

On Writer's Side
Intelligent tools for writers and new ways to write better
Content reuse – a productivity booster or a vicious circle?
Single-source publishing is a powerful must-have feature that is normally among the top three competitive advantages for any professional help authoring solution – and for good reason. Single-sourcing reusable content lets you:
- Maintain consistency throughout your documentation in terms of style, terminology, the level of detail, and so on.
- Avoid making multiple updates when a user interface or a workflow changes.
- Reduce the review and editing effort.
- Reduce the localization costs.
- Automate the routine – reproducing the same pieces of content repeatedly adds mundane work and duplicates your efforts.
While we don’t argue with the benefits of single-source publishing, in this post we would like to draw your attention to its pitfalls so that you are forewarned and can reuse content wisely.
At JetBrains, we reuse content a lot. If you are familiar with our IDEs, you’ll know that they are built on top of the IntelliJ platform, meaning there is a lot of shared content that goes into multiple documentation instances under different filters and conditions.
Here’s a simplified scheme to give you an idea of how entire articles and smaller chunks of content are reused between different documentation instances:
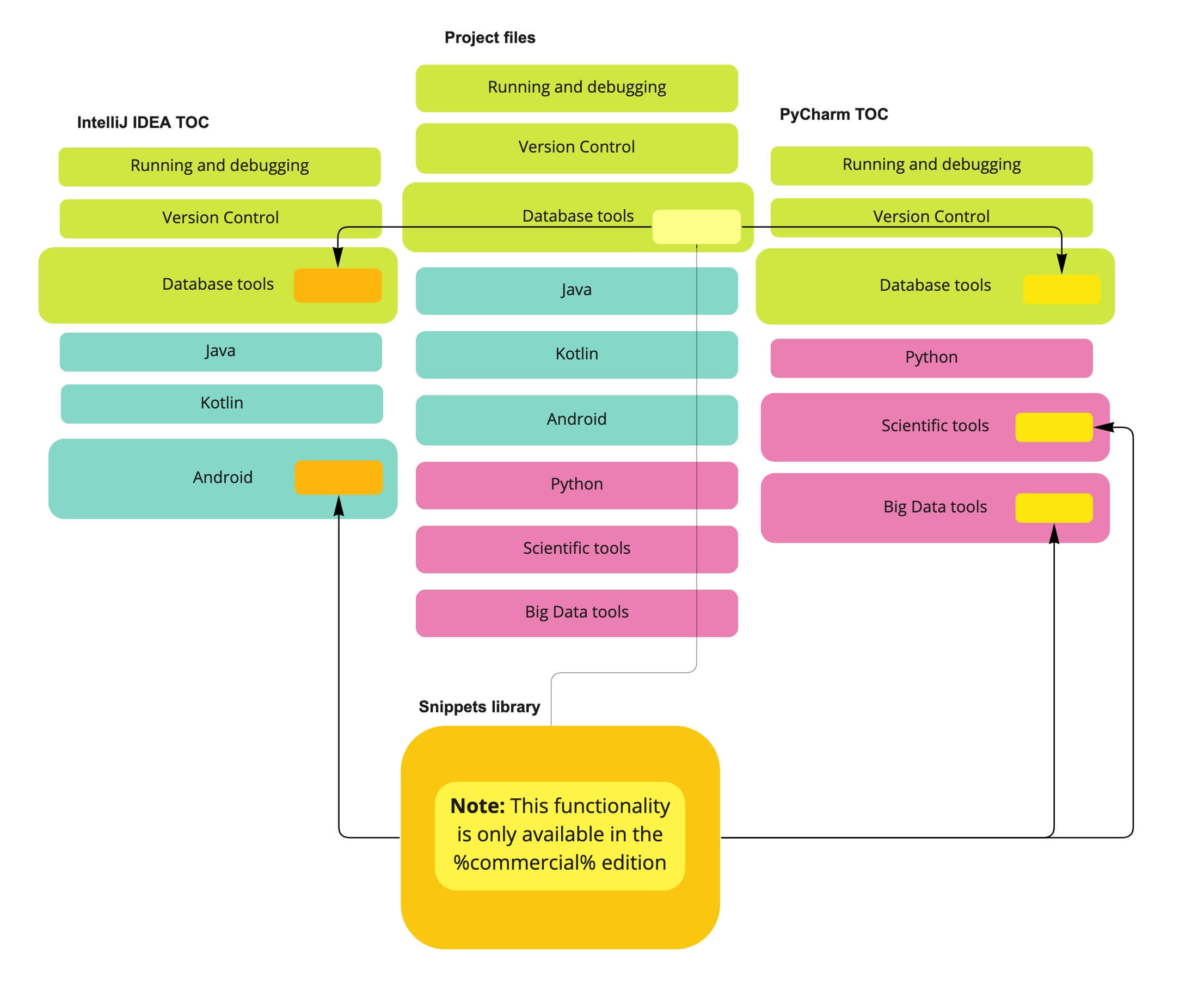
We have 21 online help instances built from the same set of source files, and about two dozen tech writers contribute to this project, so we know single-source inside and out and have fallen into every one of its traps before.

