

DataGrip 2016.2 is Out!

Hello, everybody! We are excited to release DataGrip 2016.2 and this version brings many interesting features. As usual, we thank all our early adopters who helped us make the IDE better during this release cycle.

What is in DataGrip 2016.2? tl;dr: UI for importing CSV files, JSON and XML support in literals, regular expressions checking, dynamic SQL support, completion in tables, keyboard layout aware completion, recompile packages in Oracle, search path support for PostgreSQL and much more. Let’s look closer.
Database view
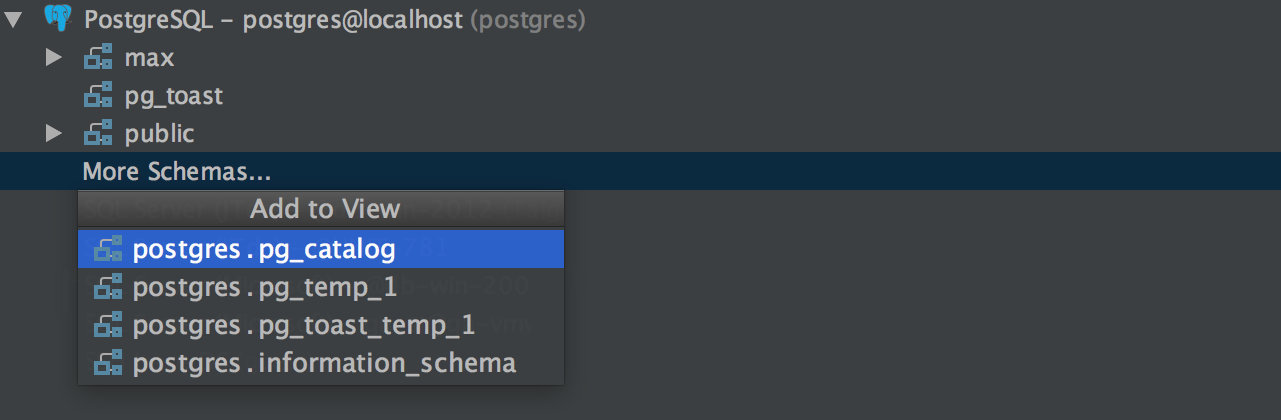
Some changes happened to the instrospector. We’ve replaced the way schemas are selected from the tab in Properties, so now you will find all schemas of the server by clicking “More Schemas…” in the database view. Choose the schemas you want to see here and hide any you don’t need from the context menu. Now you need to refresh your data source if you’ve updated from the previous version. Remember, that only schemas added to the database tree are available in code completion.
Import CSV
Many of you told us that the way of importing CSV files (with the help of Edit As Table) was not very convenient. You asked, we delivered! Enjoy a dedicated UI for importing CSV, TSV (well, DSV) files to the database.
Click the schema you wish to import data to, and choose Import From File… from the context menu. Then choose the CSV file where your data is.
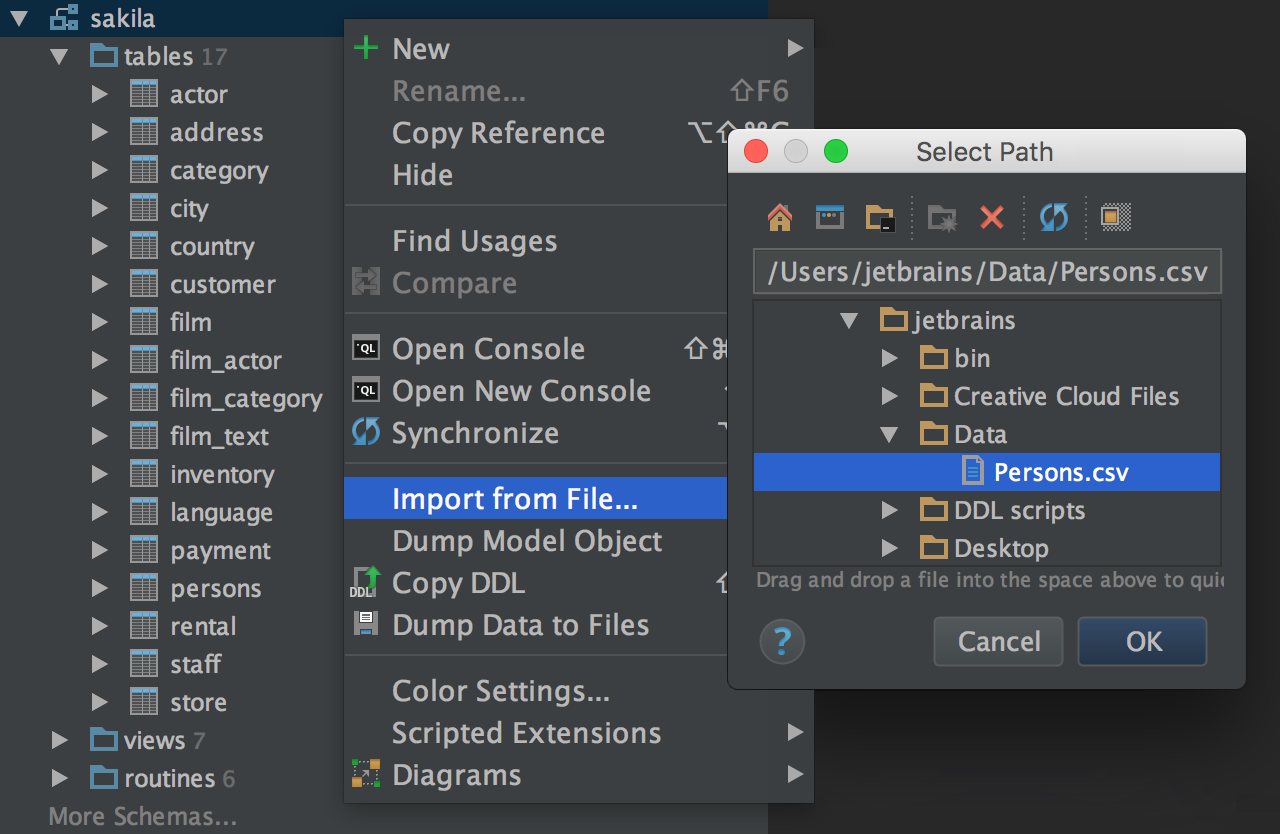
You will see the Import dialog window. The left-hand panel is for format specification: choose the delimiter, whether the first row is a header (the separate format options are available for it), and specify if you have quoted values in the file.

On the right-hand side, you see a frame describing the table to be created and a result data preview. Press Delete to remove a column from the result. If you want to import data to an existing table, just use the context menu of this particular table to choose Import From File…
What happens if there are errors in the file? Write error records to file option is available. The import process will not be interrupted, but all the wrong lines will be recorded to this file.
Language Injections
This feature lets you treat string literals as live code written in other languages (like XML, JSON, any SQL dialect or regular expressions), including formatting, highlighting, usage search, completion, and even refactoring.
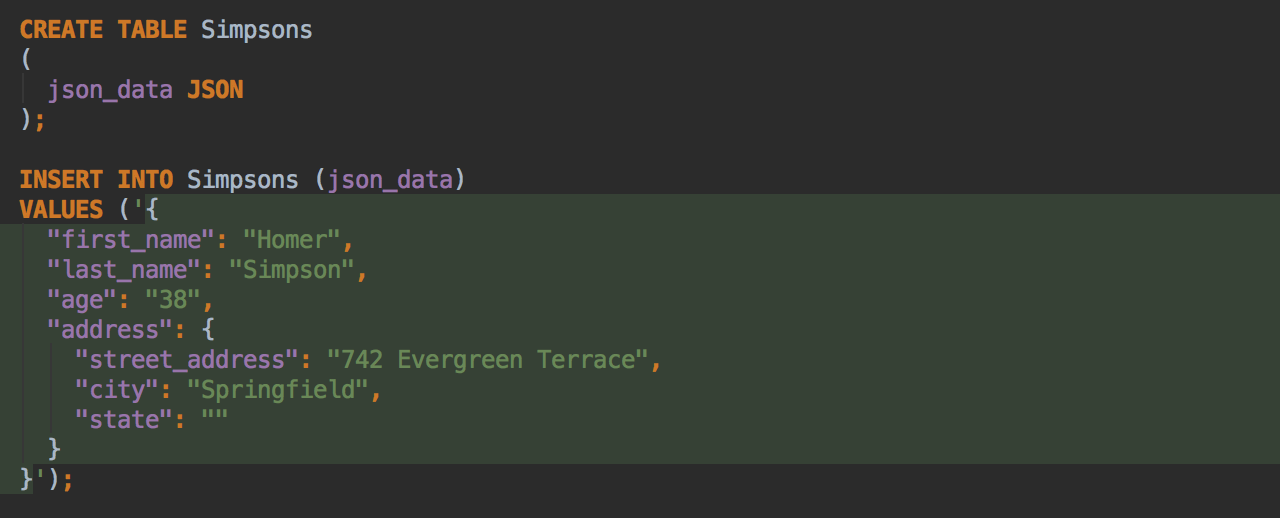
Language is auto-injected into a literal when DataGrip understands the type of the string inside. For example, if you are working with values from JSON columns, they will be treated as such.
