

Code Completion, Episode 4: Model Training

The previous articles from the series covered the following topics:
- In the first episode, we discussed general code completion scenarios.
- The second episode was devoted to the difficulties of heuristics-based implementation and explaining the necessity of machine learning.
- In the third episode, we described the data we collect from IDEs to train the completion ranking algorithm.
We would like to talk about the difficulties specific to our task and share the ways to overcome them that we found.
Due to the data protection requirements described in the third article, everything we collect is anonymous. We have a set of numeric or enumerable parameters related to each completion invocation, but we never have the source code that triggered it.
Solving data science problems without access to the original data is challenging. If something weird appears in the results, we can’t just examine the input data. We have to perform tricky investigations in all such cases.
Here is an example to illustrate what “a weird result” looks like.
A detective story
We noticed a group of users who very seldom chose anything from the completion pop-ups. The group was too big to explain with statistical outliers, so we started investigating.
How are these people different from the others?
- They have the same level of activity.
- They use the same programming languages.
- The completion pop-ups appear with the same frequency for them and other users.
After checking several hypotheses, we concluded that, somehow, the completion rankings were broken in their IDEs. The relevance scores of the top suggestions were much lower than usual for these users. We could see only that much from the logs, as we don’t record the pop-up’s contents.
Can you guess what happened? It took adding a few log fields to figure it out, but we found the cause. They all had the same option enabled in the completion settings:
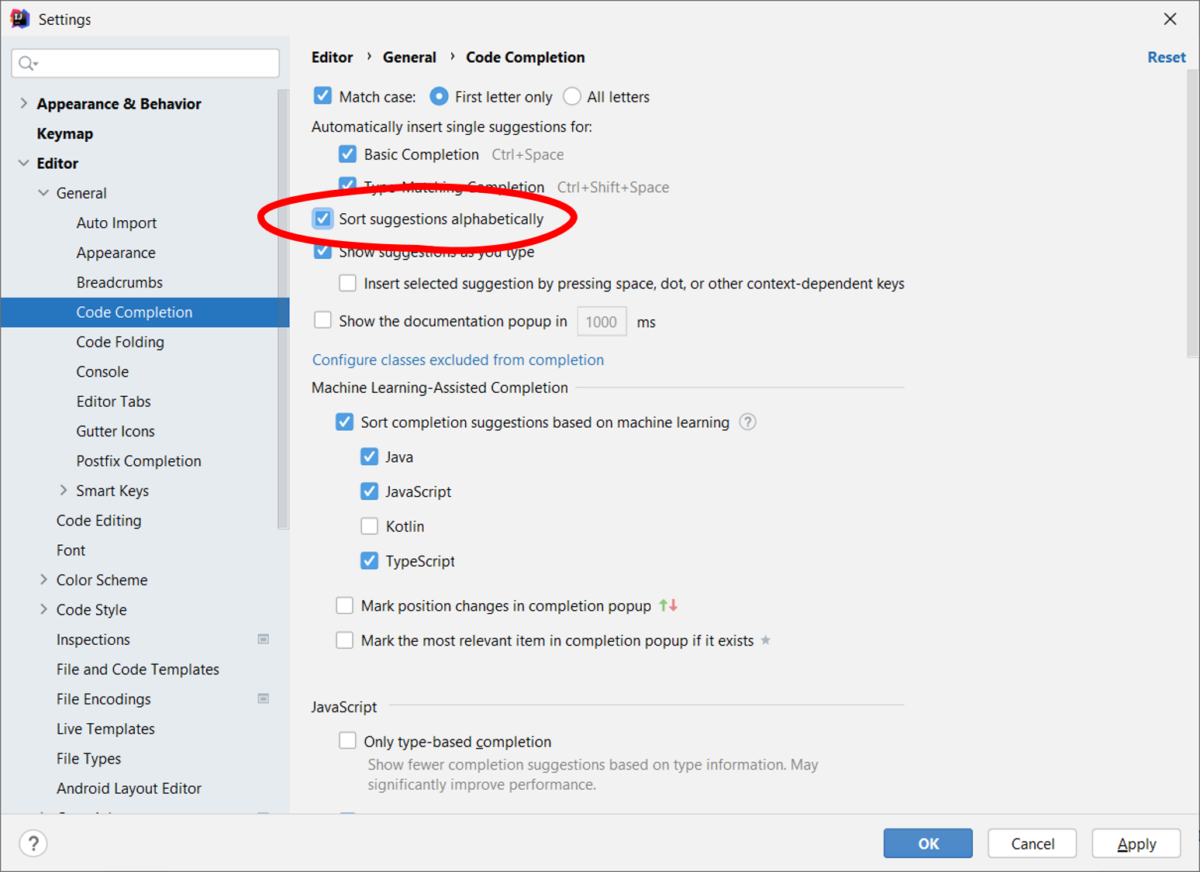
Users often can’t even see the best options, as those options don’t fit on the screen when suggestions are sorted alphabetically.
