

Datalore
Collaborative data science platform for teams
如何从 Jupyter Notebook 运行 SQL – 两种简单方式

为什么需要在 Jupyter Notebook 内组合 SQL 和 Python
SQL 非常适用于检索数据和计算基本统计数据,而 Python 在您需要深入、灵活的探索性数据分析或数据科学时大有用武之地。 如果您在一个工具中可同时使用两种编程语言,会怎样?

在本文中,您将了解通过 Jupyter Notebook 接口使用 Python 和 SQL 的两种简单方式,并使用几行代码创建 SQL 查询。 这两种方式几乎不受数据库限制,因此您可以将它们用于所需的任何 SQL 数据库:MySQL、Postgres、Snowflake、MariaDB、Azure 等。
方式 1:使用 Pandas 读取 SQL 查询
第 1 步:安装 Python 软件包以连接到您的数据库
我们建议安装以下软件包:
- PostgreSQL 数据库:
! pip install psycopg2-binary. 请确保安装 psycopg2-binary, 因为它还会处理所需依赖项。
- Snowflake 数据库:
! pip install snowflake-connector-python. - MySQL 数据库:
! pip install mysql-connector-python.
要在 Datalore 中安装软件包,您还可以使用环境管理器,它可以在您稍后重新打开 Notebook 时使软件包保持不变。
Datalore 是为数据科学和机器学习量身定制的云端协作式数据科学 Notebook。 您可以从免费的 Community 方案开始,然后随时升级!
第 2 步:在 Jupyter 中创建数据库连接
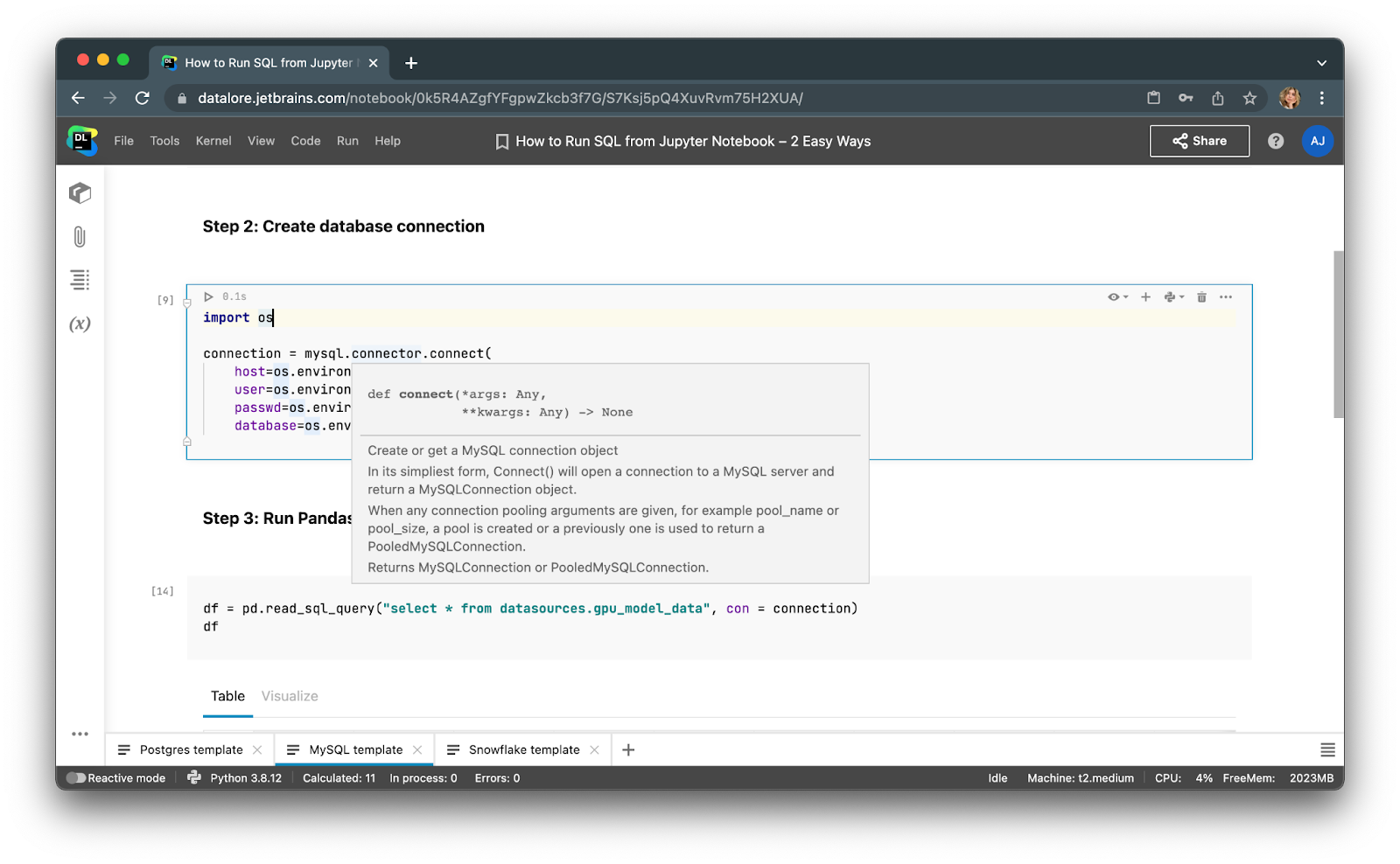
运行下方示例代码以连接到 MySQL 数据库。 您可以在本教程中找到连接到 PostgreSQL 和 Snowflake 数据库的示例代码。
import os
import psycopg2 as ps
import pandas as pd
conn = ps.connect(
host=os.environ["db_host"],
port=os.environ["db_port"],
dbname=os.environ["db_name"],
user=os.environ["db_user"],
password=os.environ["db_password"])
提示:为存储凭据,我们会在 Datalore 中使用称为密钥的环境变量。 这有助于防止在您与他人共享 Jupyter Notebook 或屏幕时意外泄露您的凭据。
如果您无法从云工具连接到公司的数据库,请考虑在私有云或本地部署环境中安装 Datalore。
第 3 步:使用 Pandas 运行 SQL 查询
创建数据库连接后,您可以立即执行 SQL select 查询!
请参见下方示例代码:
df = pd.read_sql_query("select * from <table>", con=conn)
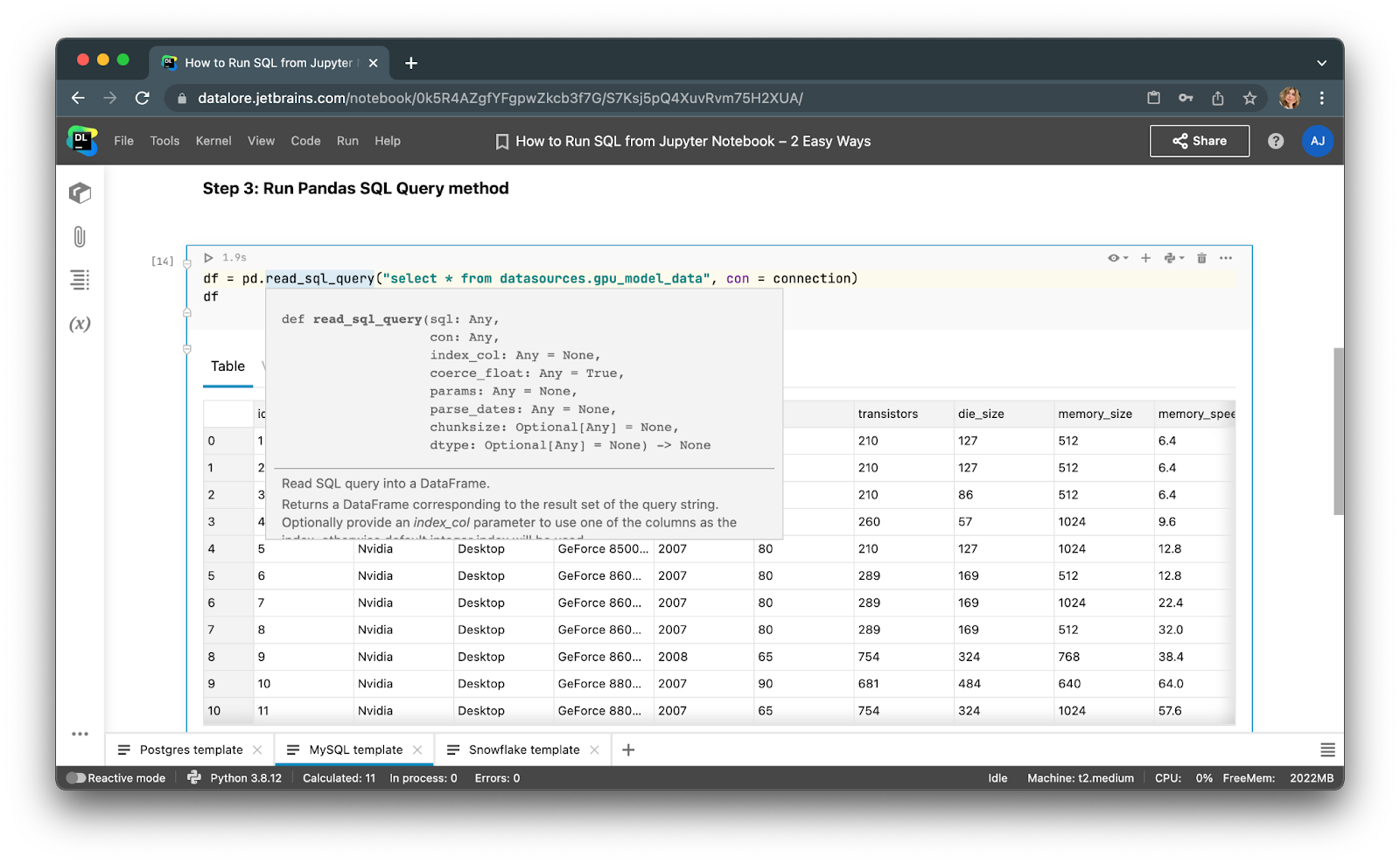
完成! 只需运行代码单元,您就可以将结果保存到 pandas DataFrame 中,以便继续使用 Python 进行处理。
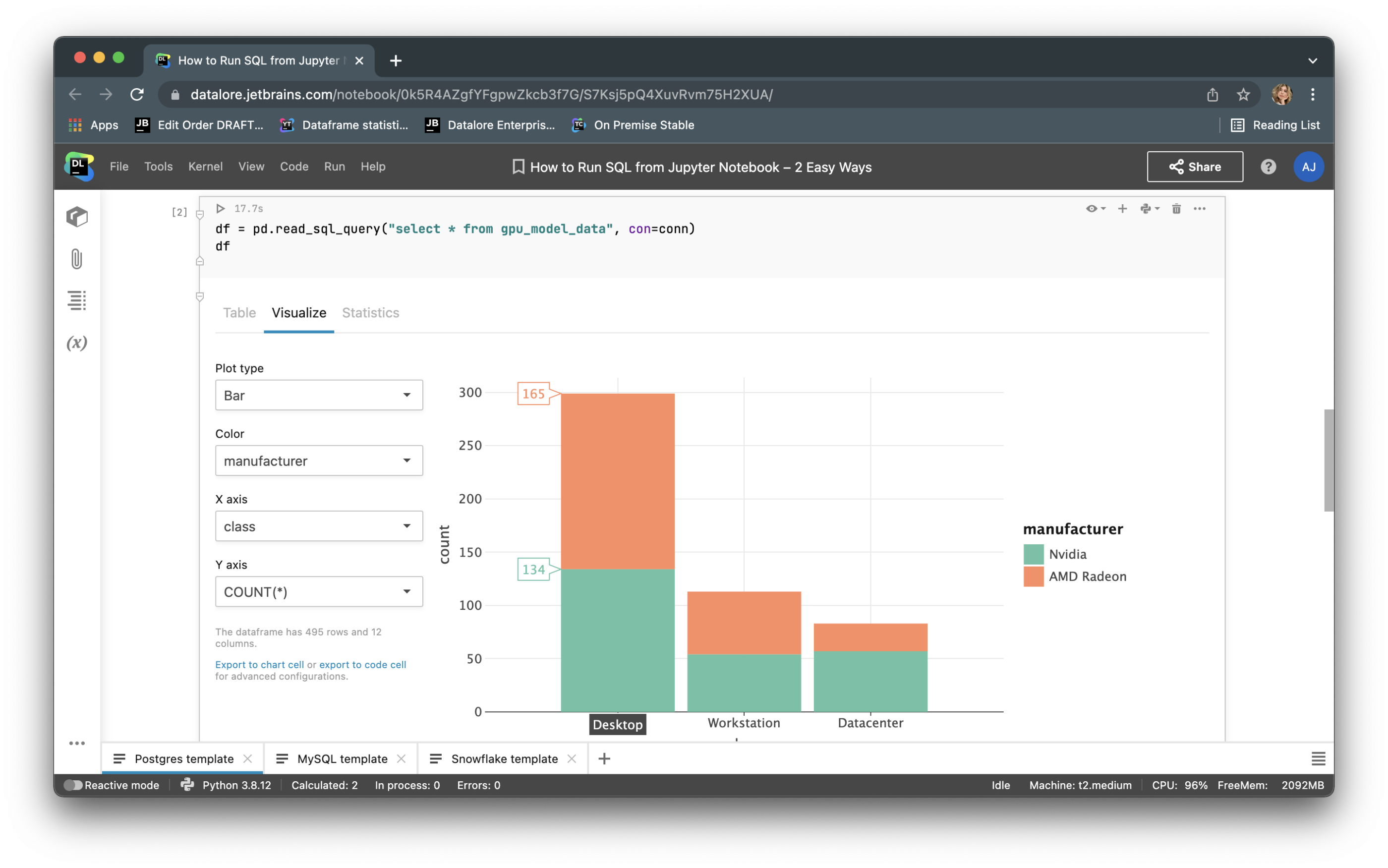
方式 2:在 Datalore Notebook 中使用 SQL 单元
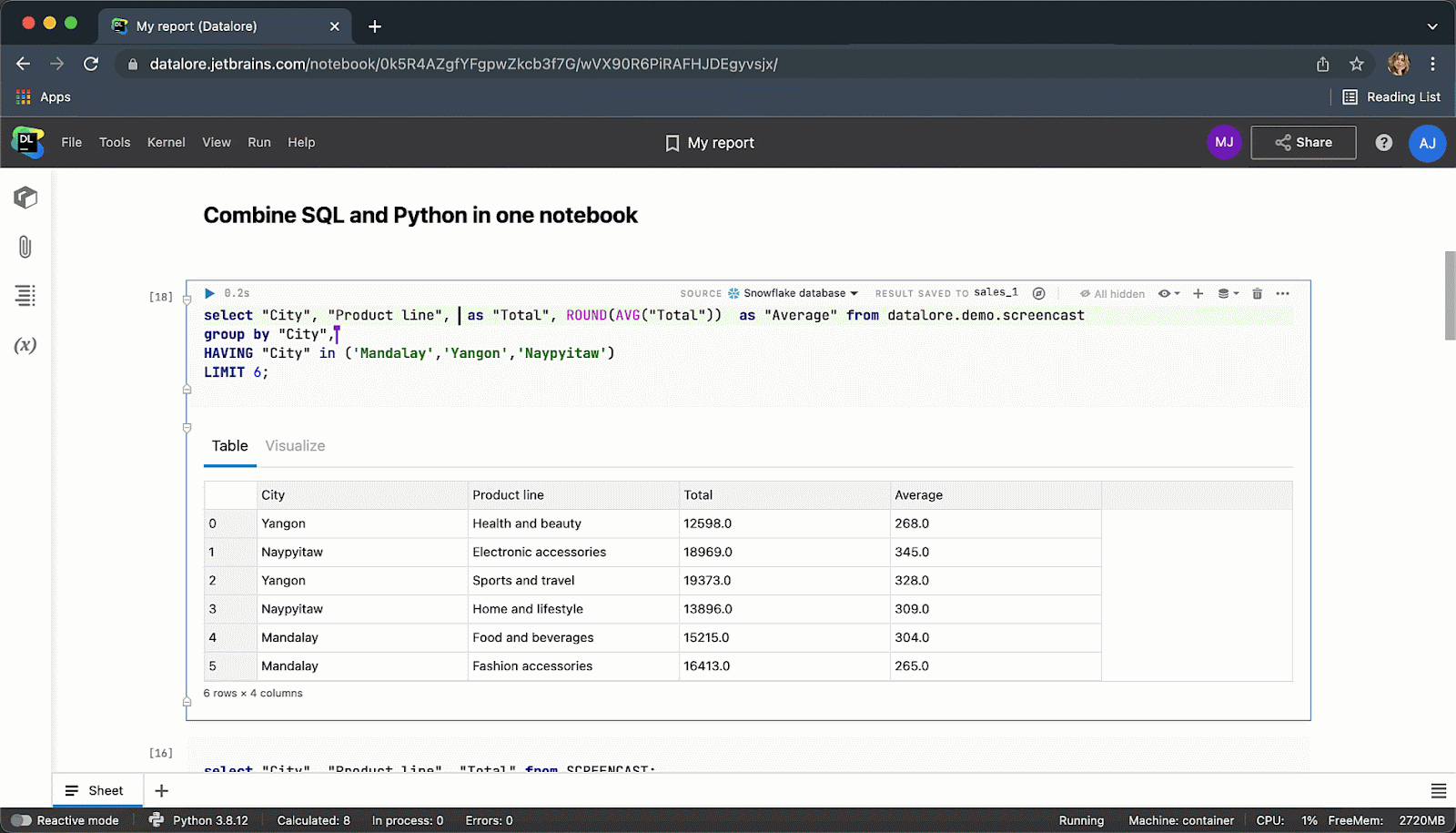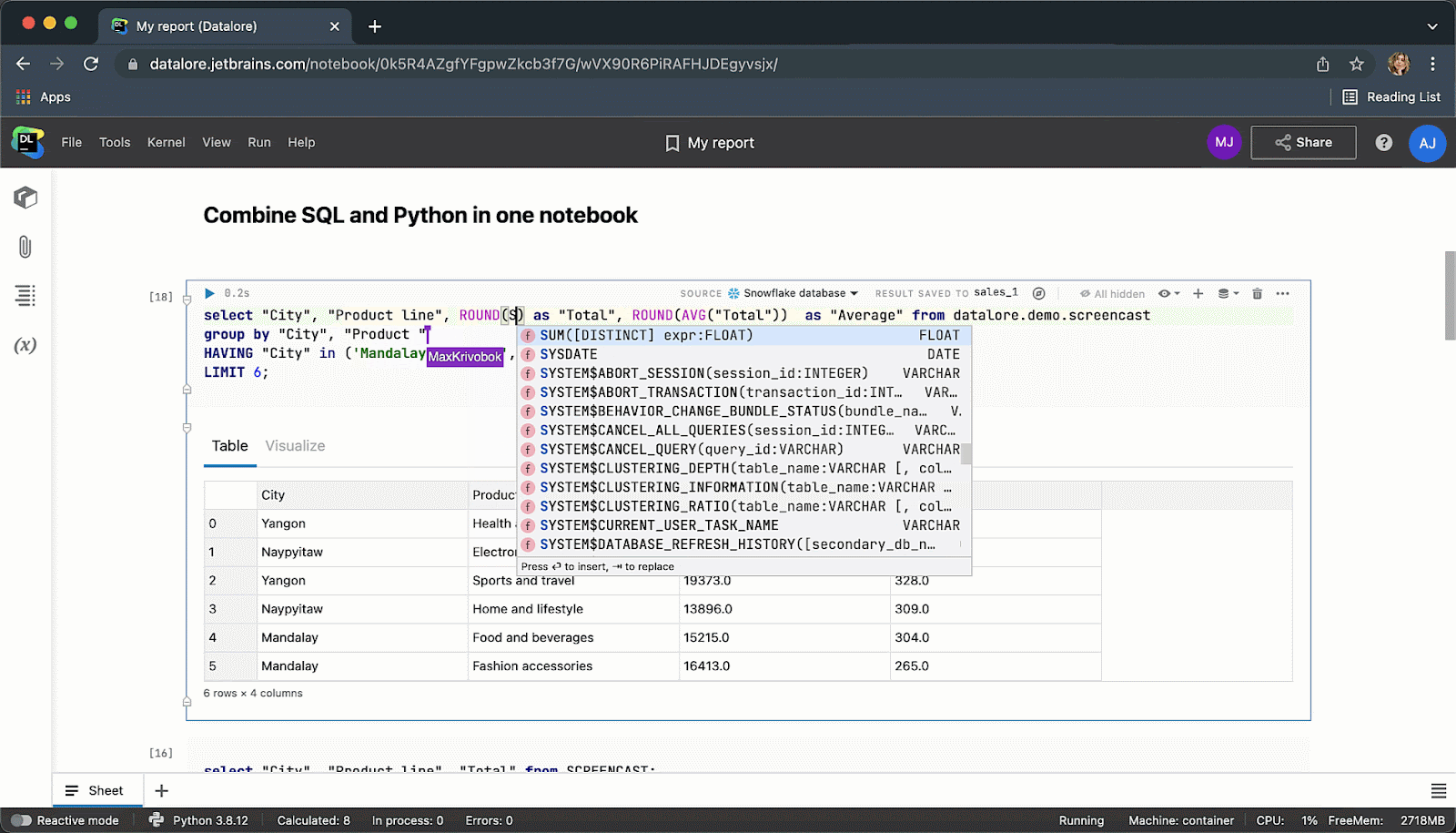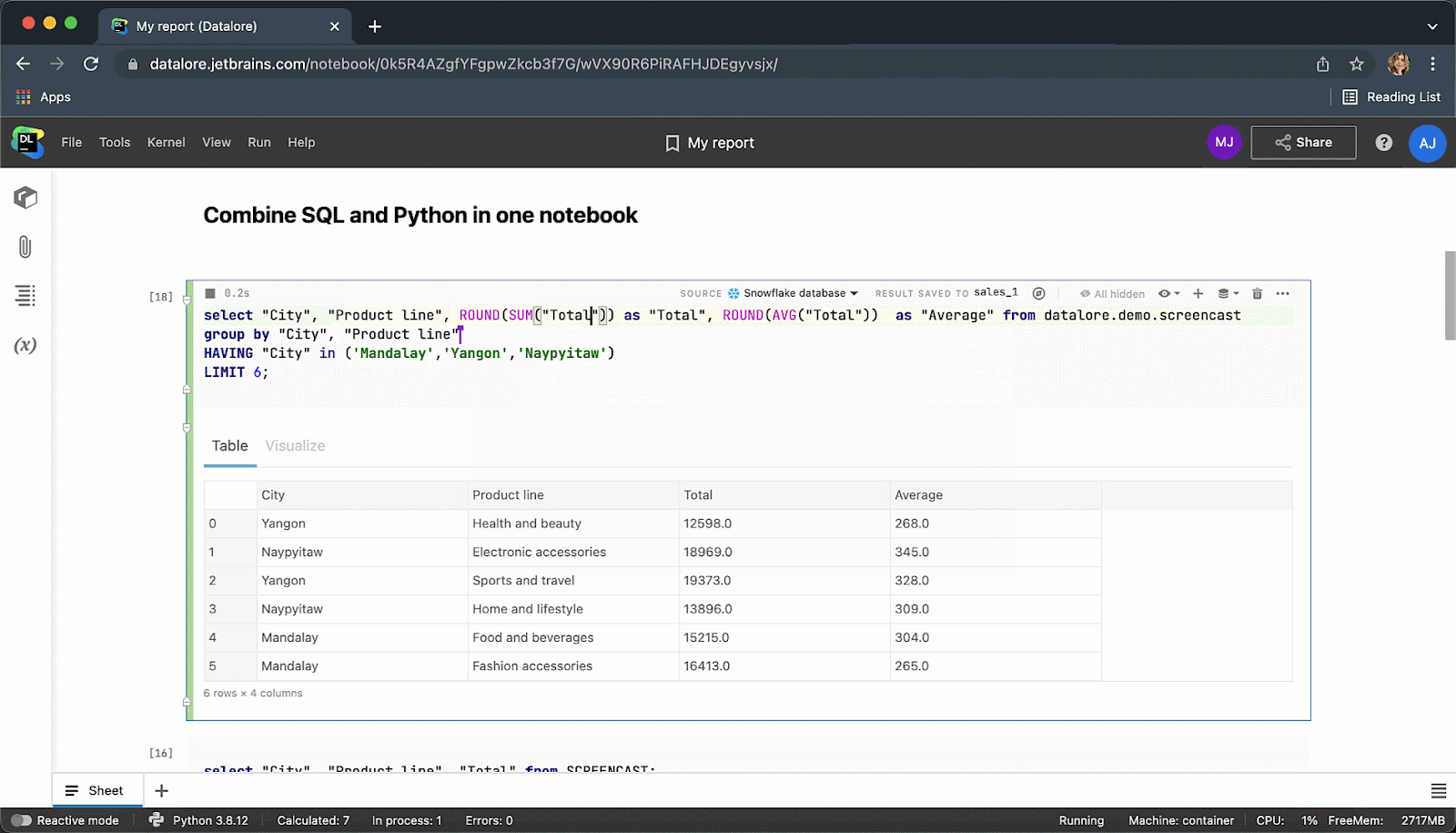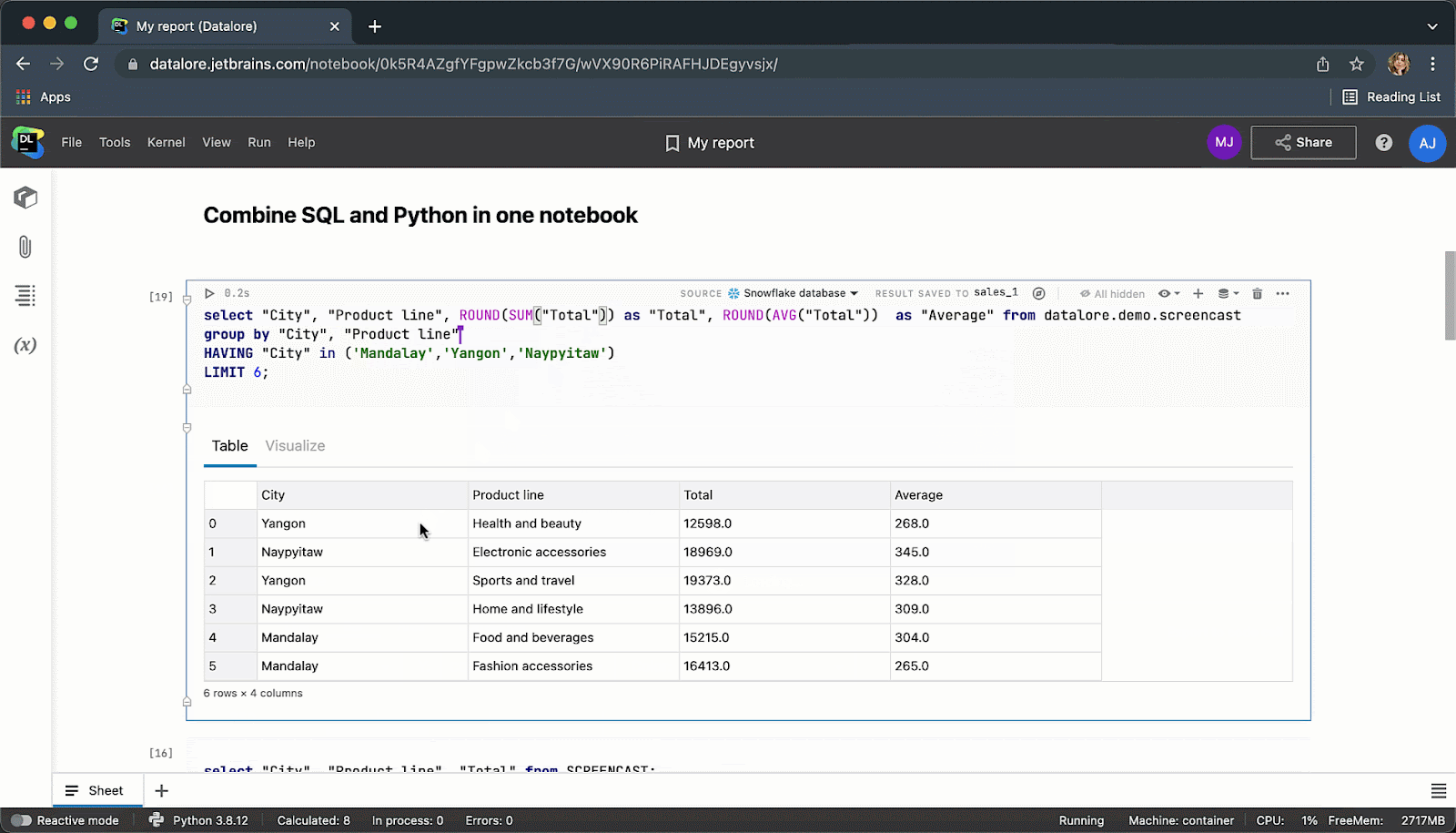
最近,我们在 Datalore 中的 Python Notebook 内集成了原生 SQL 单元和数据库连接。
