

GoLand internals: 1. Indices

Regardless if you are a new user or an existing one, all of us must spend at least a couple of minutes after every IDE upgrade or install on a task called “Updating Indices”.
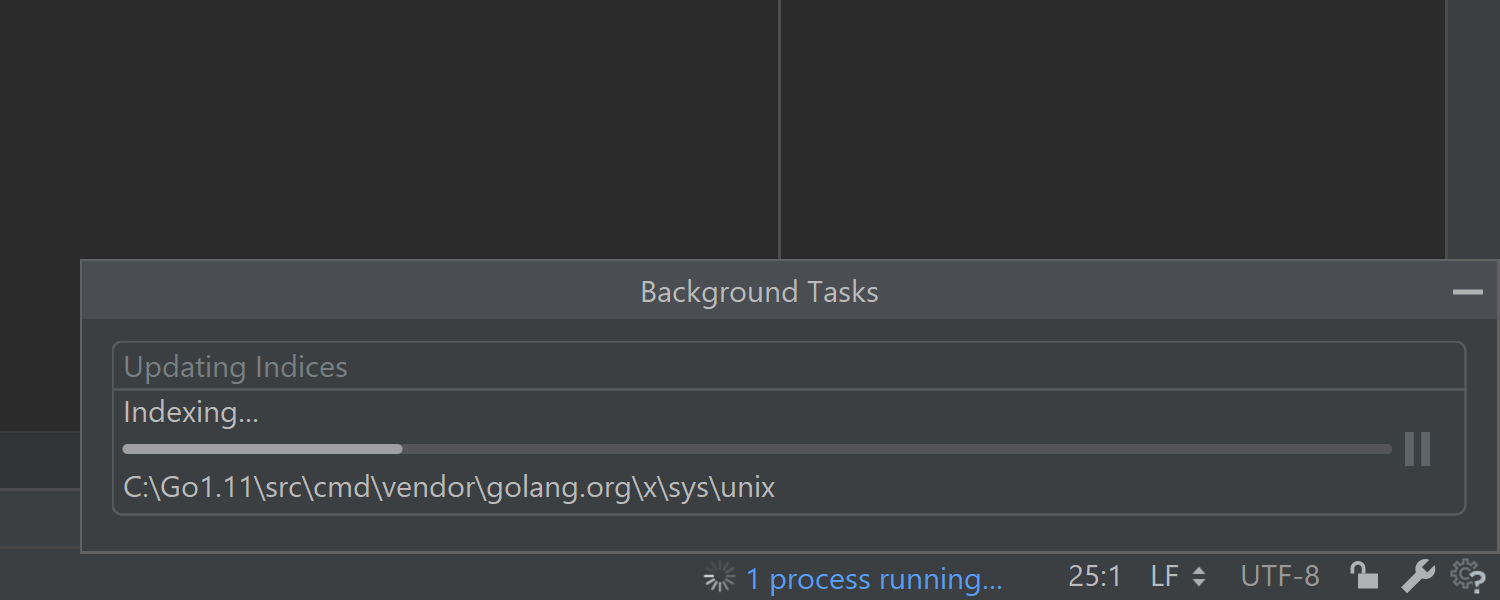
In today’s post, we’ll spend a bit of time and talk about this task, why it’s needed and when it happens.
Let’s start with why the indices are needed.
