

使用 GoLand 分析 Go 代码

本文由外部贡献者撰写。

现代软件堆栈包含许多移动的部分。 由于各个部分可能依赖于不同的依赖项,应用程序性能中的瓶颈会很难确定。
分析可以为应用程序的运行情况和改进方向提供深入见解。 通过识别代码问题(例如内存、CPU、I/O 和其他组件中的瓶颈),应用程序分析可以帮助提升性能,这对于实施优化和提升用户体验至关重要。
此外,在火焰图和其他工具的帮助下,分析还可以展示程序在何处花费了最多时间,从而帮助调试。 从分析文件获得数据后,软件工程师可以使用这些信息实现有助于提升性能的代码更改、检测内存泄漏,以及优化整个应用程序。
在这篇博文中,我们将介绍如何使用 GoLand 及其内置功能,例如 CPU、内存、互斥和阻塞分析器。 本文还将说明如何理解来自这些分析器的数据以提升示例程序的性能和运行时。
分析 Go 函数
Go 生态系统提供了大量 API 和工具,您可以借助 CPU、内存、块和互斥分析器分析 Go 程序,以及利用 pprof 等工具可视化和解析分析数据。
生成 CPU 分析文件后,您可以在浏览器或文本编辑器中将其打开。 CPU 分析文件的生成相当冗长,但 GoLand 中的内置分析器可以大幅简化这一过程。
GoLand 使用 pprof 软件包收集所有必要数据。 GoLand 提供分析数据可视化,使识别瓶颈和优化代码更加简单。 它还可以比较不同的分析文件,通过测试和分析单个函数来比较应用程序不同部分的性能。
前提
在开始探索这些工具之前,首先要准备好:
- 一台装有 Go 的机器。
- GoLand 作为 IDE 安装在机器上。
您可以在此 GitHub 仓库中找到本文使用的所有代码。
CPU 分析器
CPU 分析器有助于理解函数占用的 CPU 时间百分比。
设置示例程序
首先,准备一个要分析的示例程序。 本示例使用了一个计算第 n 个斐波那契数的 Go 程序。 斐波那契数列是一系列数字,其中每个数字都是前两个数字的和。 数列如下所示:
1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, ...
斐波那契程序的代码如下:
package main
// Package main is the entry point
import "fmt"
// Import fmt to use Println to show output
func FibRecursive(n int) uint64 {
// Function Creation to accept integer till which the Fibonacci series runs
if n == 0 {
return 0
// Base case for the recursive call
} else if n == 1 {
return 1
// Base case for the recursive call
} else {
return FibRecursive(n-1) + FibRecursive(n-2)
// Recursive call for finding the Fibonacci number
}
}
func main() {
// Function call to print out the nth term of the Fibonacci series
fmt.Println(FibRecursive(3))
}
将程序保存为 main.go 后,您可以使用 go run main.go 运行。 也可以使用内置的 GoLand 运行器。
设置示例单元测试
接下来,创建一个单元测试,帮助对程序进行测试和分析或基准测试。
以下代码演示的测试逻辑基于数列中第 30 个元素等于第 40 个斐波那契数 102334155:
package main
import "testing"
func TestFib2(t *testing.T) {
if FibRecursive(40) != 102334155 {
t.Error("Incorrect!")
}
}
要进行手动测试,可以使用 go test 命令,或者运行 CPU 分析,打开 _test.go 文件,转到 TestFib2 函数,然后点击间距区域中的 Run(运行)图标,选择 Profile with CPU Profiler(使用 CPU 分析器分析):
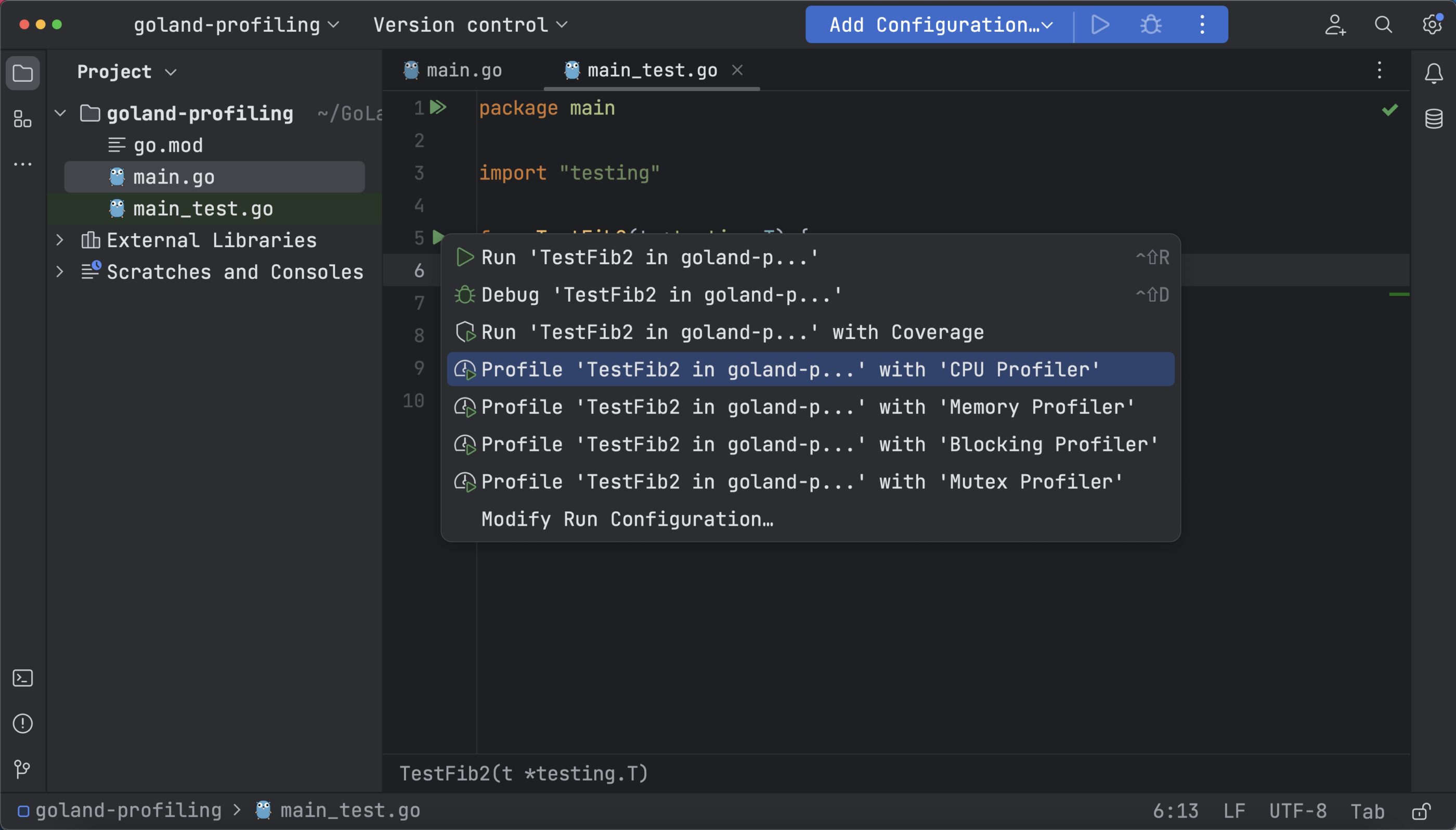
现在,分析数据以火焰图、调用树和方法列表的形式表示。 火焰图借助堆栈跟踪显示函数的 CPU 使用情况。 可以看出,测试函数和其他递归调用花费的时间最多。 这个时间由图中最宽的块表示:
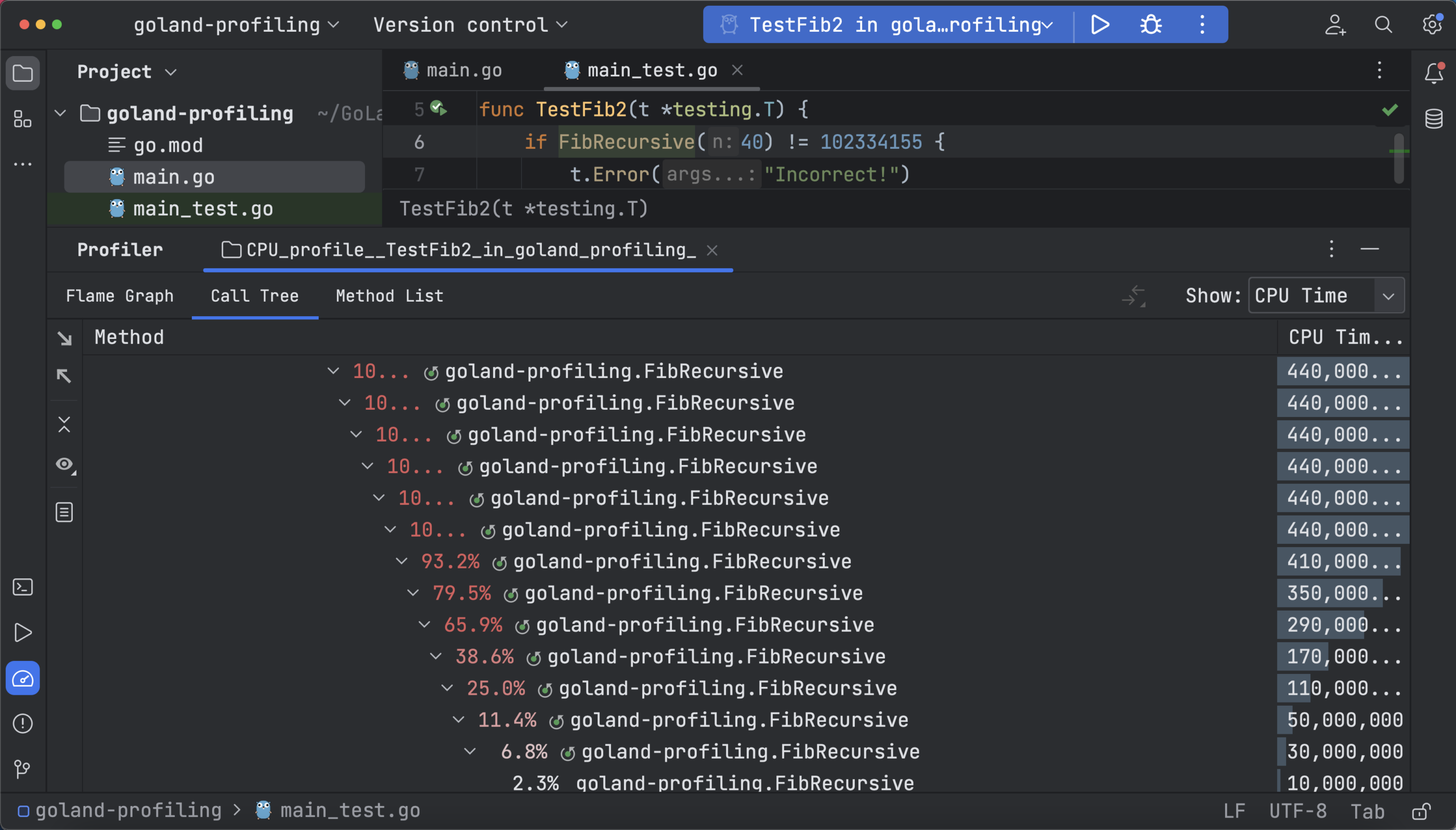
调用树有助于从函数和关联的元数据理解示例调用堆栈,还具有筛选调用序列的选项。
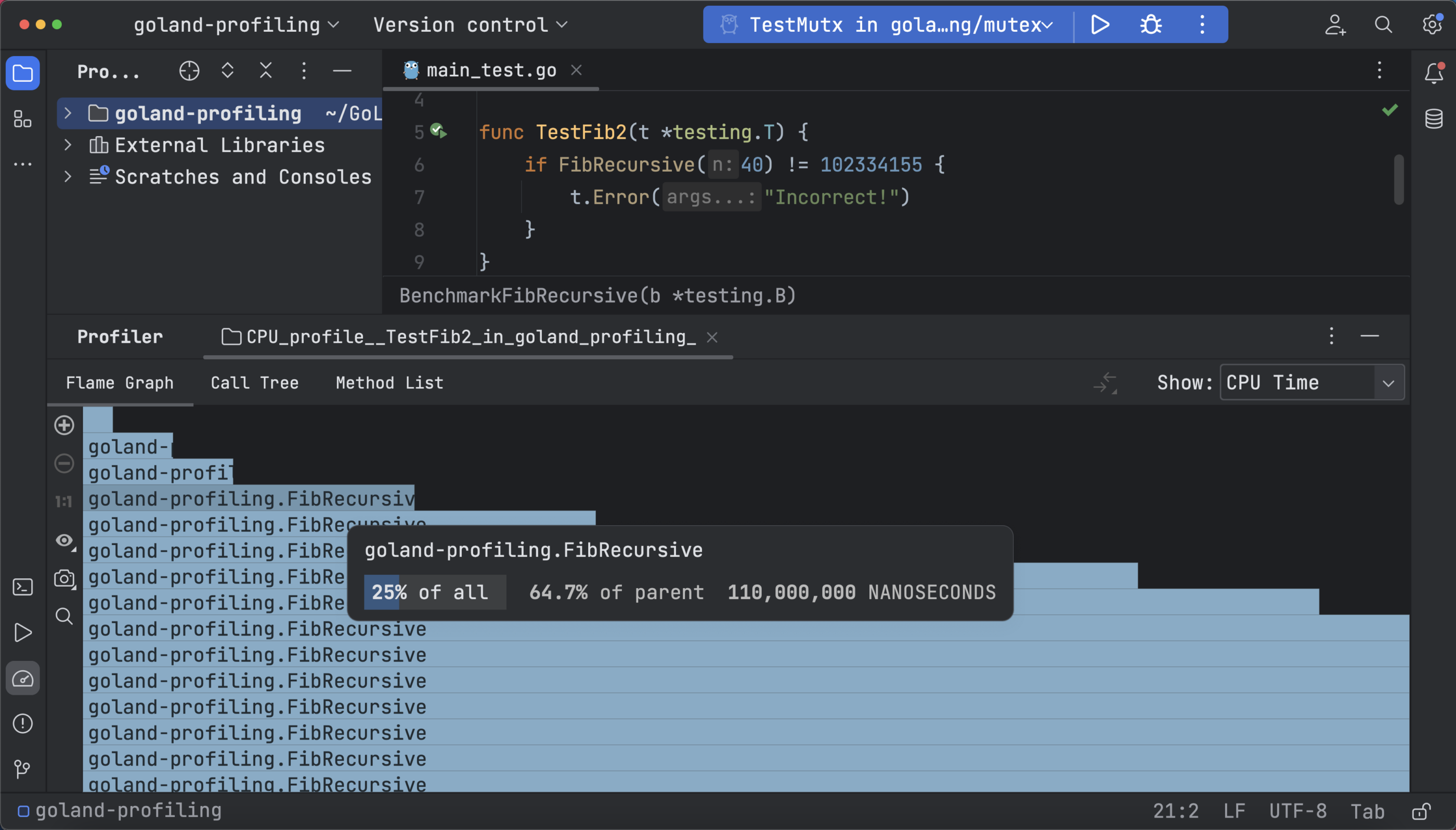
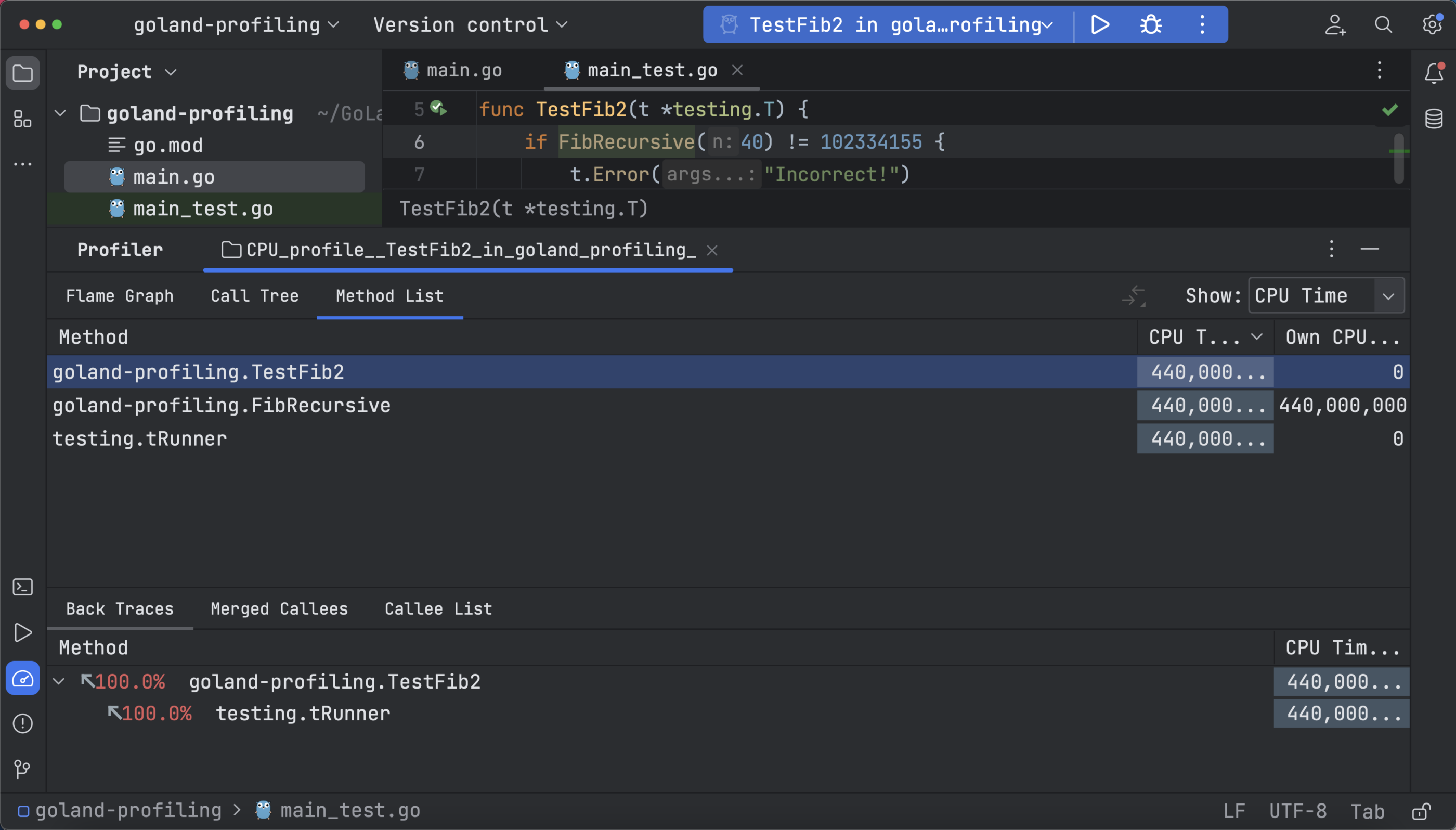
方法列表可用于收集所有函数,并在累积采样时间内对其进行排序,每个方法都带有回溯与合并被调用方支持。 以下是选择 CPU 时间时递归 FibRecursive 函数的合并被调用方和调用树:
分析的作用
分析有助于了解应用程序的运行情况以及优化方向。 以斐波那契数列程序作为实例。 程序的 CPU 分析文件显示,对 FibRecursive 函数的递归调用占用了大部分 CPU 时间。 因此,优化递归调用应该是第一要务。
要优化具有许多递归调用的程序,您可以设置一个数组来存储调用值并使用记忆化缓存结果:
package main
import "fmt"
var f [100010]uint64
func Fib(n int) uint64 {
f[0] = 0
f[1] = 1
for i := 2; i <= n; i++ {
f[i] = f[i-1] + f[i-2]
}
return f[n]
}
func main() {
fmt.Println(Fib(3))
}
使用更新后的程序运行 CPU 分析器不会显示任何分析数据,因为程序现在的运行速度太快,分析器无法收集样本。 由于您能够消除递归调用,这显然意味着改进。
要验证更改确实提升了性能,您可以使用基准测试。
Go 标准库提供了一个 testing 软件包,可供创建基准和衡量代码性能。
以下是对斐波那契示例中的更改进行测试的示例基准:
func BenchmarkFib(b *testing.B) {
for i := 0; i < b.N; i++ {
Fib(1)
}
}
运行基准测试时,您将获得指示程序效率的以下结果:
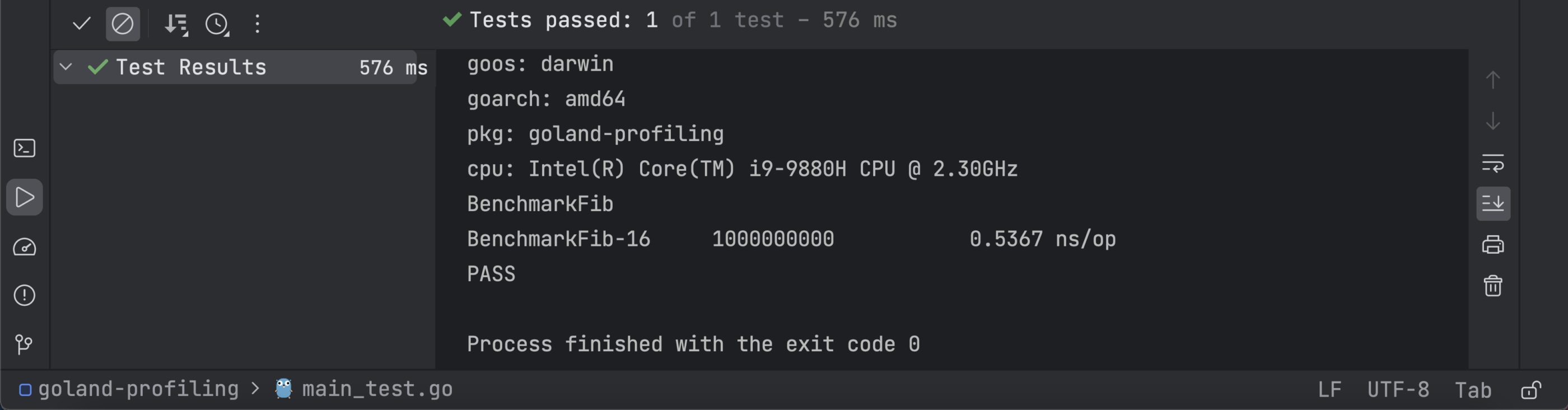
使用以下代码,您可以对初始 FibRecursive 函数进行基准测试:
func BenchmarkFibRecursive(b *testing.B) {
for i := 0; i < b.N; i++ {
FibRecursive(1)
}
}
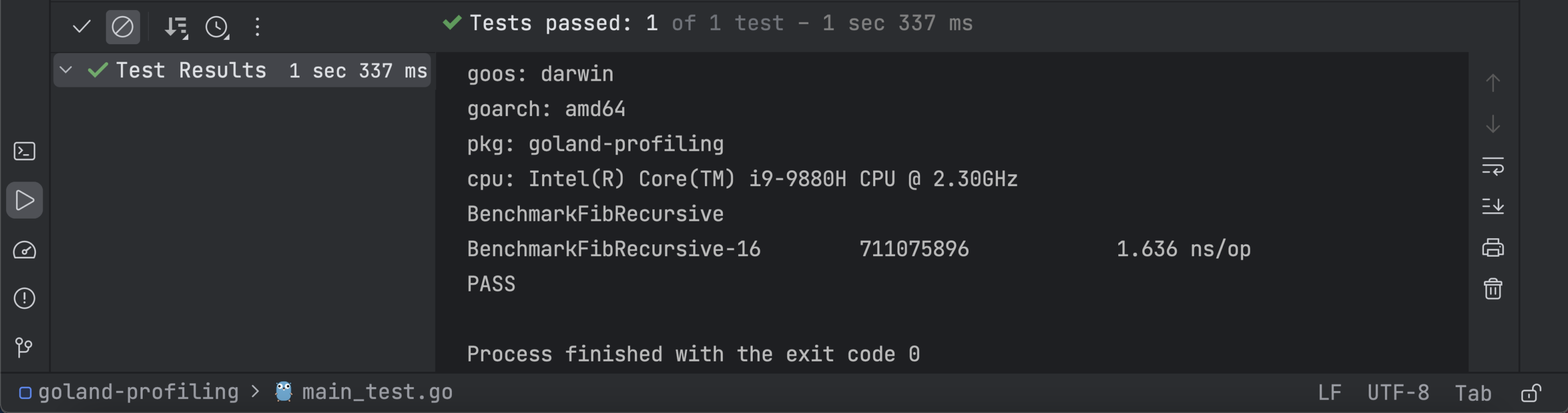
可以看到,Fib 函数花费的时间 (0.5367 ns/op) 比 FibRecursive 函数 (1.636 ns/op) 少得多,这表明性能显著提升。
内存分析器
内存分析器通过显示函数和分配的堆来分析和识别内存泄漏和总体内存使用情况。 要运行内存分析,请打开 _test.go 文件,然后点击间距区域中的 Run(运行)图标并选择 Profile with Memory Profiler(使用内存分析器分析)。
这里的分析数据也以相同的三种方式表示:火焰图、调用树和方法列表。 下面的火焰图数据显示了分配的空间和对象,并以更详细的视图显示了正在使用的对象和空间:
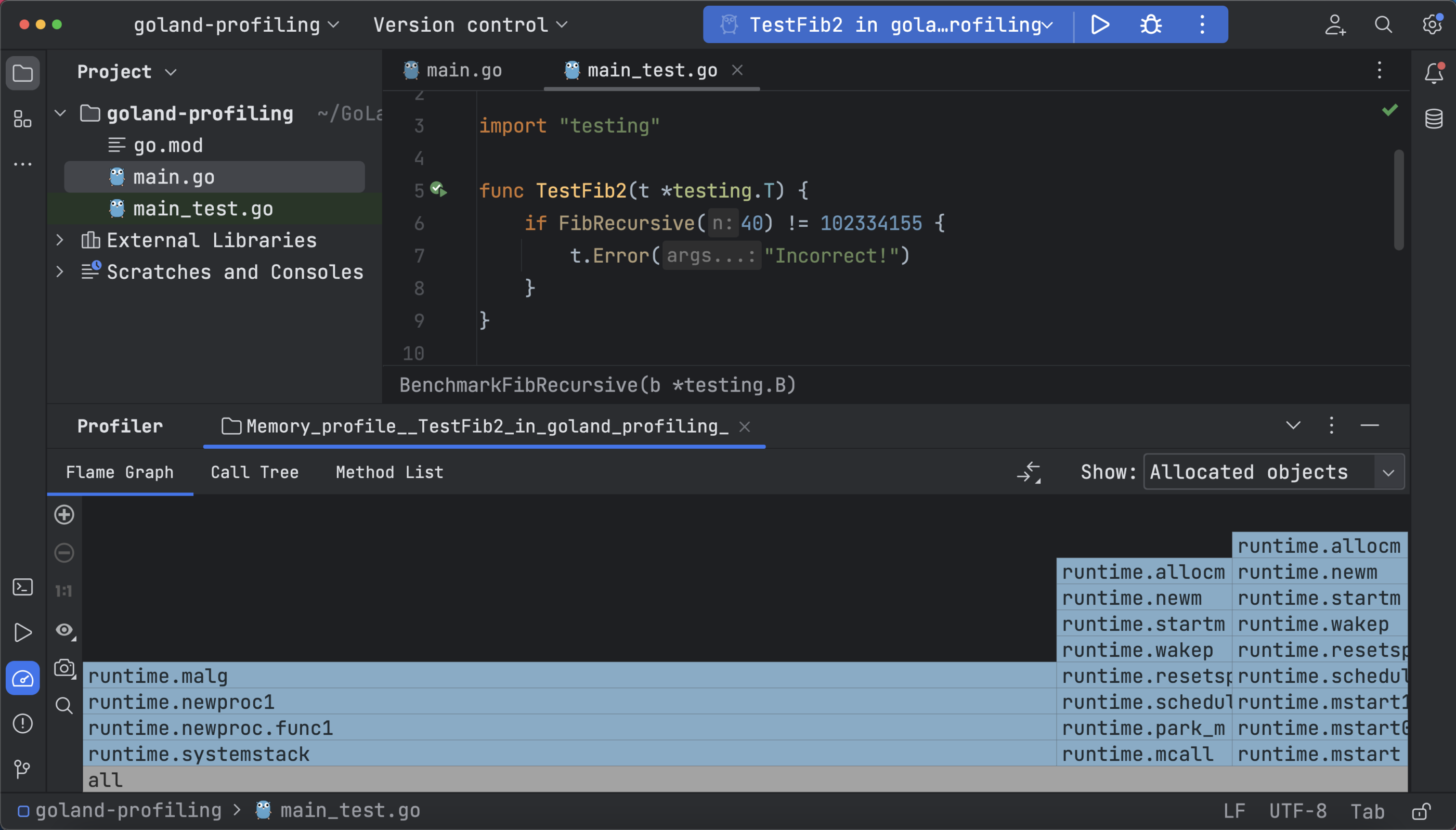
由于小分配直接影响执行速度,可以通过减少小对象的数量来实现内存优化。
调用树显示了内存中对象的内存使用情况,方法列表显示的数据与火焰图中的相同,但显示的方式是表格,可供浏览各个方法和筛选调用:
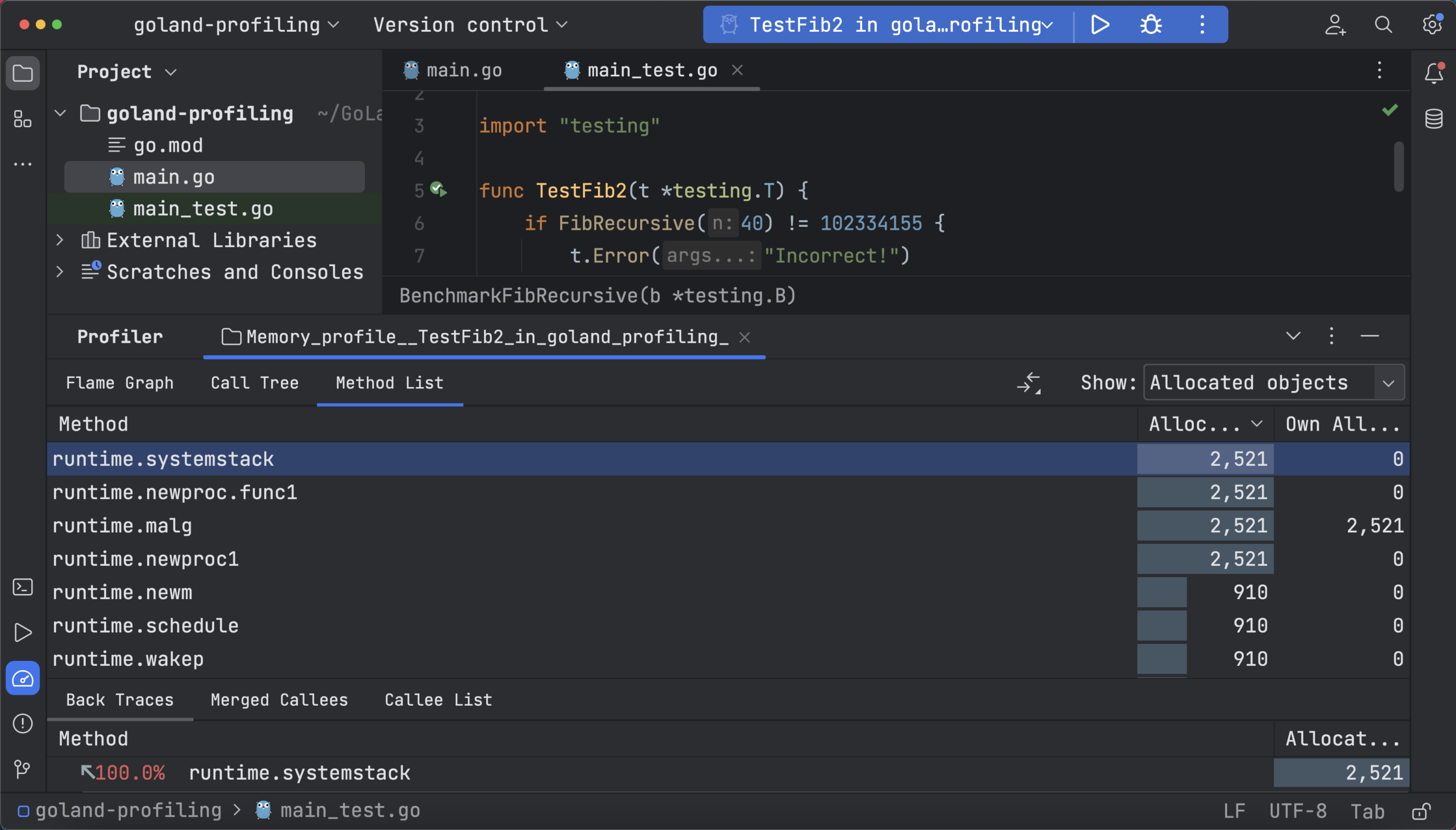
阻塞分析器
阻塞分析器对于定位未缓冲或完整通道、sync.Mutex 锁或其他瓶颈非常有用,因为它会显示 goroutine 未运行(等待)的时间段。 将以下代码添加到 main.go 后,选择 Profile with Blocking Profiler(使用阻塞分析器分析)运行分析器:
package main
import (
"sync"
"time"
)
var ch = make(chan int)
func Block() {
// WaitGroup is used to make the function wait for G1 and G2 to finish
wg := sync.WaitGroup{}
wg.Add(2)
go G1(&wg)
go G2(&wg)
wg.Wait()
}
func G1(wg *sync.WaitGroup) {
// Write to the channel
ch <- 100
wg.Done()
}
func G2(wg *sync.WaitGroup) {
// Sleep for 1 second
time.Sleep(time.Second)
// Read from the channel
<-ch
wg.Done()
}
在上面的代码中,G1 被阻塞,因为它无法在 G2 从休眠中醒来并准备好读取之前写入通道。
以下测试会检查 Block 函数:
func TestBlock(t *testing.T) {
// Call the block function
Block()
}
下面的火焰图显示了函数等待的时间(如果选择了 Delay(延迟))或争用的数量(如果选择了 Contentions(争用))以及调用树中属于同一父项的过程之间的百分比差异:
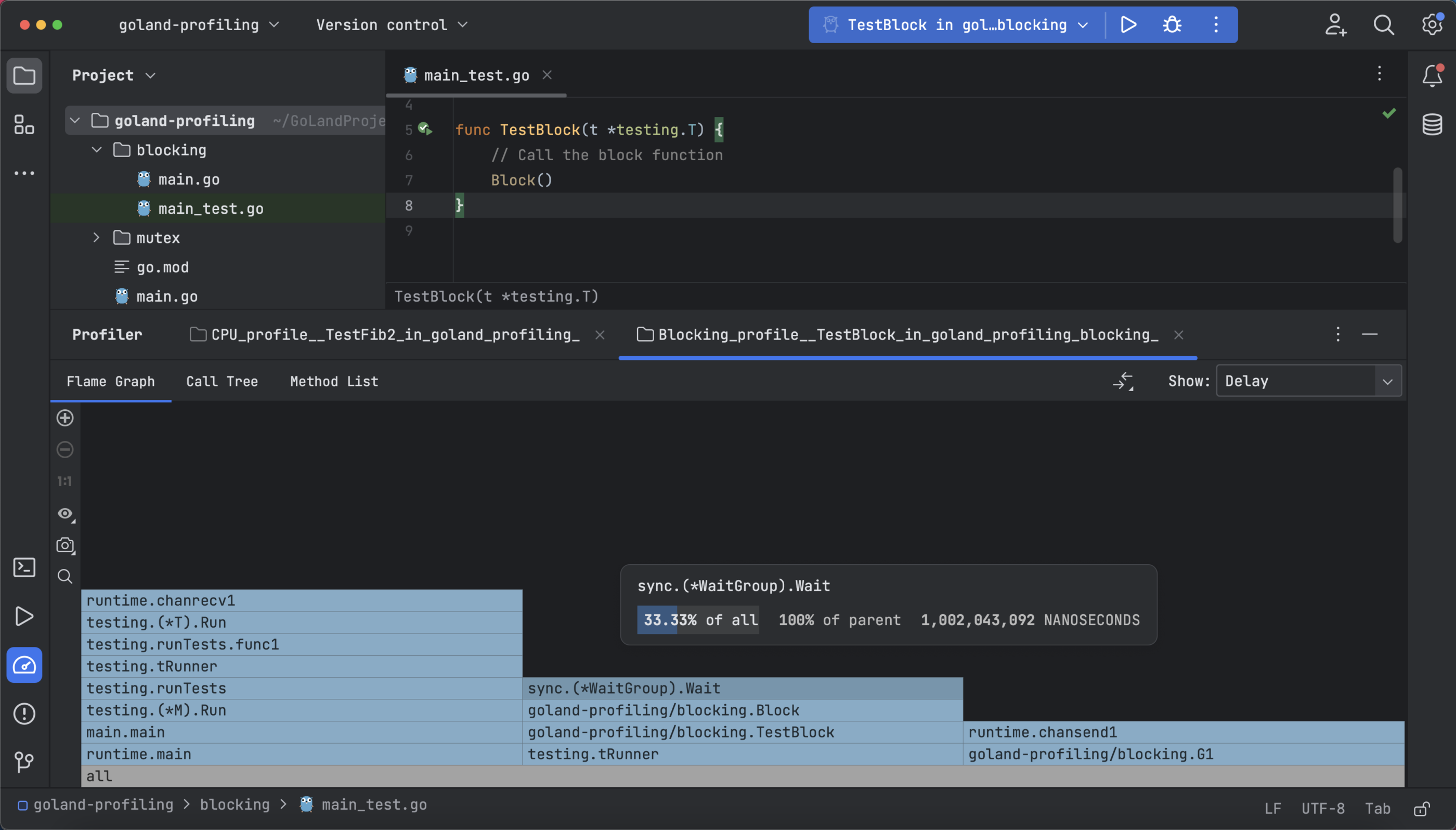
方法列表显示争用的数量,调用树显示每个函数中具有延迟的争用,具体取决于选择的是 Delay(延迟)还是 Contentions(争用)。
Mutex 分析器
您可以使用互斥分析器分析并发代码,并查看具有并发互斥的 goroutine 的堆栈跟踪片段,了解线程阻塞的原因。
互斥分析器也有三种类型的数据表示形式。 您可以使用以下示例生成分析文件:
package main
import (
"sync"
"time"
)
func Mutx(s int) int {
var mu sync.Mutex
wg := sync.WaitGroup{}
wg.Add(1000 * 1000)
// Launching 1,000,000 goroutines
for i := 0; i < 1000*1000; i++ {
go func(i int) {
// Locking the mutex
mu.Lock()
// Unlocking the mutex
defer mu.Unlock()
defer wg.Done()
s++
}(i)
}
wg.Wait()
return s
}
上面的代码启动了一百万个 goroutine,它们都尝试将共享变量 s 递增 1。 为此,创建一个互斥,并在递增变量之前将其锁定。 递增变量后,将互斥解锁。 设置一个 WaitGroup 以等待所有 goroutine 执行完成。
使用以下测试检查 Mutx 函数:
package main
import "testing"
func TestMutx(t *testing.T) {
result := Mutx(4)
t.Logf("%d", result)
}
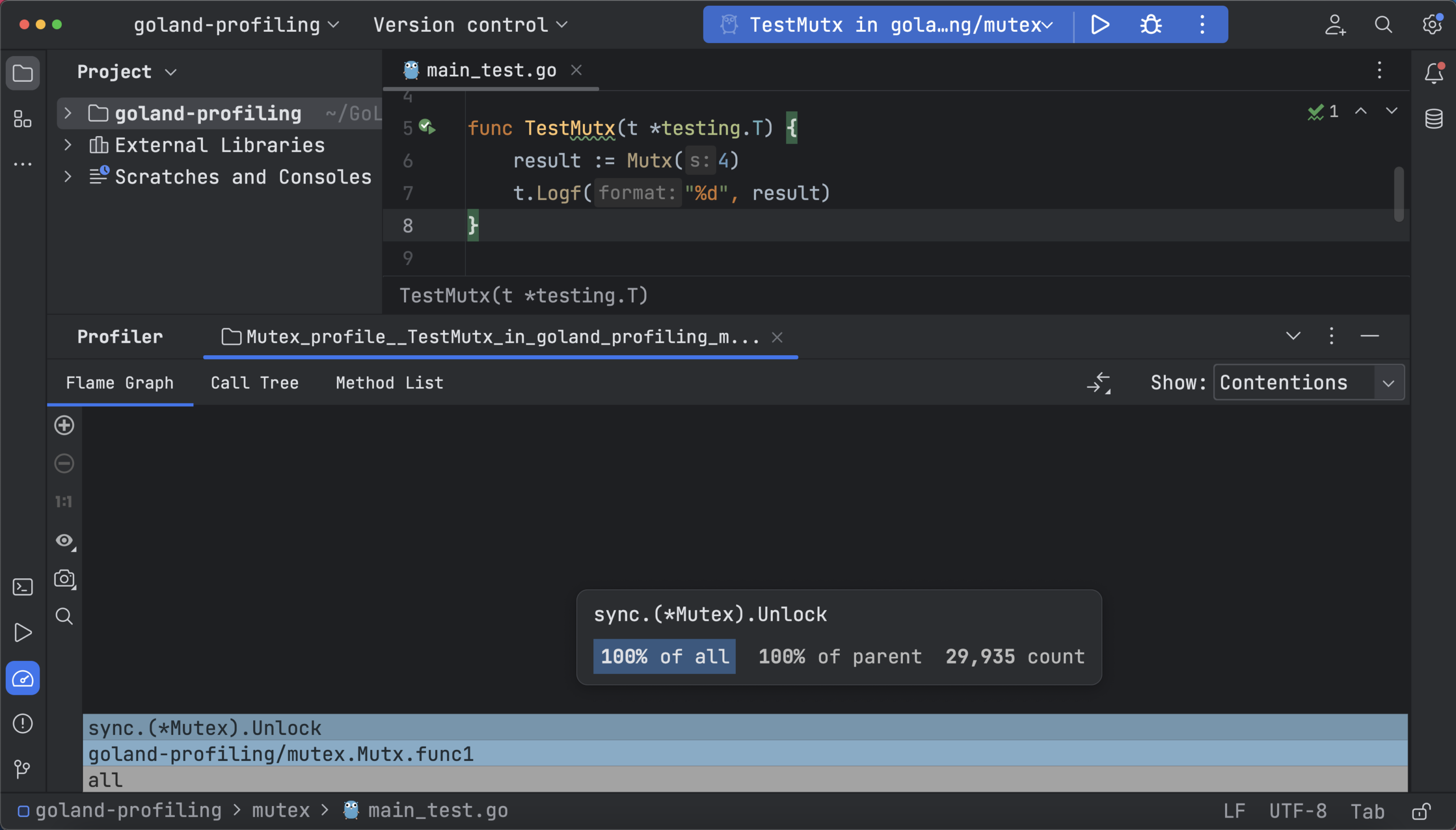
要运行此分析器,请打开 _test.go 文件,然后点击间距区域中的 Run(运行)图标并选择 Profile with Mutex Profiler(使用互斥分析器分析)。 火焰图显示延迟的数量或等待的时间,具体取决于选择的是 Contentions(争用)还是 Delay(延迟)。
总结
分析是一项关键软件优化技术,掌握基础知识即可提高效率。 GoLand 等工具将使这个过程更加高效直观。 另外,还请牢记,分析只是帮助您理解代码的工具。 实际工作仍在您这边:CPU、内存、互斥和阻塞分析器可以帮助您检查代码是否高效,但如果发现存在不足的地方,还是要由您来上手修正。
要详细了解 Go 中的分析和性能,请查阅官方文档。
本博文英文原作者:




