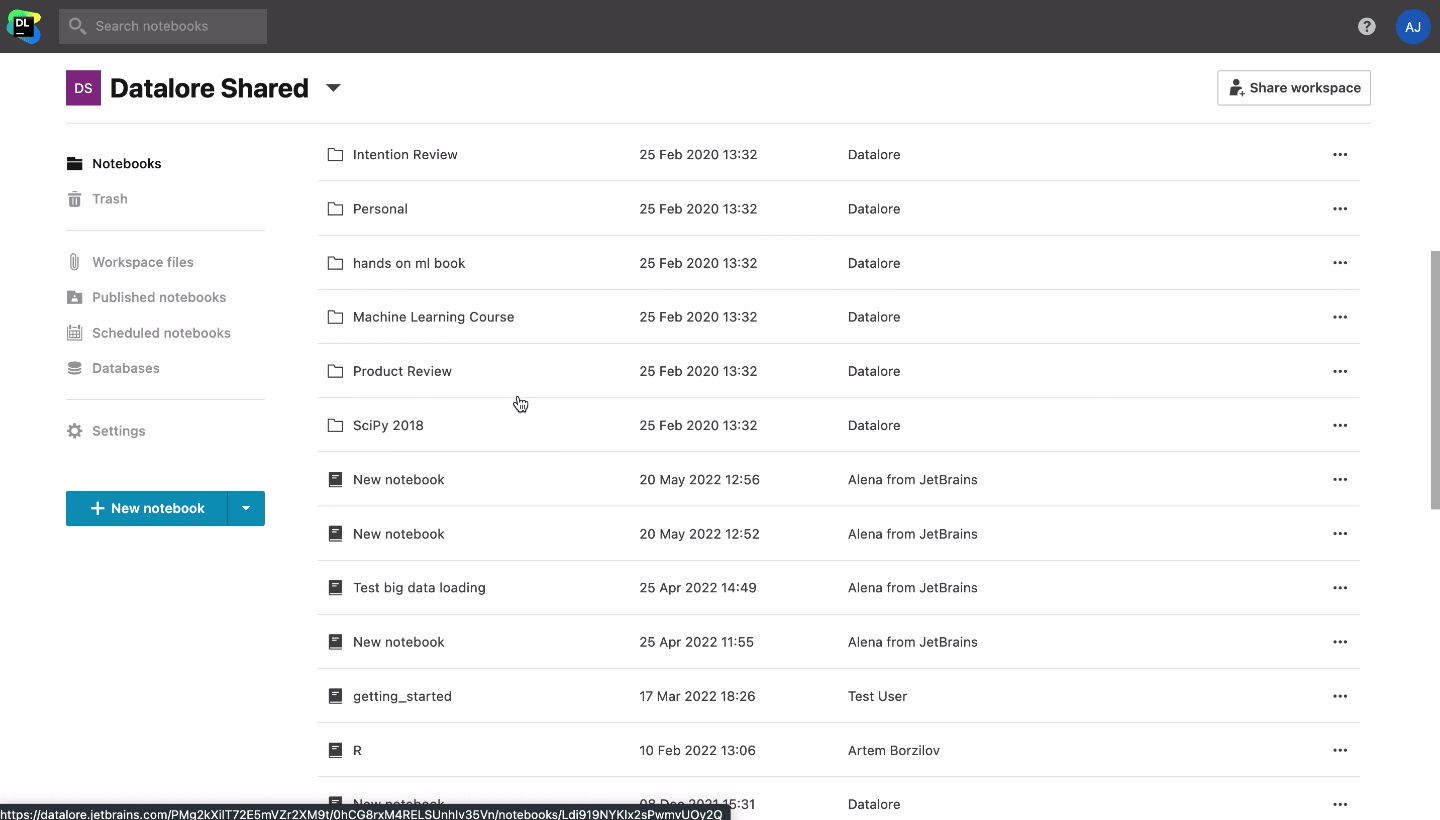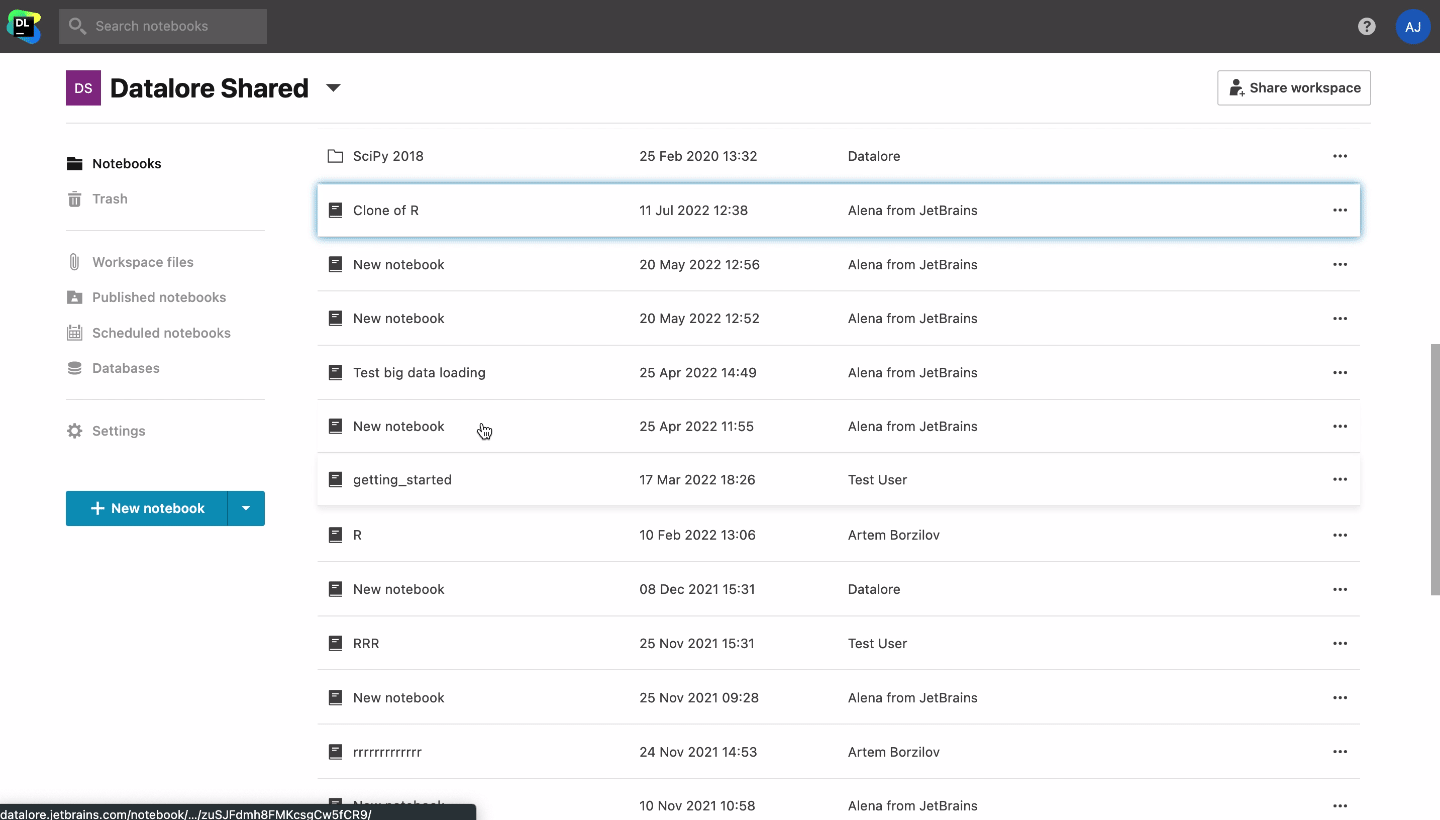
With Datalore, you can share notebooks with either view or edit access simply via link or email invitation, and all of the attached data and data integrations, environment, and computation states will be shared automatically. This could be particularly handy when you’ve been training a machine learning or deep learning model for a long time and want to share your progress in real-time.
Datalore is a collaborative data science and BI platform for teams. You can try Datalore Community and Datalore Professional online, hosted by JetBrains, or you can install Datalore Enterprise as a self-hosted solution in your private cloud or on-premises.
When your colleague enters the notebook, you will see their icon and cursor in real time. By clicking on their icon, you’ll be able to start tracking and following along with them automatically. You can also collaborate in real time on Python scripts and data files attached to the notebook as well.
