

Datalore
Collaborative data science platform for teams
AMD Radeon 和 Nvidia 495 项 GPU 技术参数分析数据集

关于 Dataset
在 Datalore 中我们组建了一个 dataset (数据集) 其中包含 495 台 Nvidia 和 AMD Radeon GPU 的相关技术资料。 让我们来了解一下这些硬件随着时间的推移是如何逐渐进步的。

如何在 Datalore 中打开 Notebook?
Datalore 是由 JetBrains 托管的一款在线 Jupyter Notebook,并提供智能编码辅助。 Datalore 自带智能代码编辑器和强大的计算工具。
在此 Notebook 中点击右上角的 “Edit” 按钮。
数据集概览
该数据集包含 495 个 GPU 型号的详细信息:
- GPU 制造商
- GPU 类型
- 名称
- 发布年份
- Fab = 制造工艺 (nm),这定义了处理程序中晶体管的大小
- 晶体管数量(百万)
- 裸芯片尺寸
- 内存大小,以兆字节(MB)为单位
- GFLOPS = 每秒数十亿次浮点运算(32 位精度)
- TDP(热设计功率)= 计算机芯片或组件产生的最大热量。
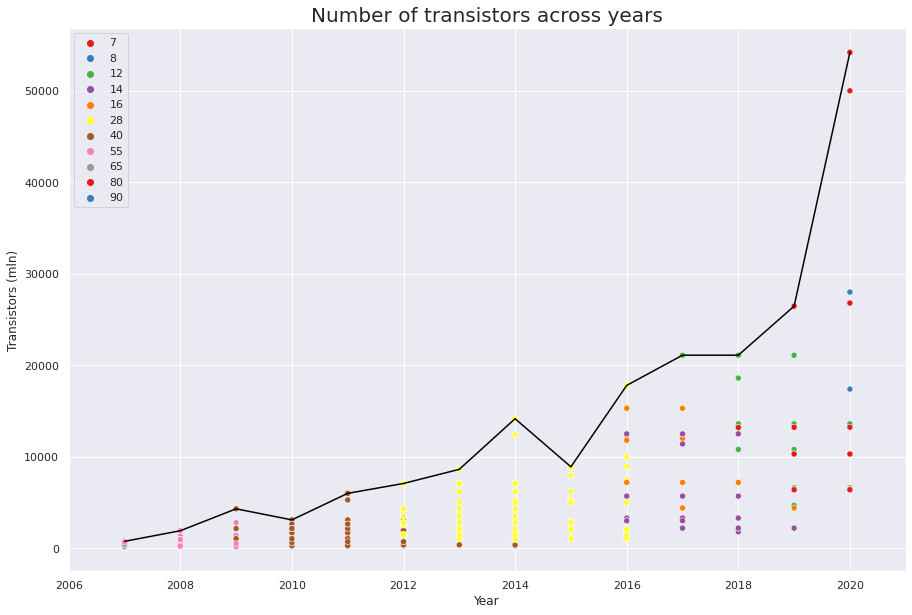
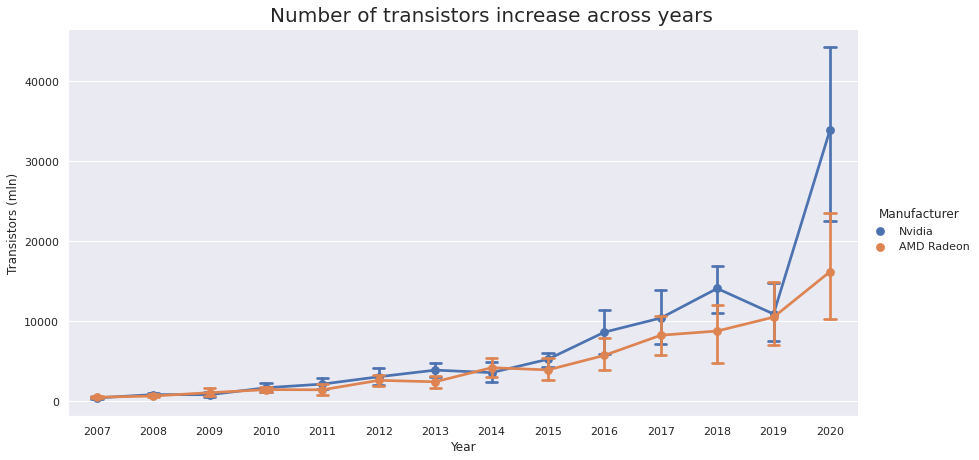
晶体管的摩尔定律
摩尔定律说,集成电路中的晶体管数量每 2 年就会增加一倍。 我们来看看它是否也适用于 GPU!
从下面的图中我们可以看到,摩尔定律在 2019-2020 年仍然有效,但在 2006-2018 年,增长几乎是线性的。
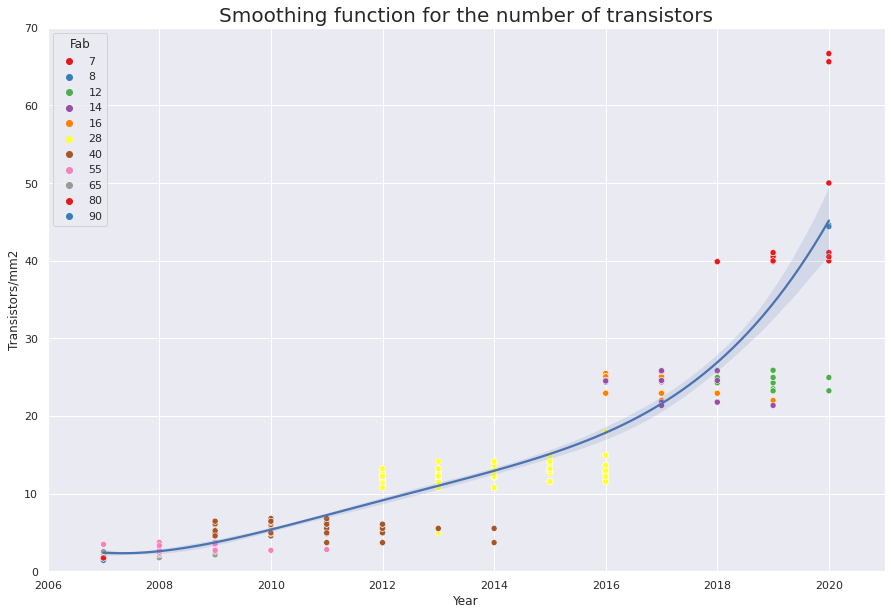
然而,摩尔定律对于晶体管密度几乎是正确的。 您可以根据下图,发现它大约每 3 年就会增加一倍。
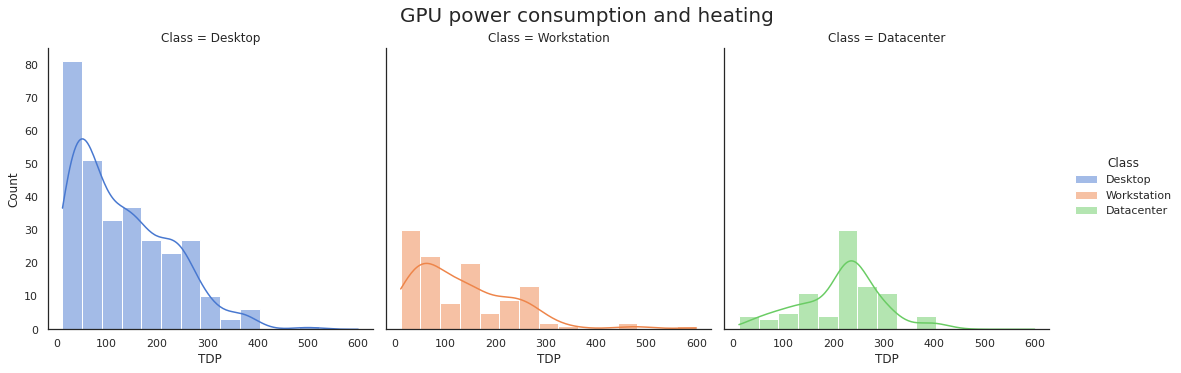
GPU 功率消耗和散热效果
GPU 的功率消耗和散热效果也是一个有趣的话题。
这个数据集将 GPU 分为三组:
- 消费级 GPU,如 Nvidia GeForce 和 AMD Radeon R 系列。
- 工作站 GPU,如 Nvidia Quadro 和 AMD Radeon FirePro。
- 服务器 GPU,如 Nvidia P/V/T 系列和 AMD Radeon Instinct。
让我们来显示 3 组 GPU 的 TDP(热设计功率)的分布情况。 我们将绘制精确的统计集,并添加一个平滑线近似值。
💡 见解:
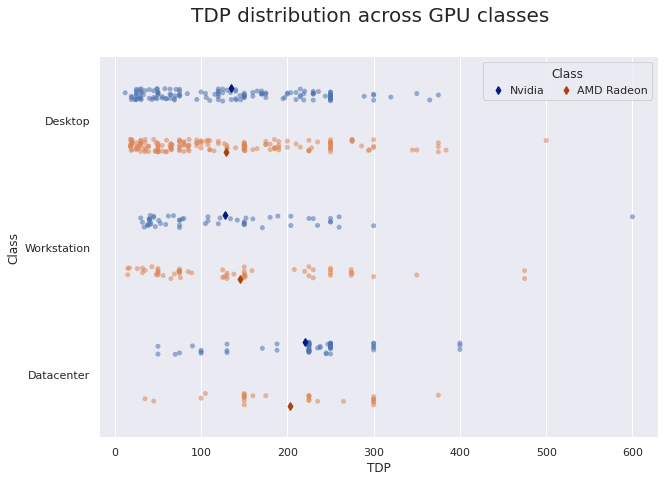
虽然服务器 GPU 比消费级和工作站 GPU 更热、更强大,有趣的是有很多低功耗工作站 GPU。 这些不是用于 3D 图形或并行计算,而是为了管理显示面板和视频墙。
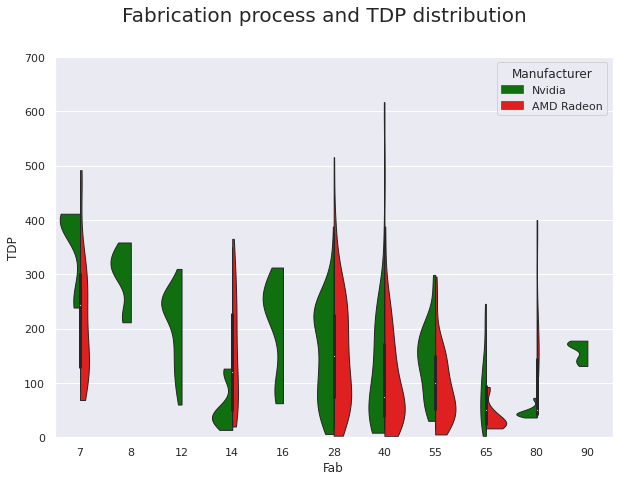
制造工艺和 TDP 分布
在接下来的图中,我们看到 GPU 模型分布如何根据两个制造商的制造工艺和 TDP 而变化。
💡 见解:
- 制造商和芯片 TDP 之间没有明显的相关性,制造工艺和 TDP 之间也没有明显的相关性。
- 虽然晶体管的功耗会随着晶体管的体积变小而降低,但芯片上晶体管数量的增加抵消了这种影响。
各类 GPU 的 TDP 分布
让我们来展示一下 TDP 在各个类别和制造商之间的分布情况,忽略制造工艺。
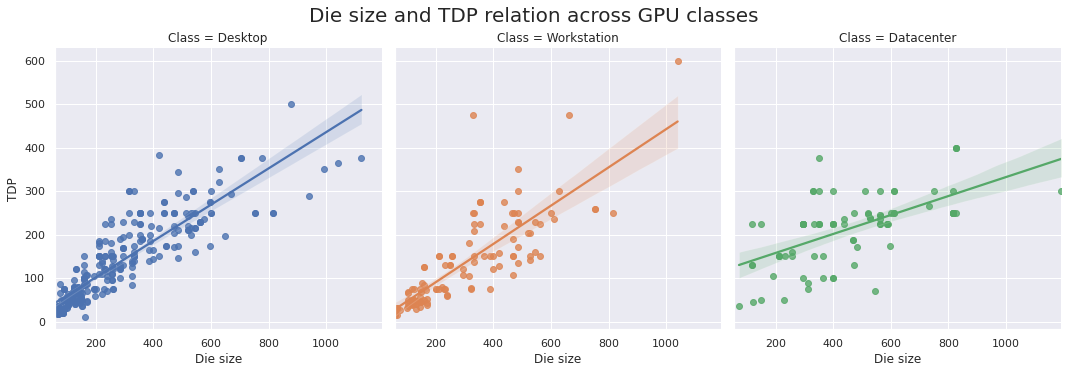
各类 GPU 的裸芯片尺寸和 TDP 关系
从下面的图中,我们可以看到 TDP 和硅的实物量(包括裸芯片尺寸)之间的线性关系。
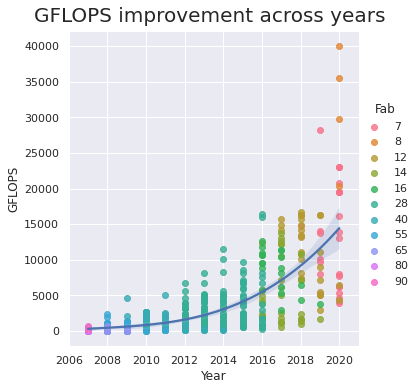
GFLOPS 进度
GFLOPS 是指每秒数十亿次浮点的数量, 它决定了 GPU 的计算能力。 让我们来看看这些年这个数字是如何增加的。
我们还将计算一个额外的特征 – 每百万个晶体管的 GFLOPS 数量。
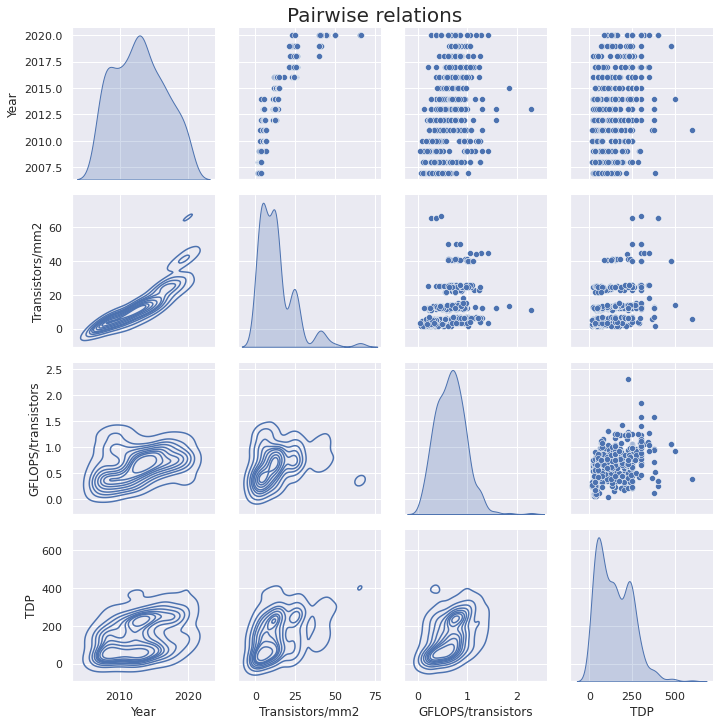
成对关系
在下图中,我们可以看到年份、晶体管/mm2、GFLOPS/晶体管和 TDP 参数之间的关系。
💡 见解:
- 250 W TDP 左右的峰值是由 AMD 和 Nvidia 的顶级芯片中普遍存在这个数值造成的。 不过,Nvidia RTX 30 GPU 比前代产品更高温:RTX 3080 和 3090 的 TDP 分别为 320 W和 350 W,AMD RX 6800 XT 为3 20 W。
- 虽然 Nvidia 的芯片一般都比 AMD 大,他们的芯片尺寸差距在 2020 年比以往更大,因为新的 54 亿晶体管 A100 芯片现已发布。 不过有趣的是,AMD 在小尺寸芯片上的 GFLOPS 和 TDP 与大尺寸芯片差不多。
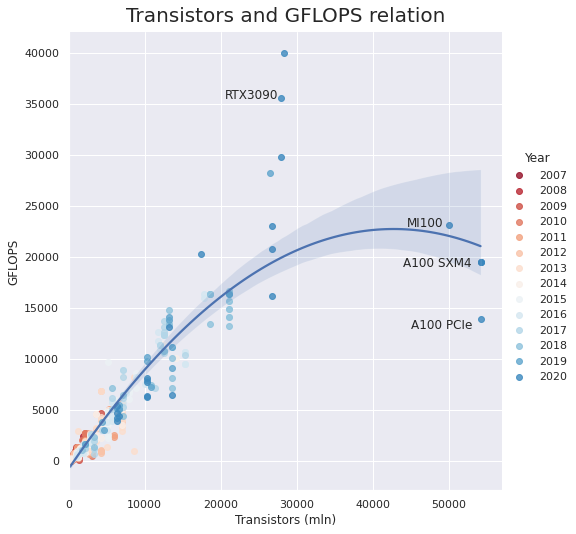
晶体管和 GFLOPS 的关系
从下面的图中我们可以看到,Nvidia A100 和 Radeon MI100 尽管拥有约 2 倍的晶体管,但其 FP32 GFLOPS 与 2020 年和 2019 年的其他顶级 GPU 大致相同。 但它们仍然明显慢于桌面级 RTX 3090,后者的 GFLOPS 数量几乎是其两倍。
然而,A100 和 MI100 具有明显更快的 FP32 稀疏和 FP16 模式。 例如,RTX3090 的 FP16 产量只有 35.6 TFLOPS,而 MI100 的可以高达 184.6,A100 在处理结构稀疏矩阵时可以达到 624。 这似乎是由新的多实例 GPU 技术造成的,该技术允许 A100 被分隔成 7 个 GPU 实例。
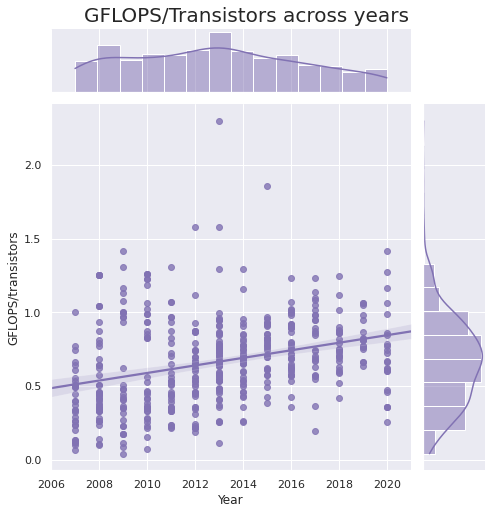
最后一个有趣的观察是,每个晶体管数量的 GFLOPS 几乎没有增长。
💡 最后一个有趣的观察是,
每个晶体管数量的 GFLOPS 几乎没有增长。
查看 Datalore 中的总结图!
欢迎点击这里获取我们的 GPU 数据集。请注明 Datalore 团队是数据集的来源。 我们很乐意看到并与我们的社区分享你的作品。