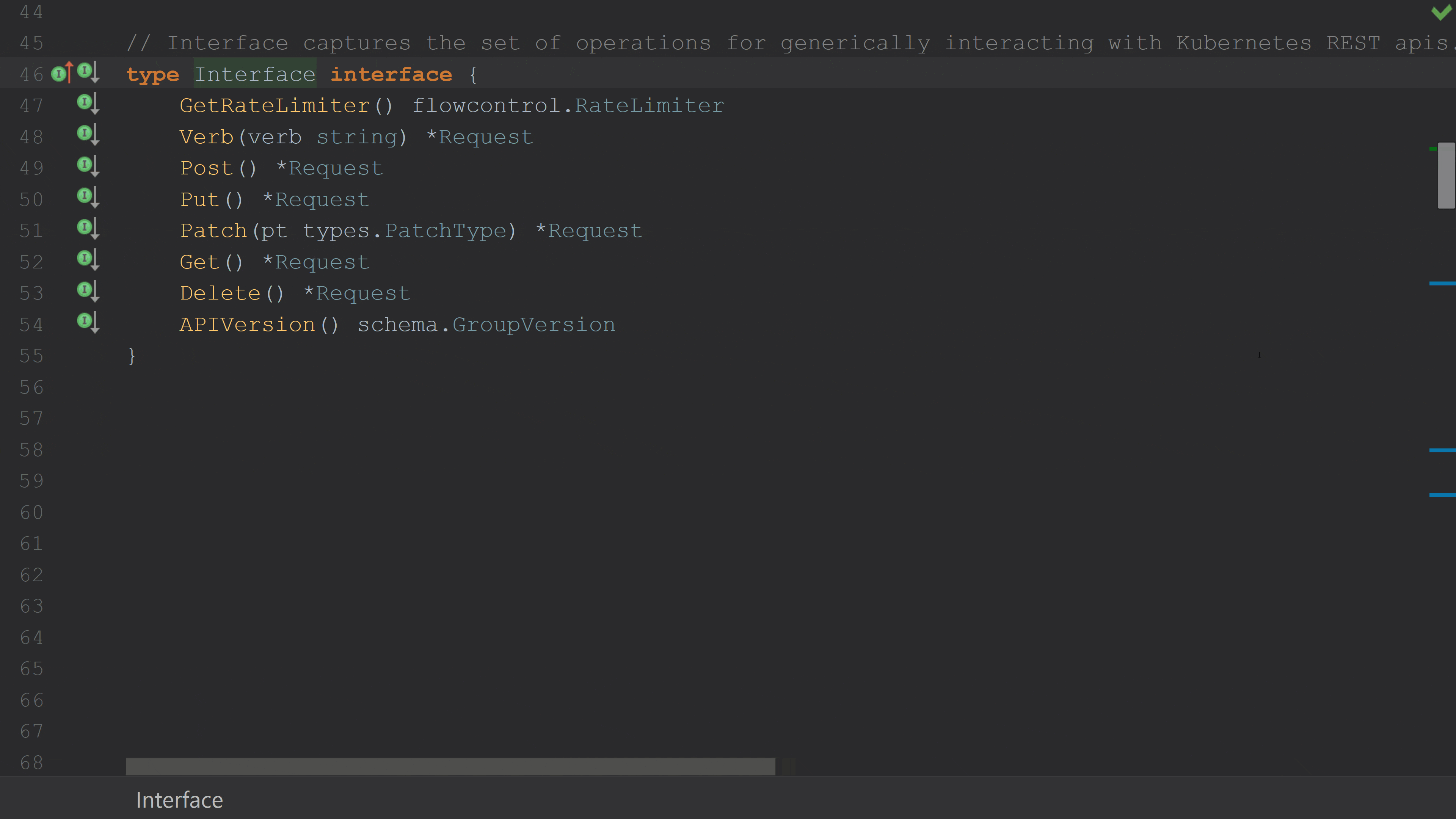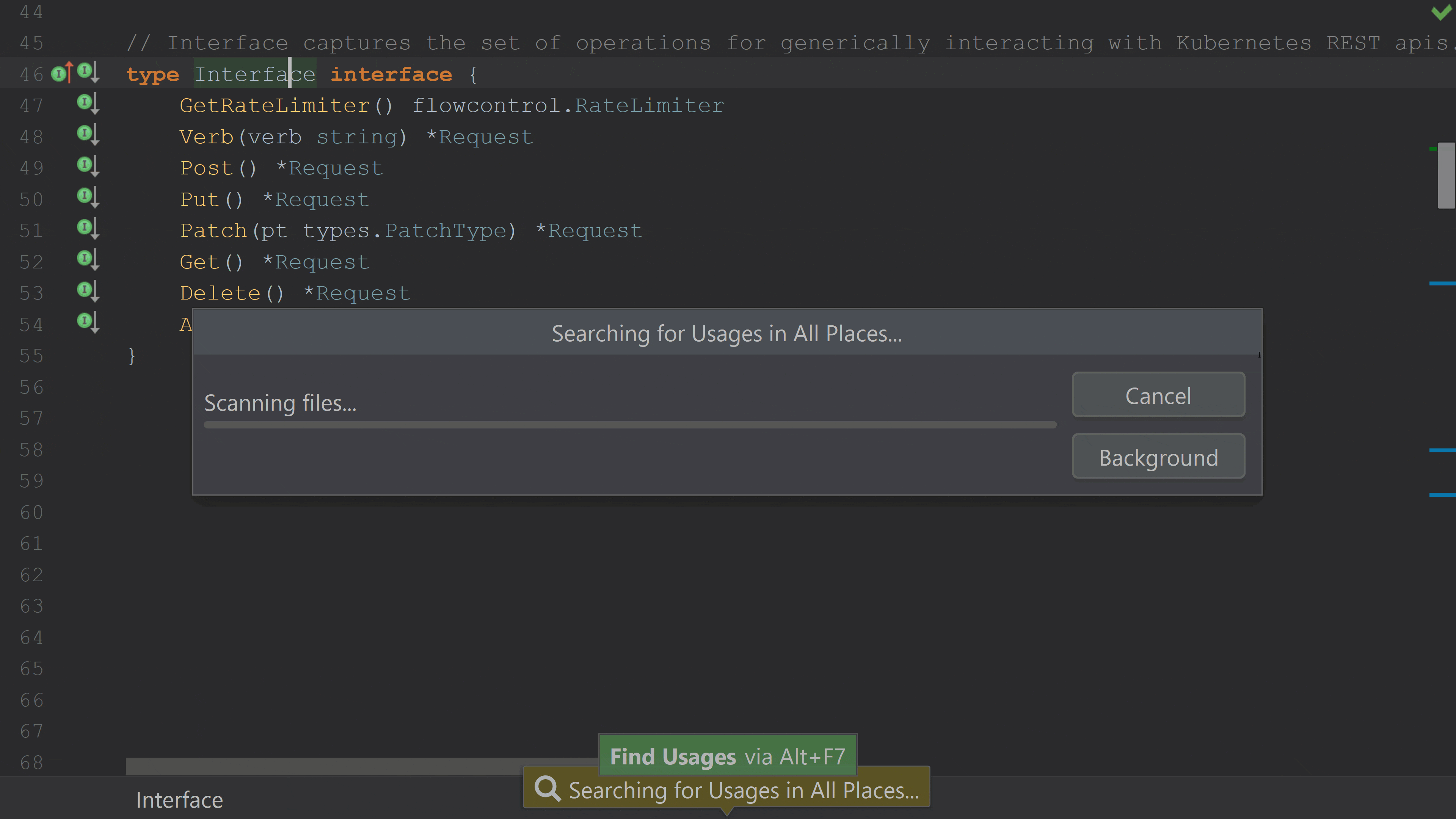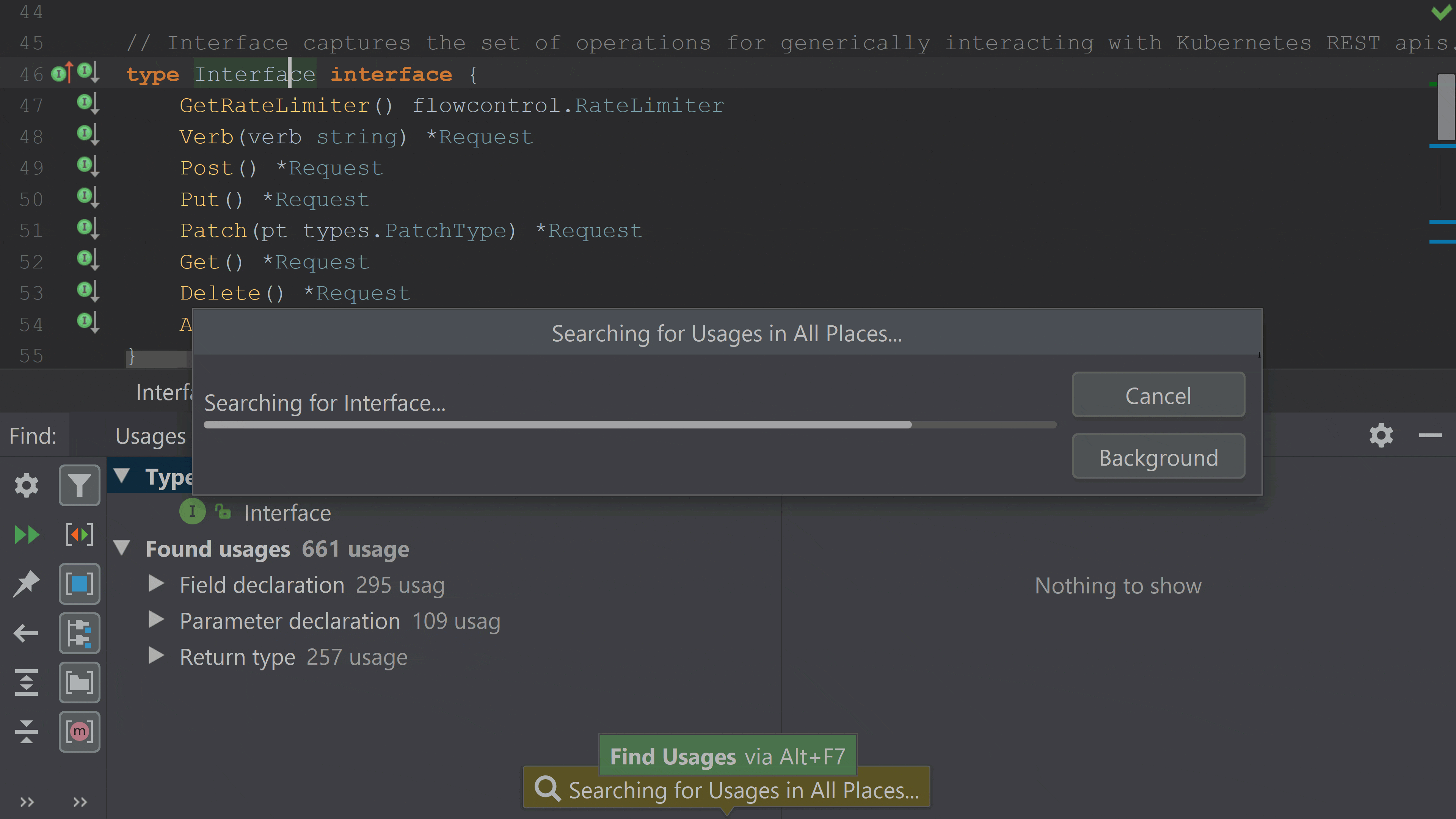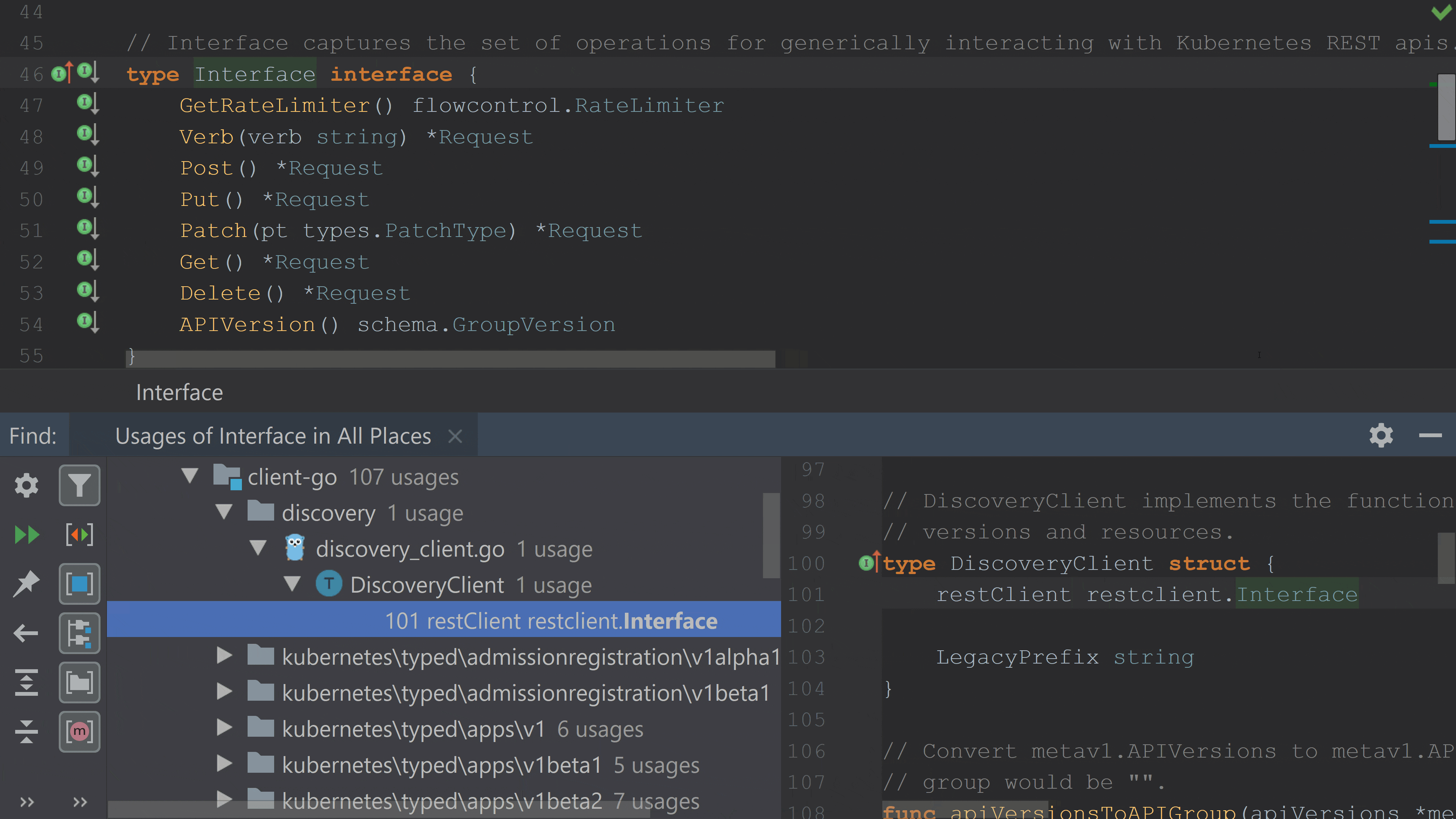
The cost of building the index pays off immediately as soon as the index is built as the indices provide information for functionality such as: auto-complete, nearly instant reference searching for Find Usages, source code navigation, refactoring, checking to see if a type implements an interface or if an interface is implemented by a type, and even functionality such as text searching inside the project or semantic highlighting of the source code. Many of these operations can run without having to touch the source code again. However, the IDE will keep track of all file changes made both from within it or from outside to refresh the available data in the index.