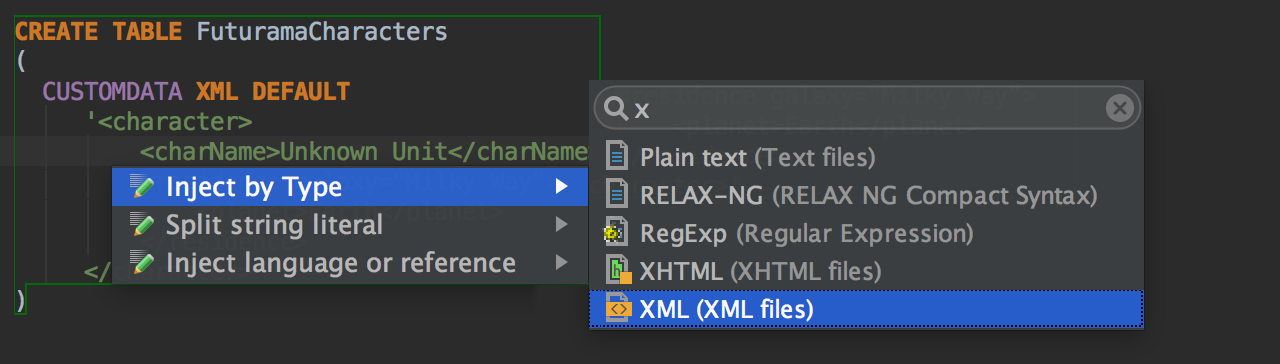
Language can also be injected when you’re specifying a column default value. In the following case it’s XML, which makes all the XML-related features available there: rename elements by Ctrl(Cmd)+F6, find usages by Alt+F7, and enjoy completion for attribute names. For more information about XML support you can have, read this IntelliJ IDEA help page. DataGrip and IntelliJ IDEA share a common platform, everything described there will work in DataGrip just as well.

By default, there are only two predefined injection types: JSON and XML. However, it’s really simple to create your own injections: just press Alt+Enter and then select Inject By Type. There are many languages you can inject. Notice that quick search is available here.
You will be offered to create a custom type pattern that simplifies the use of injections; for instance, you can configure it to inject XML into any type ending with DATA. You can use regular expressions to define the injection patterns. There’s RegExp assistance, too: Alt+Enter invokes the Check RegExp feature.
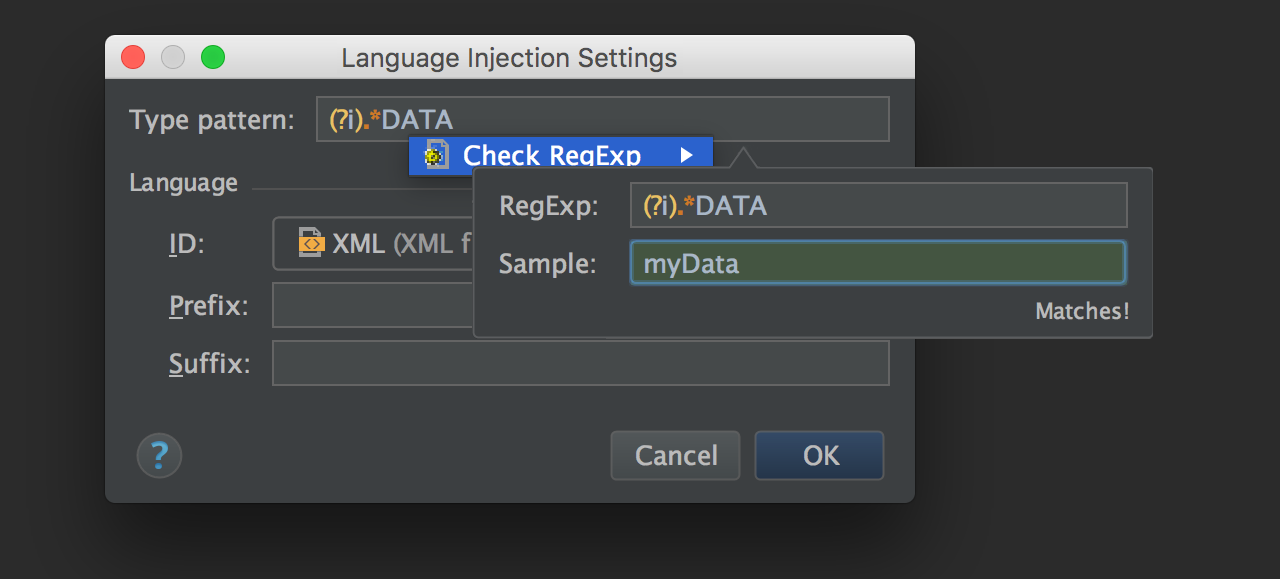
Your pattern will be added to the list in Settings/Preferences → Editor → Language Injections.