We now store one more enumerable value in the logs: does the user have alphabetical sorting enabled? We need this parameter to remove such user sessions from our training sets and metric calculations. This filter is the only significant data cleanup step in our process.
If you are using this sorting option, please let us know why.
Target metric
Now that we have the data prepared, we can set the target that our ML-based algorithm will try to achieve.
What is the target metric?
In case you are not familiar with the term, here’s a brief, informal explanation. When training an ML-based system, we create some quantitative limitations that enforce the desired behavior. These limitations determine which cases our software will handle well and which ones it is ok to ignore and make mistakes on.
Let’s compare it to driving a car. The drivers quickly learn to follow rules that are penalized with high fines. For example, the countries that start enforcing seatbelt laws find that everyone drives with seatbelts fastened after just a few years. I like this example because many people still remember when seatbelts were not mandatory and can recall how their mindset changed.
On the other hand, the law rarely punishes people for not using their turn signal when changing lanes. Therefore, the drivers often change lanes without signaling.
Machine learning works the same way. You need to develop a punishment system that forces the formula to perform well in situations you consider essential.
Now let’s apply this concept to our software. There’s only one crime the completion system can commit: giving the top position to the wrong suggestion. How can we express a punishment for that in numbers?
Average position approach
The first thing that we tried was raising the average position of the correct result.
This optimization is available out-of-the-box in the Scikit-learn implementation of the Random Forest algorithm. The metric name is RMSE (Root Mean Square Error). This target causes the algorithm to place the correct answers closer to the top across our dataset.
This approach works well with relevance-based ranking tasks, for example, in a search engine.
To follow the further improvements that we made, let’s first look into what relevance is. We encounter it every day using Google (or Bing, Yandex, DuckDuckGo, etc.), so the concept seems intuitive. However, there is a substantial difference between search engines and code completion. In a web search:
- Several documents can be relevant to a query.
- There are degrees of relevance.
Imagine that you perform scientific research about code completion and issue a query: code completion relevance.
Google might return the following results at the top of the page:
Code Completion article from WebStorm’s site
As much as we love JetBrains products and websites, this article is probably irrelevant given the context of the query. It mentions sorting by relevance eight times, though.
Learning from Examples to Improve Code Completion Systems
Here we have a scientific paper by the researchers from Darmstadt University. This article is a good match for the query.
Page at researchgate.net devoted to the same article as the above.
This document is somewhat relevant: it doesn’t provide the full text of the paper but it gives an option to request it from the authors. Not perfect, but better than nothing.
We have three results and three degrees of relevance here. One is entirely off the mark, the other is very useful, and the third is somewhat helpful. This example illustrates the fact that we can measure web search relevance in shades of grey. Lifting better documents across all of the queries works when there are many relevant documents, as it makes the result visibly better.