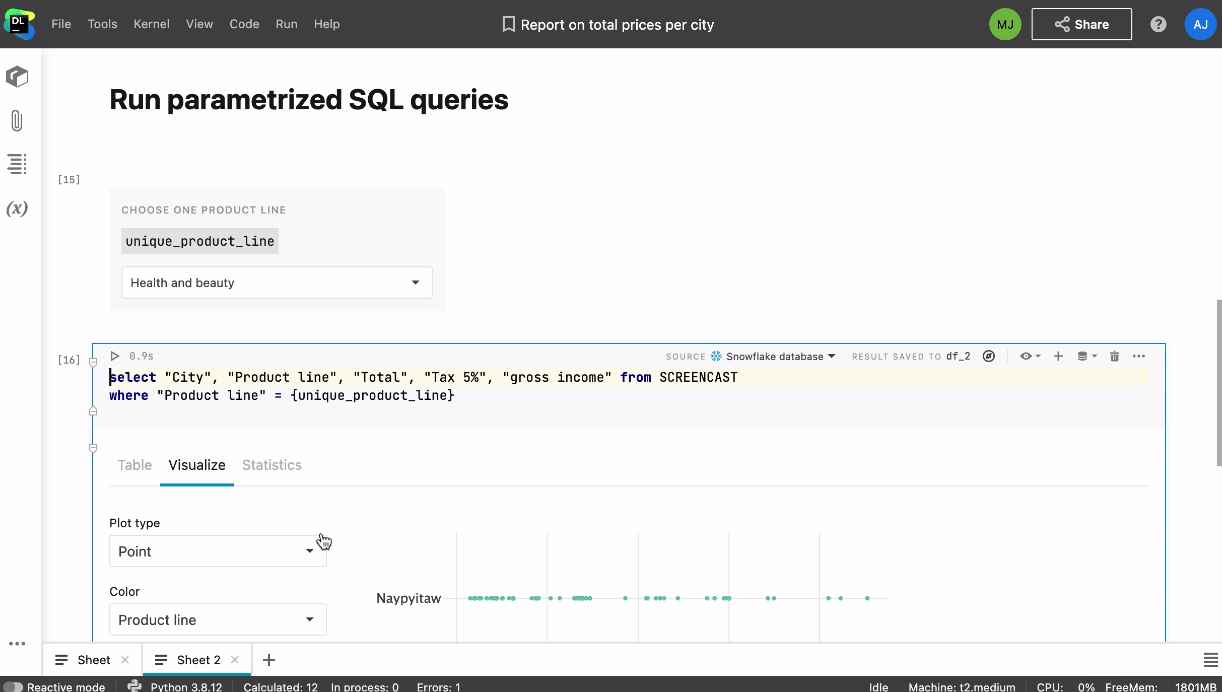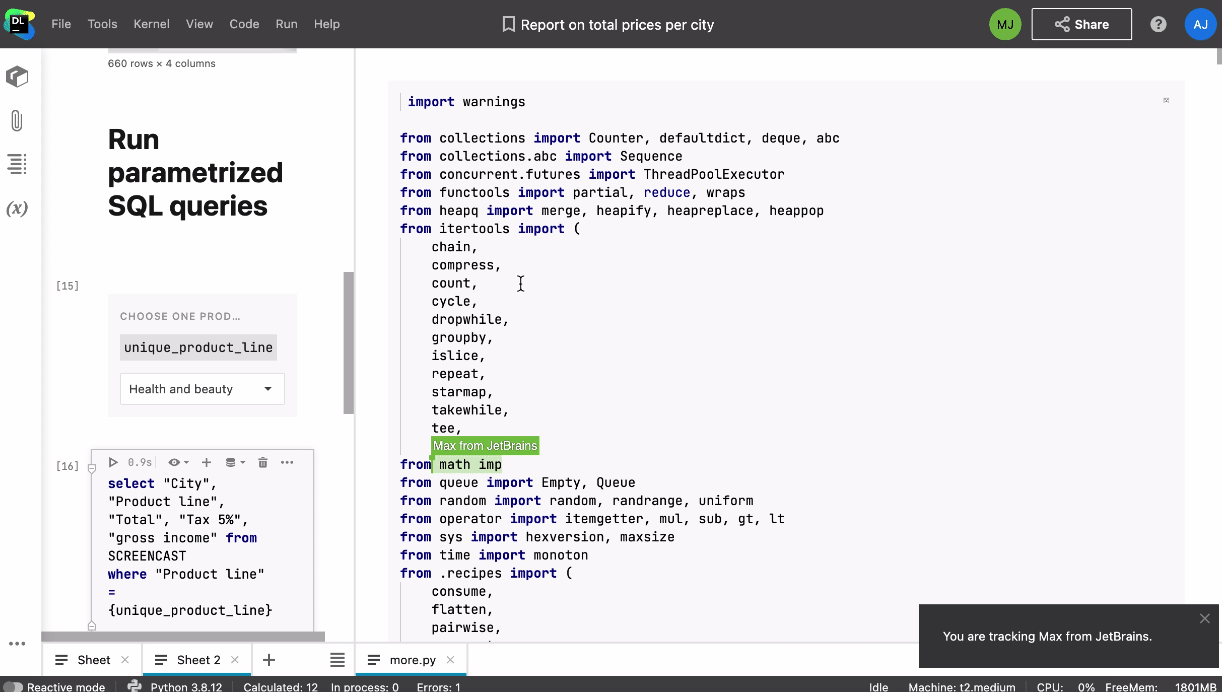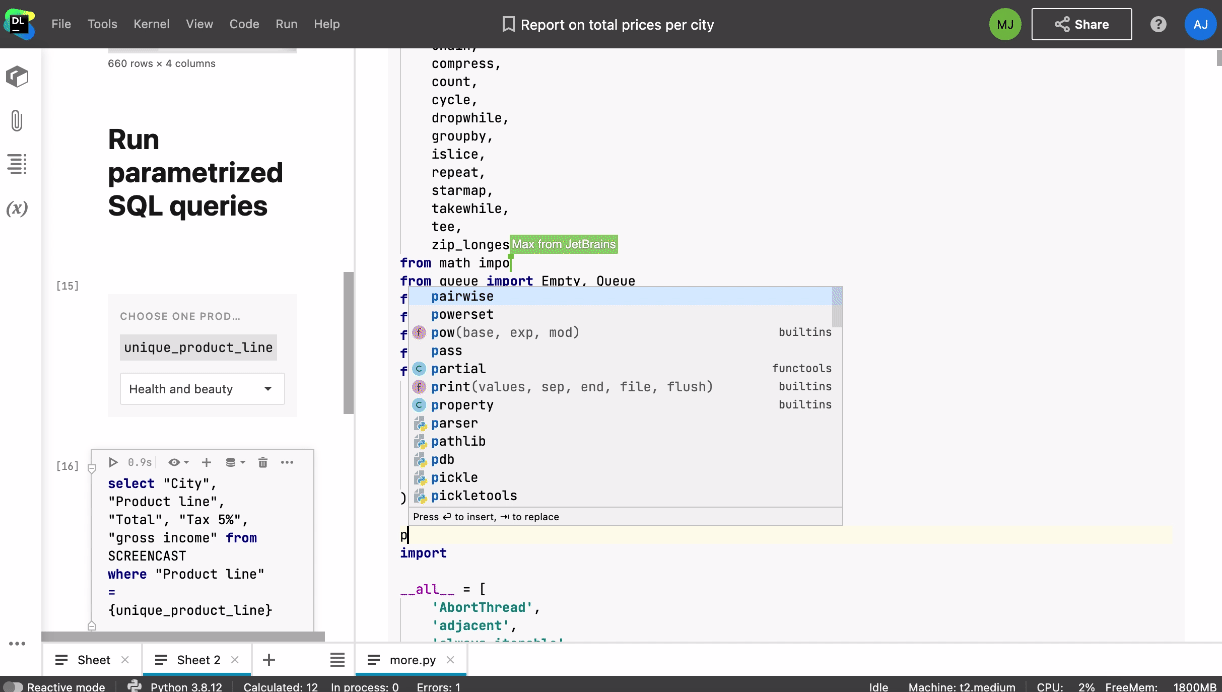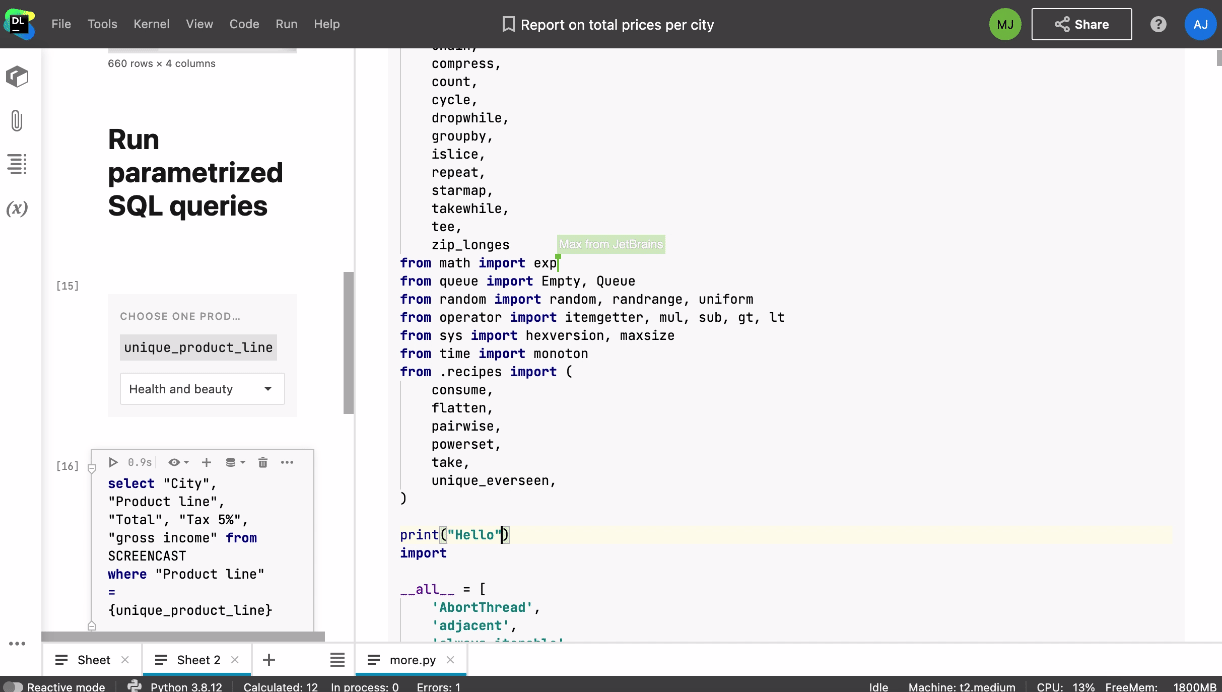
It is possible to access a shared notebook both in real time and when the other team member is offline. You don’t need to worry about breaking something in the notebook, as the actions are saved in the History tool, meaning you can always track changes and revert to a custom or automatic checkpoint.
If you prefer to use open-source Jupyter notebooks, you can share them via link and collaborate in real time after installing a Yjs plugin on your server. However, this plugin lacks role permissions, doesn’t have real-time collaborator tracking and version diffs, and your database passwords or other credentials are exposed and can be retrieved by your team members.
Create a knowledge base for data science projects
If your team members often do repetitive tasks, you might think of creating a knowledge base with notebook templates. This is a simple way to prevent a member of your team from wasting hours reinventing a process that another team member has already developed.
In Datalore, you can create a shared team workspace and store all of your essential notebook templates and datasets. Thanks to the all-in-one setup of Datalore, these templates can include a configured environment, proper markdown descriptions, some documented template code, and even connections to relevant databases or cloud storage. Data scientists will then be able to clone these notebooks to their home workspaces and start building on them.
Such a knowledge base also streamlines the onboarding of new team members, as all essential datasets, notebooks, and environment setups are available in one place.
Write code with reproducibility in mind
Understanding each other’s code can be tough, but resolving your colleagues’ bugs is even harder. Below you can find a brief checklist to introduce to your team to help with reproducibility:
- Describe every 2-3 code blocks with a Markdown cell.
- Click “Run all” and make sure the notebook is recomputed with no errors before publishing your work as a report or putting it in a shared workspace. Alternatively you can use Reactive mode in Datalore to make the notebook state consistent. You can read more about it here.
- Share the environment and data along with the notebook. Datalore handles this by default, but if you are using open-source Jupyter you need to do this explicitly.
If reproducibility is important to you, make sure to watch our recent webinar with Dr. Jodie Burchell on 5 tips for reproducible research.
Effectively communicate your findings to foster data-driven decisions company-wide
While notebooks are an excellent tool for conducting data science research, they are not the most effective means to communicate the results.
Raw notebooks with large chunks of code are bound to include a lot of information that is irrelevant to both technical and non-technical stakeholders. They usually just want the story of what you did, why you did it, and what your findings are.
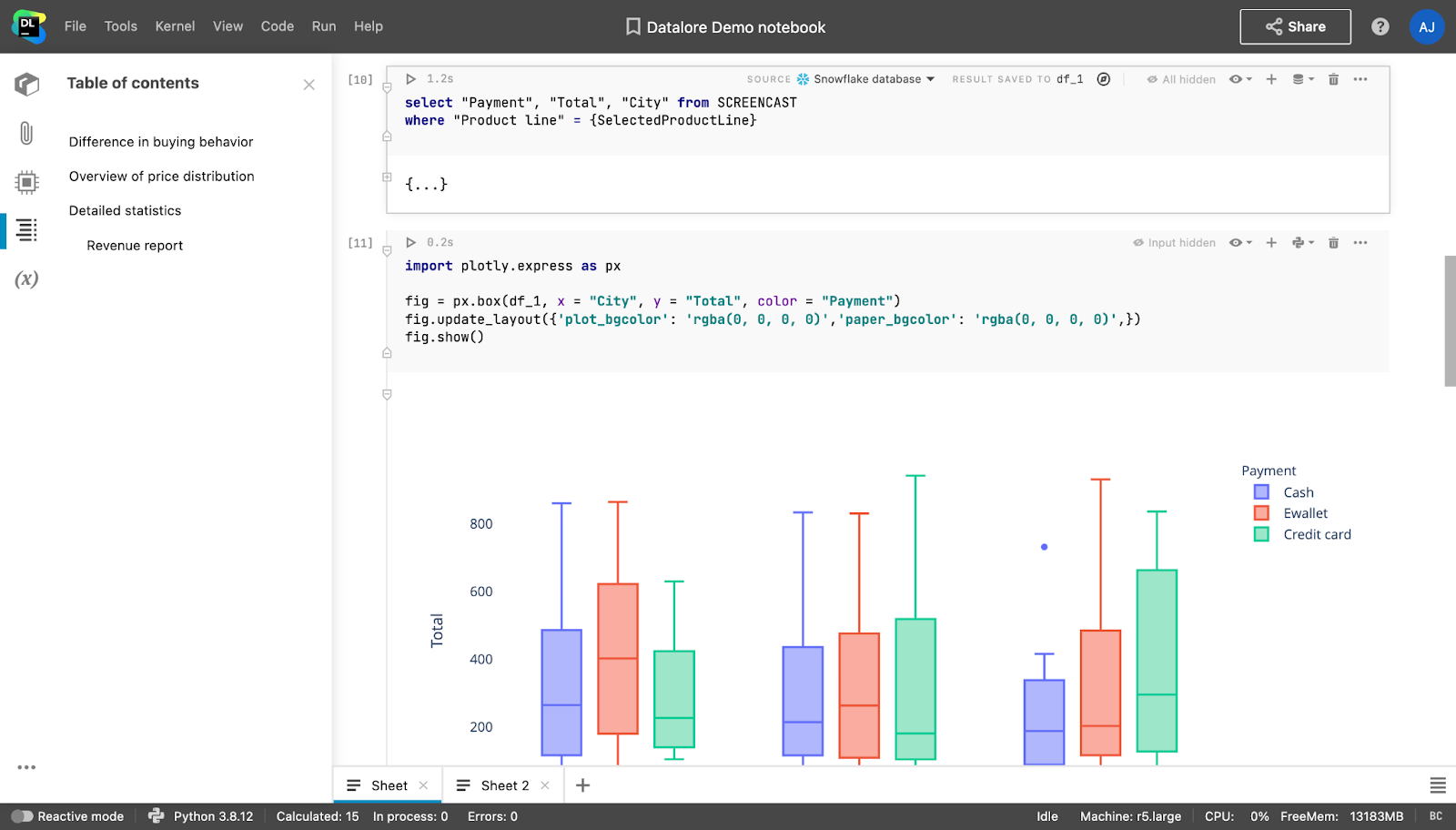
However, creating reports using tools like Tableau or Power BI, or dashboarding packages like Dash/Streamlit (Python), Shiny (R), or Google Docs/Microsoft Word, is a lot of extra work. It also removes the connection between the notebook and the report, meaning that any changes you make to the notebook need to be manually updated in the report.