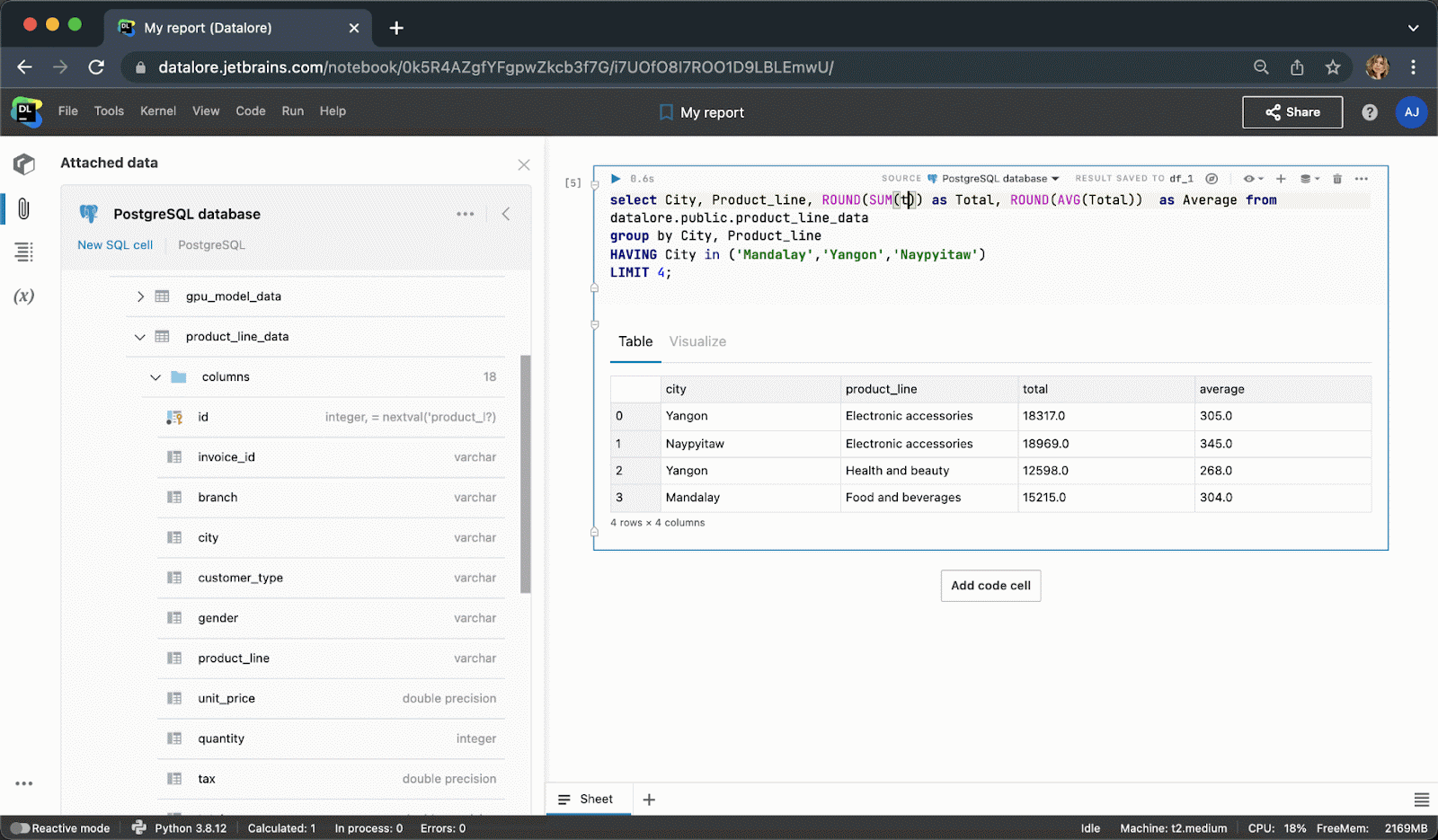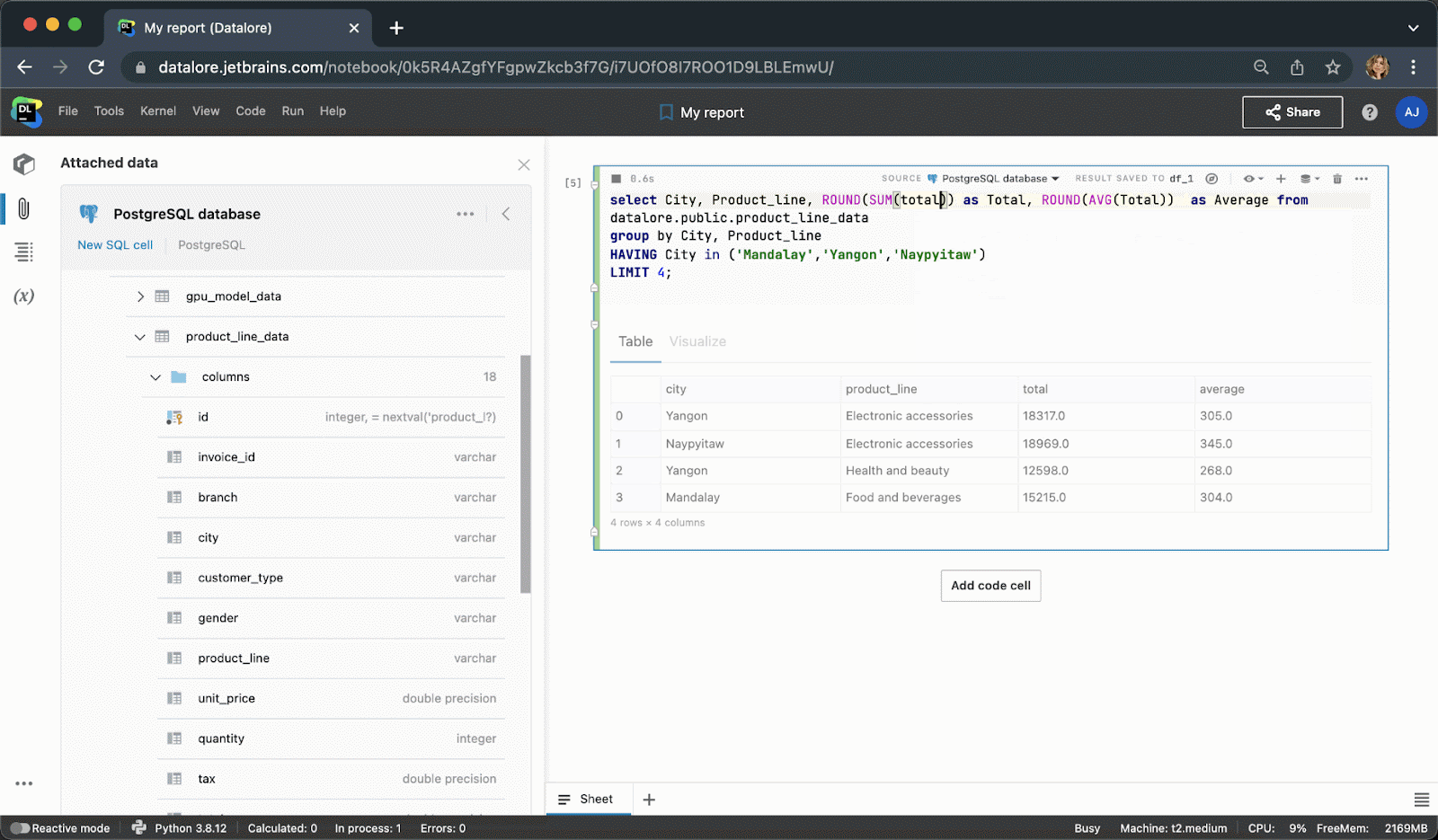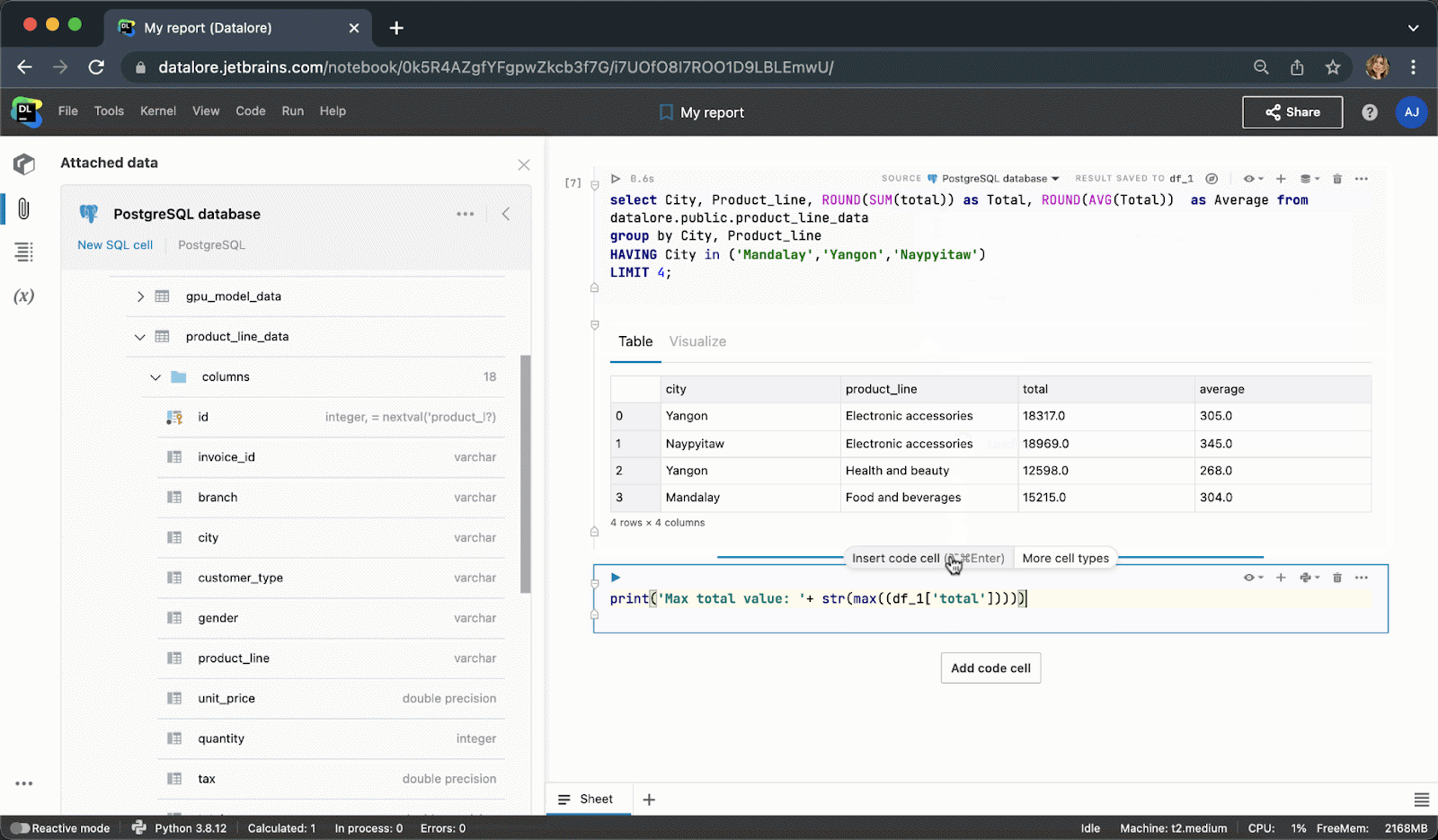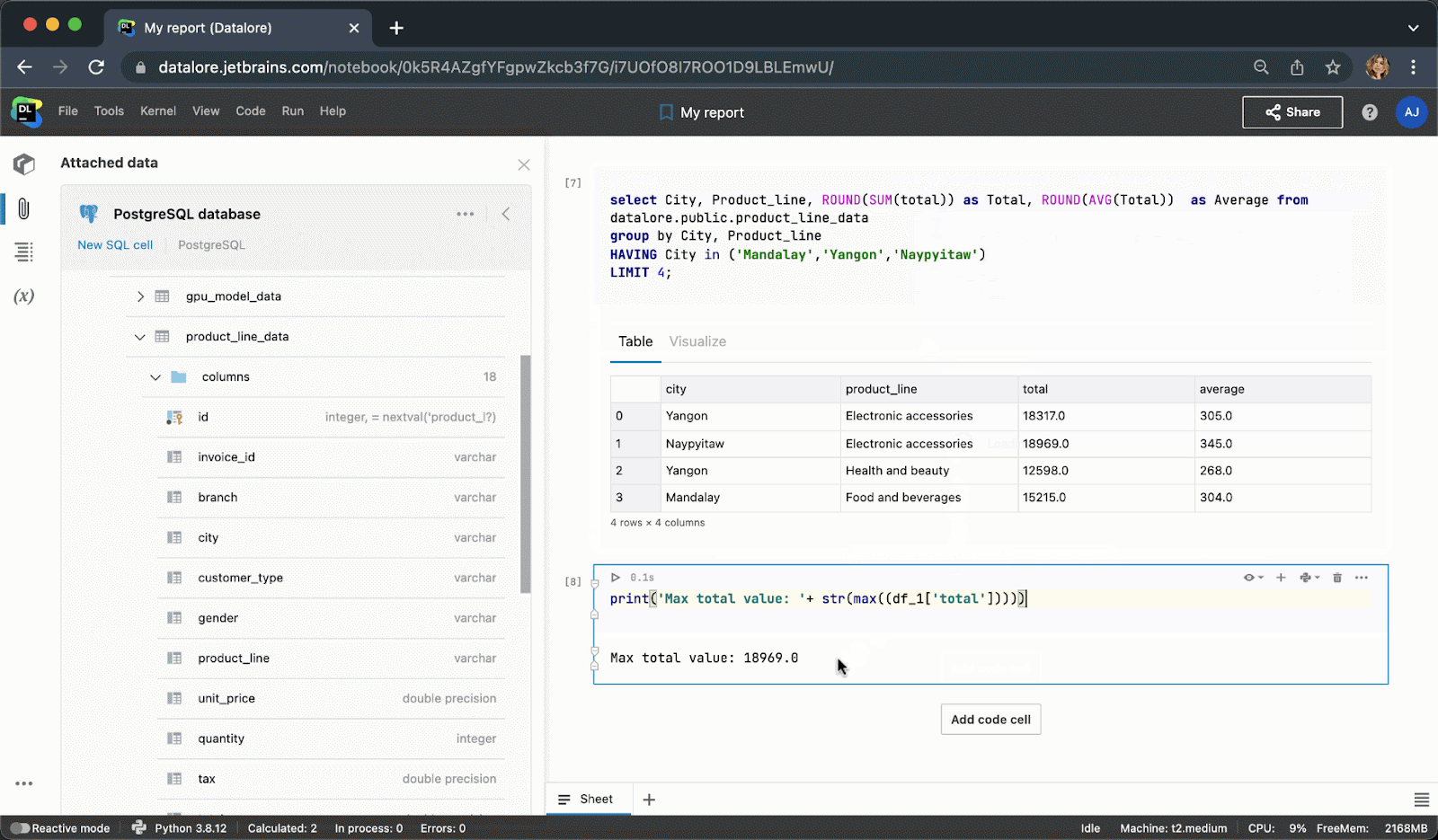
现在,您不需要编写样板 Python 代码来连接到数据库,而是可以从 UI 创建一个连接,然后在多个 Notebook 中重用该连接。 创建连接后,您将能够浏览数据库架构,这对于编写 SQL 查询极其有用。
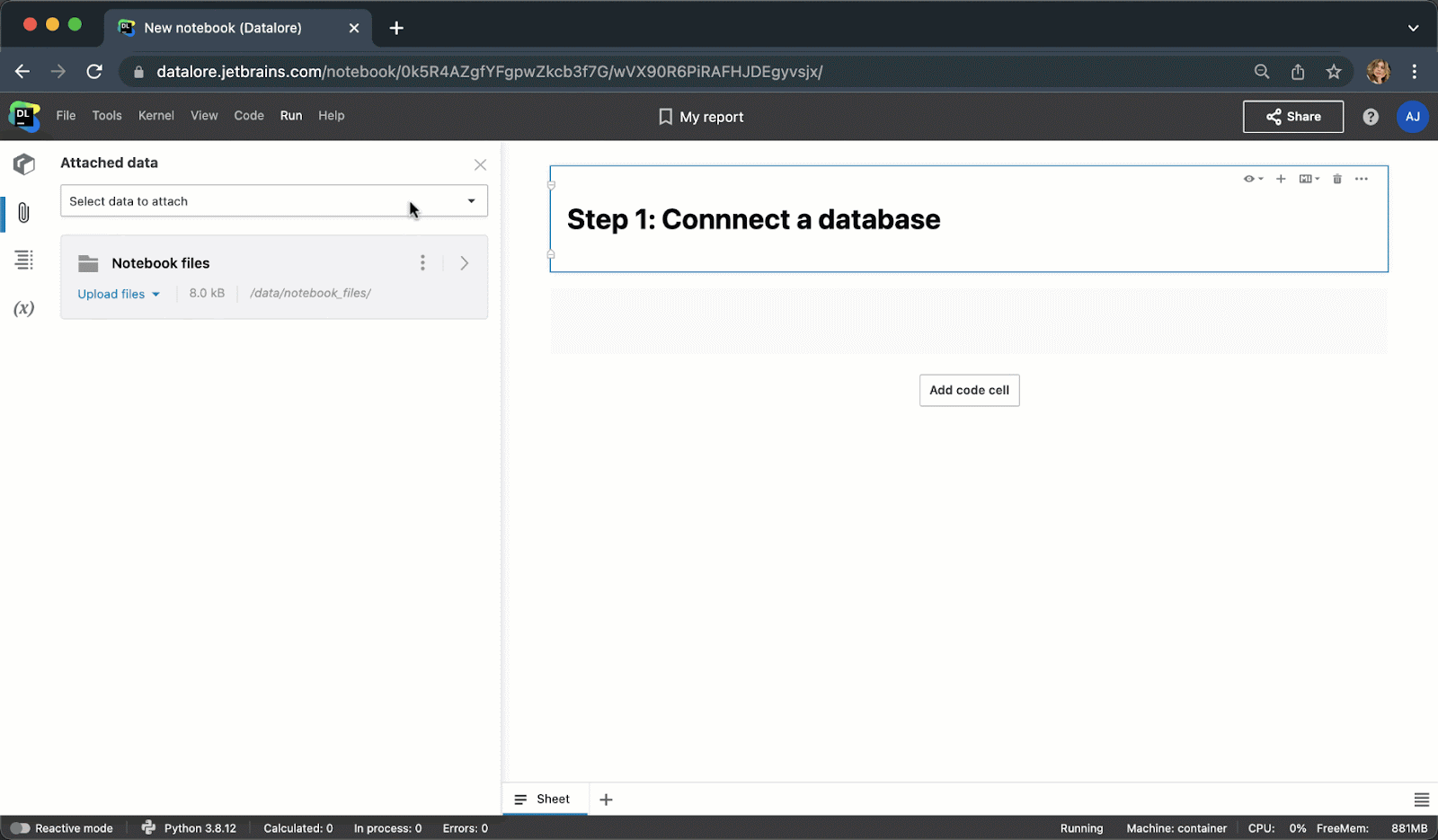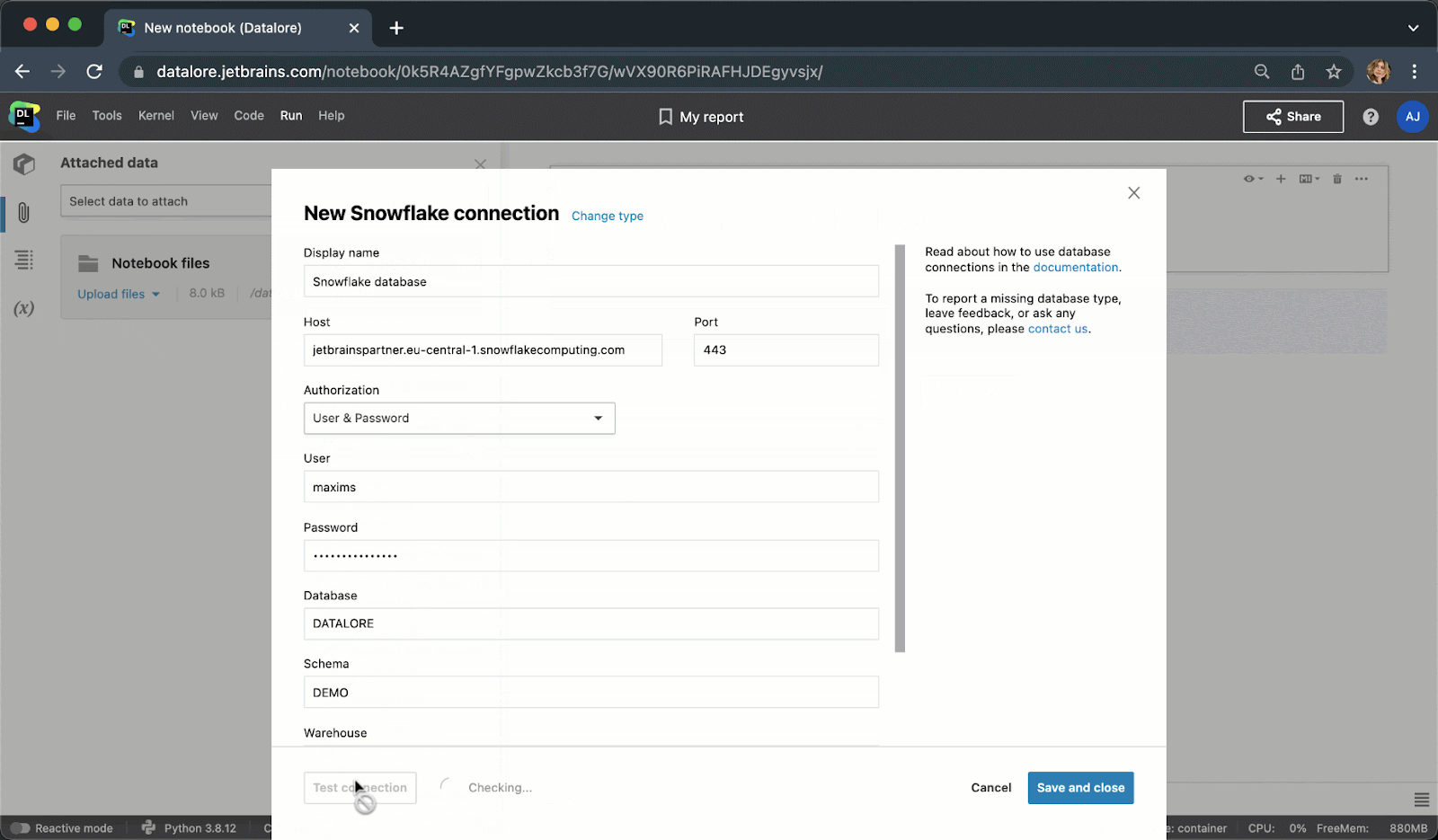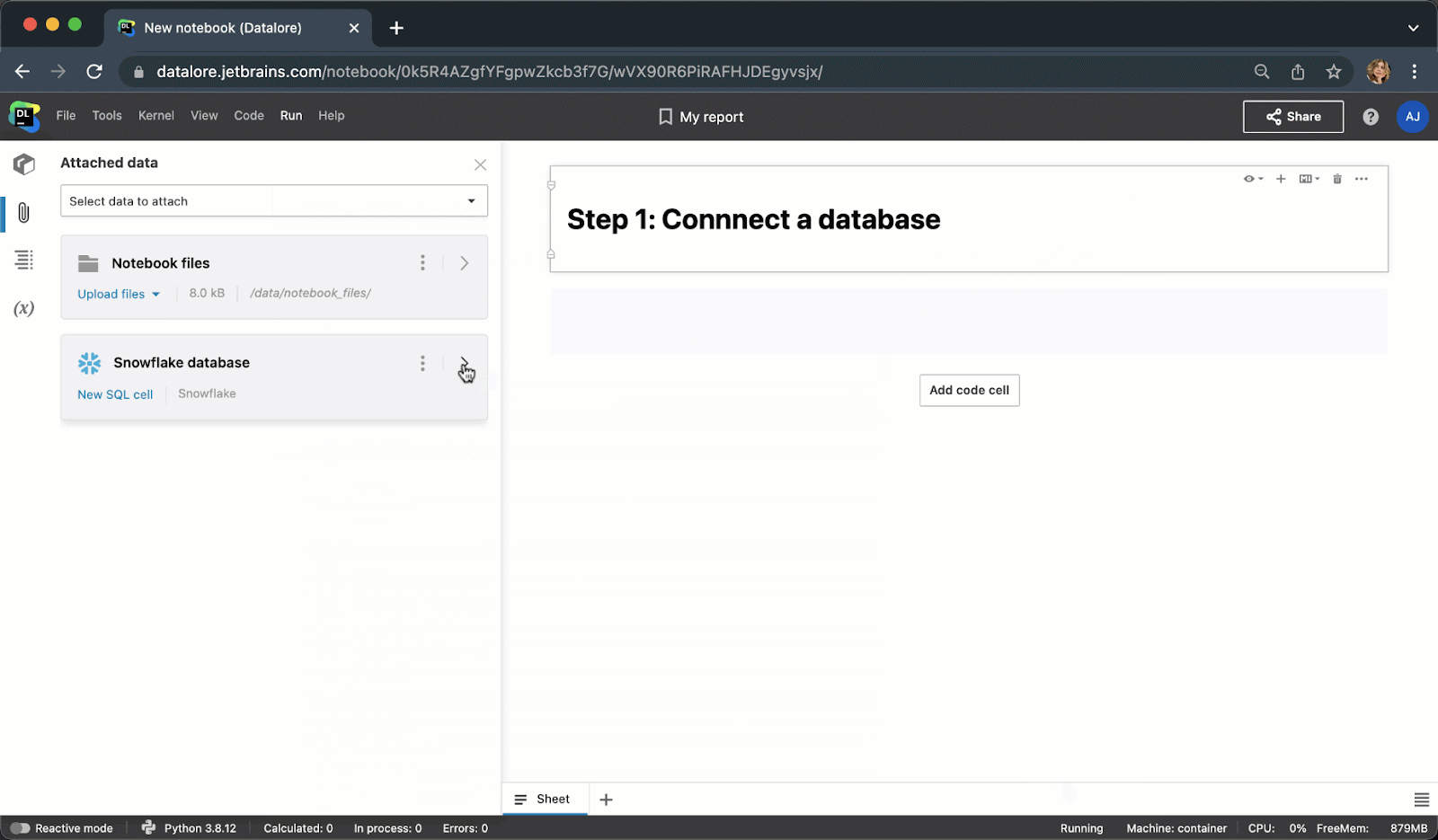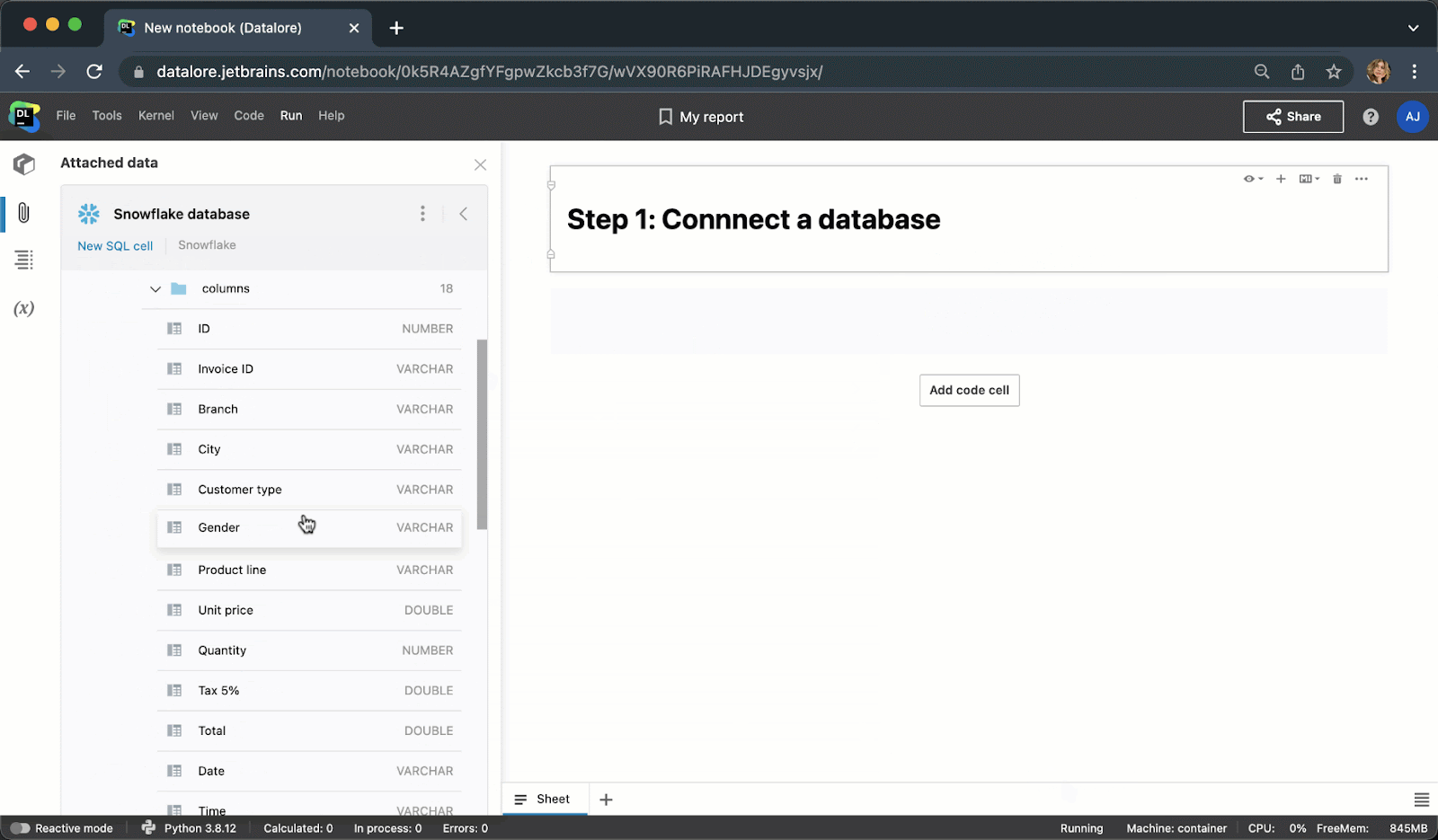
键入 SQL 代码时, 您将获得 SQL 语法和表/列名的智能代码补全。
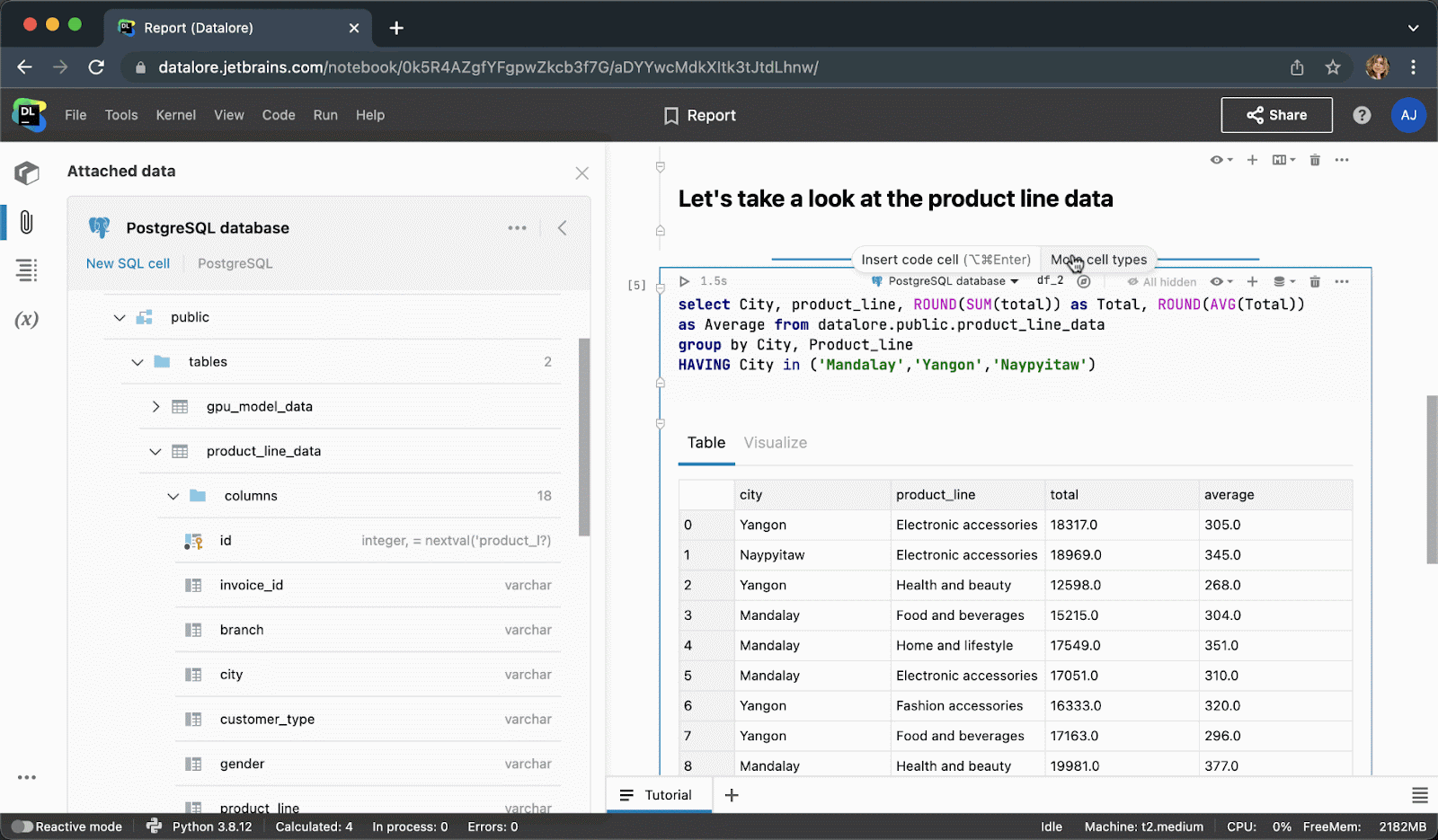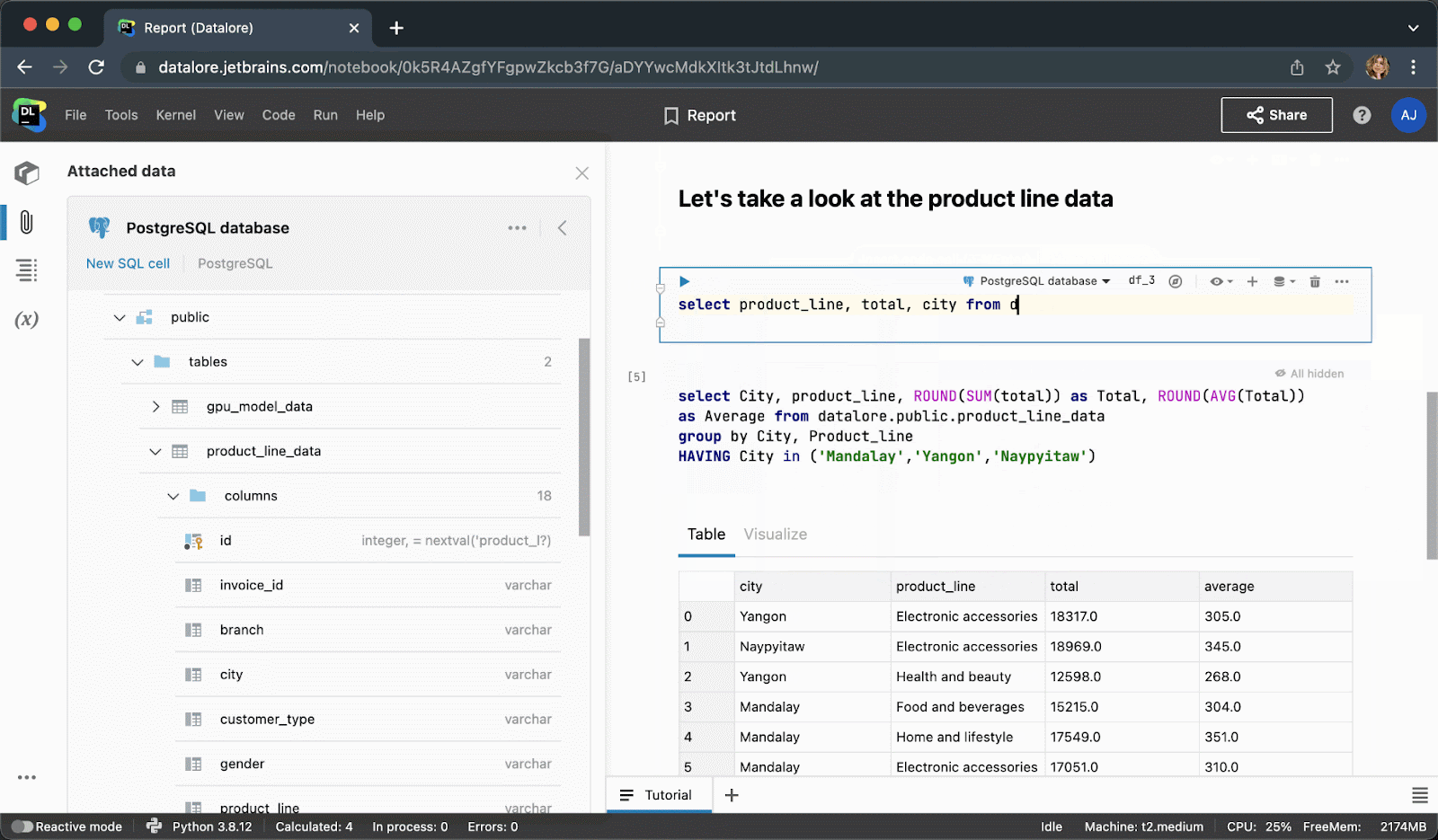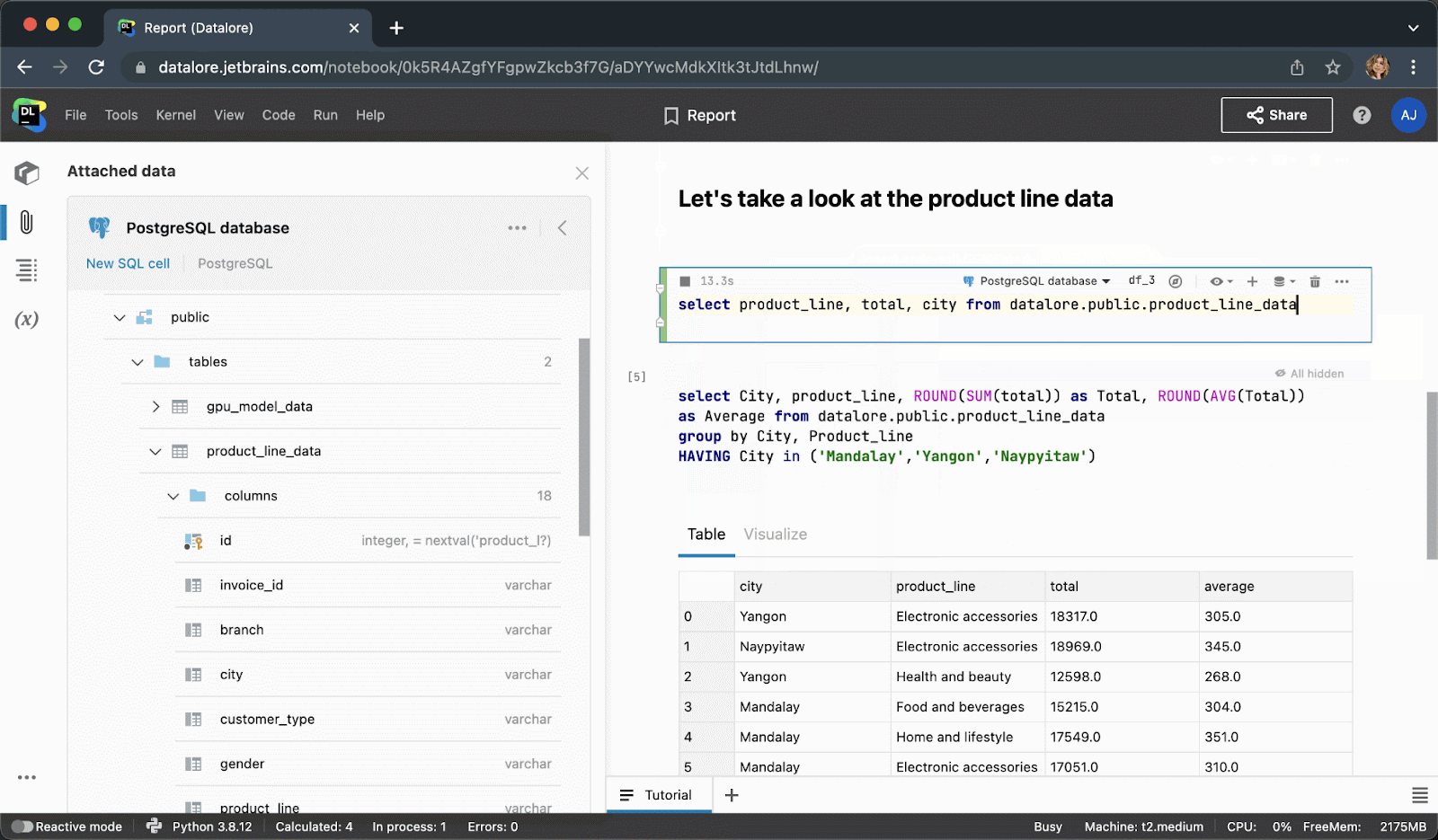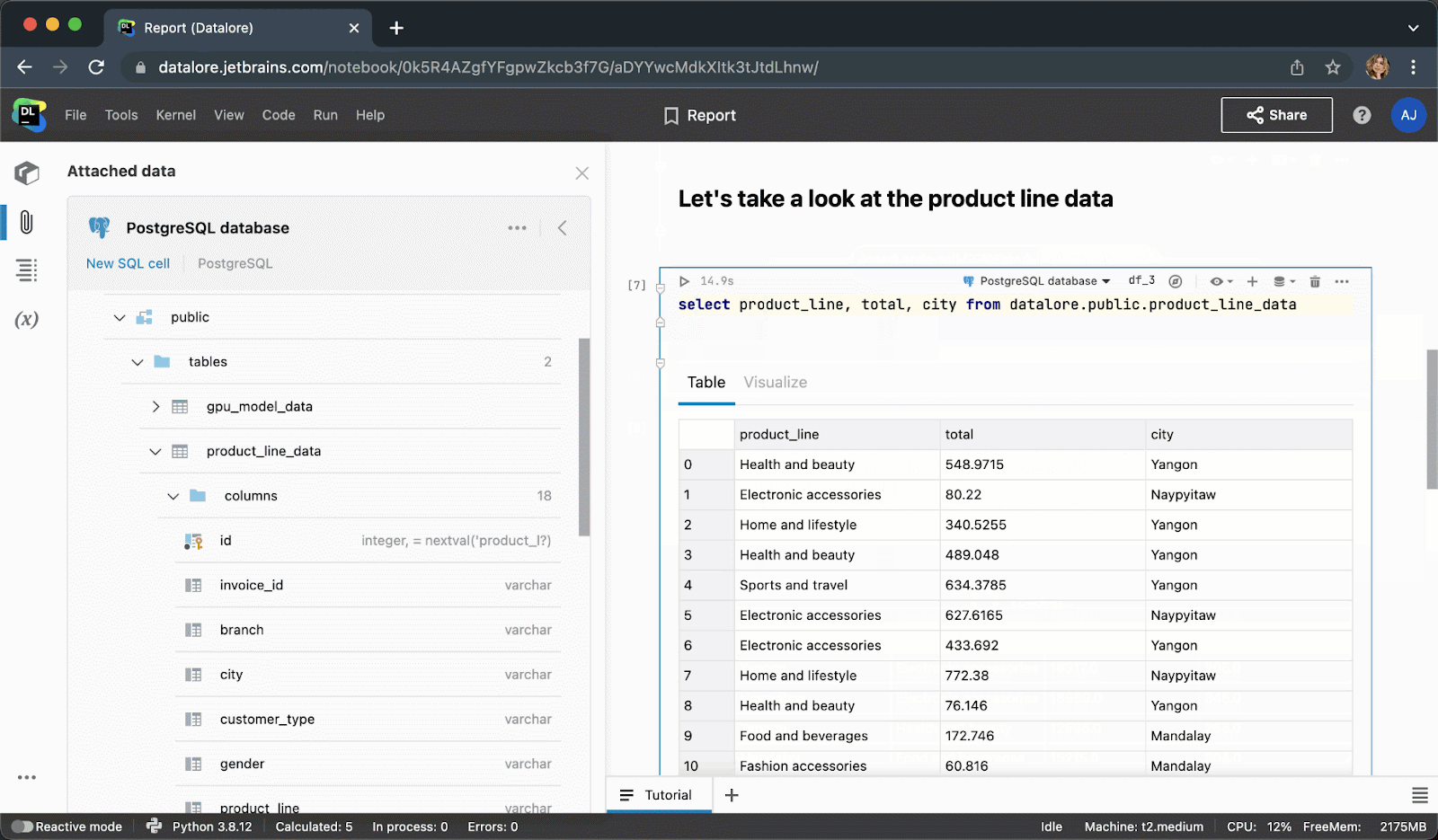
执行代码单元后,结果将自动保存到 pandas DataFrame,您可以继续使用 Python 进行无缝处理。
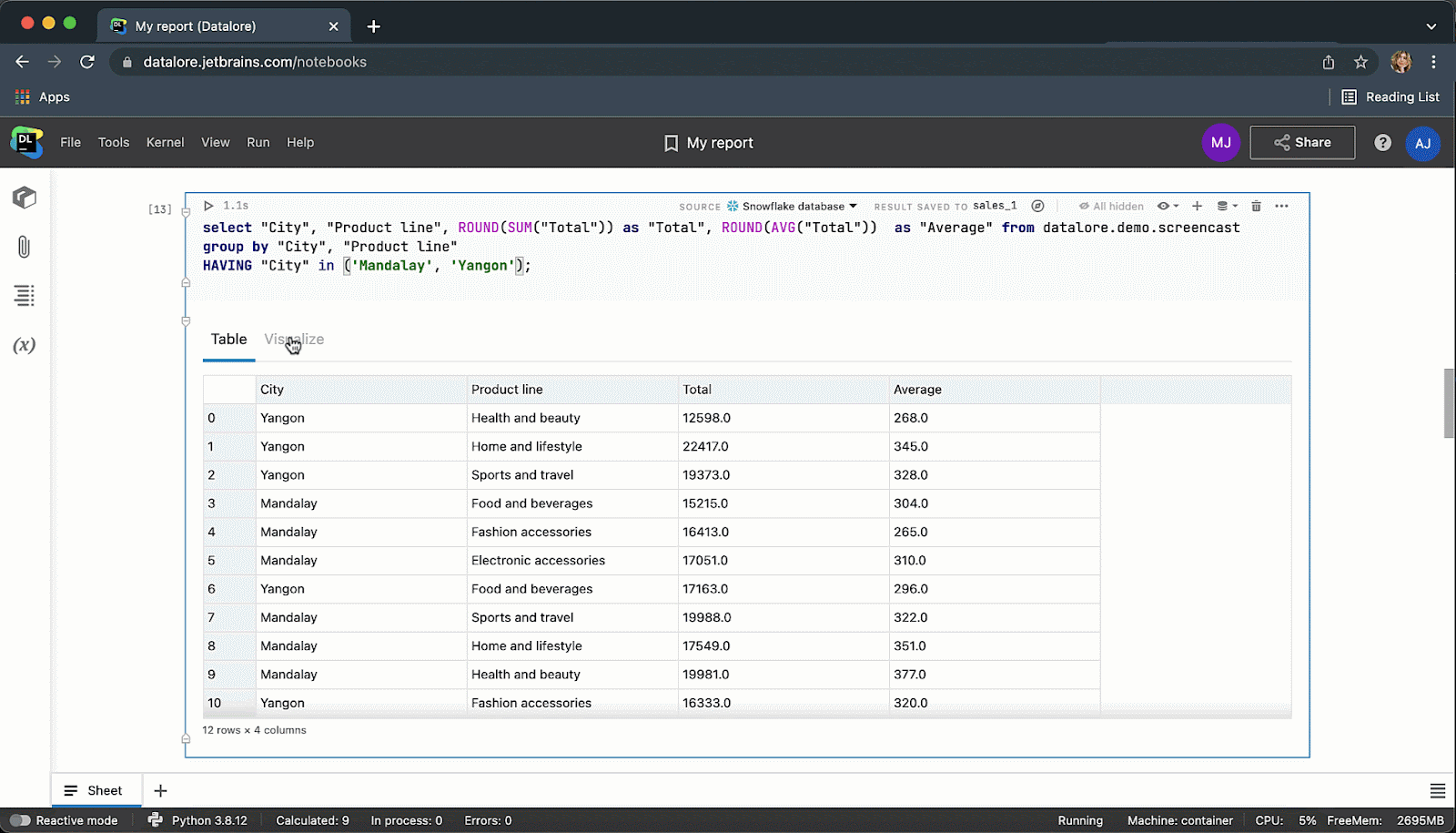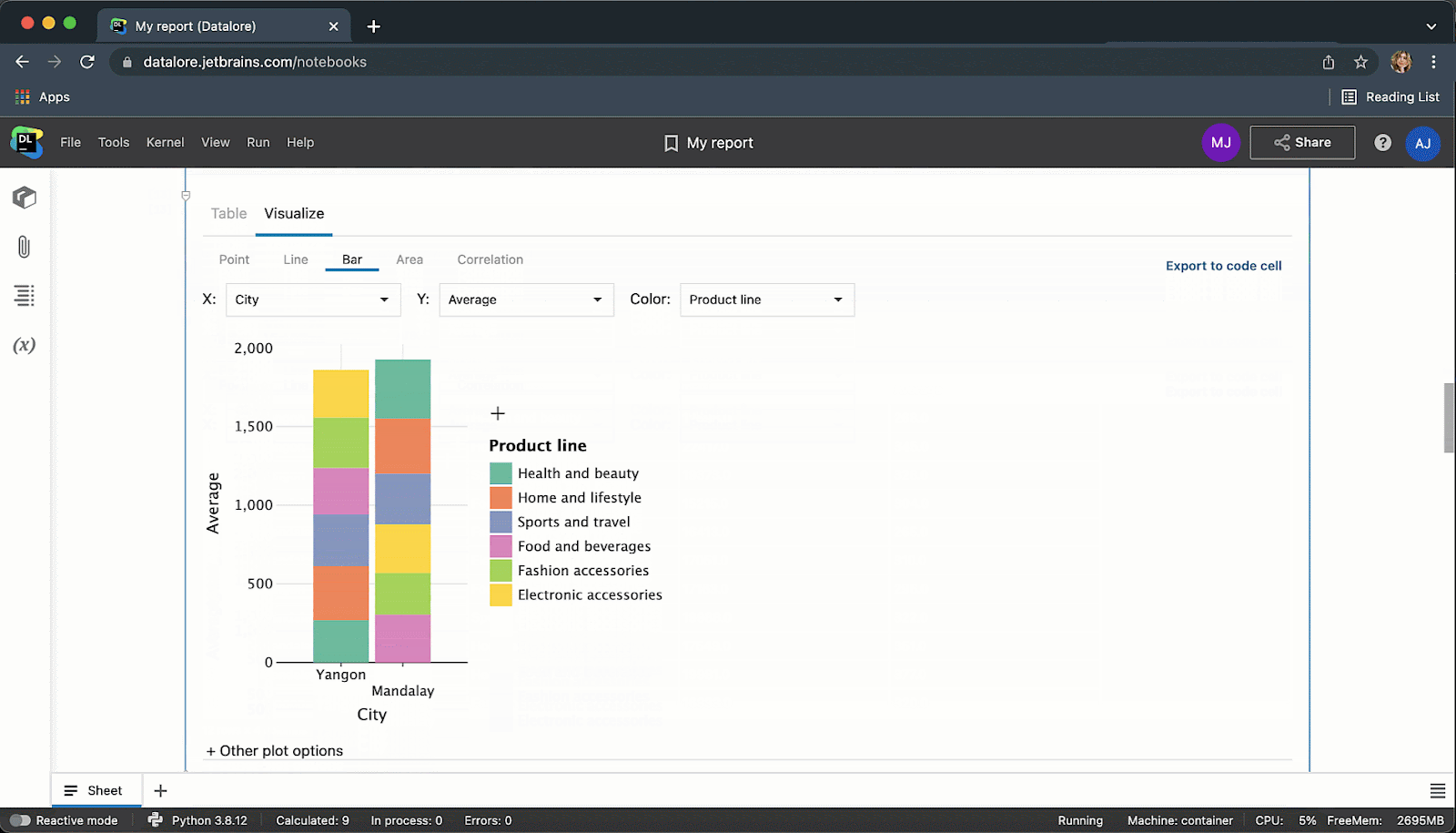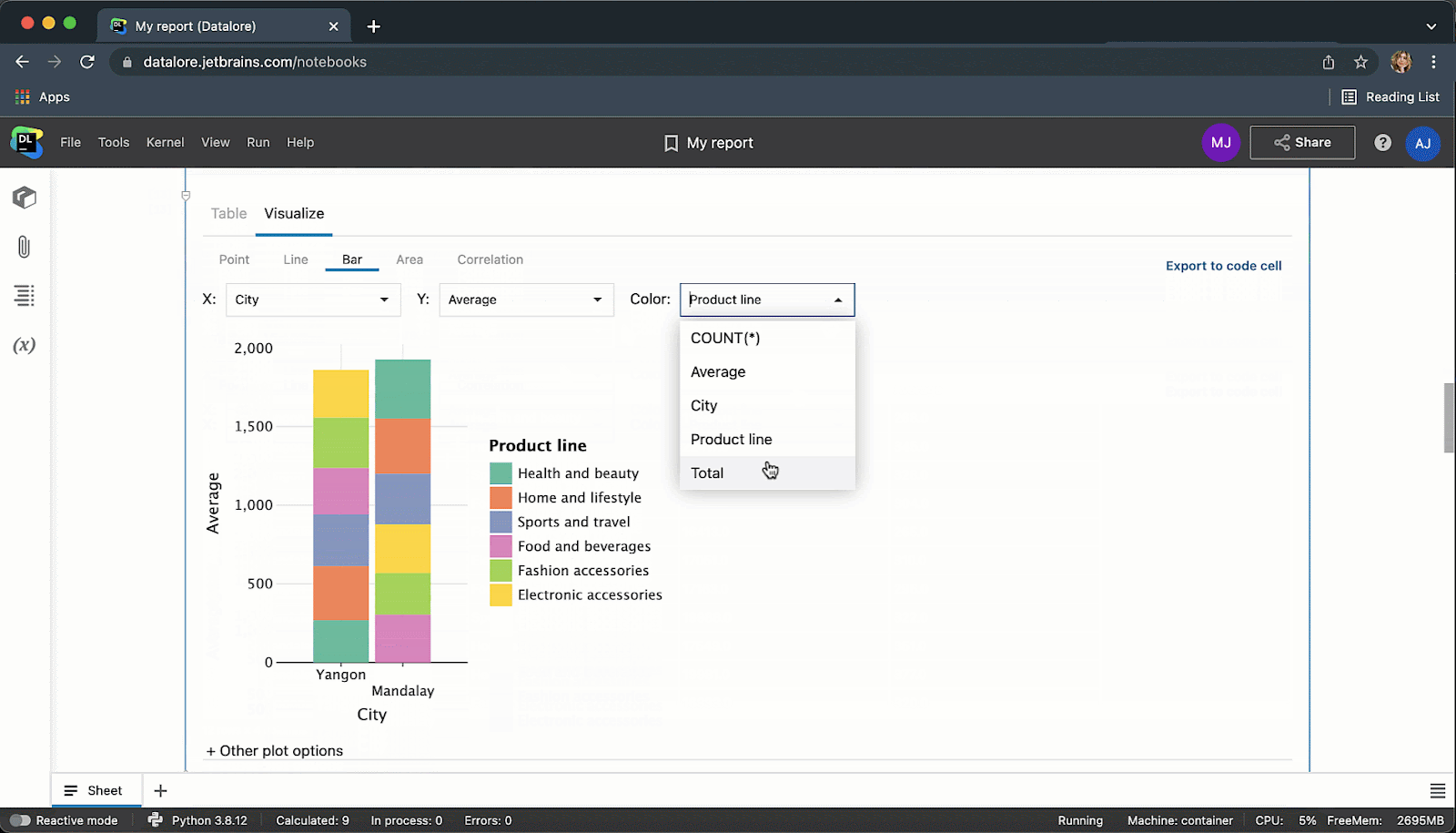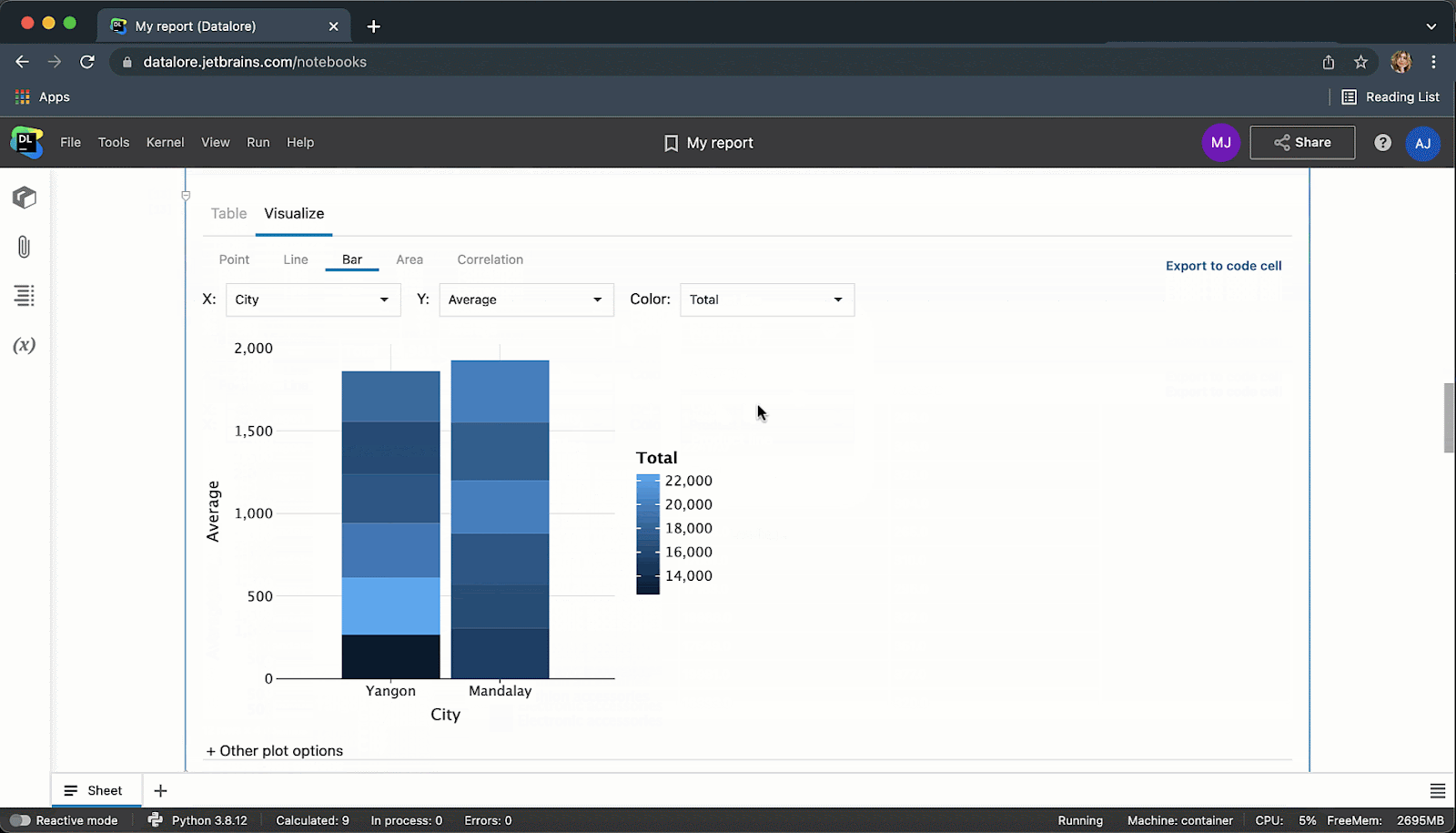
我们是否提到您在 Datalore 中可以实时协作处理 SQL 代码?
完成后,您可以将结果发布为报告,并通过链接与全世界分享您的数据故事。
今天的文章就到这里! 我们希望这些在 Jupyter Notebook 内使用 SQL 的简单方式能够让您的数据科学家工作变得更加轻松。 要获取有关使用 Jupyter Notebook 的更多提示,敬请订阅我们的博客动态并在 Twitter 上关注我们!
祝您愉快投身数据科学!
Datalore 团队
链接:
英文博文原作者:

