

Big Data Tools
A data engineering plugin
Big Data Tools 1.0 Generally Available

A new update of the Big Data Tools plugin has been released. This is our first version for general use, after a year and a half of the Early Access Preview program.
Install the plugin from the JetBrains Plugin Repository or from inside your IDE to edit Zeppelin notebooks, upload files to cloud filesystems, and monitor Hadoop and Spark clusters. The following JetBrains IDEs support the plugin: IntelliJ IDEA Ultimate, PyCharm Professional Edition, and DataGrip.
In this release, we’ve added many useful features and addressed a variety of bugs. Let’s dive into the details.
Zeppelin 0.9 Support

The latest version of Apache Zeppelin, 0.9.0, was released last December with 568 tickets resolved, including many new features and bug fixes.
We had been preparing for that for a long time, testing the BDT plugin thoroughly against Zeppelin 0.9-preview2, so finalizing 0.9 support did not take long. Now we invite everyone to try not only the new version of Big Data Tools but also the new version of Zeppelin.
Zeppelin notebook import/export
The Big Data Tools plugin does the small routine operations for you so you don’t have to switch to the web interface too often. The obvious candidate for automatization is the importing and exporting of notebooks. Now you can save your notebook directly from the IDE to your computer and share it with your colleagues.
Zeppelin interpreter and repository settings
Pick Open Interpreter Settings from the notebook context menu to open this new window:
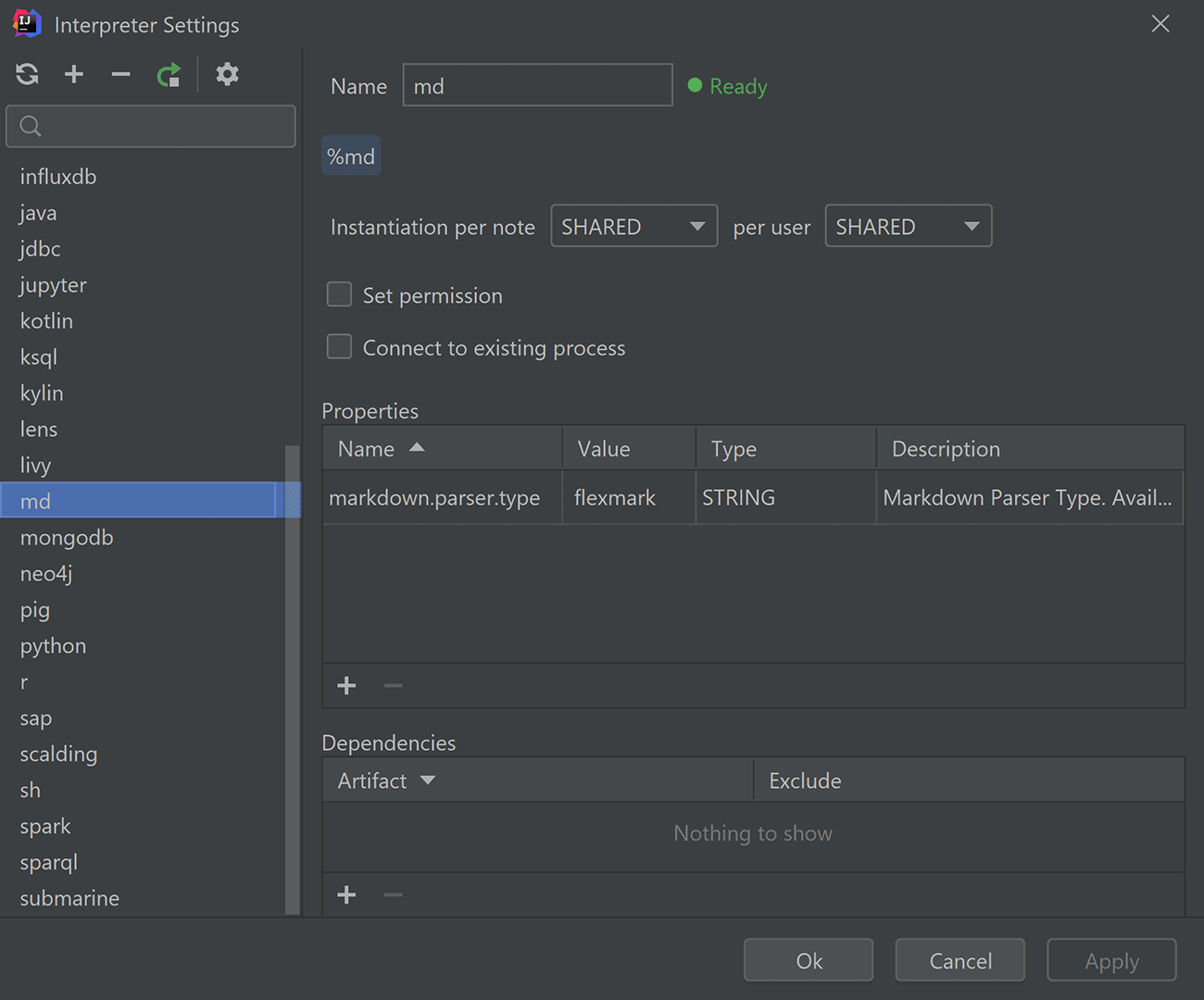
The screenshot shows the Markdown interpreter settings, just as an example. The markdown.parser.type parameter can take values flexmark, pegdown, or markdown4j. The ability to select flexmark is new and available in Zeppelin 0.9 only.