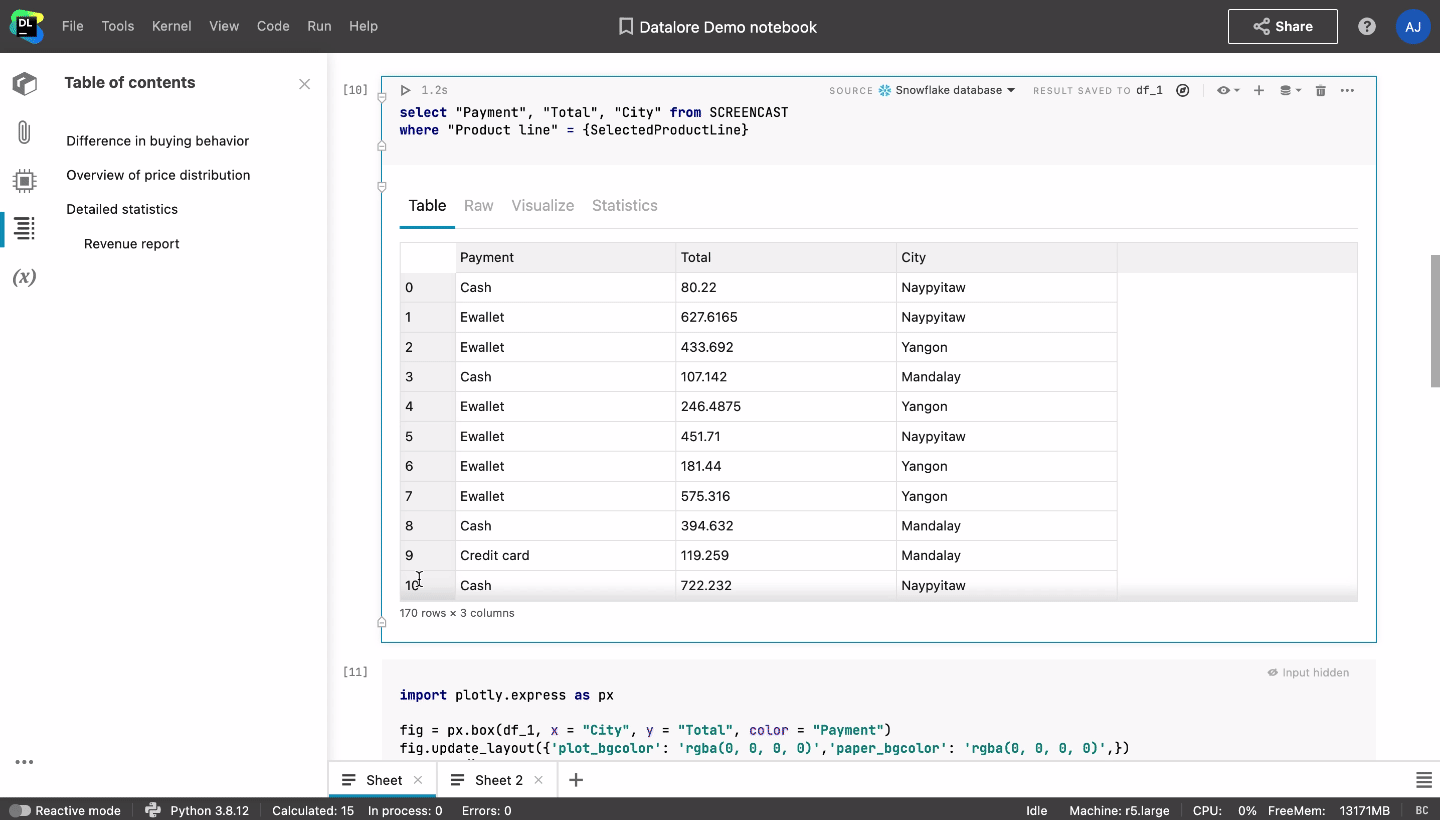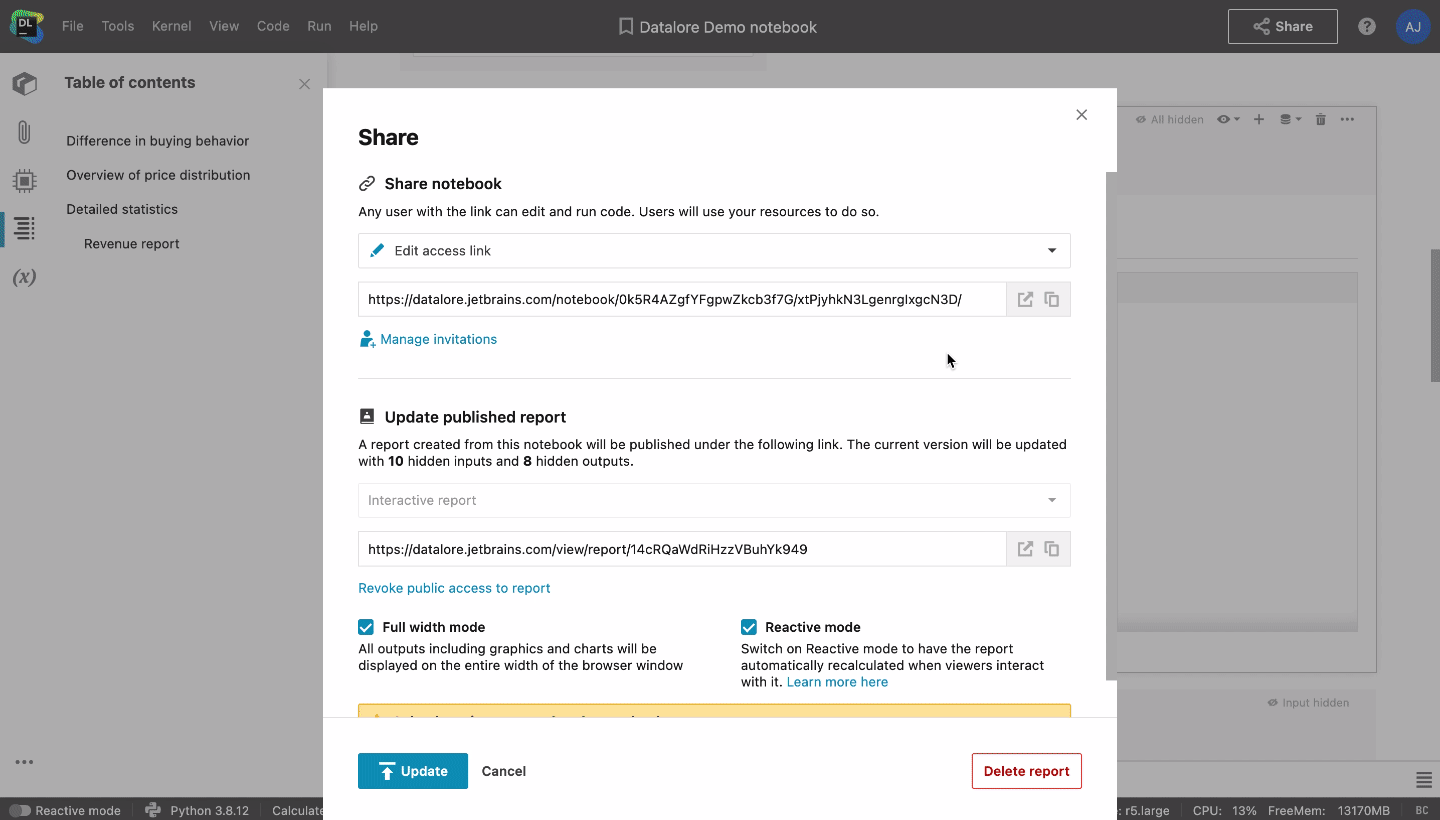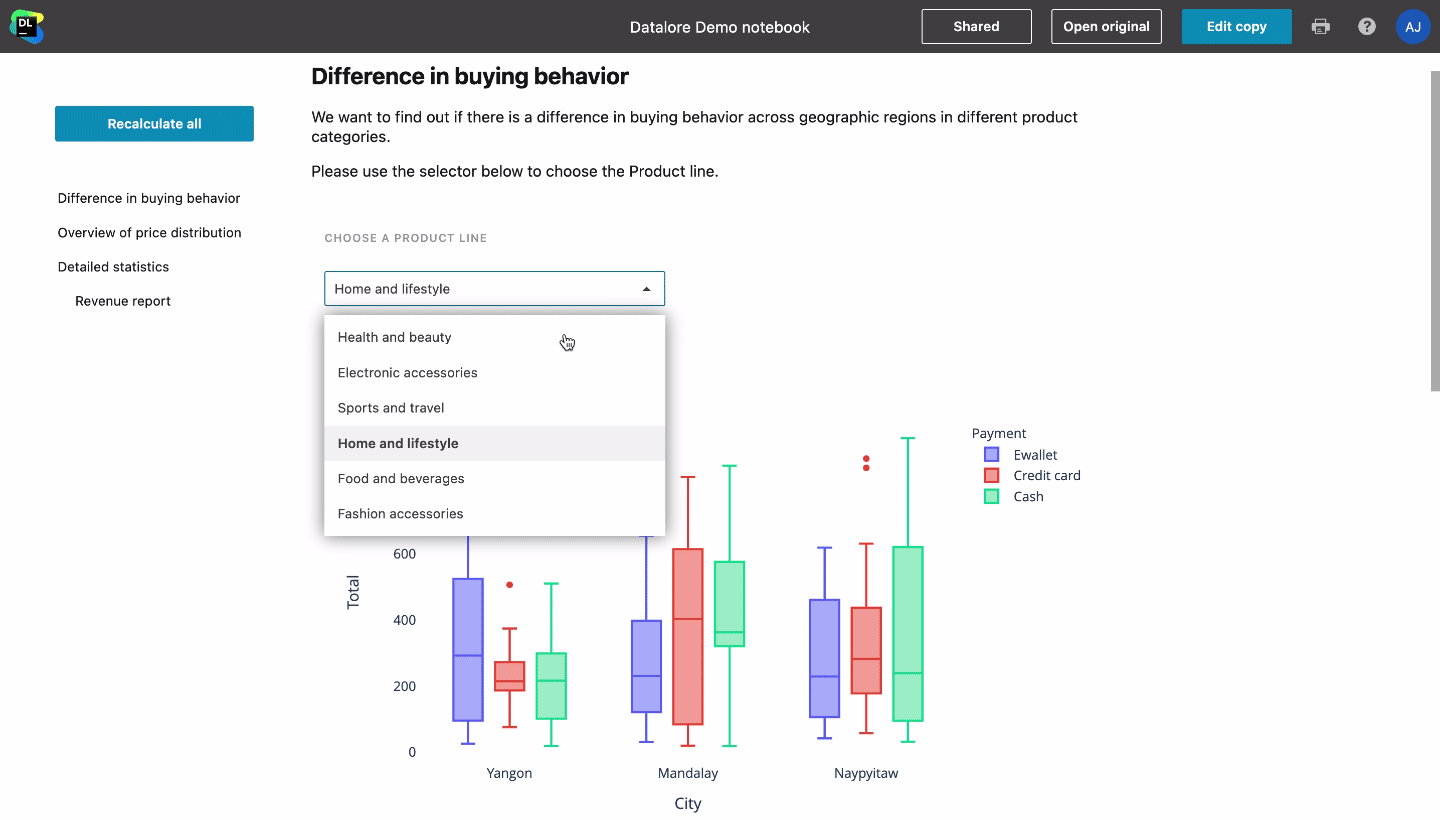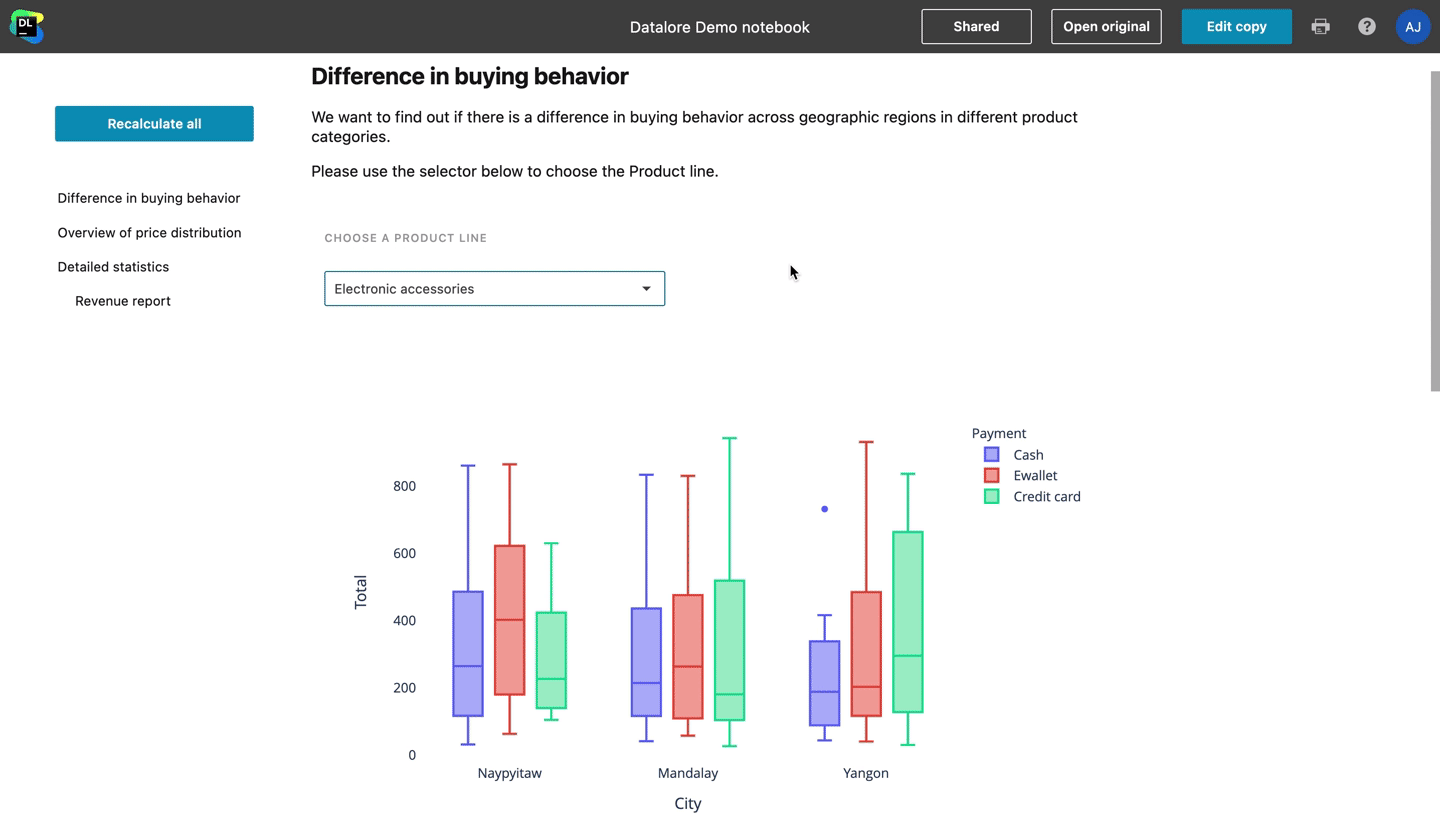
These pain points can be easily addressed with Datalore. Notebooks in Datalore can be converted directly into reports, with the ability to hide as much of the notebook input and output as you would like. Stakeholders can access these reports without a Datalore account and interact with dropdowns, sliders, and plots. If stakeholders have a Datalore account and basic Python or SQL knowledge, they will be able to dive into the analysis by editing a copy of the report.
From local to cloud-based
Are you using locally installed Jupyter notebooks? Check out the comparison table below for a few reasons why you should consider moving to a cloud-based data science platform.
| Local Jupyter, installed individually. | Cloud platform, hosted by your company or an SaaS provider. | |
| Collaboration | Only via Git. Connection to data and environments might be lost, you might forget to commit the latest state of the project, and pushing notebooks with outputs can bring additional clutter into the Git repo. | Real-time collaboration on notebooks and shared workspaces, with all of the artifacts attached (available in Datalore). |
| Working with big data | Takes a lot of time to pull big data from the server and your local machine might run out of memory. | You can scale the cloud machine and pull the data without having to rely on internet speed. |
| New team member onboarding | Every new team member spends time installing Jupyter, configuring the environment, and pulling data by themselves. | One-click access to team projects with everything pre-installed. |
| Computation machine access | Need to spin up a machine manually and SSH to it. | Easy to run computations on powerful servers with one click. |
| Environment setup | Each user has different environments which can be hard to manage. A new package might break the whole application and it will be hard to debug. | Teams can create multiple base environments with pre-installed dependencies. The app won’t be broken, as each notebook’s environment is isolated. |
How can I try Datalore in order to improve my data science team collaboration?
If you want to try Datalore in your team, you can host a private cloud or on-premises version with the Enterprise plan. Learn more about Datalore Enterprise and request a trial here.
If you want to use Datalore for yourself or quickly try it out in the cloud, you can register for Datalore Community or Professional plans, hosted by JetBrains.
That’s all for now! Follow us on our blog for useful tips and on Twitter for the latest updates!
Happy collaborating!
The Datalore team




