

빅데이터 세계, 4부: 아키텍처

빅데이터, 빅데이터를 바라보는 JetBrains의 관점 및 관련 제품 개발과 관련하여 연재 중인 시리즈의 4번째 게시물입니다. 이번 글에서는 데이터 엔지니어의 두 번째 업무인 아키텍처를 살펴볼 예정입니다.
관련 게시물:
목차:
빅데이터의 세계, 2부: 직무에서 논의된 바와 같이 데이터 엔지니어의 역할은 데이터 웨어하우스 아키텍처를 구축하는 것입니다. 그러나 정확한 의미는 무엇일까요? “아키텍처”는 엔지니어링에서 남용되는 용어이며, 실제로는 여러 의미를 지니고 있습니다. 특히 데이터 엔지니어링에서 의미는 스토리지 아키텍처와 데이터 처리 아키텍처 두 가지로 분류됩니다.
스토리지 아키텍처
기존 백엔드 엔지니어링에서 스토리지 계층은 일반적으로 매우 단순하며 최대 세 가지 구성 요소(데이터베이스, 캐시 및 파일 스토리지)가 이에 포함됩니다. 데이터베이스는 일반적으로 SQL 또는 NoSQL, 관계형 또는 비관계형 등의 단일 엔티티입니다.
하지만 데이터 엔지니어링에서 다양한 유형의 스토리지를 사용해야 합니다. 각기 다른 요구 사항에 따라 데이터가 여러 계층으로 저장되어야 하기 때문입니다.
가장 널리 사용되는 스토리지 아키텍처 중 하나는 데이터 웨어하우스입니다.
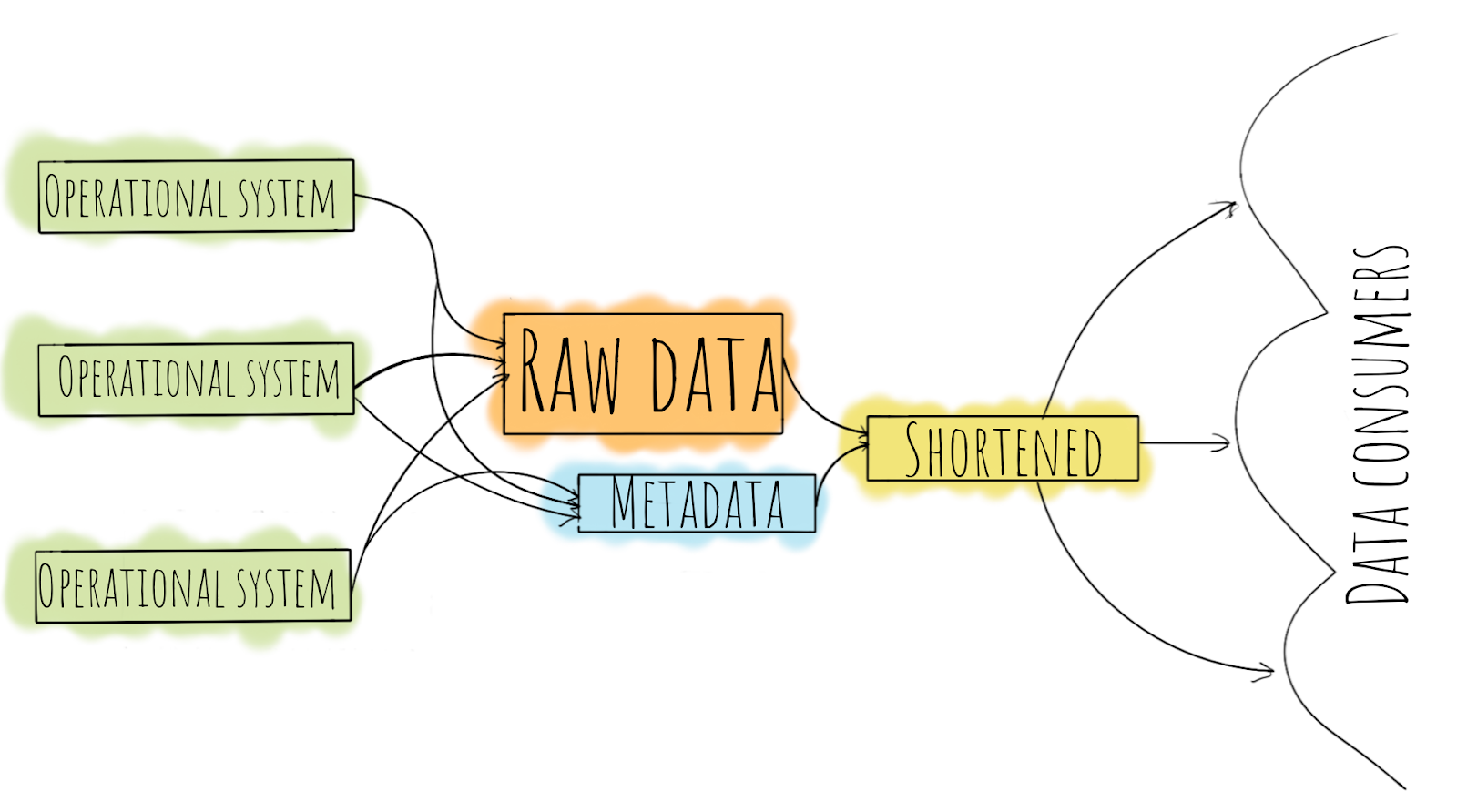
전자상거래, 은행 외의 모든 것은 운영 시스템에서 시작됩니다. 운영체제의 데이터는 그대로 원시 데이터 저장소로 이동합니다. 데이터가 일관적인지, 정제 또는 검증되었는지 여부와 무관하게 어떤 형태이든 데이터를 저장하여 정의된 로직에 따라 필요한 만큼 많은 대상으로 처리할 수 있습니다.
데이터 외에도 운영 데이터베이스의 스냅샷이 생성되거나 메시지가 이벤트 저장소로 전송되는 경우 등의 일부 메타데이터를 저장해야 합니다.
원시 데이터를 수집한 후에는 정제, 검증, 집계 절차를 거쳐 축소/집계된 데이터 저장소에 보관해야 합니다. 데이터가 집계되면 개인 또는 전체 부서와 같은 비즈니스 소비자가 데이터를 사용할 수 있습니다. 이러한 형식의 데이터는 원하는 보고서 작성이나 고객 세분화 등의 기타 비즈니스 요구에 적합해야 합니다.
여기까지는 데이터 웨어하우스에 대한 기본적이고 간단한 설명일 뿐입니다. 더 자세한 설명은 Wikipedia에서 확인할 수 있습니다.
하지만 데이터 웨어하우스 시스템만이 널리 사용되는 솔루션은 아닙니다. 다음과 같이 다른 솔루션도 있습니다.
또한 기업은 일반적으로 자사의 니즈에 맞는 하이브리드 스토리지 모델을 직접 생성합니다.
보시다시피 데이터 스토리지 계층을 구성하는 다양한 방식이 있지만 데이터 스토리지 계층은 시스템의 일부에 불과합니다. 데이터는 단순히 스토리지에 보관되지 않습니다. 데이터는 이동합니다. 빅데이터의 세계, 2부: 직무에서 설명드린 것처럼 데이터는 파이프라인을 통해 이동합니다. 데이터 처리 아키텍처를 살펴보지 않고 이 활동을 이해하긴 어렵습니다.
데이터 처리 아키텍처
데이터의 요구 사항 및 사용 패턴은 비즈니스 사례에 따라 직접적으로 결정됩니다. 그럼에도 라이브 스트리밍 데이터 및 과거 데이터라는 두 가지 유형의 데이터는 오늘날 어디서든 발견됩니다.
이 데이터는 어떻게 활용해야 할까요? 우리 솔루션은 가능한 한 많은 데이터를 사용하는 경우에만 안정적일 수 있으며, 단기적 문제를 다루는 솔루션의 경우 일반적으로 거의 실시간 데이터여야 합니다.
수집된 데이터를 이용한 작업도 흥미롭지만 이와 동시에 실시간 데이터 처리를 중점적으로 살펴보겠습니다. 실시간 데이터 및 수집된 데이터를 동시에 처리하는 다양한 방식이 있지만 두 가지 주요 방식은 Kappa 및 Lambda 아키텍처입니다.
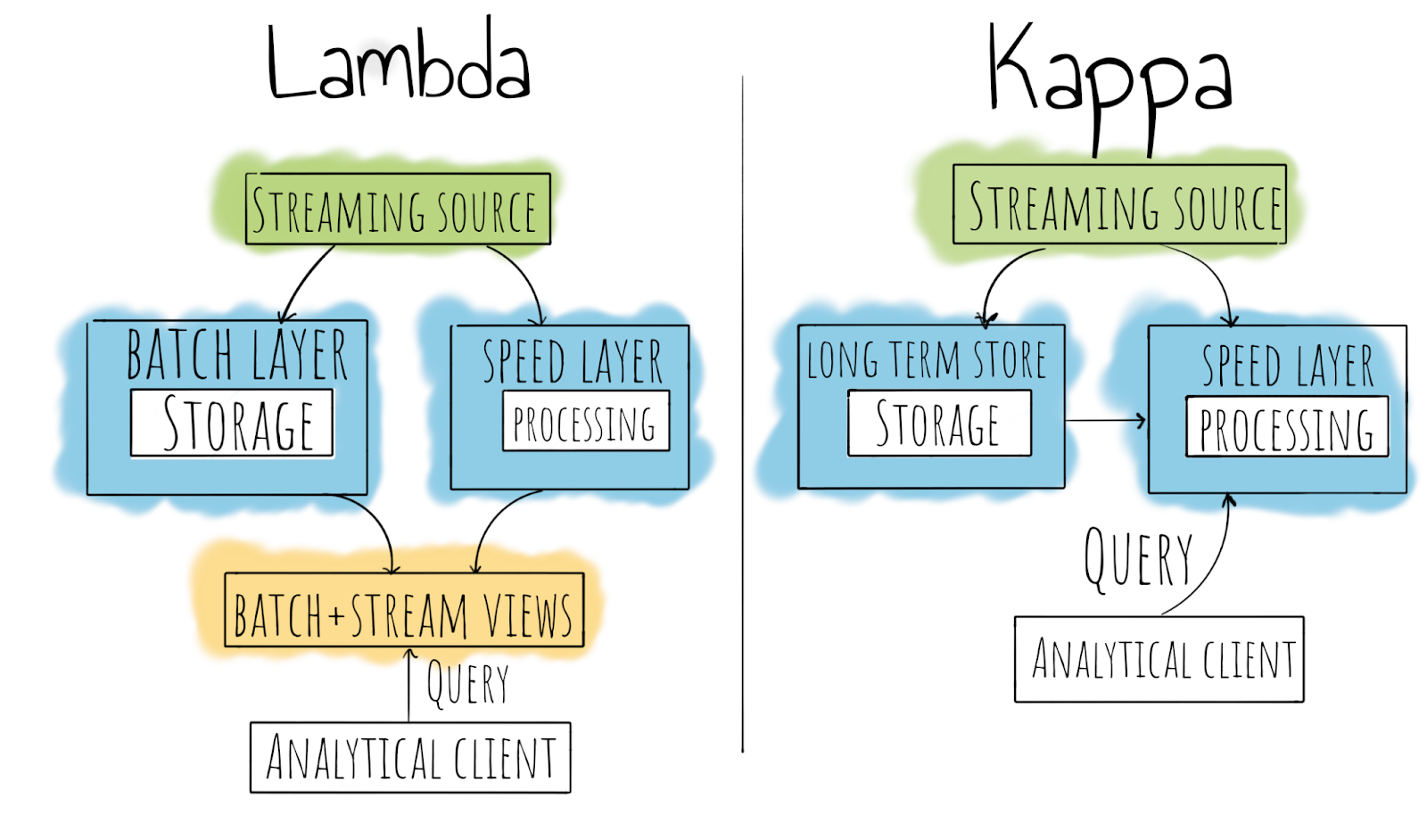
여기 표시된 그림은 무슨 의미일까요? 먼저 용어 몇 가지를 정의해보죠.
속도 계층 – 실시간 데이터 처리를 담당하는 계층입니다. 대개 정밀도와 데이터 처리 속도 사이에 상호 절충 관계가 있습니다.
배치 계층 – 마스터 데이터 스토리지를 담당하는 계층입니다. 이 데이터는 절대 수정이 불가하며 추가 전용 모드로만 저장됩니다.
분석 클라이언트 – 데이터의 소비자로, 자동화된 시스템이거나 사람일 수 있습니다.
그림의 화살표는 빅데이터의 세계, 3부: 데이터 파이프라인 구축에서 다룬 것처럼 데이터 변환 및 전송을 담당하는 처리 메커니즘, 즉 파이프라인입니다.
이제 그림의 상황을 간략히 설명해드리겠습니다.
Lambda 아키텍처에서 스트리밍 소스의 데이터가 배치 계층 및 속도 계층으로 스트리밍됩니다. 다음으로 해당 데이터는 고객이 쿼리를 수행할 수 있는 배치 및 스트리밍 뷰를 형성합니다.
흥미롭고 달성 가능한 듯하지만, 이 아키텍처에는 한 가지 잠재적 문제가 있습니다. 배치 및 스트림 계층에서 다른 도구를 사용할 경우(거의 확실히 그럴 겁니다), 처리 로직을 두 번 구현해야 합니다. 따라서 시스템을 지원하는 데 엔지니어가 추가로 필요하므로 관리가 매우 어려울 수 있습니다.
Kappa 아키텍처는 더 단순합니다. 이 아키텍처의 주요 아이디어는 모든 데이터가 항상 속도 계층을 통과해 배치(장기 저장) 계층에 저장된다는 것입니다. 그러나 Kappa 아키텍처에도 다른 문제가 있습니다. 배치 데이터 뷰가 없을 경우 스트림 프로세서를 확장해야 합니다.
하지만 Kappa 아키텍처에 배치 계층이 필요한 이유는 무엇일까요? 계산 논리가 변경되면 장기 저장소의 모든 데이터를 다시 계산할 수 있습니다. 그리고 장기 저장소는 실제로 스트리밍 소스의 이벤트 로그를 저장하지만, 분석 클라이언트 측에는 아무 변화도 없습니다.
스트리밍 데이터 처리 아키텍처와 관련한 자세한 정보는 다음 글에서 확인하세요.
이 게시물 전체에서 특정 기술에 대한 언급이 없다는 사실을 느끼셨을 겁니다. 그 이유는 아키텍처 패턴이 사실상 기술에 구애받지 않기 때문입니다. 하지만 물론 실제 비즈니스의 실제 아키텍처를 논의할 경우 기술 스택의 선택은 분명 중요합니다.
기술 스택
Lambda 및 Kappa 아키텍처를 논의할 때 항상 스트리밍 소스가 언급됩니다. 실제로 그 역할을 수행할 수 있는 기술은 별로 많지 않습니다. 온프레미스 솔루션용 Apache Kafka 및 Apache Pulsar 또는 솔루션이 클라우드에서 호스팅되는 경우 공급업체 전용 솔루션이 가장 널리 사용됩니다.
모든 웨어하우스는 자체적 스토리지 계층을 보유하며, 이때 선택할 기술 옵션의 범위는 방대합니다. 모든 클라우드 제공업체는 오브젝트 스토리지, 파일 스토리지, 관계형 스토리지, MPP(대량 병렬 처리) 데이터베이스 등 다양한 요구사항에 부합하는 여러 스토리지를 갖추고 있습니다. 아키텍처 구축은 많은 것을 배울 수 있는 좋은 방법입니다.
결론
빅데이터 아키텍처는 매우 광범위한 분야이며, 데이터 엔지니어가 즉시 사용할 수 있는 아키텍처 패턴과 기술이 다양하게 준비되어 있습니다. 궁극적으로 데이터 엔지니어는 비즈니스 및 고객의 요구사항에 따라 솔루션을 선택하게 될 겁니다. 사실 이 분야는 잠시 멈추고, 생각하고, 조사하여 요구 사항을 충족하는 최선의 솔루션을 결정하기에 적합하며 이는 도전적이고 보람찬 작업일 겁니다.
어떤 기술을 선택하시든 JetBrains 제품을 통해 이미 지원될 가능성이 높습니다. 예를 들어, JetBrains DataGrip으로 JDBC 지원 데이터 소스 쿼리를 수행하거나 Big Data Tools 플러그인을 사용해 오브젝트 스토리지의 항목을 확인할 수도 있습니다.
게시물 원문 작성자