In this post, we’ll look at a few of these traps, which I’ve dubbed as follows:
- Abuse of reuse
- Source code reduction
- Misuse of reuse
- Traffic cannibalization
1. Abuse of reuse
Tools powered with single-source features allow you to include reused content under conditions and filters, thus giving you a lot of flexibility. Sometimes too much flexibility, really.
Let’s look at an example of content reuse with conditions where filters are justified. Here, filters are used because programming languages have different components. For example, in Java you would search for usages of a method, while in C++ this would be called a function, and in database tools you would search for usages of a table, column, or key.
So filters here are legitimate.
<tip-of-the-day id="FindUsages">
<p>
You can view the list of all usages of a
<for product="ij,py,ws,ps,rm">method</for>
<for product="cl">function</for>
<for product="db">table, column, or key</for>
across the whole project, and quickly navigate to the selected item.
</p>
</tip-of-the-day>
Now let’s look at another example:
<tip-of-the-day id="ChangeSorting" product="ij,py,ws">
<p product="ij">
You can sort completion suggestions by relevance
or alphabetically.
</p>
<p product="py">
By default, completion suggestions are sorted by relevance,
but you can sort them alphabetically bу selecting the
<control>Sort by Name</control> option.
</p>
<p product="ws">
To choose how you want to sort completion suggestions - by name
or relevance - toggle the <control>Sort by Name</control> checkbox.
</p>
</tip-of-the-day>
Can you guess what’s wrong here? All three paragraphs here are about exactly the same thing. The only thing different is the wording and the level of detail. Nothing is actually reused here at all apart from the title.
🪴 Root cause
There are a few reasons why things like this happen:
- Writers think they can come up with better wording than the original piece, but they don’t feel comfortable replacing their peer’s work with their variant.
- Writers are affected by feedback from a user who’s not satisfied with the level of detail, and add redundant information as a reaction to feedback.
⚖️ Weigh the gains against losses
Do you remember the reasons to bother about reuse? Let’s weigh them against this example:

💡 How to avoid
Here are some strategies that we have implemented in our writers’ team to help us prevent things like this from happening:
- We’ve developed an in-house style guide. In many cases, it helps us avoid abuse of reuse, as there’s an agreement on how much detail to provide, the tone of voice, and so on, so that these things are not a matter of a writer’s personal taste.
- We’ve automated checks against our style conventions so that style violations are highlighted in the editor and the author is prompted to rephrase. There are different ways to implement such checks depending on the editor you use. If you are using a JetBrains IDE, you may want to check out the Grazie Professional plugin that supports Vale syntax and has built-in checks against some popular style guides.
- In our team, we have agreed on the “improve for yourself – improve for everyone” principle. You don’t need to be shy about improving a piece of text for everyone instead of multiplying similar chunks.
- We are also working on implementing a syntax checker that would detect non-exact duplicates and suggest extracting them to a library so that they can be reused. We already have an MVP of this linter ready to use, but we are also looking at different approaches that might involve technologies like ElasticSearch, machine learning, and others.
2. Source code reduction
Sometimes you want to edit a page and open the source file, and what you see is just a couple of lines behind a web page that’s several screens long. Instead of being able to easily locate the piece you want to update, you find multiple includes wrapped into one another with filters and variables declared God-knows-where, and it takes you a while to figure out what the text you see on a web page actually resulted from.
Here’s an example of such code reduction from my recent talk at Write the Docs Portland conference:
🪴 Root cause
Since our company makes developer tools, we as writers work closely with developers and write for developers. We often tend to adopt developer approaches, and we even author docs in an IDE. So we sometimes get carried away with the beauty and brevity of source code reduced to a single line that lets you unveil layers of content behind it like a nesting doll.
⚖️ Weigh the gains against losses
Now let’s look back at our benefits list and test this example against them.

💡 How to avoid
Honestly, this is not something that we at JetBrains are champions at, but as a team, you need to find a balance between reusing everything that could possibly be reused and keeping your code readable and searchable. We suggest you try sticking to the following principle:
Just because you can doesn’t mean you should.
Sometimes it’s better to choose some duplication over the wrong abstraction and put up with less than 100% reuse. Otherwise you may complicate your life by creating source code that is rigid and difficult to maintain and reuse. And the investment you’ve made into reducing it can never be recovered.
3. Misuse of reuse
Sometimes, you realize you’ve been writing the same phrase (like a path to a settings page) several times a week. It’s only natural to be tempted into thinking that if you are repeating yourself so often, you must be doing something wrong and it makes sense to reuse it.
Here’s a procedure that tells you how to configure something in an IDE.

Let’s look at the source code behind the first step:
<include src="PREF_CHUNKS.xml" include-id="step_open_settings_page">
<var name="page_path"
value="Build, Execution, Deployment | %language% Profiler"/>
</include>
<chunk id="step_open_settings_page">
<step>
<include src="PREF_CHUNKS.hml" include-ide="open_settings_page"/>
</step>
</chunk>
<chunk id="open_settings_page">
Press <shortcut key="ShowSettings"/> to open the IDE settings and select
<control>%page_path%</control>.
</chunk>
To reuse everything that can potentially be reused here, you need to introduce variables and wrap reusable snippets into one another. So, in the end, there are 10 lines of code behind this little sentence. And I’m asking myself – is it really worth it?
🪴 Root cause
In software development, there’s a principle called “DRY”. It was formulated as early as 1999 in a book called “The pragmatic Programmer”. “DRY” here stands for “Don’t Repeat Yourself” and it’s aimed at reducing repetition of software patterns and replacing it with abstractions to avoid redundancy.
Just like in programming, this principle is often misunderstood by technical writers who are tempted to re-use anything that could potentially be reused and wrap multiple reusable snippets into one another, thus creating complex markup structures where changing one element breaks the logic for other dependent elements.
⚖️ Weigh the gains against losses

💡 How to avoid
What can we do about it?
- Remember that the “DRY” principle doesn’t always work. If you strive to achieve perfect reuse, you may end up implementing a tangled ball of dependencies and it will be very difficult for your teammates to understand and maintain the code.
- Wikipedia tells you that the opposite of the “DRY” principle is the “WET” principle, which stands for “Write Every Time” or “We Enjoy Typing” or even “Waste Everyone’s Time”. However, I would suggest that the opposite should be the “KISS” principle introduced in the 1960s in the US navy that stands for “Keep it Simple, Stupid”. This states that most systems work best if they are kept simple rather than made complicated.
- Think of other means to achieve your goal. In this example, the ultimate goal of the author was to automate the routine task of typing the same phrase. Just like in a programming language, there are usually multiple ways to achieve the same goal. In this case, you could create a template or a completion pattern and assign a hot-key combination to it so that you can paste the required text with a couple of keystrokes.
Wouldn’t that be easier for everyone?
4. Traffic cannibalization
In the previous four sections, we talked about the pits that content authors may fall into if they don’t weigh the gains of content reuse against possible losses. This one affects our customers – the people who read technical documentation.
Web content cannibalization happens when you pull your audience in more than one direction.
That’s exactly what happens when you reuse content and publish identical chunks of it to multiple outputs on the web. Search engines like Google just ignore some of the web pages because identical content already exists on a different page and it’s ranked higher in search results.
This is an example of a search query.
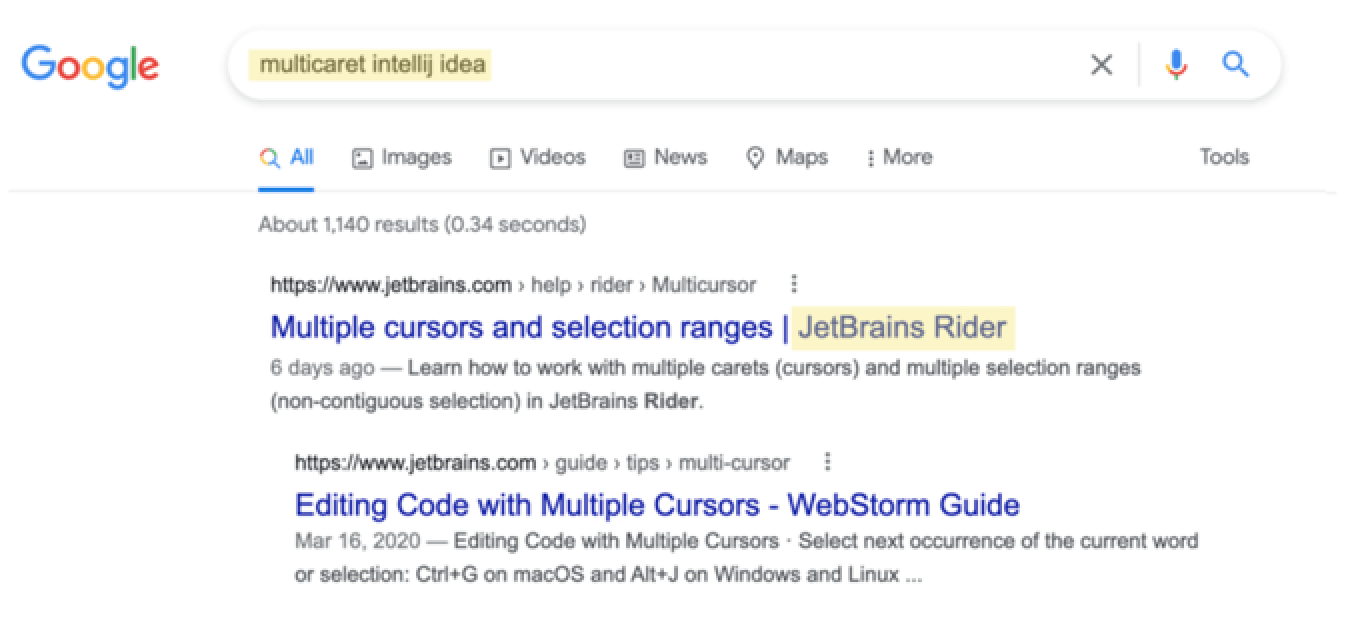
The top ranked result is the relevant article that talks about multiple cursors, only in JetBrains Rider – a different JetBrains product – and not IntelliJ IDEA.
The content of this article is single-sourced and, for some reason, Google thinks that the page from Rider documentation is more relevant.
🪴 Root cause
Our SEO specialists have helped us identify some of the reasons for this problem (though the list may be incomplete):
- If content is published earlier, it’s indexed earlier. So if JetBrains Rider is released several weeks before IntelliJ IDEA, chances are that Google crawlers will have already indexed this article before IntellIJ IDEA documentation was published.
- The less content on a page, the better it’s indexed. Sometimes documentation authors on our team reuse bits and pieces, but the overall section architecture is different. That’s exactly what happened with JetBrains Rider – the information on multiple carets was placed in an isolated help topic, while in IntelliJ IDEA it was a chapter in a larger article, so headings containing the keywords were lower-level.
- SEO specialists also tell us that more traffic and links to a page from other sources also lead to a better ranking, so JetBrains Rider documentation likely contained more references to this section in other articles.
💡 How to avoid
SEO specialists tell us you can avoid traffic cannibalization only if your content is unique. Now that we’ve learned about this phenomenon, should we stop reusing content altogether? Obviously not. The gains of single-sourcing content are still significant.
So my first piece of advice is to BE AWARE of the problem. Forewarned is forearmed. Just remember that your job is not done after you’ve published your content on the web. Well-written documentation has huge marketing potential, so you always need to do everything within your power to ensure that it works, it’s discoverable and accessible, and take action if needed.
When it comes to action, you can do the following:
- If you are reusing content snippets and not entire articles, you can embed metadata into your sources containing more keywords to help search engines distinguish between different target outputs.
- Schedule updates to make sure different documentation instances containing new content that’s reused are not published with an interval of multiple weeks between them.
- Agree on an optimal article length so that the same content doesn’t appear on different nesting levels in different documentation deliverables.
- Consider using other means to distinguish between different types of content. For example, use tabs.
