

TeamCity
Powerful CI/CD for DevOps-centric teams
Benchmarking TeamCity

How many agents can be handled by TeamCity server?
This is our official reply to the question in the title:
The latest TeamCity version is known to work well with up to 300 build agents (300 concurrently running builds actively logging build run-time data). In synthetic tests the server was functioning OK with as many as 500 agents (the server with 8 cores, 32Gb of total memory running under Linux, and MySQL server running on a separate comparable machine).
This reply is based partly on our own experience and partly on our internal benchmarks. In this post I’ll explain what kind of benchmarks we use and will also show some of the results measured against the latest TeamCity version – 9.1.1.
We’ll start with the TeamCity architecture first: this will let us understand results better.
As you already know, TeamCity consists of a server and a number of agents. Agents run builds and send results (build log, artifacts, tests, etc.) back to the server. Most of the time the results are being sent in real time, while build is still running, which allows us to show a nice real-time progress of the build in the web interface, send notifications early, and so on.
An agent sends results to the server by the RPC protocol established over HTTP. During processing of these results, the server stores data in the build log on the file system and can also write some data into the database. For instance, all statistic values, as well as the information about tests (name, duration, status) are stored in the database.
Both the agent and the server maintain buffers for the build results data: the agent sends results to the server when the buffer becomes full, the server also processes results in packs, because it greatly improves performance. To reduce concurrency costs on the server side and in the database, all build results on the server side are processed by N worker threads, where N roughly equals to the number of cores. So even if we have 300 agents sending results at the same time, they will be processed on the server with the concurrency not greater than the number of cores.
So what happens if the server cannot sustain the load? All running builds have bounded message queues, so if these queues become full because workers cannot keep up with the data from agents, agents will get blocked on an attempt to add new data from builds. As a result, the build time will start increasing. When this happens, we can observe that the build script itself has already finished on the agent, but the server still did not mark the build as finished because it is still processing the build results.
This brings us to a simple idea of the benchmark: we need to generate build logs from a lot of agents for some time with a constant rate; then we need to stop the load generator and measure the amount of build logs processed on the server up to this time. Once we know the duration of the benchmark and the rate of build log generation, we can estimate the amount of build logs which should’ve been processed. Having this delta (estimated amount – actual amount) we can judge whether the server is ok with the load or not.
Meet Benchmark plugin
This benchmark idea has been implemented as a TeamCity plugin. The plugin adds additional tab under the Administration -> Diagnostics page. On this tab you can configure benchmark parameters, such as: the number of concurrently running builds, the duration of benchmark, the build log output rate and others.
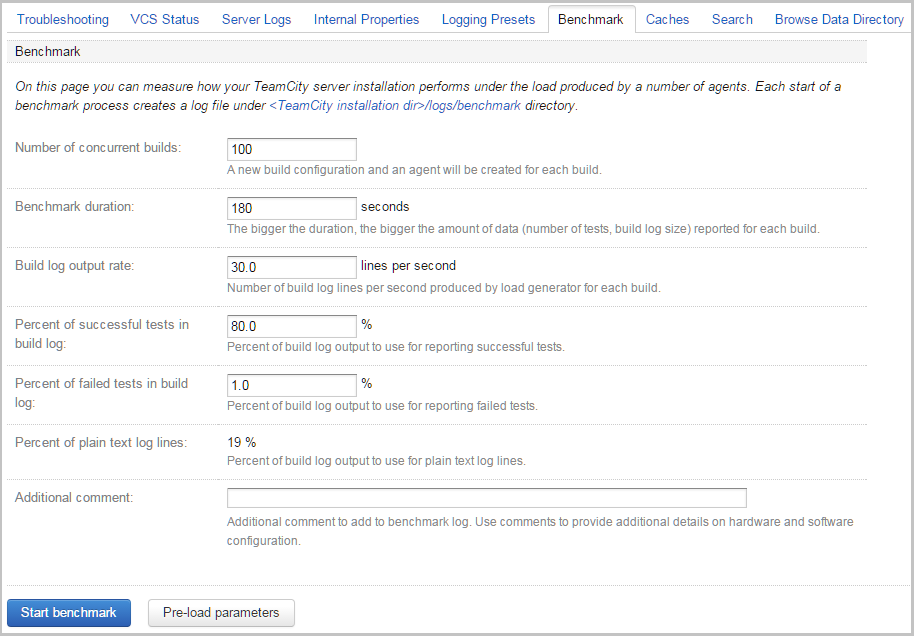
Some of the fields require additional explanation:
- Build log output rate – the number of log lines produced by a build per second
- Percent of successful tests in build log – assuming that one line of the build log represents a test, this is the percent of build log lines to allocate for tests reporting. So if the build log output rate is set to 30 lines per second, and the percent of successful tests is set to 50, then the load generator will produce 15 tests per second and 15 other random log lines for each build.