What are indices and how are they built?
As the name suggests, the indexing operation is responsible for creating an internal representation of the source code so that the IDE can better understand it. In this process, the code is converted from the text representation to the internal representation, called Program Structure Interface, or PSI for short.
To create this representation, the IDE will need to identify then read all source code files from your project. This takes us to the speed part. The IDE currently tries to read these files as quick as possible, and thanks to the capabilities Java has, it can do it very efficiently by indexing multiple files in parallel, which sometimes leads to high system usage (or as it’s known, laptops heating up or starting to take off from their desk).
One of the problems that the indexing process must handle is the presence of many files, usually under 2-3 KB each. This means that the speedier is the location that hosts the files is, the faster the indexing will be performed. As such, when indexing files from a local SSD, the operation will finish quicker than indexing files from within a VM running from the same machine, and a lot faster than indexing files located on a network mount (which are known to dislike fast reading of multiple small files).
Besides the first start of the IDE after a new installation, there is an additional case when indexing can happen. Each plugin can create its own set of indices. When installing a plugin, or an update for a plugin, that can trigger a rebuild of the plugin’s indices so that the plugin can work correctly, or of the common indices like the TODO indices. For example, when updating the Vue.js plugin, it is possible for the plugin to request a reindexing of the source code.
If you find yourself in need to perform some tasks outside of the IDE and you need the full power of your computer or want to do a small precision fix, such as a typo, you can also pause the indexing operation and resume it later. However, until the indexing is finished, some of the features such as completion, highlighting, inspections, refactorings, etc. may not be performed due to the lack of information needed for them.
Talking specifically about Go, the bigger the GOPATH (also known as a Go Workspace), the longer the indexing will take.
You might ask, why the IDE needs to index the GOPATH to being with and not just the current project. Given the nature of a Go Workspace, operations such as completion or refactoring cannot be safely performed without the IDE knowing where all the identifiers are referenced. Think of an example where your source code is located under $GOPATH/src/github.com/jetbrains/library, but it’s also used under $GOPATH/src/github.com/jetbrains/application. If the IDE will perform a rename refactoring, then it’s possible that it would also affect the application source code without having a way to identify or fix the issue. In turn, this means that you’ll be left with fixing the problem manually, at which point the IDE would not be as useful as it should be and it would be just a glorified text editor.
There are a couple of exceptions where GOPATH is not necessarily needed.
The first one is when creating a project using the vendoring approach. This allows the IDE to skip indexing/looking for data in the GOPATH and it will perform the operations just in the project itself, in the vendor folder, and in the Go SDK. GOPATH will not be used in this case.
Specifically, the IDE automatically recognizes the usage of golang/dep, but it can be used with any project that uses the vendoring approach. To enable this functionality, go to Settings (Preferences) | Go | GOPATH and untick the Index entire GOPATH option. Be careful, as disabling this checkbox means that if a library is not found under the vendor/ directory it will be flagged as a missing dependency and all references to it will be flagged as unresolved, leading to a poor experience.
The other option is using Go Modules, which were introduced in Go 1.11 as an experimental feature.
In this case, the IDE will also not rely on the GOPATH to do the resolving anymore, and instead will only look for the libraries and the dependencies listed in the go.mod file.
In both these cases, the indexing operation will finish faster than usual, and the IDE will display a speed improvement in certain situations as the index will be focused only on the dependencies required by the project itself.
This concludes our short introduction post about the indexing operation. Besides extra heating during the winter, the investment in indexing time pays off really quickly given how much productivity help the IDE can provide thanks to having that knowledge it builds.
I hope you enjoyed this post, and if you have any comments or suggestions for future articles exploring the IDE internals, please let us know in the comments section below.






