
Upsource
Code Review and Project Analytics
What to look for in a Code Review: Data Structures

This is part 4 of 6 posts on what to look for in a code review. See previous posts from the series.
Data structures are a fundamental part of programming – so much so it’s actually one of the areas that’s consistently taught in Computer Science courses. And yet it’s surprisingly easy to misuse them or select the wrong one. In this post, we’re going to guide you, the code reviewer, on what to look out for – we’re going to look at examples of code and talk about “smells” that might indicate the wrong data structure was chosen or that it’s being used in an incorrect fashion.
Lists
Probably the most common choice for a data structure. Because it is the most common choice, it’s sometimes used in situations it shouldn’t be.
Anti-Pattern: Too Much Searching 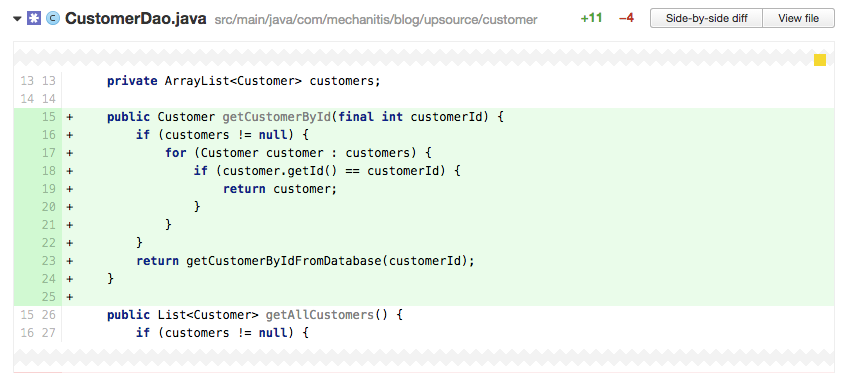 Iterating over a list is not, in itself, a bad thing of course. But if iteration is required for a very common operation (like the example above of finding a customer by ID), there might be a better data structure to use. In our case, because we always want to find a particular item by ID, it might be better to create a map of ID to Customer.
Iterating over a list is not, in itself, a bad thing of course. But if iteration is required for a very common operation (like the example above of finding a customer by ID), there might be a better data structure to use. In our case, because we always want to find a particular item by ID, it might be better to create a map of ID to Customer.
Remember that in Java 8, and languages which support more expressive searches, this might not be as obvious as a for-loop, but the problem still remains.
Anti-Pattern: Frequent Reordering
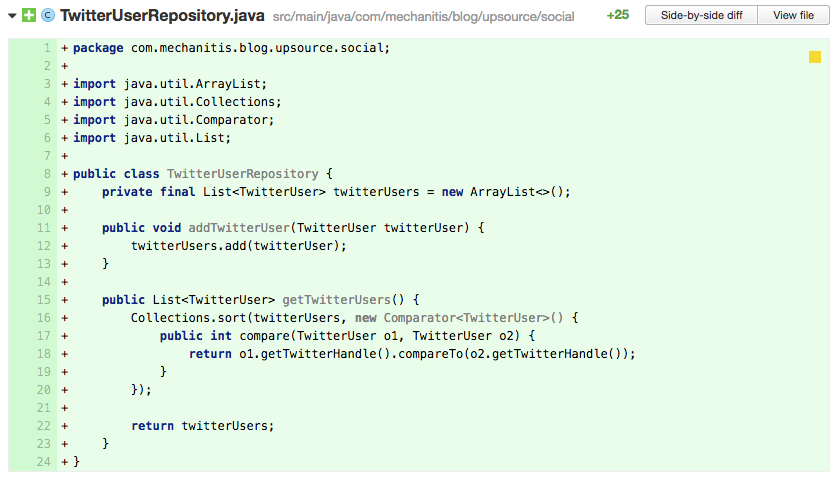
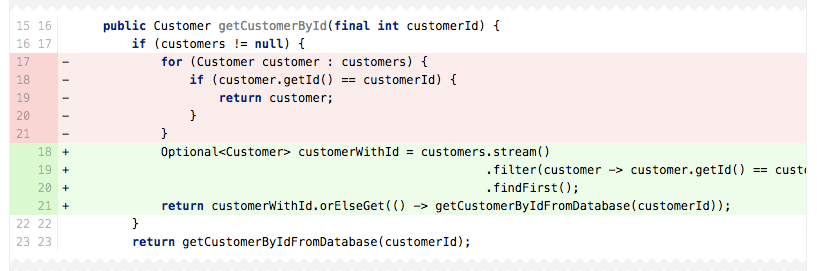
Lists are great if you want to stick to their default order, but if as a reviewer you see code that’s re-sorting the list, question whether a list is the correct choice. In the code above, on line 16 the twitterUsers list is always re-sorted before being returned. Once again, Java 8 makes this operation look so easy it might be tempting to ignore the signs:

Upsource shows the pre-Java-8 method of sorting (lines 16-20, in red) replaced with the Streams solution (line 16, in green)
In this case, given that a TwitterUser is unique and it looks like you want a collection that’s sorted by default, you probably want something like a TreeSet.

Upsource’s side-by-side diff with the change
Maps
A versatile data structure that provide O(1) access to individual elements, if you’ve picked the right key.
Anti-Pattern: Map as global constant
The map is such a good general purpose data structure that it can be tempting to use globally accessible maps to let any class get to the data.
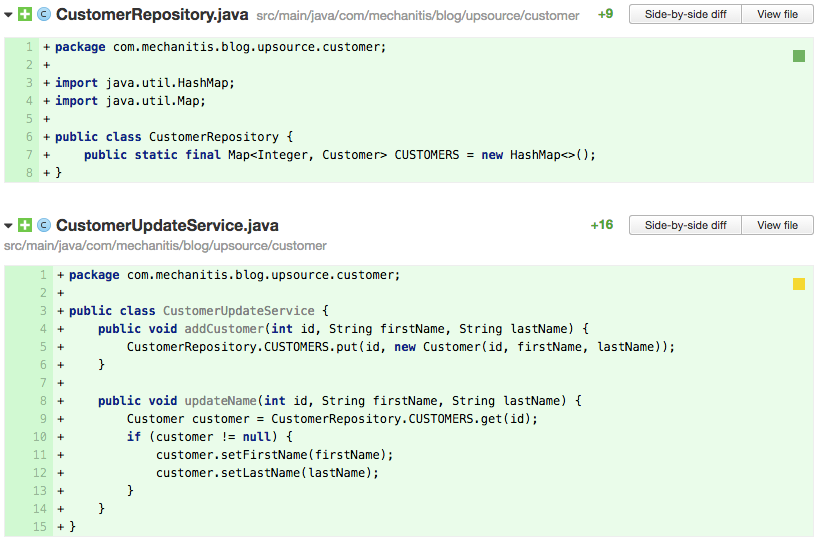
In the above code, the author has chosen to simply expose the CUSTOMERS map as a global constant. The CustomerUpdateService therefore uses this map directly when adding or updating customers. This might not seem too terrible, since the CustomerUpdateService is responsible for add and update operations, and these have to ultimately change the map. The issue comes when other classes, particularly those from other parts of the system, need access to the data.
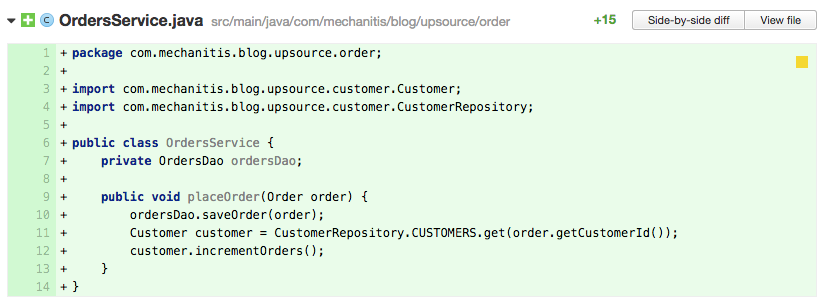
Here, the order service is aware of the data structure used to store customers. In fact, in the code above, the author has made an error – they don’t check to see if the customer is null, so line 12 could cause a NullPointerException. As the reviewer of this code, you’ll want to suggest hiding this data structure away and providing suitable access methods. That will make these other classes easier to understand, and hide any complexity of managing the map in the CustomerRepository, where it belongs. In addition, if later you change the customers data structure, or you move to using a distributed cache or some other technology, the changes associated with that will be restricted to the CustomerRepository class and not ripple throughout the system. This is the principle of Information Hiding.
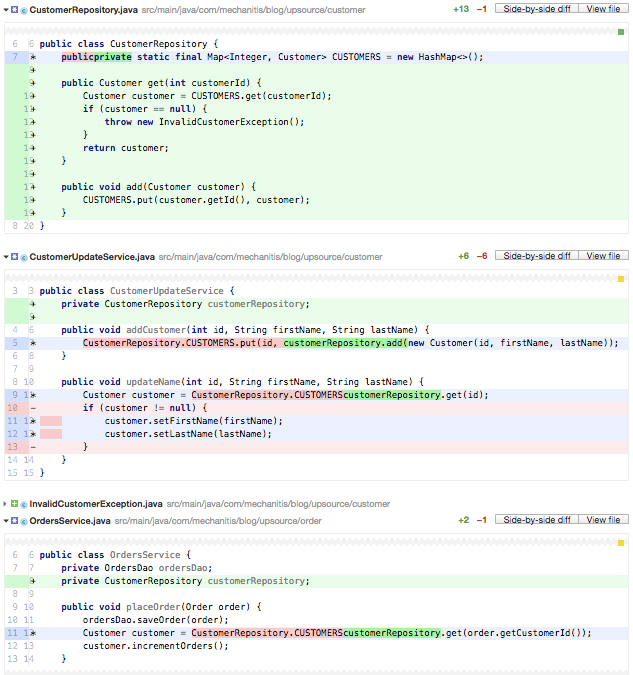
Although the updated code isn’t much shorter, you have standardised and centralised core functions – for example, you know that getting a customer who doesn’t exist is always going to give you an Exception. Or you can choose to have this method return the new Optional type.
Note that this is exactly the sort of issue that should be found during a code review – hiding global constants is hard to do once their use has propagated throughout the system, but it’s easy to catch this when they’re first introduced.
Other Anti-Patterns: Iteration & Reordering
As with lists, if a code author has introduced a lot of sorting of, or iterating over, a map, you might want to suggest an alternative data structure.
Java-specific things to be aware of
In Java, map behaviour usually relies on your implementation of equals and hashCode for the key and the value. As a reviewer, you should check these methods on the key and value classes to ensure you’re getting the expected behaviour.
Java 8 has added a number of very useful methods to the Map interface. The getOrDefault method, for example, could simplify the CustomerRepository code at line 11 in the example above.
Sets
An often-underused data structure, its strength is that is does not contain duplicate elements.
Anti-pattern: Sometimes you really do want duplicates
Let’s assume you had a user class that used a set to track which website they had visited. Now, the new feature is to return the most recently visited of these websites.
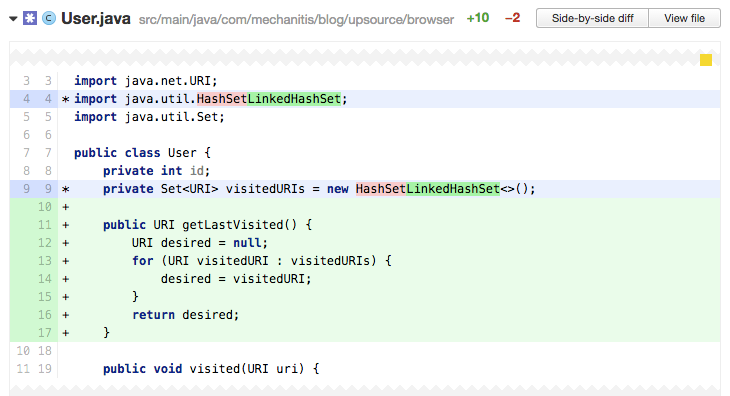
The author of this code has changed the initial set that tracks the sites a user has visited from HashSet to LinkedHashSet – this latter implementation preserves insertion order, so now our set tracks every URI in the order in which they were visited.