- Percent of failed tests in build log – the meaning is the same as with the successful tests percent; note that the sum of and cannot exceed 100.
Note that the build log output rate and percent of successful and failed tests can be pre-calculated based on builds history of projects already configured on the TeamCity server (see “Pre-load parameters” button).
The benchmark workflow is pretty simple. When the benchmark starts, it:
- creates a dedicated agents pool named Benchmark with the number of agents equal to the number of configured concurrently running builds
- creates a project with build configurations where builds will start: one configuration for each build
- adds all builds to the queue and waits till builds start
- spawns the load generator as a separate java process and waits till it finishes
- cleans up the data: stops builds, removes the project and build configurations, removes the agents and the agent pool; cleanup is also performed if the benchmark is interrupted using the Stop button.
The log file for each benchmark is stored in a separate file under the <TeamCity logs directory>/benchmark folder. If additional comments are specified, they will be stored in the benchmark log as well.
Benchmark results
So we’ve done some measurements on our own hardware:
TeamCity server:
- CPU: Core i7-4790, 3.6GHz
- RAM: 32Gb
- SSD: Intel 530, 240Gb
- HDD: Seagate Barracuda ES (ST3500320NS), 7200RPM
Database server:
- CPU: Core i7-4790, 3.6GHz
- RAM: 32Gb
- SSD: Intel 530, 240Gb
- HDD1: Western Digital Velociraptor (WD3000HLFS), 10000RPM
- HDD2: Western Digital Caviar Blue (WD6400AAKS), 7200RPM
Ubuntu 14.0.4 was installed on both servers. In case of the TeamCity server, the TeamCity data directory was placed on an HDD. On the database server, the data files and transaction logs were placed on an SSD. In all of the cases the Ext4 file system was used.
Percona server 5.6.25 was installed on the database server machine. We’ve selected Percona because it is well known for it’s performance optimizations compared to regular MySQL. The following parameters were changed in my.cnf file:
innodb_buffer_pool_size=10G
innodb_buffer_pool_instances=8
innodb_file_per_table=1
innodb_flush_log_at_trx_commit=0
innodb_log_file_size=512M
innodb_log_files_in_group=3
thread_handling=pool-of-threads # Percona and MariaDB only
TeamCity server was started under Java 1.8.0_45 with Xmx set to 3Gb.
To make the benchmark results more realistic, we set up a few open source projects and measured their build log output rate using the “Pre-load parameters” feature. See the results below:
| Project name | Build log output rate per build | Percent of build log used by successful tests | Resulting tests rate per build |
| commons-math | 71 lines/sec | 80% | 57 tests/sec |
| JUnit | 46 lines/sec | 61% | 28 tests/sec |
| Maven | 45 lines/sec | 28% | 12.6 tests/sec |
| Spring Framework | 20 lines/sec | 50% | 10 tests/sec |
| Netty | 30 lines/sec | 21% | 6.3 tests/sec |
| Hibernate ORM | 60 lines/sec | 5% | 3 tests/sec |
Let’s see how these numbers are calculated:
- build log output rate = <total number of log lines> / <build duration>
- tests rate – assuming that each test is represented in the build log by at least one line:
tests rate = <build log output rate> * <number of tests> / <total number of log lines>
As you can see, these formulas do not take the test duration into account. So even if there are lots of fast tests with the duration of 1ms, but besides running tests a build also performs other time consuming tasks, the resulting tests rate will be far from 1000 per second. This is especially true when many builds are running concurrently on the real server. In this case the builds will be in different states: some can run tests, others download artifacts, compile code, etc, etc. So we can safely say that it is unlikely that there will be a situation when all of them report tests with the rate of 1000 per second at the same time. As a result, the real load which can be sustained by the server is much bigger than one would expect by simply looking at the duration of individual tests.