Let me show you an example:
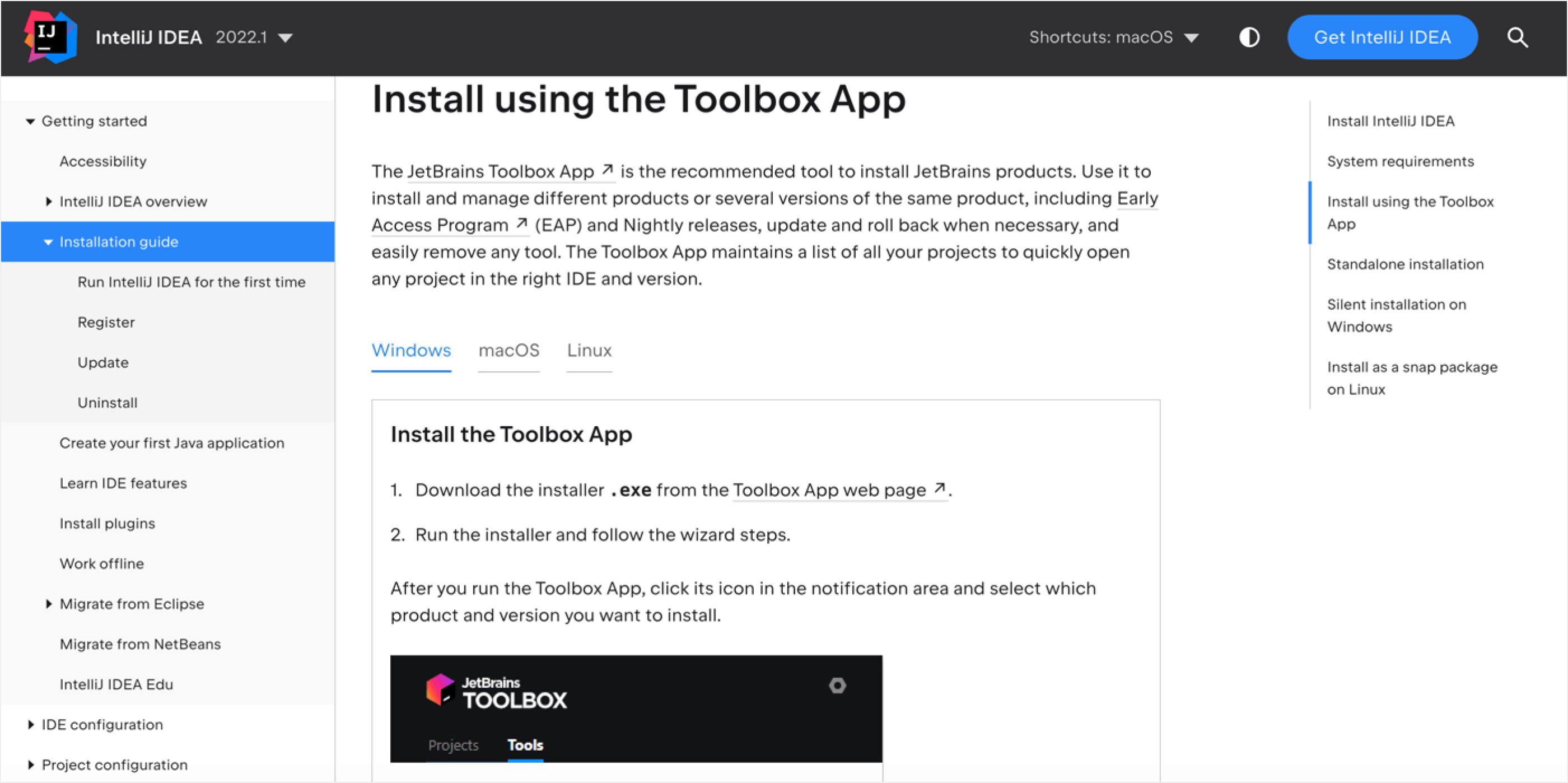
Here, you could create three separate articles telling users how to install IntelliJ IDEA on different operating systems, and each of them would contain some references to reused content. However, this would literally be pulling the audience in different directions with almost identical content, and search engines would likely rank the most visited page higher, depending on which operating system is more popular among IntelliJ IDEA users.
Instead, you could break these types of content into tabs to make sure readers land on the same page and will be able to quickly navigate to the instructions they need.
Takeaways
Let’s summarize the conclusions we’ve made at JetBrains after about ten years of falling into all the traps of reusing content.
- Whenever you make a decision about reusing some content, always weigh the benefits against the drawbacks. Make sure you are making your life (or your colleagues’ lives) easier and that it’s worth the trouble.
- Be careful about creating dependencies between reusable chunks of content that imply complex logic. Aim to create stand-alone reusable chunks whose logic won’t be broken by a slight change to a parent snippet or a modification to a pile of filters overriding each other. Strike a balance between reusing content and keeping sources readable and maintainable.
- Remember that just because you can doesn’t mean you should. Don’t misinterpret the “DRY” principle. Sometimes it’s advisable to sacrifice perfect reuse for a simpler solution.
- Ask yourself which problem you are trying to solve with content reuse. Maybe you’ll find out there are other, simpler solutions to your problem. Think of our examples, where we suggested automating routine work by creating templates, configuring completion patterns, or splitting similar content across tabs within the same article.
- Remember that your job isn’t done when content is published to the web. Always check whether it’s discoverable after you make any major changes or publish anything new. At the end of the day, it doesn’t matter whether your content is useful if it doesn’t reach your readers.
We hope these tips help you reuse content responsibly!