There are a number of signs in this code that this is wrong though. Firstly, the author has had to do a costly full iteration of the whole set to reach the last element (lines 13-15) – sets are not designed for accessing elements by position, something that lists are perfect for. Secondly, because sets do not contain duplicate values, if the last page they visited had been visited previously, it will not be in the last position in the set. Instead, it will be where it was first added to the set.
In this case, a list, a stack (see below), or even just a single field, might give us better access to the last page visited.
Java-specific things to be aware of
Because one of the key operations of a set is contains, as a reviewer you should be checking the implementation of equals on the type contained in the set.
Stacks
Stacks are a favourite of Computer Science classes, and yet in the real world are often overlooked – in Java, maybe this is because Stack is an extension of Vector and therefore somewhat old-fashioned. Rather than going into a lot of detail here I’ll just cover key points:
- Stacks support LIFO, and should ideally be used with push/pop operations, it’s not really for iterating over.
- The class you want for a stack implementation in Java (since version 1.6) is Deque. This can act as both a queue and a stack, so reviewers should check that deques are used in a consistent fashion in the code.
Queues
Another CS favourite. Queues are often spoken about in relation to concurrency (indeed, most of the Java implementations live in java.util.concurrent), as it’s a common way to pass data between threads or modules.
- Queues are FIFO data structures, generally working well when you want to add elements to the tail of the queue, or remove things from the front of the queue. If you’re reviewing code that shows iteration over a queue (in particularly accessing elements in the middle of the queue), question if this is the correct data type.
- Queues can be bounded or unbounded. Unbounded queues could potentially grow forever, so if reviewing code with this type of data structure, check out the earlier post on performance. Bounded queues can come with their own problems too – when reviewing code, you should look for the conditions under which the queue might become full, and ask what happens to the system under these circumstances.
A general note for Java developers
As a reviewer, you should be aware not only of the characteristics of general data structures, but you should also be aware of the strengths and weaknesses of each of the implementations all of which are documented in the Javadoc:
If you’re using Java 8, remember that many of the collections classes have new methods. As a reviewer you should be aware of these – you should be able to suggest places where the new methods can be used in place of older, more complex code.
Why select the right data structure?
We’ve spent this blog post looking at data structures – how to tell if the code under review might be using the wrong data structures, and some pointers for the pros and cons of various data structure so not only can you, as the reviewer, identify when they might be being used incorrectly, but you can also suggest better alternatives. But let’s talk about why using the right data structure is important.
Performance
If you’ve studied data structures in computer science, you’ll often learn about the performance implications of picking one over another. Indeed, we even mentioned “Big O Notation” in this blog post to highlight some of the strengths of particular structures. Using the right data structure in your code can definitely help performance, but this is not the only reason to pick the right tool for the job.
Stating Expected Behaviour
Developers who come to the code later, or who use any API exposed by your system, will make certain assumptions based on data structures. If the data returned from a method call is in a list, a developer will assume it is ordered in some fashion. If data is stored in a map, a developer can assume that there is a frequent need to look up individual elements by the key. If data is in a set, then a developer can assume it’s intentional that this only stores an element once and not multiple times. It’s a good idea to work within these assumptions rather than break them.
Reducing Complexity
The overall goal of any developer, and especially of a reviewer, should be to ensure the code does what it’s supposed to do with the minimal amount of complexity – this makes the code easier to read, easier to reason about, and easier to change and maintain in the future. In some of the anti-patterns above, for example the misuse of Set, we can see that picking the wrong data structure forced the author to write a lot more code. Selecting the right data structure should, generally, simplify the code.
In Summary
Picking the right data structure is not simply about gaining performance or looking clever in front of your peers. It also leads to more understandable, maintainable code. Common signs that the code author has picked the wrong data structure:
- Lots of iterating over the data structure to find some value or values
- Frequent reordering of the data
- Not using methods that provide key features – e.g. push or pop on a stack
- Complex code either reading from or writing to the data structure
In addition, exposing the details of selected data structures, either by providing global access to the structure itself, or by tightly coupling your class’s interface to the operation of an underlying data structure, leads to a brittleness of design, and will be hard to undo later. It’s better to catch these problems early on, for example during a code review, than incur avoidable technical debt.



