

빅데이터의 세계, 3부: 데이터 파이프라인 구축

이번 글은 빅데이터와 관련한 JetBrains의 관점 및 제품 개발 방식을 다루는 시리즈의 세 번째 게시물입니다. 이 글에서는 데이터 엔지니어의 가장 중요한 업무인 파이프라인 구축을 설명합니다.
관련 게시물:
목차
빅데이터의 세계 2부에서 설명드린 바와 같이 데이터 엔지니어는 데이터 전송과 DWH 아키텍처 등을 담당합니다. 상당히 간단한 것 같지만 현실적으로 이 작업을 수행하는 최선의 방법이 명확하지 않을 때도 있습니다.
파이프라인이란?
개발 과정의 모든 요소는 어느 정도까지 데이터 파이프라인으로 표현할 수 있습니다. 백엔드 개발의 경우 다음과 같이 표시될 겁니다.

ETL(추출, 변환,로드)처럼 보이는데요, 그렇지 않나요? 추출되는 건 없지만 의미는 동일합니다!
일반적으로 간소화된 CI 파이프라인은 다음과 같습니다.

이러한 방식으로 생각하면 CI 서버 역시 ETL 도구입니다.
하지만 데이터 엔지니어링의 작업은 훨씬 더 복잡합니다. 수많은 소스, 수많은 싱크(데이터 저장 장소), 수많은 복잡한 변환 및 수많은 데이터가 있습니다. 수십 개의 운영 데이터베이스, Kafka를 통해 발생하는 사이트의 클릭스트림, 수백 개의 보고서, OLAP 큐브 및 A/B 실험이 있다고 상상해 보세요. 또한 원시 데이터에서 시작하여 보고서 작성에 적합하도록 집계, 정리, 검증을 거친 데이터 계층까지 이르는 여러 방식으로 모든 데이터를 저장해야 하는 상황도 상상해 보세요.
데이터 엔지니어가 이와 같은 오케스트라의 지휘를 준비하며 지휘봉을 두드리는 소리가 벌써 들리는 것 같습니다. 실제로 데이터 엔지니어는 이 모든 프로세스를 통제합니다. 오케스트라가 다양한 악기 연주자로 이루어진 것처럼 데이터 전송 프로세스에도 별개의 파이프라인이 필요합니다.
실제로 파이프라인은 오케스트레이터 및 ETL 도구라는 두 단계로 구성됩니다.
오케스트레이터
이 파이프라인은 DAG(방향성있는 비순환 그래프)라는 엔티티로 통합됩니다. DAG는 아래와 같이 나타날 수 있지만 훨씬 더 복잡할 수도 있습니다.
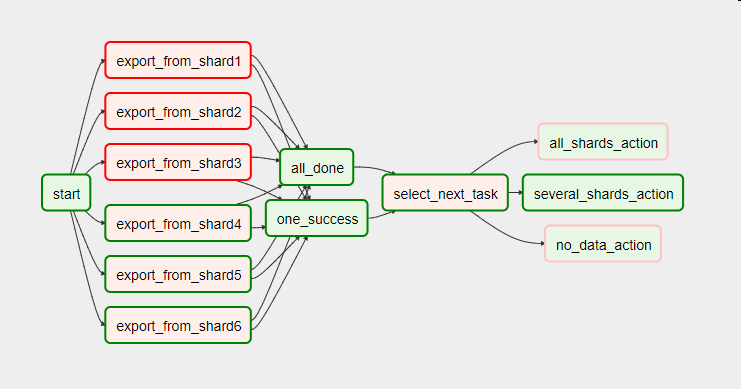
데이터 엔지니어의 주요 도구 중 하나가 오케스트레이터인 이유입니다. 복잡한 파이프라인을 비교적 간단하게 구축할 수 있기 때문이죠.
가장 널리 사용되는 오케스트레이터는 Apache Airflow, Luigi, Apache NiFi 및 Azkaban입니다. 기본적으로 이들은 모두 동일한 작업을 수행합니다. 필요한 순서대로 도구를 실행하고 문제가 발생하면 다시 시도하는 작업입니다.
이제 더 낮은 단계의 파이프라인 구축을 고려해 보겠습니다.
ETL 도구
앞서 말씀드린 바와 같이, 오케스트레이터는 다른 도구(일반적으로 로컬 환경에 더 적합한 ETL 파이프라인 구축을 위한 도구)를 호출합니다. 많은 경우 ETL 도구는 DAG와 함께 작동하므로 특히 흥미롭습니다.
예를 들어, Apache Spark는 범용 분산 컴퓨팅 엔진임에도 불구하고 가장 널리 사용되는 ETL 도구 중 하나입니다. 자주 사용되는 패턴 중 하나는 데이터를 한 위치에서 다른 위치로(소스에서 싱크로) 옮기는 도중 데이터를 변환하는 것이며, 이 작업도 DAG로 표시될 수도 있습니다.
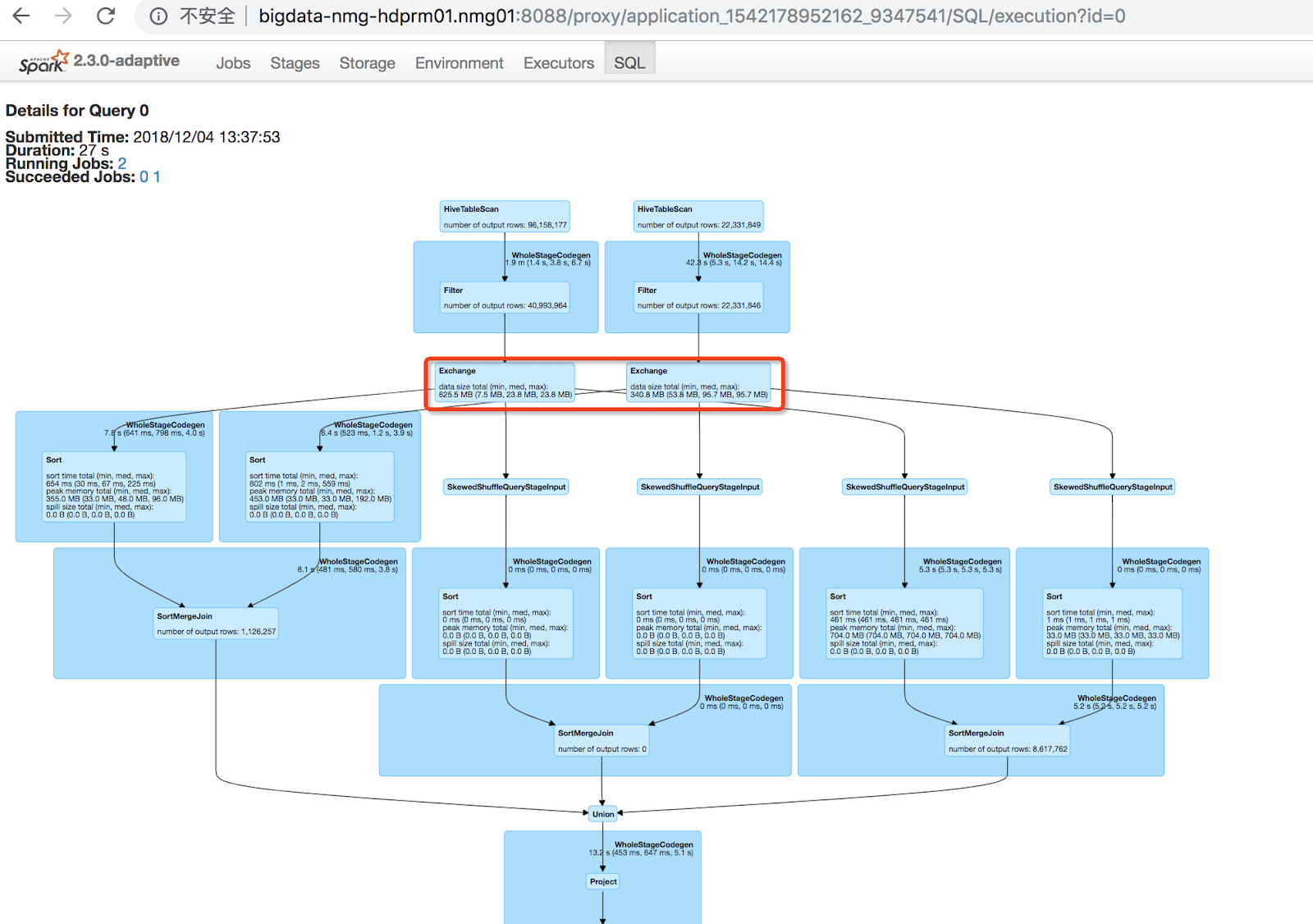
이 그래프를 통해 입력 2개, 출력 1개 및 “join”처럼 누구나 잘 알고 있는 작업이 포함되는 다양한 중간 처리 단계가 있다는 점이 확인됩니다. 또한 데이터가 노드를 통과하는 방식 및 처리된 데이터의 양과 노드별 소요 시간도 확인할 수 있습니다.
DAG는 매우 복잡할 수 있으며 일반적으로 오케스트레이터가 작동하는 DAG보다 더 복잡합니다. 따라서 어떻게 보면 데이터 엔지니어가 파이프라인의 파이프라인이 작동하는 오케스트레이터를 조정하는 것입니다.
배치 처리 vs 스트림 처리
일반적으로 ETL 도구는 배치 처리 또는 스트림 처리라는 두 가지 방식 중 한 방식으로 작동할 수 있습니다.
배치 처리를 사용하면 작업이 한 번에 실행되고, 일부 데이터를 불러와 처리한 다음 종료됩니다. 스트림 처리를 사용하면 프로세스가 끊김 없이 실행되어 소스에 표시된 즉시 데이터를 얻을 수 있습니다.
이러한 방식으로 제시될 때 스트림 처리는 항상 Kafka와 같은 스트리밍 소스와 함께 사용해야 하는 것처럼 보일 수 있습니다. 놀랍지만 반드시 그런 것은 아닙니다. 이 규칙의 한 가지 일반적 예외는 관계형 데이터베이스입니다. 데이터를 추출하는 두 가지 방식이 있습니다. 더 보편적이고 명확한 첫 번째 방식은 데이터베이스에서 필요한 모든 데이터를 한 번에 읽는 것입니다. 하지만 Debezium 등의 특수한 도구를 사용하여 데이터베이스의 변경 사항을 스트림 처리할 수도 있습니다.
Apache NiFi
오케스트레이터 및 ETL 도구라는 별개의 두 가지 세계가 있다는 인상을 받으셨을 수 있습니다. 그리고 스트림 처리와 배치 처리 방식에도 차이가 있습니다. 그러나 현실에는 이상치가 있습니다. Apache NiFi는 오케스트레이터이자 ETL 도구로, 배치 모드 및 스트리밍 모드에서 작동 가능합니다(물론 몇 가지 제한은 있음).
