

Big Data World, Part 5: CAP Theorem

This is the fifth installment of our ongoing series on Big Data, how we see it, and how we build products for it. In this episode, we’ll cover the CAP theorem. What is it? Is it correct? And why is it needed for data engineers?
- Big Data World, Part 1: Definitions
- Big Data World, Part 2: Roles
- Big Data World, Part 3: Building Data Pipelines
- Big Data World, Part 4: Architecture
- This article
Table of contents:
The life of a data engineer is basically built on working with distributed systems. Every system they have to work with is distributed, whether storage, computation framework or query engine. Let’s define what we mean by “distributed”.
Distributed systems
We call any system “distributed” when more than one process is involved in communicating. It is not important how many computers, or what kind of computers, you need to run them. It could be a “smart” teapot or a cluster with thousands of high-end nodes, both are considered to be “distributed”.
The limitations of distributed systems are clear: the connection may be unstable or even disappear, data may become inconsistent between processes, and events may come in the wrong order.
In this post, we’ll discuss systems that communicate via a network because there are interesting situations that are easier to model on this kind of system.
Usually, it’s helpful to discuss distributed systems in terms of consistency, availability, and partition tolerance – CAP.
All of us want our distributed systems to be consistent, available, and partition tolerant, but the CAP theorem says that you can only choose 2 of the 3.
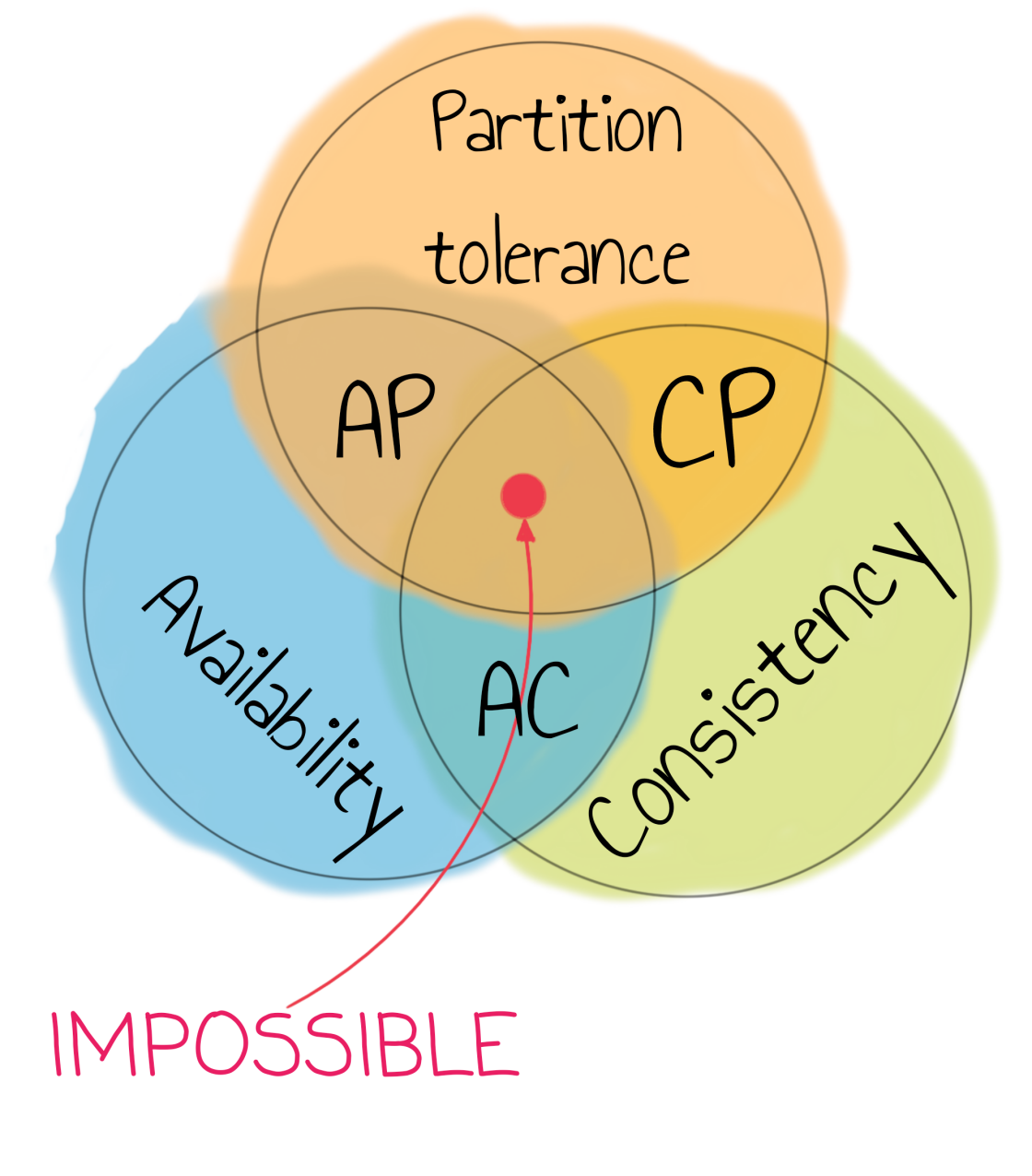
What are consistency, availability, and partition tolerance? Let’s define them.