As you can see, the complete list of interpreters is available in this window, and you can change their settings, too.
This interface is an improved alternative for what already exists in the Zeppelin web interface. A big advantage is that you no longer need to open the browser to view or edit any setting.
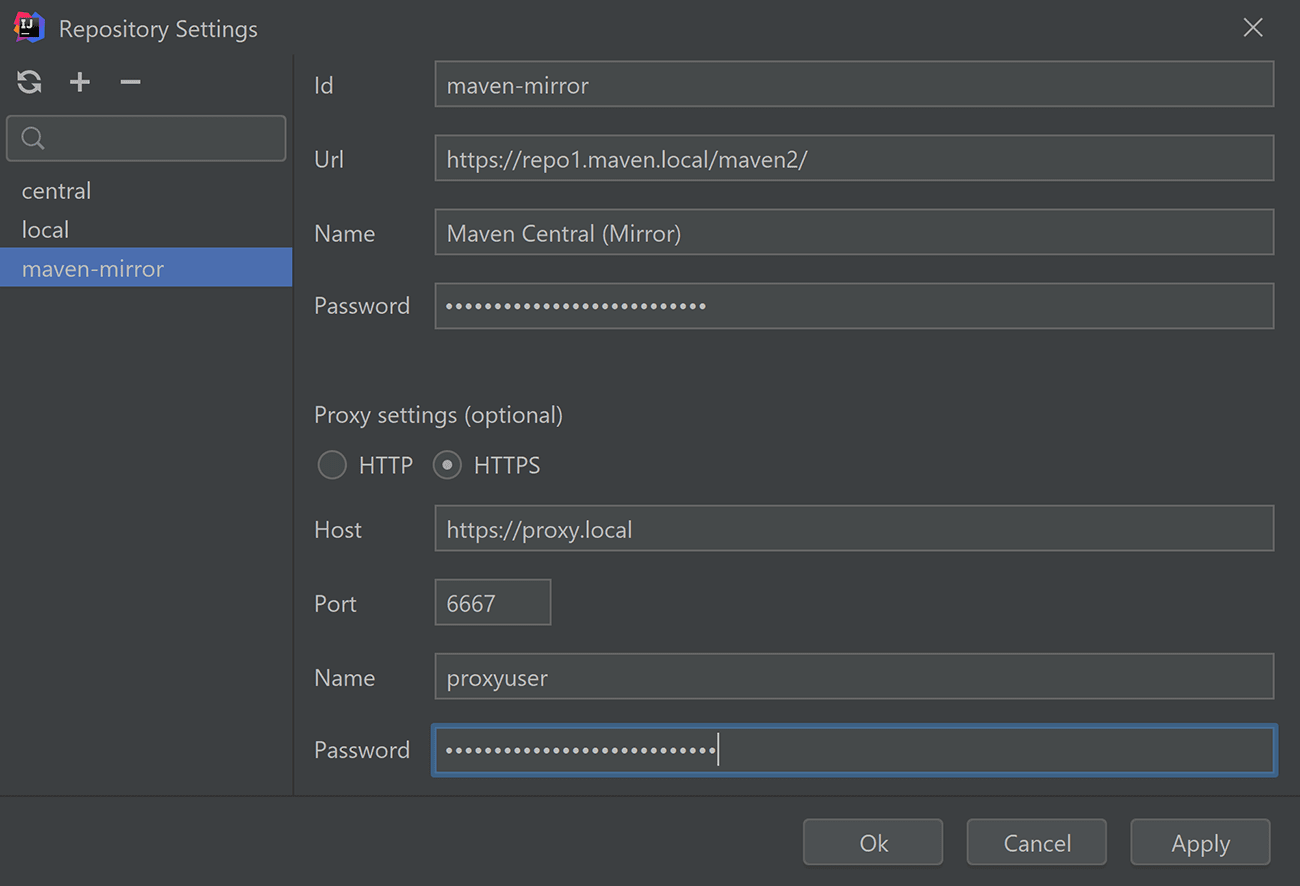
Also in this window, you can reload the interpreter or edit the list of repositories:
Precode highlighting
In Zeppelin, it is possible to declare variables separately from the notebook. All such variables will be available when the interpreter is started, which can be useful for storing configuration values.
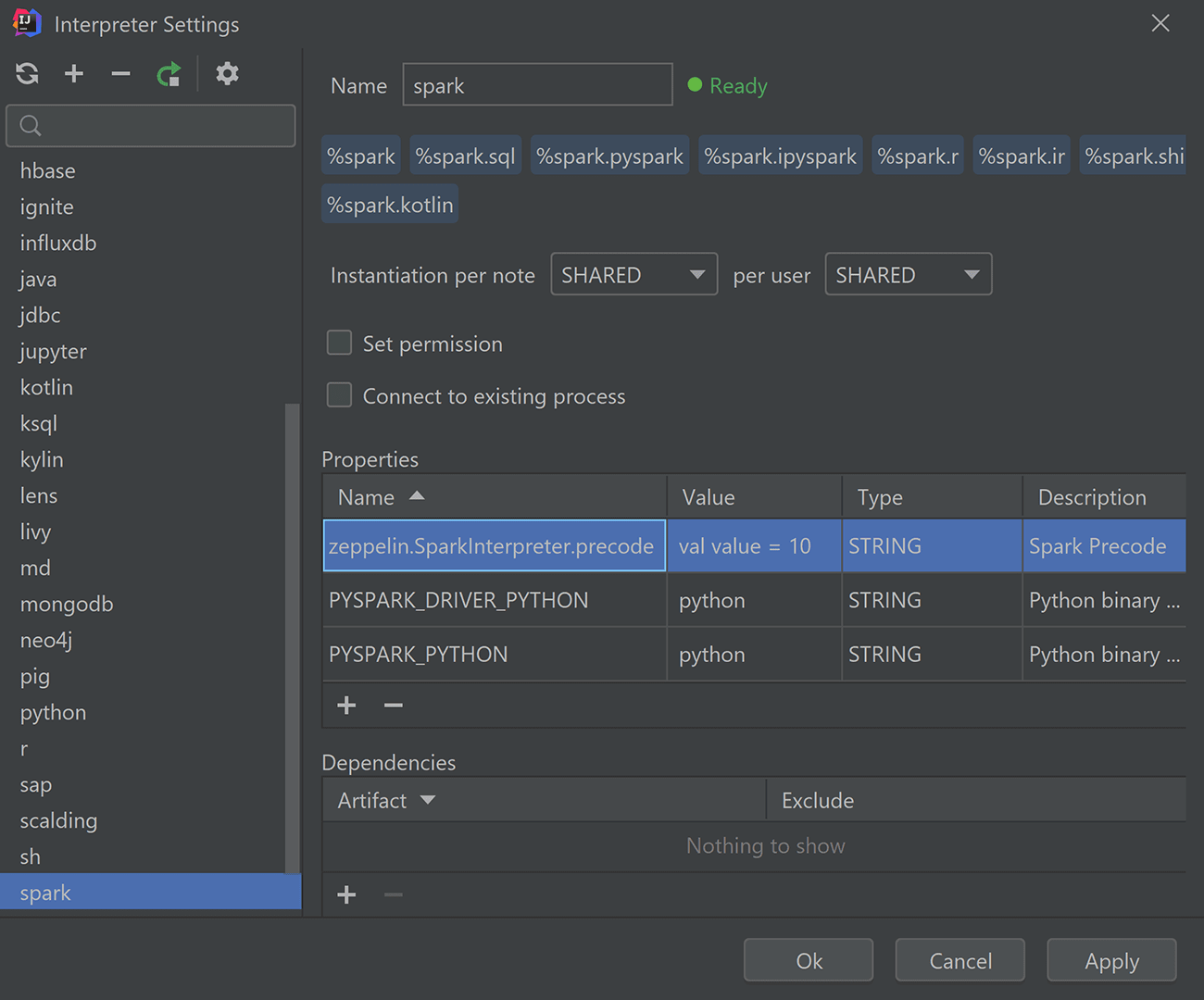
This setting looks like zeppelin.SparkInterpreter.precode. (In theory, any interpreter can be used there, but our highlighting feature only supports Spark and PySpark.) The documentation for this Zeppelin feature is available here.
Starting with this update, the Big Data Tools plugin understands code written inside precode. If you use any precode-declared variables inside the notebook, they will be perfectly highlighted, like any other variable.
To configure the precode value, use the interpreter settings window we described above:
Let’s check if the highlighting feature really works:
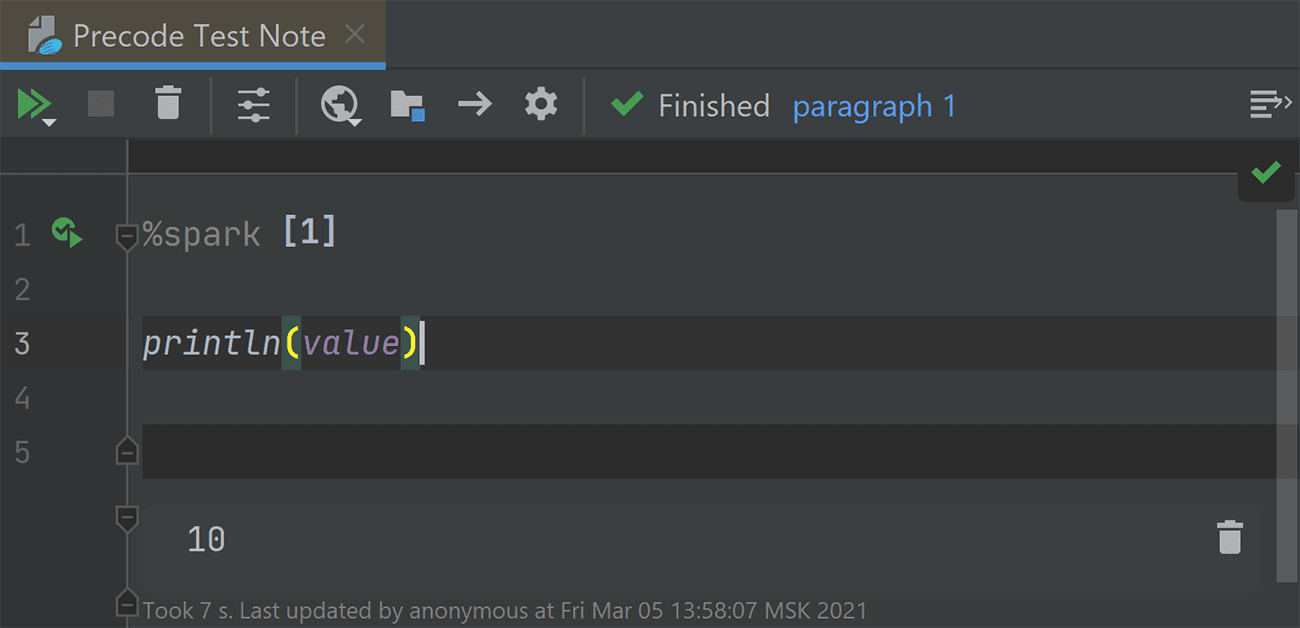
Running scripts before spark-submit
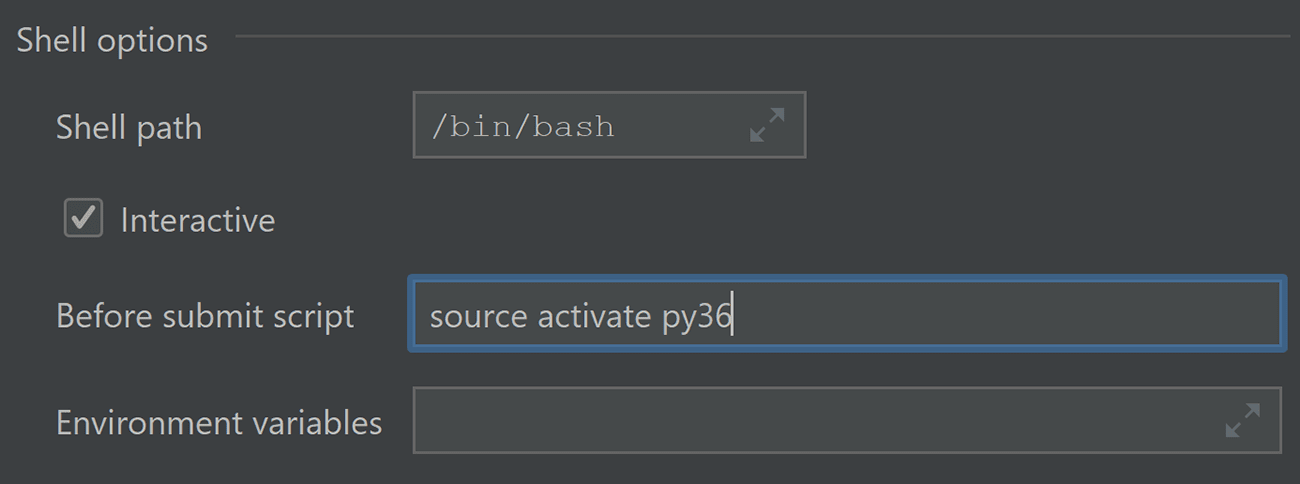
Now there’s an easy way to configure the environment before starting a task for execution. Right in the spark-submit settings, you can specify a string that will be executed by bash.
If you want to configure a Python environment, now you can run “source activate py36” without providing any additional scripts. You can also run echo “Hello World” or any other console command.
Improved Python support
We’ve been gradually improving Python support since introducing it last December. Here’s a new window that lets you configure Python, if you haven’t already.
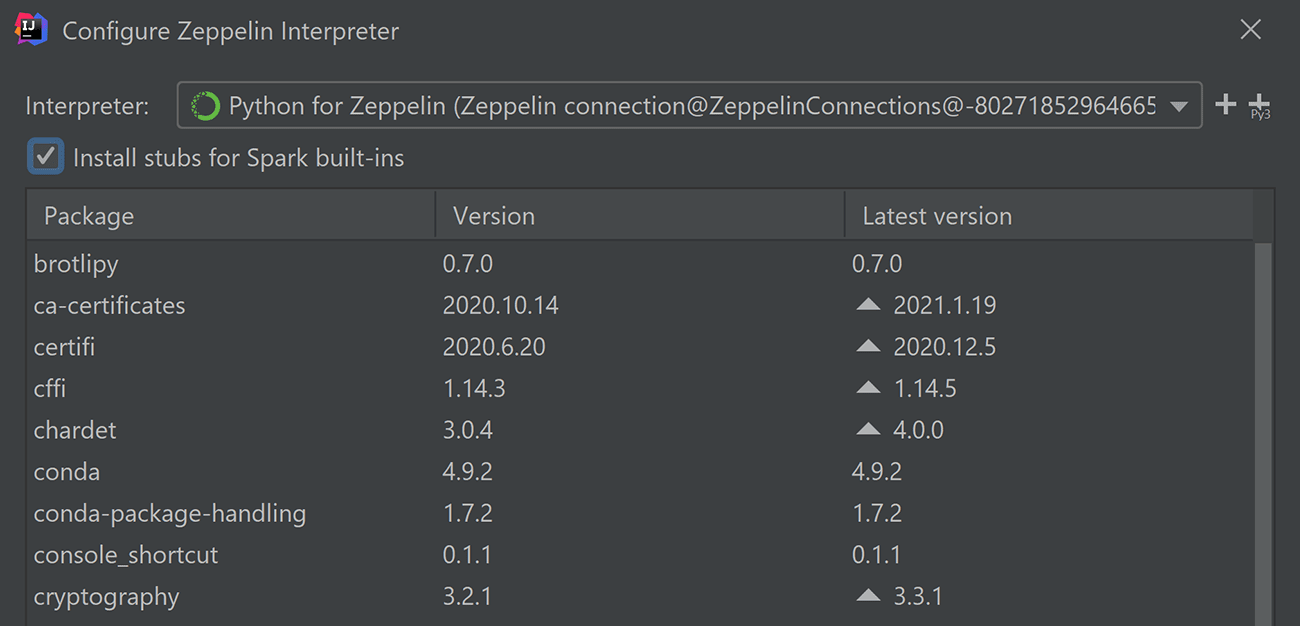
You may want to select the “Install stubs for Spark built-ins” checkbox to greatly improve autocompletion in PySpark.