When it comes to code completion, relevance is strictly black and white. There is exactly one good match: the token that the user wants to type. In terms of root mean square error, the right pop-up on the picture below is much better than the left one:
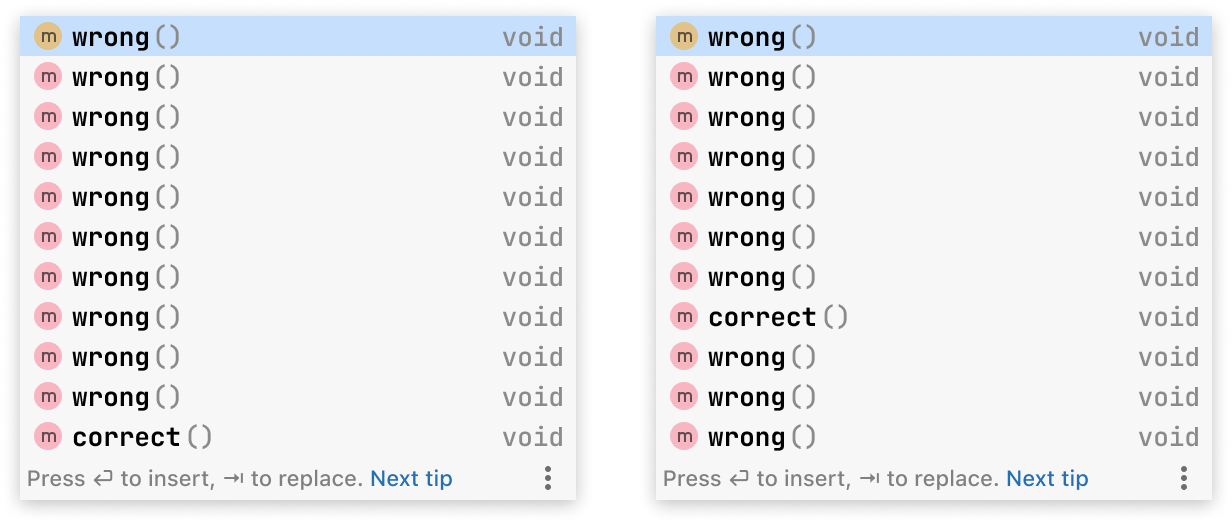
From a practical standpoint, however, they are both wrong. Many of the “improvements” that we saw during the training were of that nature. The model was happy to move the correct answer from position 200 to position 100. Numerically, such a change is a huge improvement, but practically, both options are equally unhelpful.
Top-position-only approach
We want the correct answer in the first position only. The metric should only give credit for the desired result on the first position.
Scikit-learn Random Forest doesn’t provide that functionality. We tried CatBoost, which has the QuerySoftMax target metric out of the box to optimize the top position without writing any additional code. This metric was introduced as the ListNet loss function in a research paper authored by Zhe Cao, Tao Qin, Tie-Yan Liu, Ming-Feng Tsai, and Hang Li.
We trained the formula with CatBoost targeting QuerySoftMax, and lo and behold, the success rate of our completion went up 10%! The developers started selecting items from our completion pop-ups 10% more often than before!
We wanted to identify the reason for the change. Did the improvement happen due to metric selection, or was CatBoost just a better ML framework? We trained another formula with CatBoost targeting RMSE, and the result was on par with Random Forest. We concluded that QuerySoftMax optimization was the cause.
Key findings
First, creating a code completion system using fully anonymized logs as a training set is possible. It’s a bit inconvenient to debug, but it is doable.
Moreover, a fairly small dataset is sufficient. We train on ~30,000 completion sessions which we collect from our EAP users.
Second, target metric selection is critical for success. Don’t use RMSE if your relevance is “winner takes all.” Switching to a better metric makes sense, even if it forces you to change the ML framework.
What’s next?
In the next episode, we will talk about quality evaluation. Once we have a new formula, how do we ensure it is better than the old one?
Each new formula goes through an extensive trial. We would like to share the following details:
- We have an automated testing tool that catches trivial bugs.
- We run an A/B test, which is unusual for a desktop application.
- We know how to get a statistically significant result with just a few hundred users.
Stay with us to learn more about how we do it!