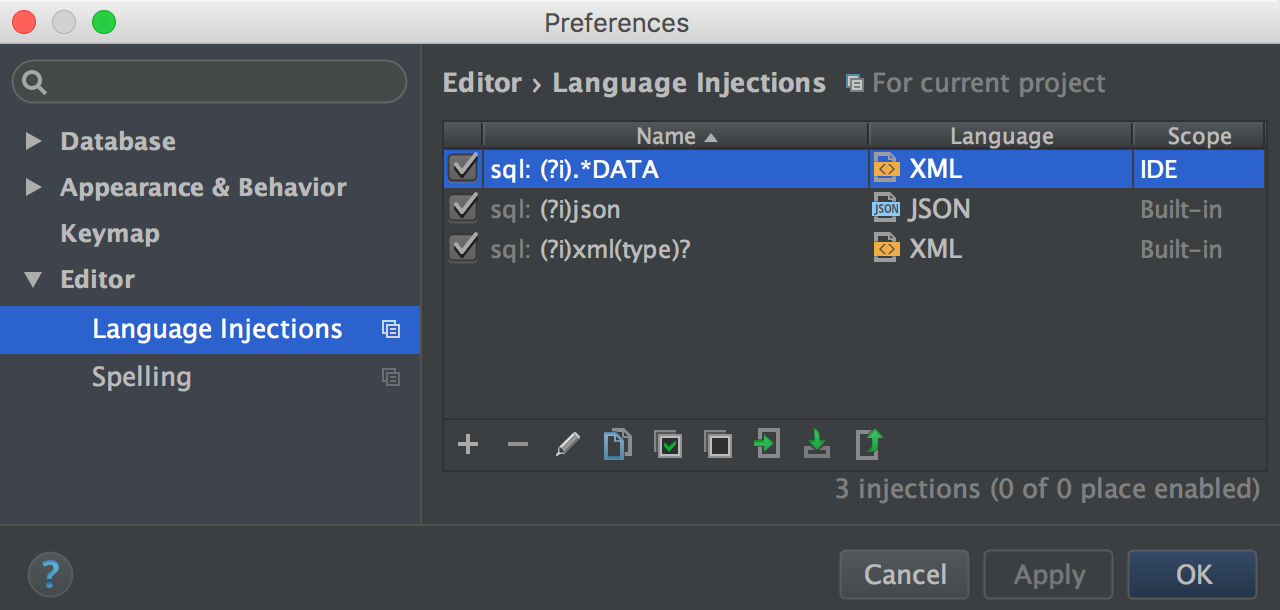
Since it’s possible to inject languages into any string in the SQL code, we can use Check RegExp if we’re inserting, for example, a value for the Visa card pattern.

Did you see this the ‘was temporarily injected’ tooltip? If you want to have the injection whenever you edit a particular piece of code, comment it with “language=” like on the following screenshot. In it is another important example — the use of DynamicSQL that provides coding assistance for the injected fragment.
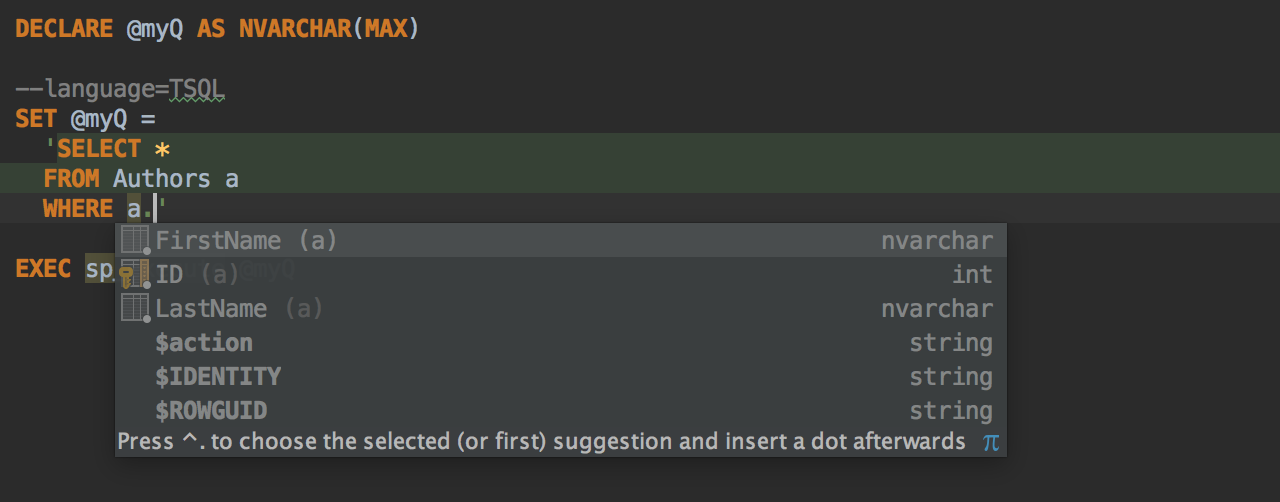
Table Editor
Completion for values in table is available via Ctrl+Space. It looks through all the values in the column and offers you a list of possible matches. Remember, that if you need completion by used words in the editor (all open consoles), use Alt+/.
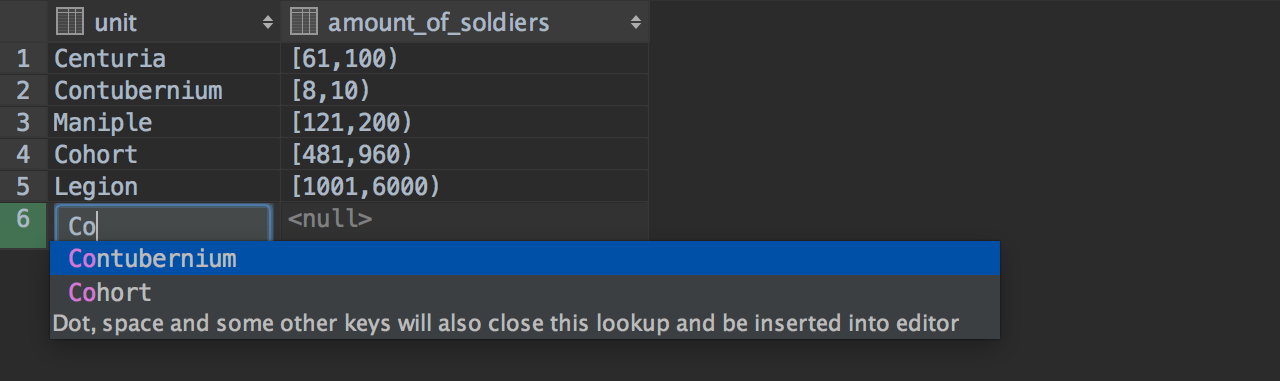
Some improvements have been made in PostgreSQL: now you can modify different range types.
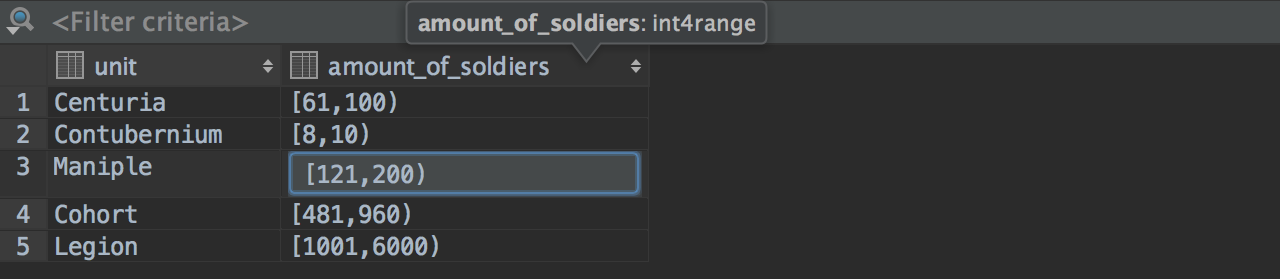

We’ve added actions for resizing columns: use Ctrl(Cmd)+Shift+Left/Right You can resize several columns at the same time. Ctrl(Cmd)+Shift+Up stands for the default size. Notice, that selection of the whole row was invoked by Shift+Space, like in Excel.
Query Console
Just like any other IntelliJ-Platform-based IDE, DataGrip editor now officially supports fonts with programming ligatures. To enable ligatures, go to the Settings → Editor → Colors & Fonts → Font, specify a font that supports ligatures, e.g. FiraCode, Hasklig, Monoid or PragmataPro (the font has to be installed) and select the Enable font ligatures option.
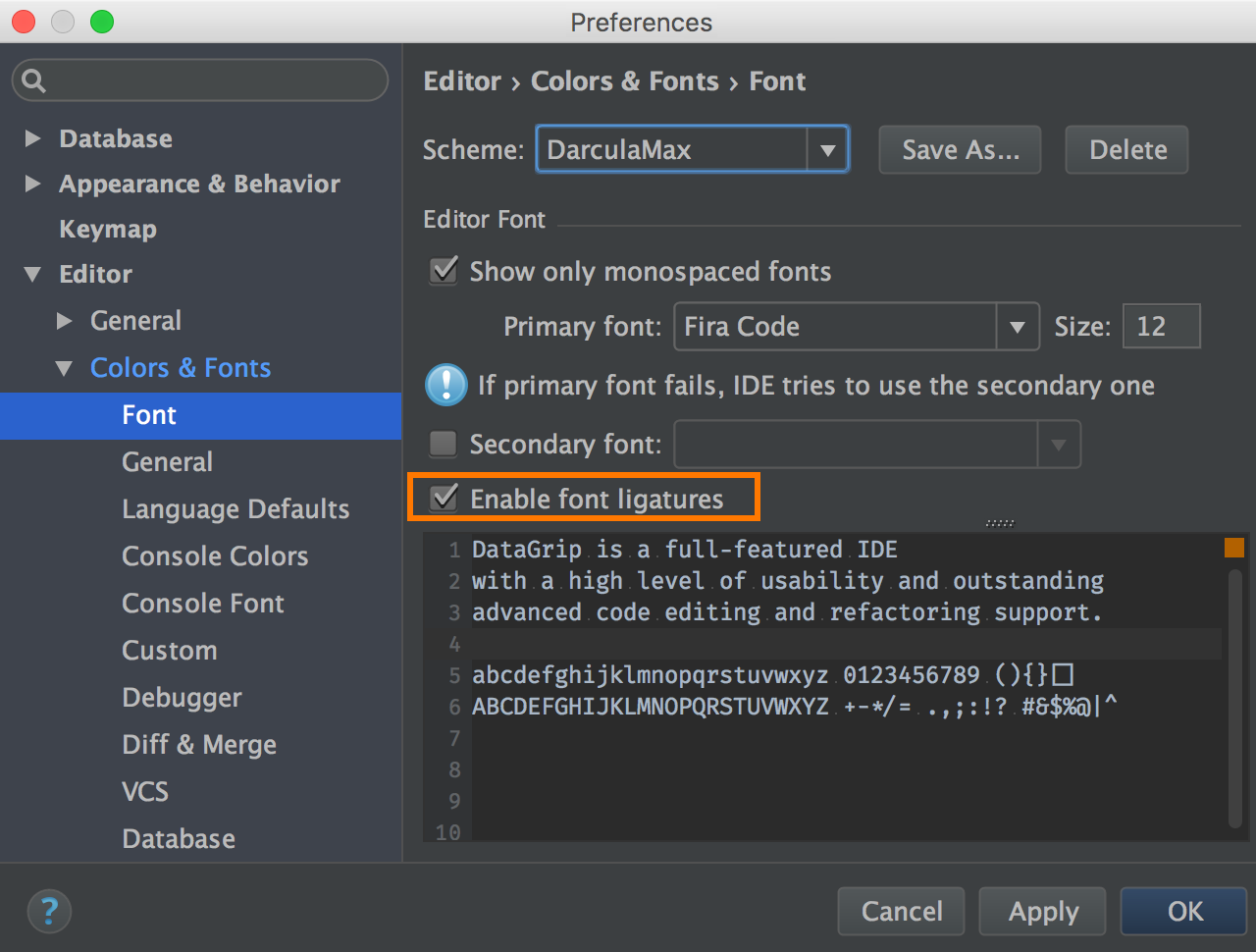
And here you are!

A small enhancement for those who use many languages, IntelliJ-based IDEs including DataGrip now understand what you mean, even if you forgot to switch the language of input.

Surround action doesn’t ruin multi-carets anymore. Also, we’ve added surround with function which means that the caret will be placed before the brackets, not after: put the name of the function here. Notice, you can just type “bion” to put get_AuthorByIdOrName function.

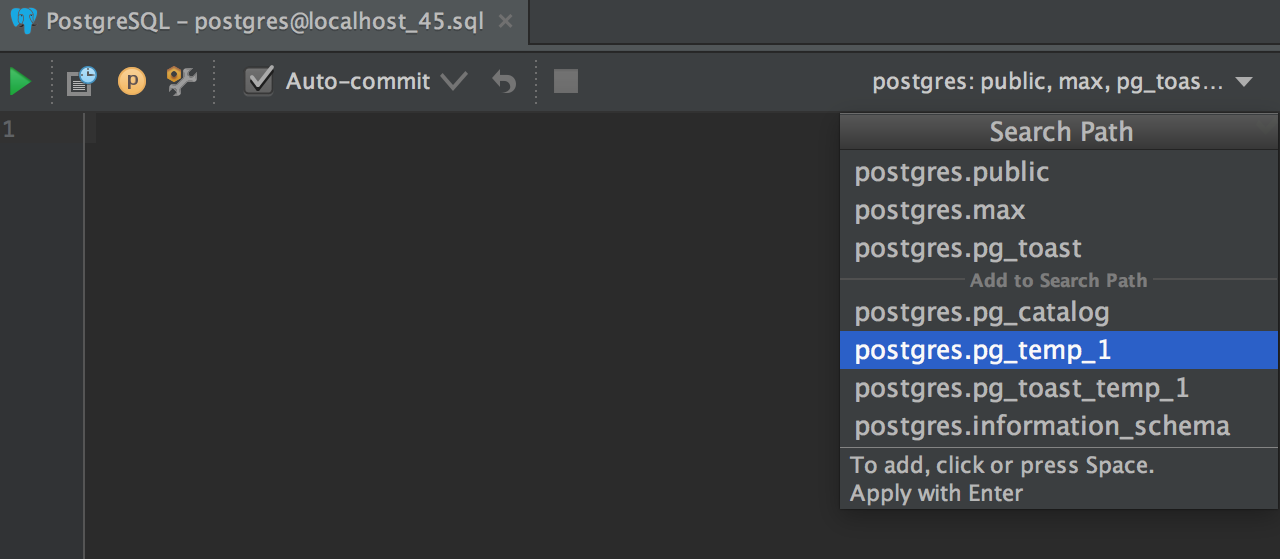
DataGrip now supports search path in PostgreSQL, meaning you can add schemas one by one in the switcher of the console. The console has a list of schemas to look in. If there are two tables with the same name in different schemas, the first one will be used. Thus, the order is important: move schemas in the search path with the mouse or Alt+Arrows.
Connectivity
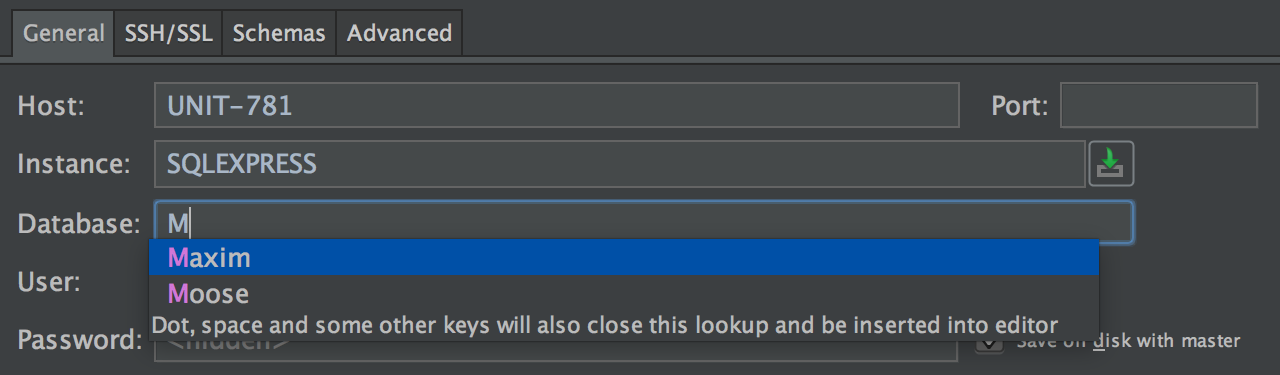
We’ve added completion for database names in the connection dialog. Make sure you’re logged in to the server, and then press Ctrl(Cmd)+Space.
For those who had problems connecting to SQL Server, we published a small tutorial covering the most common issues.
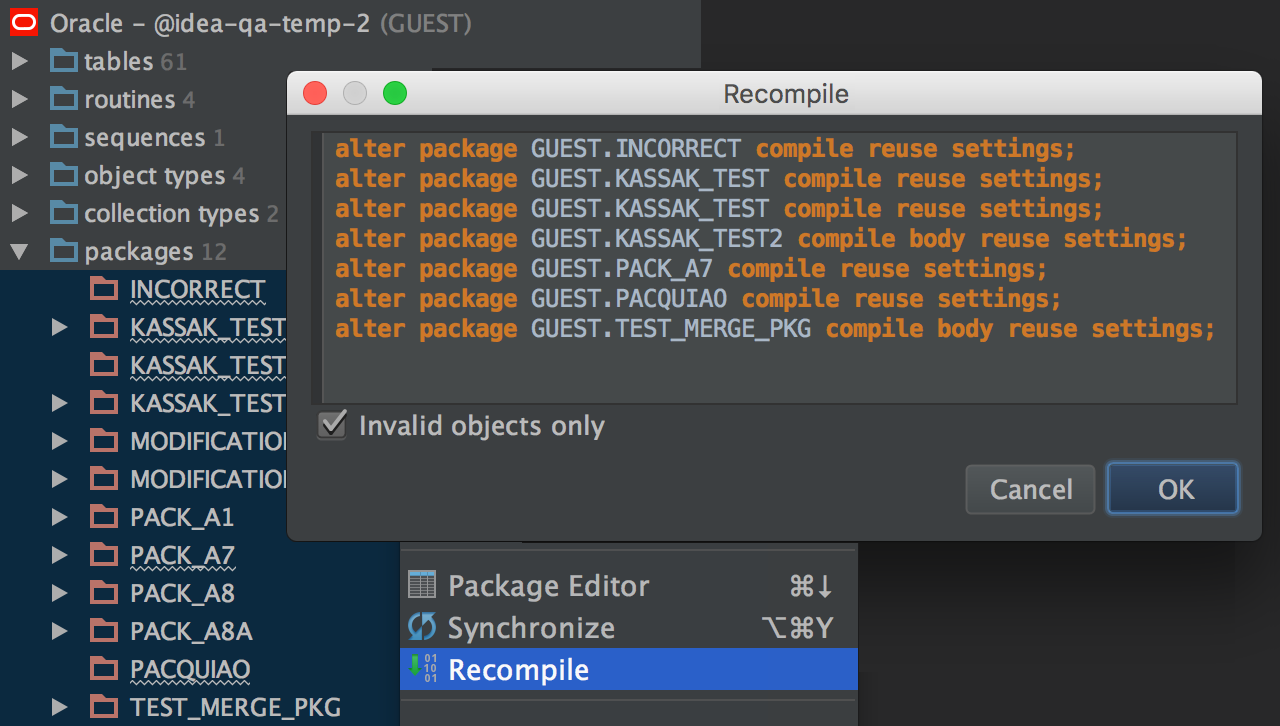
Recompile objects in Oracle
We’ve fixed some bugs in recompiling packages and added a way to recompile any DB object. Well, it has to be recompilable, of course, like procedures, views, types, triggers, etc. There is a possibility to recompile only invalid objects in the group, too.
Dumping Tables
Now you can dump multiple tables and even the entire schema, which means that any data (not only result-sets), can be exported to CSV, JSON or a list of INSERT/UPDATE statements.
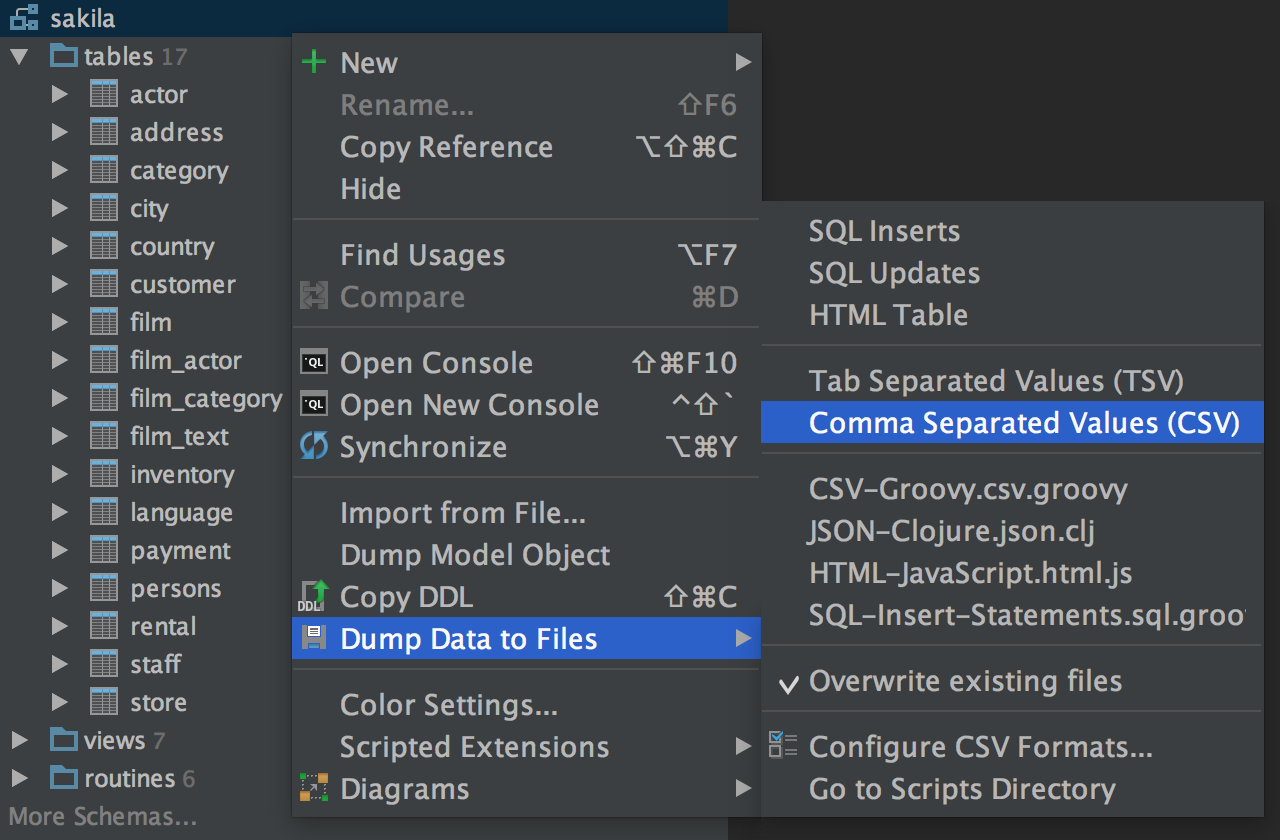
We are working on dumping improvements with using of external tools like mysqldump and pg_dump. If you have thoughts or demands, please tweet at us or create feature requests in our issue tracker.
Background Images
A small new feature will help you make DataGrip look different: set any image as the background of your IDE. Add the folder with the picture to the Files panel, and then choose Set Background Image from the context menu. Or just choose Set Background Image from Find Action by Ctrl(Cmd) + Shift + A.
And that’s not all! A short list of other improvements:
- Copying SSH and SSL settings copies the password as well.
- *.sql files are associated with DataGrip on Windows and also can be opened from the “Open with” context menu.
- Fixed DBE-569: important bug with timed out connection on MySQL.
- The Database tool window now provides the option Auto-scroll from Editor.
- Eras support in Date types for PostgreSQL
- If you use auto-completion, in case of identical names DataGrip will qualify the name of the object automatically.
- Go to source works from the preview in Find in path.
- Inserting the selected keyword in completion by “;” and “,” doesn’t insert a space anymore.
- CTE support has been improved — we parse it even not finished.
- Aggregate functions in ORDER BY are not highlighted as errors.
- The same for PREVIOUS VALUE in DB2.
- Test connection UI has been improved.
Now is the moment to try all this! Get your 30-day trial of DataGrip today if you haven’t before, or just test new features if you use DataGrip. And while you are trying 2016.2 we are already working on 2016.3 expected this fall. Stay in touch!
Your DataGrip Team
JetBrains
The Drive to Develop