Improved notebook search
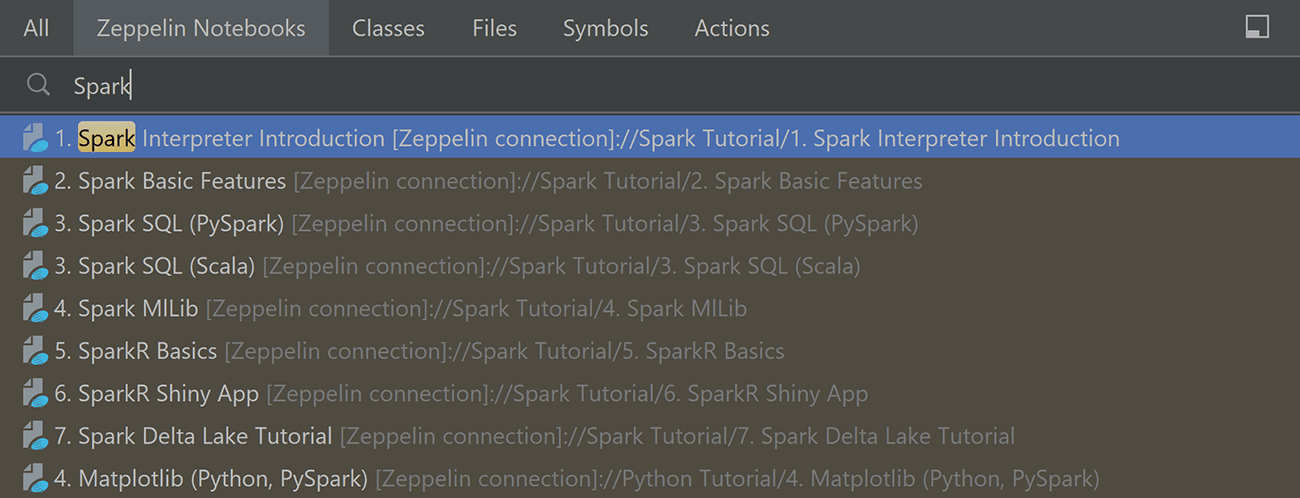
Now you can find notebooks using Search Everywhere, by pressing Shift Shift.
Notebooks are displayed in two ways: along with all the results in the All tab, and separately in the Zeppelin Notebooks tab.
Support menu
Have you ever been in a situation where you wanted to report a bug in the plugin or get in touch with the plugin developers, but you weren’t sure how to quickly do that? Well, now there is an easy way. Simply click the Support dropdown menu in the upper right-hand corner of the Big Data Tools tool window and choose one of three ways to contact us. We’ll be happy to hear from you!
Bug fixes and improvements
We’re actively developing and enhancing the Big Data Tools plugin, doing our best to take into account all your feedback and fix as many bugs as possible.
For an overview of the key recent improvements, please visit the What’s New section of the plugin page, or check out the full report on YouTrack with just about all the release notes.
You can upgrade to the latest version either from your browser, from the plugin page, or inside the IDE. On the plugin page, you’re very welcome to leave your feedback and suggestions. We always want to know what you think.
Documentation and social networks
Last but not least, if you’re looking for more info about how to use any feature of the plugin, make sure to check out the IntelliJ IDEA, PyCharm, or DataGrip documentation depending on which IDE you use. Still need help? Please don’t hesitate to leave us a message either here in the comments or on Twitter.
Version 1.0 is a big milestone in the history of the Big Data Tools plugin. Hopefully, all of these improvements will be useful for you, allowing you to do more exciting things and in a more enjoyable way. Thank you for using the Big Data Tools plugin!
The Big Data Tools plugin team