Final results
For each of these projects we measured the maximum number of concurrently running builds our system can sustain without significant increase of the build duration (10% increase in build duration was considered acceptable). See the results below:
| Project name | Max number of concurrently running builds | CPU usage (server/database) |
| commons-math | 320 | 42% / 20% |
| JUnit | 570 | 40% / 18% |
| Maven | 990 | 50% / 15% |
| Spring Framework | 1300 | 52% / 15% |
| Netty | 1600 | 58% / 10% |
| Hibernate ORM | 1650 | 60% / 9% |
Some observations:
- even with this hardware which is not quite optimal for the server tasks, some very promising results can be achieved
- the more tests produced by the build per second, the smaller the resulting number of agents concurrently running builds; in our case commons-math has rate of 57 tests per second which may not sound like a lot, but surprisingly the majority of projects have much lower rate of tests. In general, the bigger the project, the slower its tests, which is understandable, as besides tests, build scripts also perform lots of other time-consuming tasks
- the bigger the rate of the build log output, the bigger the load produced on the TeamCity server machine; with the large number of agents, the CPU usage on the TeamCity server machine reached 60%; obviously, it is not a good idea to dedicate 60% of CPU just to process data from agents as there are other CPU intensive tasks which should be done by TeamCity server
- the load generator worked as a separate java process, and at peak times it took some CPU as well, although this time was negligible comparing to the CPU time used by the server
- the CPU usage on the database server only reached 20% which probably can be explained by a very simple workload imposed by our test – mostly inserts, no complex queries at all
Note that the results of this benchmark cannot be applied blindly simply because this benchmark is a synthetic test and, like many other synthetic tests, it does not entirely represent the real life. For now it only measures one aspect of the server performance. It does not cover things like artifacts downloading and publishing, user requests, VCS operations, etc, etc.
On the other hand, if you plan to move your server to new hardware, this benchmark can help you to tune the hardware, disks and database parameters to achieve better performance.
How to run benchmark on your own server
The Benchmark plugin is available for download.
The plugin is compatible with TeamCity 9.1.x.
If you want to try this plugin on your hardware, please read our suggestions below.
The plugin creates agents and each agent needs to be authorized, which means you should have enough agents licenses to run benchmarks. Besides, using this plugin on the production server may be a tempting idea, but the plugin can impose a significant load on the system, making it hard to use by other users. Moreover, in case of bugs in the plugin or server crashes, you can end up with lots of data which was not properly cleaned up – agents pool, agents, projects, etc. Finally, it may not be easy to fine tune the production system for better results as it requires downtime.
Because of that we recommend to setup a separate server, obtain an evaluation license from our site to be able to run the server with unlimited agents, and then run benchmarks on this system. Note that using the latest TeamCity version is also recommended as it may have significant performance improvements comparing to the version you’re using now.
Take a look at our documentation if you’re going to use MySQL or PostgreSQL database.
We would not recommend using HSQLDB for this benchmark: since we don’t recommend this database for production use, benchmarking against it is pointless. It’s a good database engine, but it is not as reliable and scalable as “big” databases. Big databases implement sophisticated approaches to keep your data safe (see for example: http://www.postgresql.org/docs/current/static/wal-reliability.html or https://www.percona.com/blog/2006/08/04/innodb-double-write/). HSQLDB being a database written in Java does not have a chance to implement similar reliability as it does not have proper access to hardware.
While running benchmarks, make sure to run them a few times, or at least run them with the duration not less than 180 seconds as this makes results more predictable. It is also recommended to perform a few warm up benchmarks after the server startup. Finally, if you choose to tune some parameters in the database or elsewhere, make sure to change one parameter at a time. Otherwise you may fail to notice which parameters give you better results.
Benchmarking is fun, but be prepared to spend tons of time on it!
We hope that you will use this plugin to assess your server performance, so if you do decide to run this benchmark, we will be really interested in seeing your results.
Happy benchmarking and building!