Consistency
You may already be familiar with consistency from the ACID (Atomicity, Consistency, Isolation, Durability) term, BUT in CAP, the meaning is quite different.
In ACID, consistency is when data doesn’t break constraints like foreign keys in your database. For example, if there is a NULL in a NOT NULL column after the transaction finishes, then it means that this storage is not consistent. If you’re using a database without foreign key support (for example, MySQL with MyISAM storage engine) your data is always consistent (in terms of foreign keys, of course). If your RDBMS does not support strong typing of columns (like SQLite) you can put data of any type into any column, and it will be consistent.
In CAP, consistency is defined much more strictly. A system that satisfies CAP’s consistency should be linearizable. Linearizability is one of the strongest consistency models, which dictates that every operation on an object should be atomic and consistent with the real-time order of operations on such an object.
To better understand what it is and how it works let’s start with a counterexample. Consider the following image:
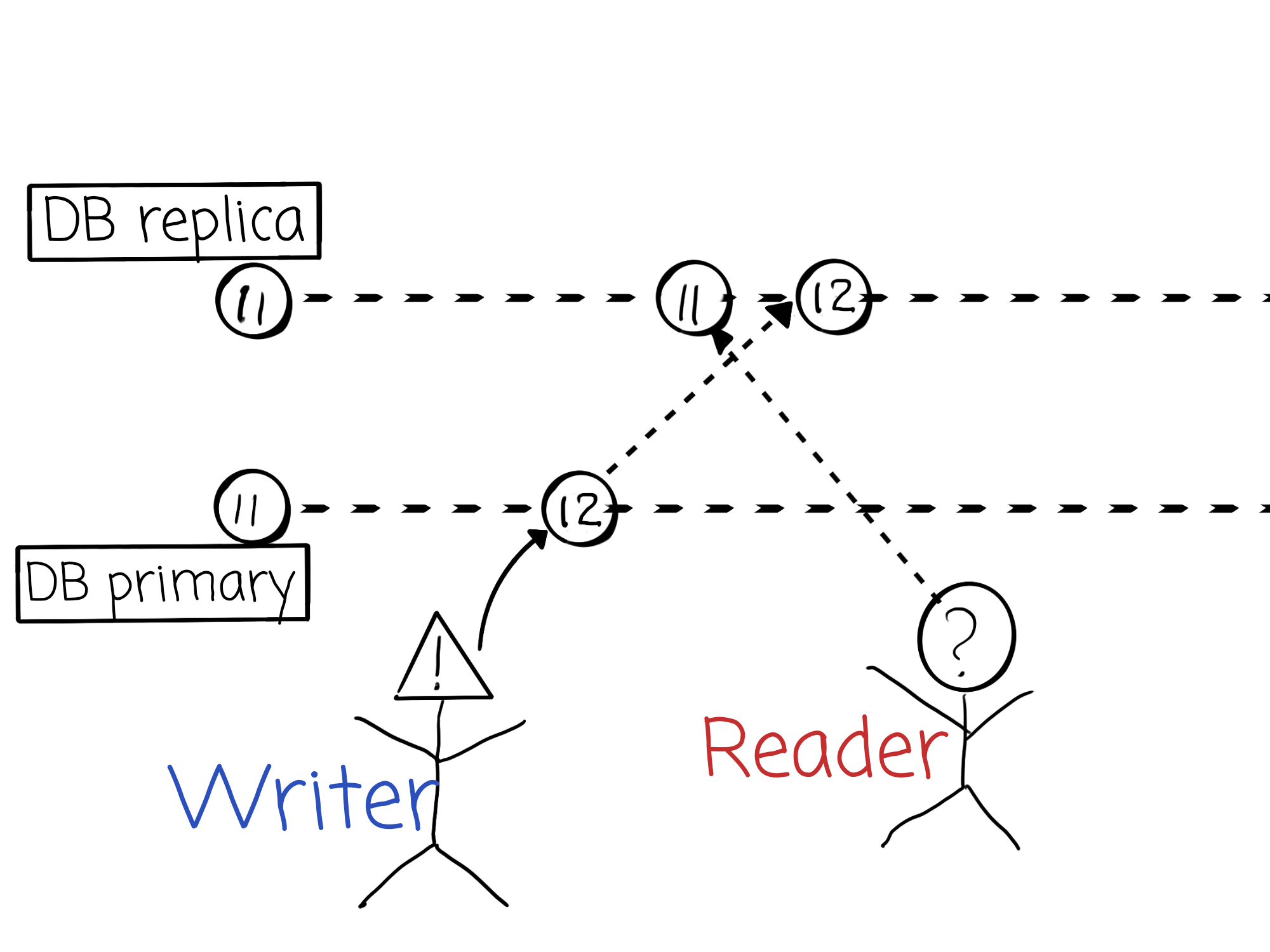
Here we have a distributed system, consisting of 2 database nodes, one of them is primary and the second is a replica. Replication is asynchronous (this is a frequent setup of RDBMS).
- At the start of our virtual time, both instances contain an object with a value of
11 - At some point in time, the actor named
Writerwrites the value12into the object at the primary node. - Immediately after writing, the
WritergetsOKfrom the primary. - A quantum of time later, another actor,
Reader, tries to read our object from the replica. In the perfect world, it would obtain the value12, but replication is asynchronous, so it’s totally possible to get a value of11, too.
That’s it! As soon as we are able to build a scenario where at the same real-time one actor may read data that another actor already modified, the system is not linearizable. If only replication would be synchronous! In this case, the Writer would get OK from the server only after replication from this particular writer would be synchronized to the replica. And so Reader would read before (formal) write ends and the system would be consistent in terms of the CAP theorem.
NB inconsistent in terms of CAP doesn’t imply that it is entirely inconsistent. It’s just another level of consistency, meaning not consistent in terms of CAP, but consistent in other terms. In this particular case, most probably sequentially consistent. You can read more about levels of consistency in the Jepsen blog
Consistency is hard – let’s take a break from it and discuss more straightforward matters.
Availability
What is availability? How fast should a formally available system answer? In a millisecond, second, or minute? While a client is waiting?
Contrary to consistency, which CAP defines very strictly, availability is defined relatively loosely. The available system should answer eventually. It could be after the heat death of the Universe (very cool if you could build a system that would answer something after the heat death of the Universe!). It doesn’t matter at all if the client is still waiting for an answer, so a system that is available in terms of CAP actually should be ready to answer even if there is nobody to answer to.
Availability is simple and a bit boring, so let’s move on to the simple, but exciting, topic of partition tolerance.
Partition tolerance
Partition tolerance is a property of the system, which says that the system should continue to operate correctly in case of a network partition. This part is exciting because there are two tricky parts:
- Network partition
- Correctness
Network partition is an unbound set of situations when nodes of a distributed system cannot see each other or have a degraded connection with each other. Let’s postulate several cases of network partitioning in distributed systems:
- Other nodes may not see one node in the system.
- A group of nodes may see each other but may not see another group of nodes
- One node can see all other nodes, but those nodes can’t see each other
- The network may lose packets
How can this happen in the world of reliable networks? Sadly there is no such thing as a reliable network – many things can go wrong. Network equipment breaks all the time, logically or physically. Ports can burn out, and firmware can hang. People aren’t perfect and make mistakes. For example, incorrectly built QoS rules or routing tables may create an actual network partitioning. Systems operate over the internet, and the internet loses packets all the time, as it’s unstable.
Now it’s time to define what correctness is. Correctness is the ability of the system to fulfill the guarantees it gives. For example, if the system states that it’s available – then it should return an answer eventually, no matter what.
Trade-offs
Since you can only choose 2 out of the three from CAP, it’s time to discuss the possible trade-offs. Indeed, there are only three combinations of two letters from CAP:
- AP
- CP
- AC
One example of an AP system is Cassandra. It means that it will answer no matter what, but sometimes you can find inconsistent (in terms of CAP) answers from it. Fun fact: some time ago Amazon S3 was an AP system too! You could write an object there, and then read it with different content (shorter or missing a part in the middle).
The most prominent CP system examples are relational databases with synchronous replication turned on. They will just not answer if there is partitioning (they will do their best, but it’s not guaranteed). But when the system answers, your answer is guaranteed to be consistent across the whole system.
AC systems are a bit funny in that they are available and consistent until a partition occurs. After that, they are neither available nor consistent. One example of such a system is RabbitMQ with mirrored queues that can unpredictably drop or duplicate messages. In some sense, AC systems are not consistent in terms of CAP because the consistent systems should always be consistent, and they’re only consistent until a partition occurs.
We as data engineers do not operate on only one kind of system – we operate on storages, queues, databases, etc. If we’re using AP and CP systems together, is the whole system consistent, available, and partition tolerant? NO. In the best-case scenario, it will just be partition tolerant. But during partition, the consistent part will be unavailable and the available part of the system will be inconsistent, which means that at least the whole system will be inconsistent too! In the worst-case scenario, it won’t operate correctly during partition either.
Still, there is some criticism of the CAP theorem.
Criticism
- Martin Kleppmann in his beautiful Please stop calling databases CP or AP describes several limitations of the CAP theorem: narrowness of the definitions, that it describes only work with single-register objects, and does not describe transactions, and many others.
- Julia Evans in her awesome A Critique of the CAP Theorem states that the CAP theorem can’t tell us anything about the system. It’s not enough to say “I have a replicated database” to understand where this database lies on CAP. We need much more information to understand a systems’ guarantees.
My answer is this: yes, the CAP theorem is not enough and it’s not very easy to understand. But the CAP theorem gives us a model for thinking about worst-case scenarios, of which we as data engineers (and any engineers working with distributed systems) should understand.
Understanding worst cases is crucial for risk management.
For example, if we’re building a payment system, we would usually prefer it to be consistent over it being available because nobody loves the idea of losing money due to some technical issue. If we’re building a commenting system, we would probably choose availability because it’s better to read some comments than not to see them at all.
Let’s look at the usual data engineering work: building reporting systems. What is more important: availability or consistency? The answer, as always, is it depends! If this is ad-hoc reporting not being used for decision making, but just for quick overviews, we would choose availability. For strategic decision-making, we would probably select consistency.
Conclusion
The CAP theorem is valuable to understand when we’re building our systems. Proof of this theorem looks shaky, but practice shows us that there are no distributed systems that are consistent, available, and partition tolerant all at the same time. We all hope to see such systems, but even building a consistent system is an extremely complex task.
As you’ve seen, RabbitMQ may break expectations if you’re not setting it up to work as a CP system, and at the same time, it may be absolutely OK for your customer to have inconsistent data in a reporting system. What we should take away from this is that the functionality of the system is not enough to make a decision about its usage. We should also be aware of its guarantees.
Data engineers are people who build complex, multi-layered storages, as described in Big Data World, Part 4: Architecture and should, in my opinion, be aware of the trade-offs their systems introduce.
Further reading:
- Julia Evans’s blog, where we can find lots of interesting articles on distributed systems and networks.
- Jepsen blog, a blog with analysis of different systems by Aphyr
- Martin Kleppmann’s blog and his book on Designing Data-Intensive Applications
And remember, with great power comes great responsibility!