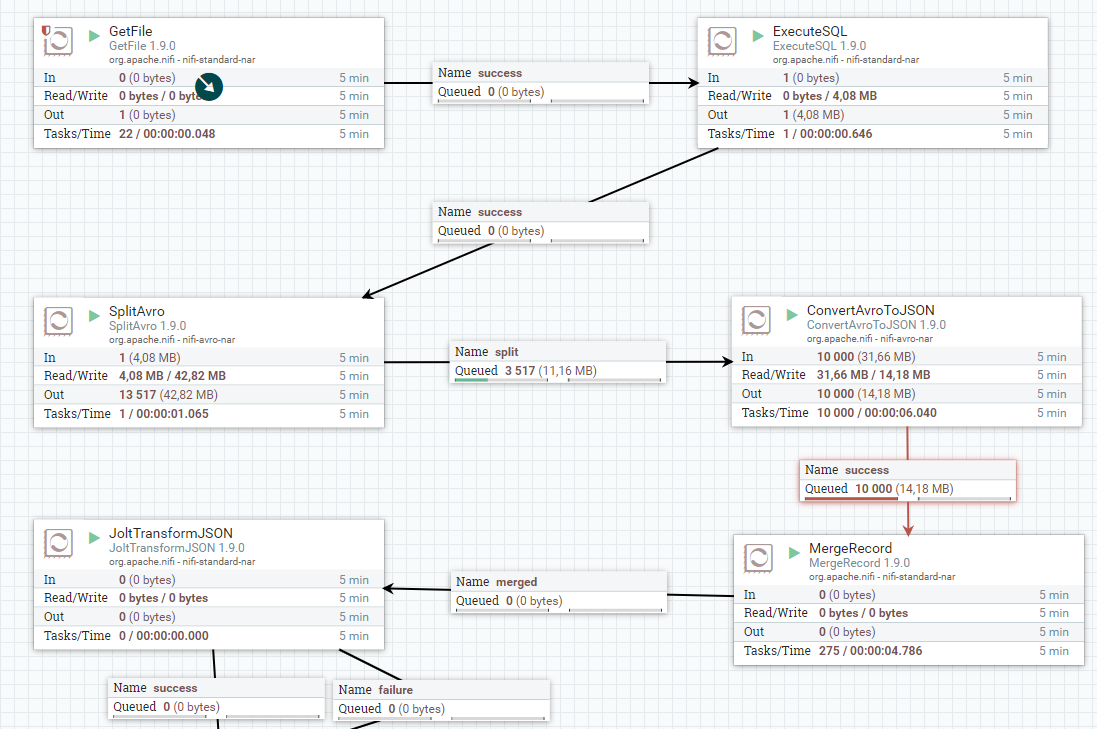
Apache NiFi는 2006년 NSA에서 개발되었으며(최초 이름은 NiagaraFiles), 프로그래머가 아닌 사람도 데이터 파이프라인을 작성할 수 있도록 지원하겠다는 목표에 따라 설계되었습니다. 2014년에는 NSA의 기술 이전 프로그램의 일환으로 Apache Software Foundation에 이전되었습니다.
그러나 특별한 기술이 없는 사용자도 복잡한 데이터 파이프라인을 생성할 수 있도록 지원한다는 목표는 동일하게 남았습니다. 이 목표는 정말 실현되었습니다. 물론 이와 같은 시스템의 한계가 있으며, 사용자는 NiFi에서 기본적으로 지원되지 않는 기능을 구현해야 할 수도 있습니다. 하지만 괜찮습니다. Apache NiFi는 확장 가능한 방식으로 구축되므로 개발자는 고객이 필요로 하는 모듈을 구현할 수 있으며, 모듈은 어디서든 재사용이 가능합니다.
결론
파이프라인 구축은 분석적이고 기술적인 복잡한 작업입니다. 그러나 내부 및 외부의 고객이 선호하는 형식으로 필요한 데이터에 액세스할 수 있는 유일한 방법이기도 합니다.
일반적으로 파이프라인은 다른 ETL 도구를 호출하는 오케스트레이터의 지원을 통해 구축되지만, 때때로 Apache NiFi와 같은 단일 도구로 전체 파이프라인이 구축되는 경우도 있습니다.
파이프라인 구축을 위한 도구에 관심이 있는 경우 BigData Tools 플러그인을 살펴보세요. 이 플러그인은 현재 여러 스토리지 제공업체 및 Apache Spark와 통합되어 있습니다.
게시물 원문 작성자




