DataGrip 2017.1 Early Access Program Started

Hello! The new year has already brought us a new version of DataGrip, as today we start the Early Access Program for DataGrip 2017.1. Everybody can try this free build and take the new possibilities for a spin:
– Сolumns mapping in CSV
– Drag-n-drop tables
– Smart options for SQL editing
– Code insight
– SQLite introspection
– Miscellaneous
Let’s see what these enhancements are about.
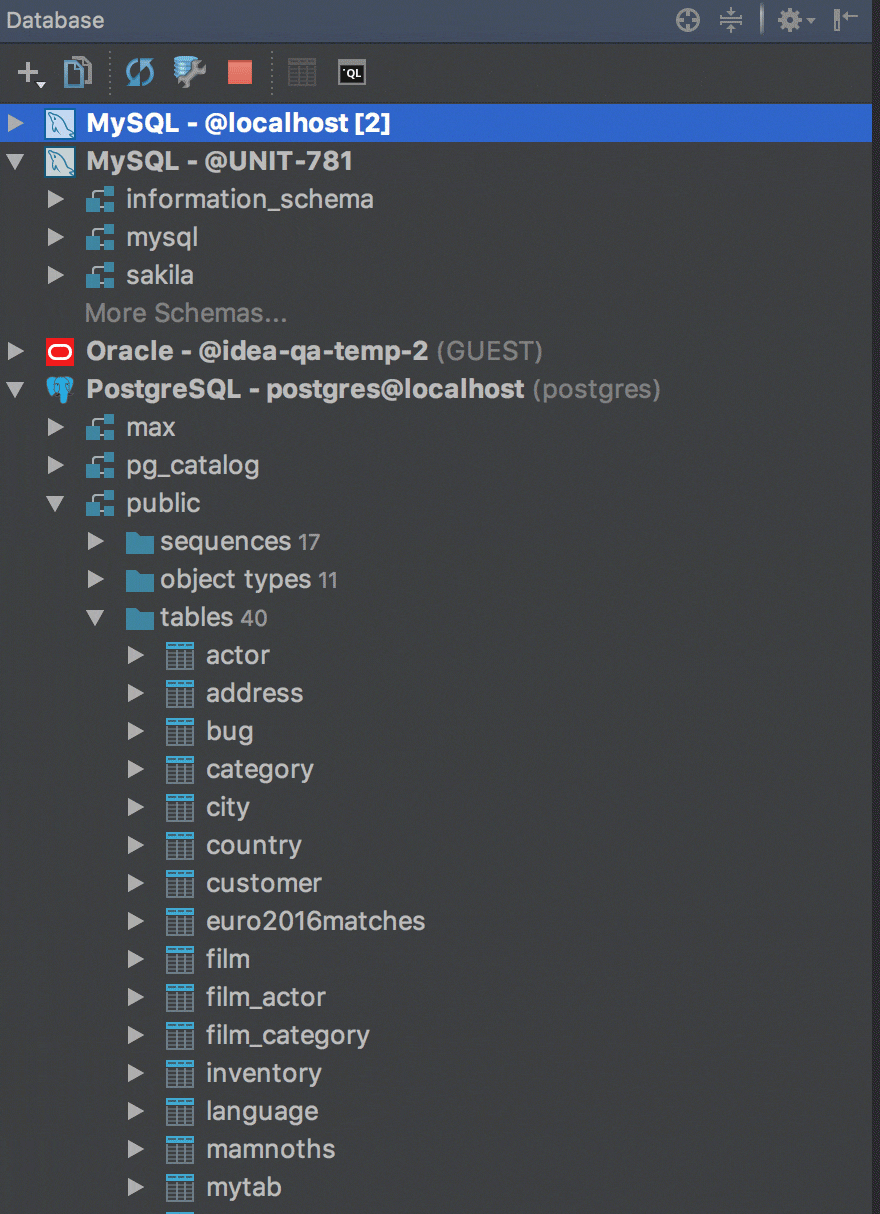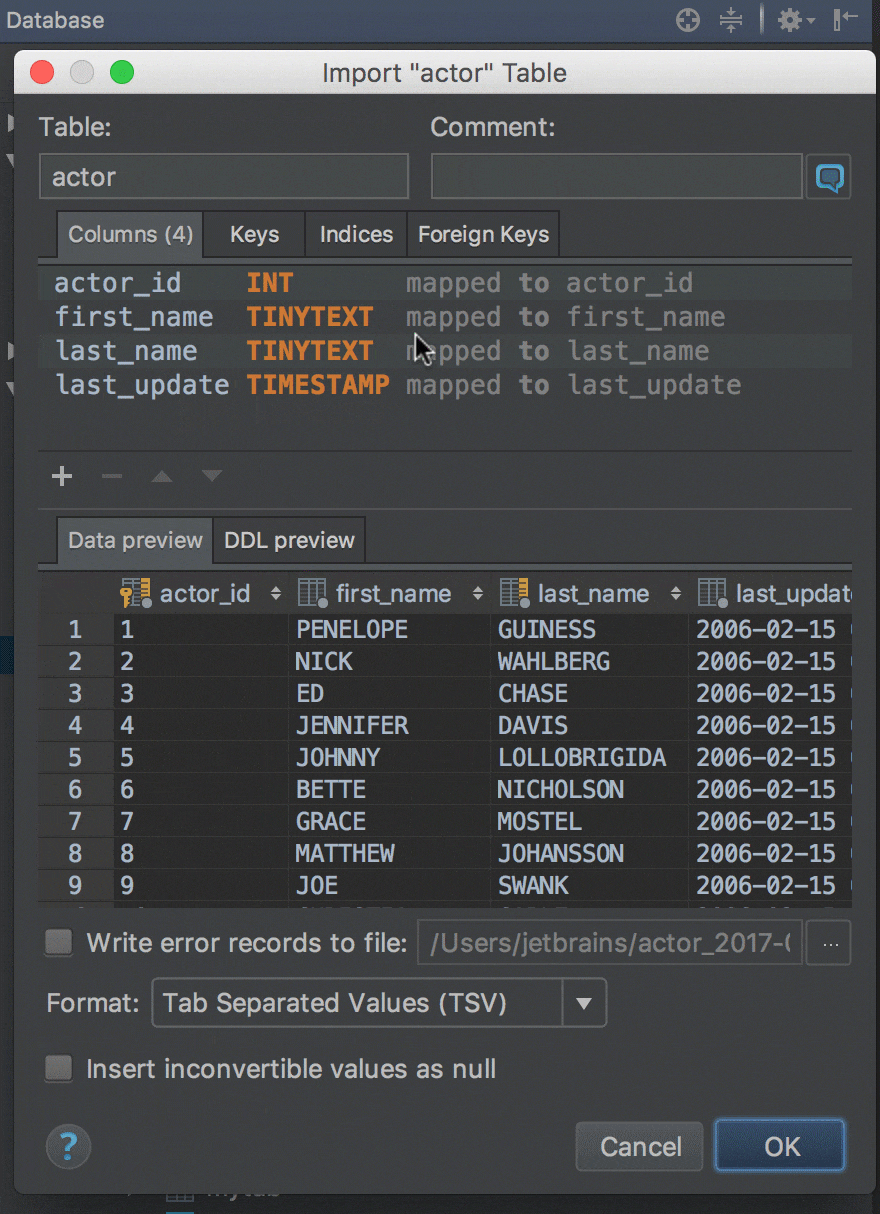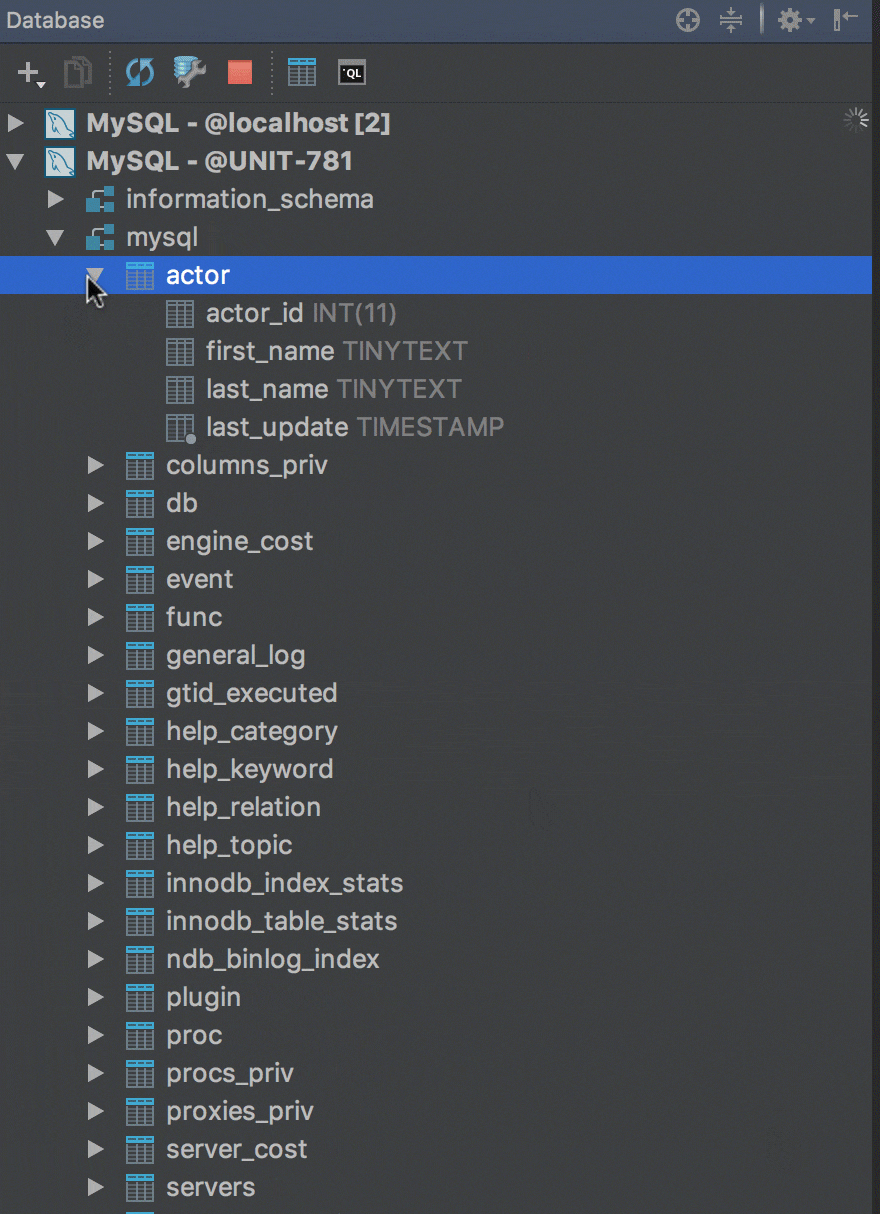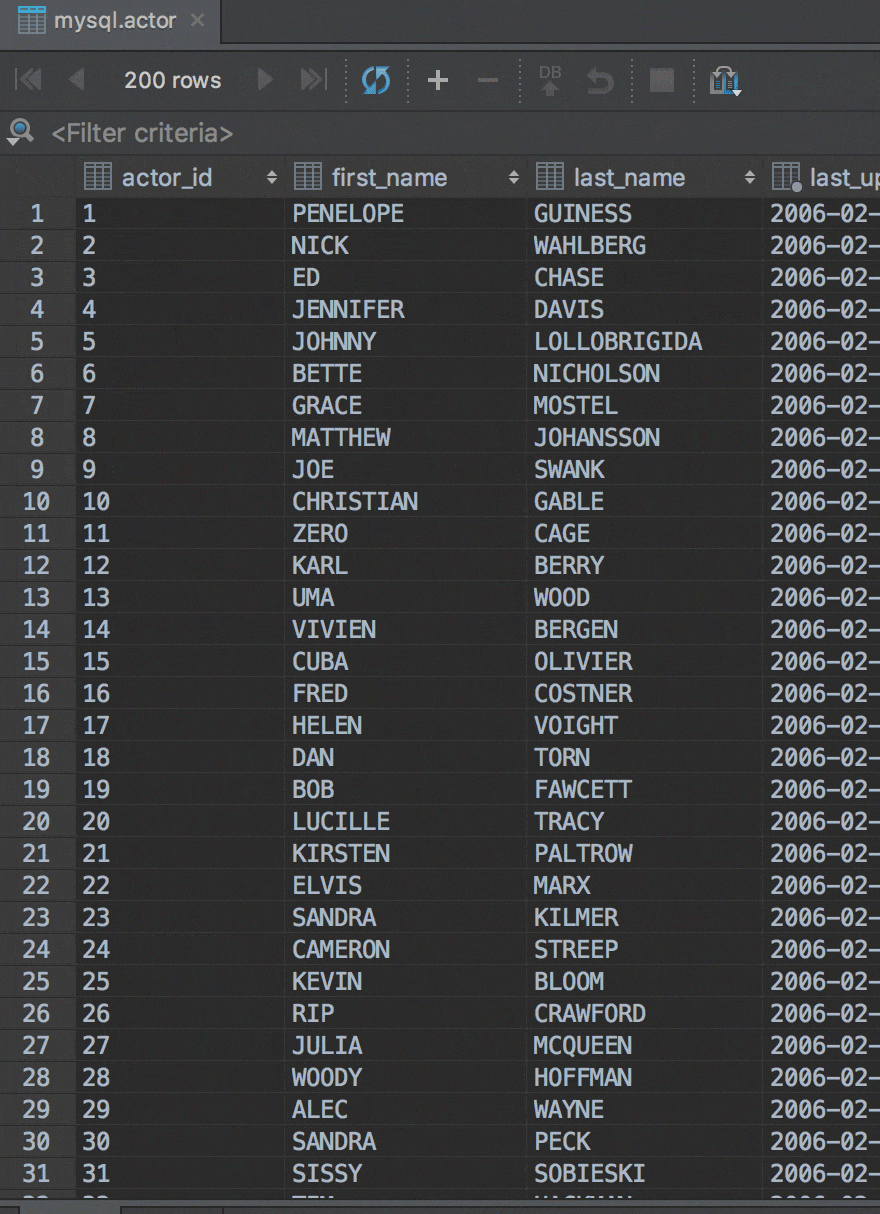
Сolumns mapping in CSV import
Many users have asked us to make the import process more flexible. It frequently happens that the number of columns in a .csv file is not the same as in the target table. Or you just want to import several columns from a file but not all. Now it’s possible to map every column of the file being imported to a table column in your database, which can be either an existing table or a new one created during the import process. Of course, completion works for column names.
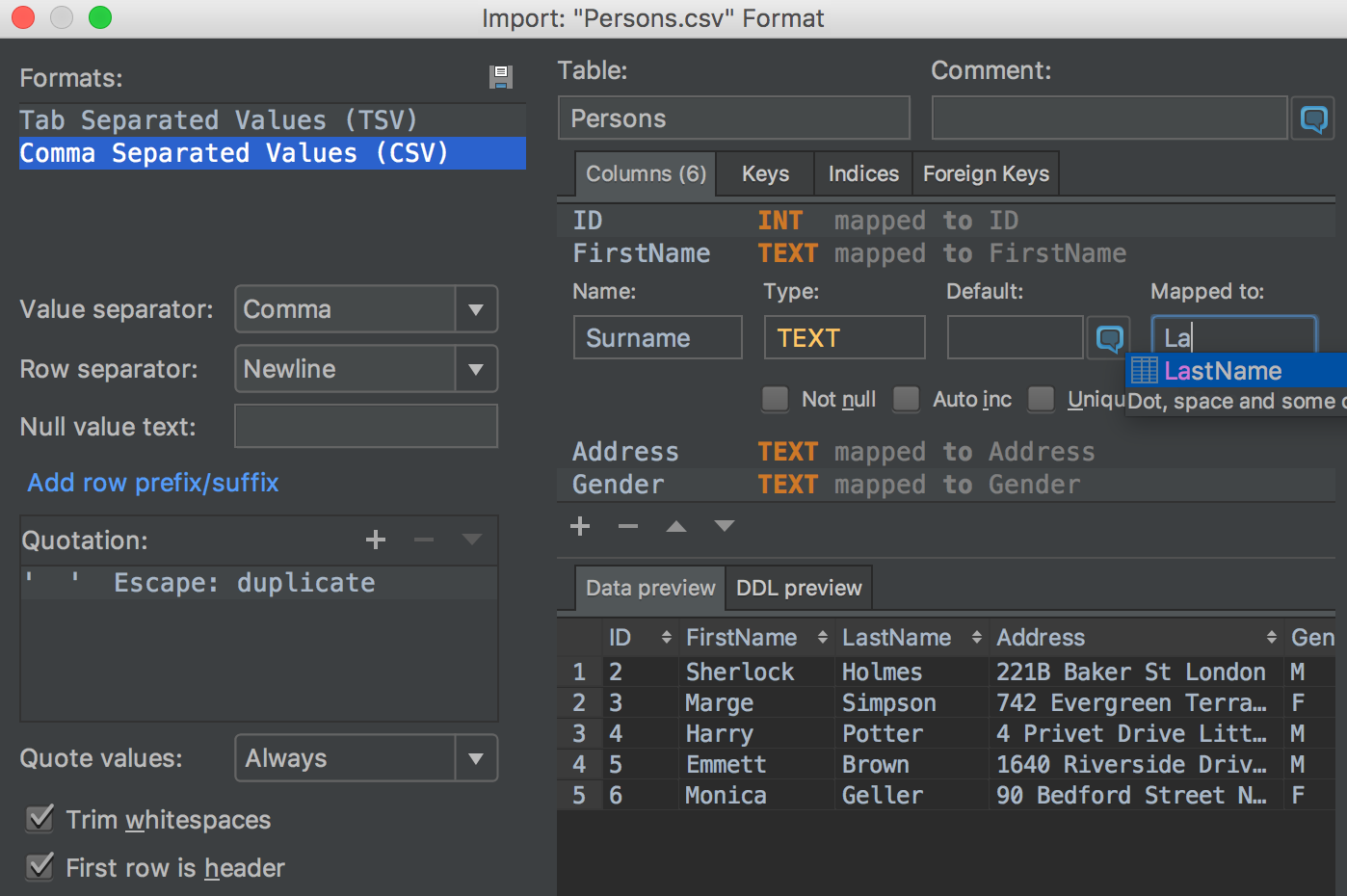
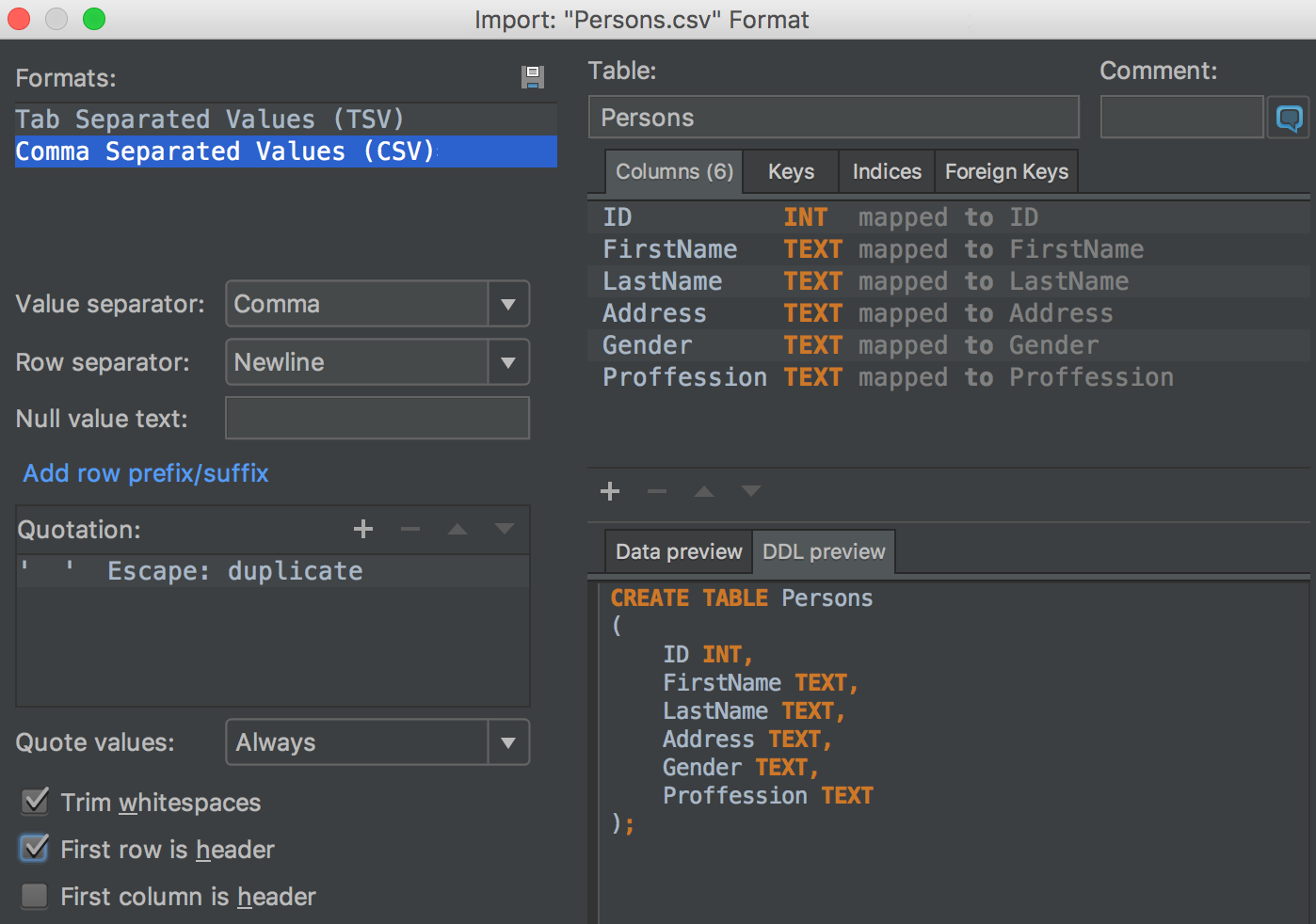
Another new thing in this window is a DDL preview tab, showing you the code to be executed for creating or changing the table.
Drag-n-drop tables
Now there is an easy way to export tables and their data from one database/schema to another. It works even if the tables are in different databases from different vendors. For example, if you need to copy a table from a PostgreSQL database to a MySQL database, just drag-n-drop it. Check if all is OK in the Import table window and go ahead!
Smart options for SQL editing
We’ve added an SQL section to Settings → Editor → Smart Keys.
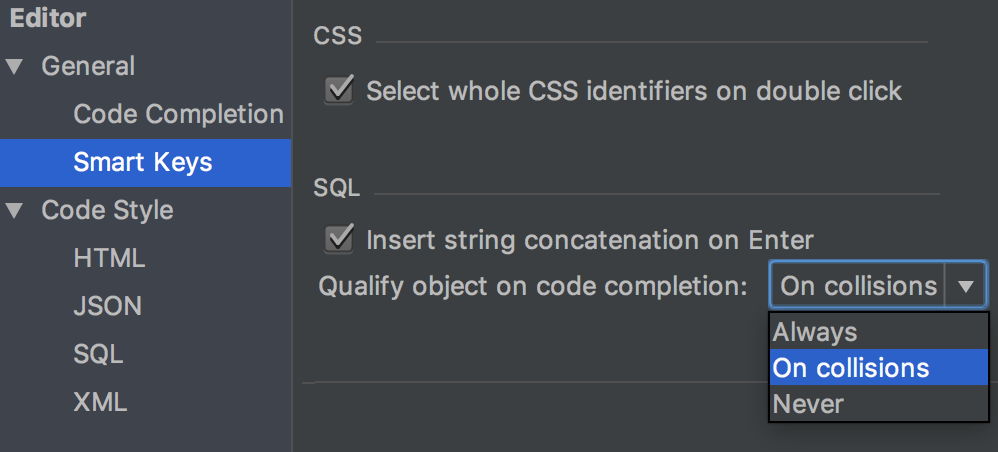
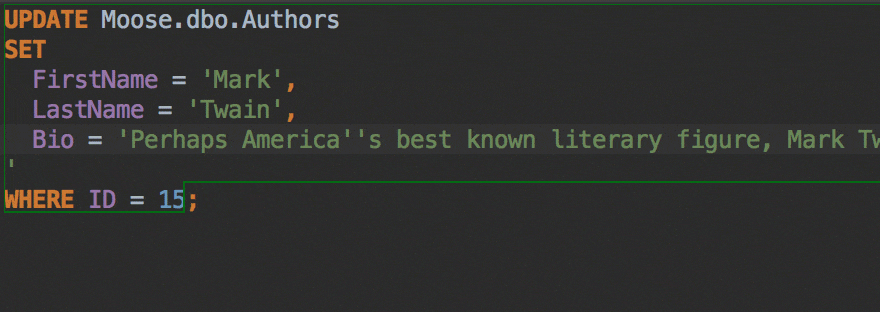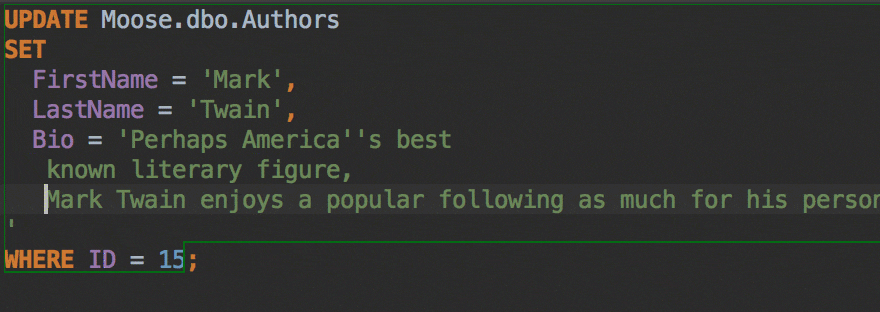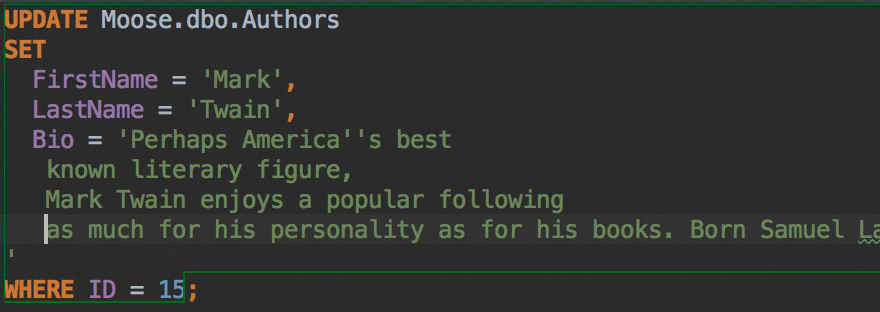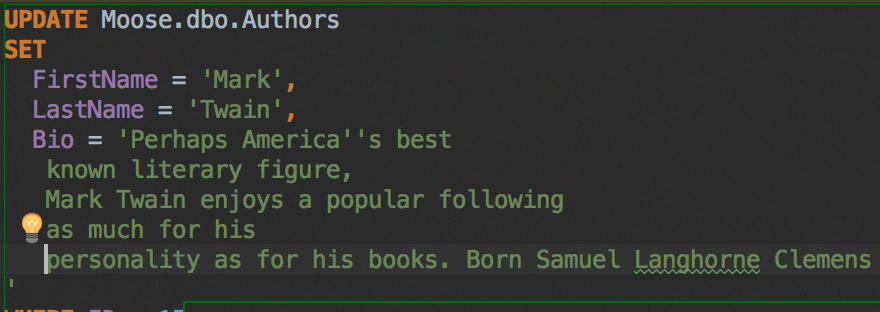
The Insert string concatenation on Enter option lets you choose if you actually need this. It was the default option before, and it works like this:
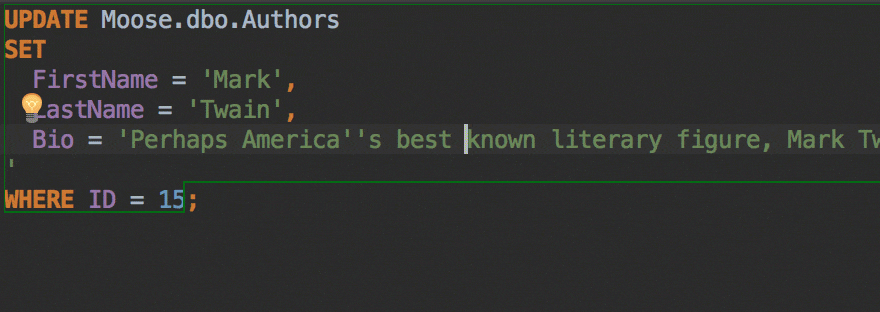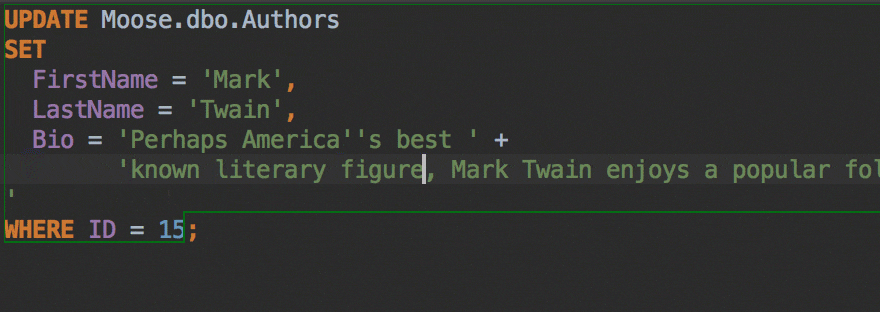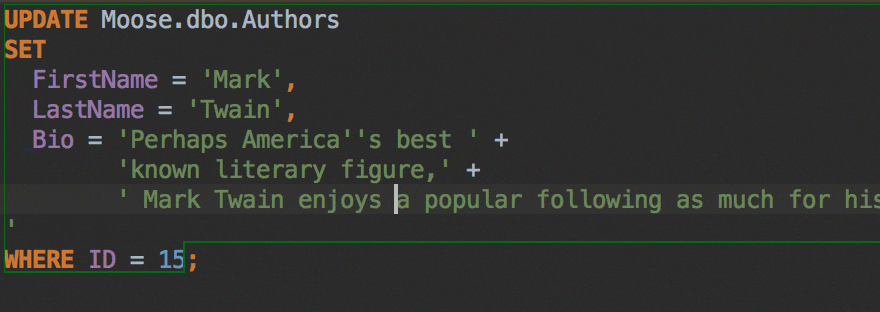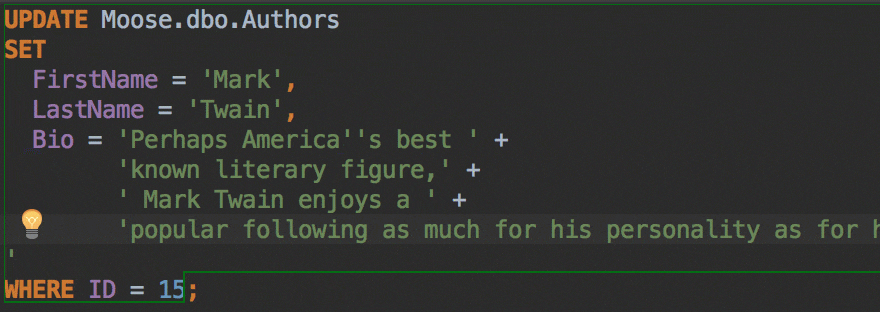
But the majority of database management systems support multiline string literals, so this IDE behavior may be annoying. Uncheck the option if you use multiline literals.
Qualify object in completion is also a thing we’ve been asked to implement. There are three options and here’s how they work. Suppose we have two schemas, max and public:
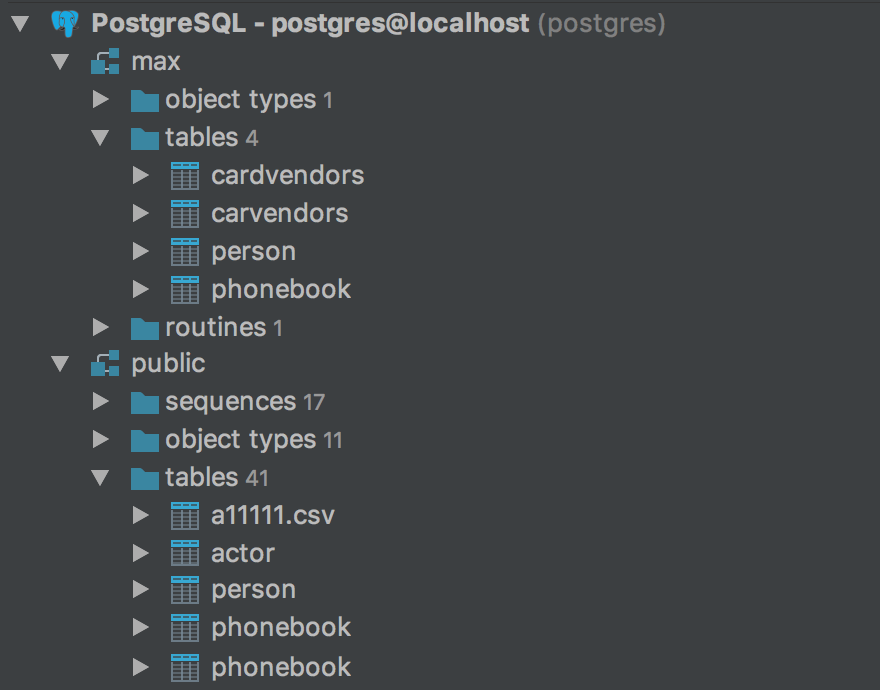
The table persons is present in both schemas and the table cardvendors is only in max. Here are examples corresponding to the different values in Qualify object in completion:
– Always

– On collisions

– Never

Code insight
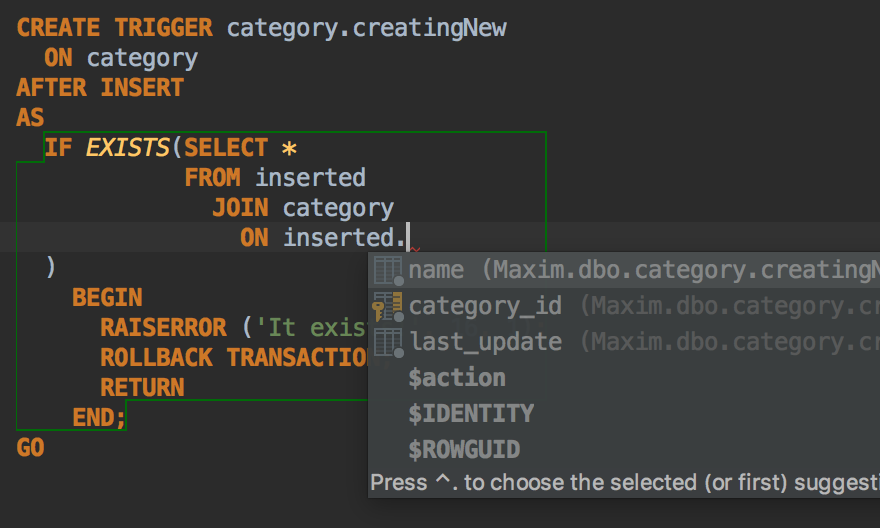
DataGrip now supports NEW/OLD and INSERTED/UPDATED tables when creating or editing triggers. This means you can use completion for these tables’ columns as well.
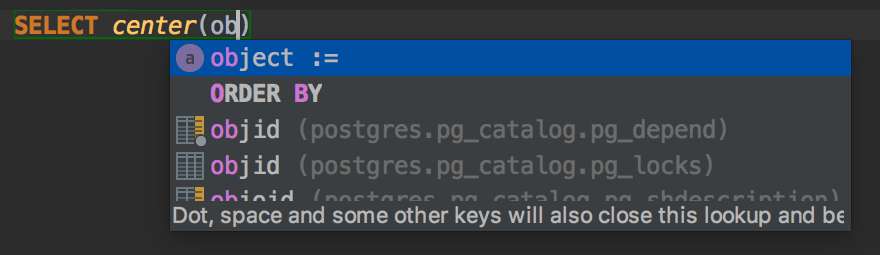
Named parameters of routines can be completed by using second completion (pressing Ctrl+Space twice):
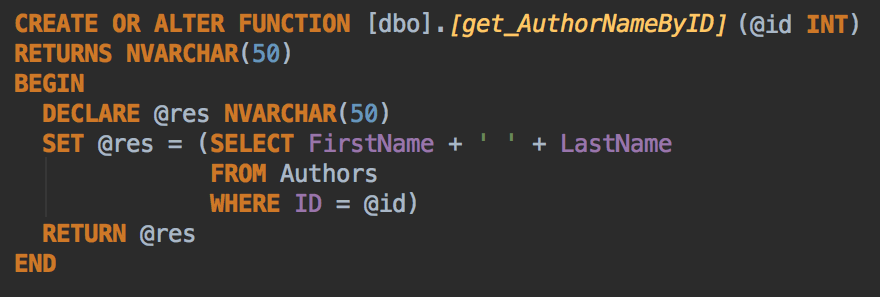
Also, the CREATE OR ALTER construction, which appeared in SQL Server 2016, is now supported as well.
SQLite introspection
In earlier versions we used the introspection provided by JDBC-driver for SQLite. As a result, many objects were absent in the database tree and some source codes were incorrect. Now we show triggers, expression indexes, partial indexes and check constraints.
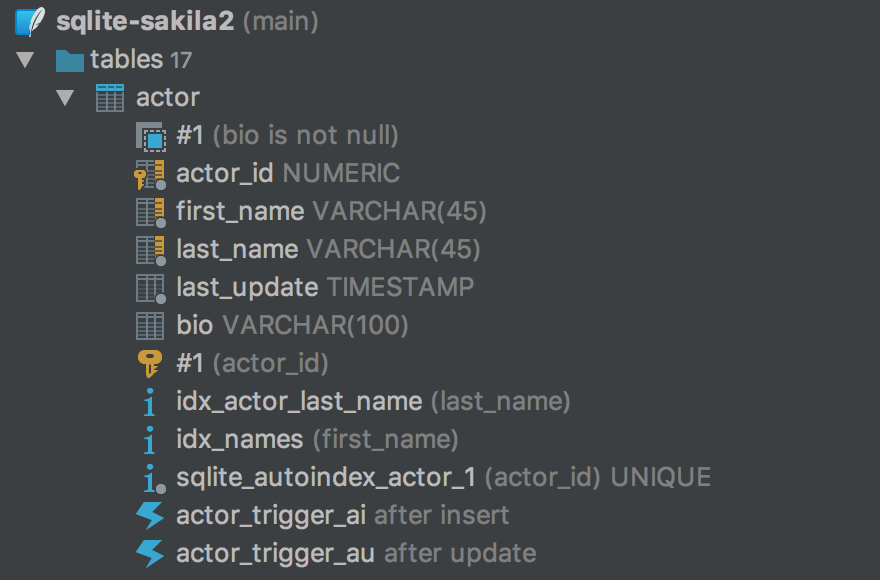
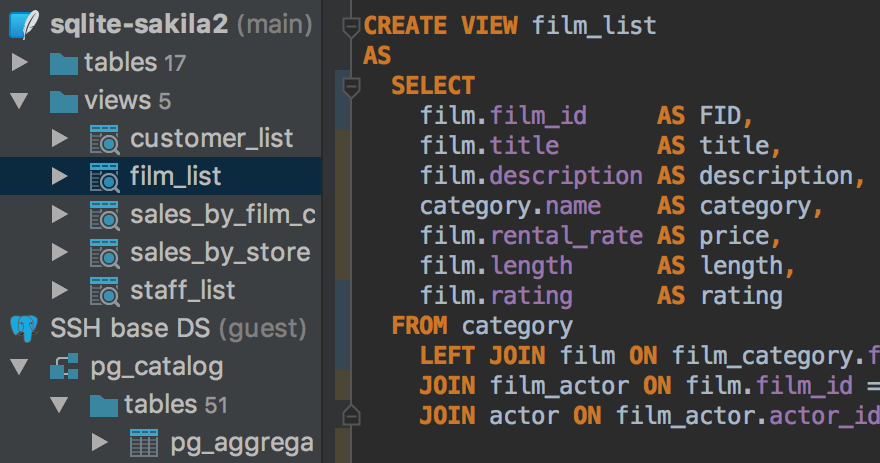
Also, now DataGrip loads the correct source code for views. Before it was ‘CREATE table’ code.
Miscellaneous
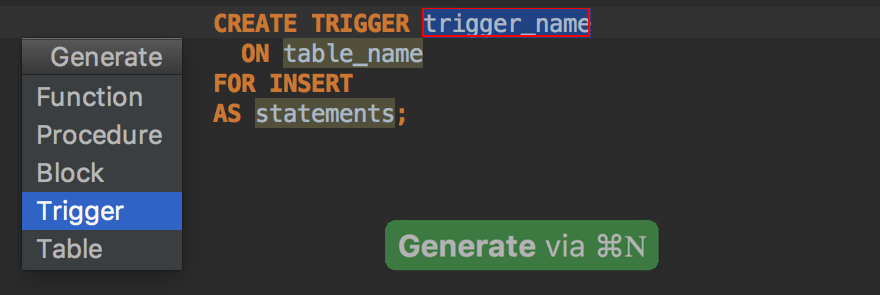
A trigger template has been added to the Generate menu, which is invoked with Ctrl+N (Cmd+O for OSX).
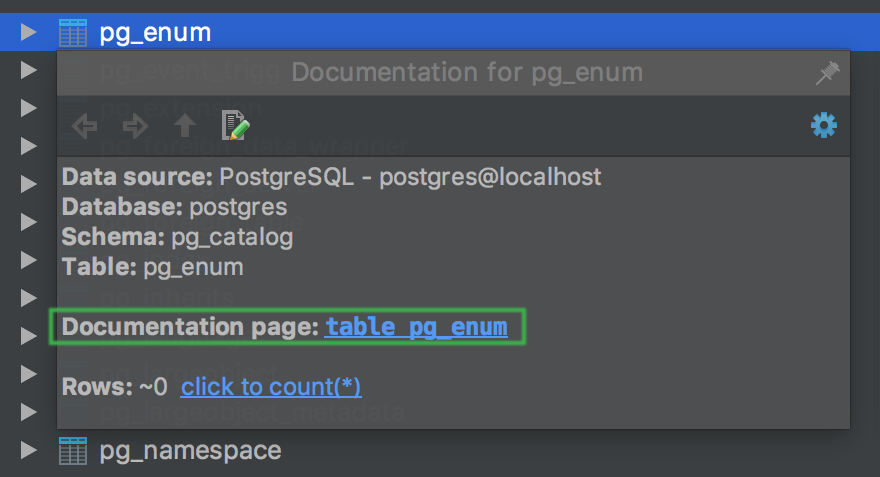
The quick info pop-up (Ctrl+J) for PostgreSQL system tables now contains the link to the documentation page at postgresql.org.
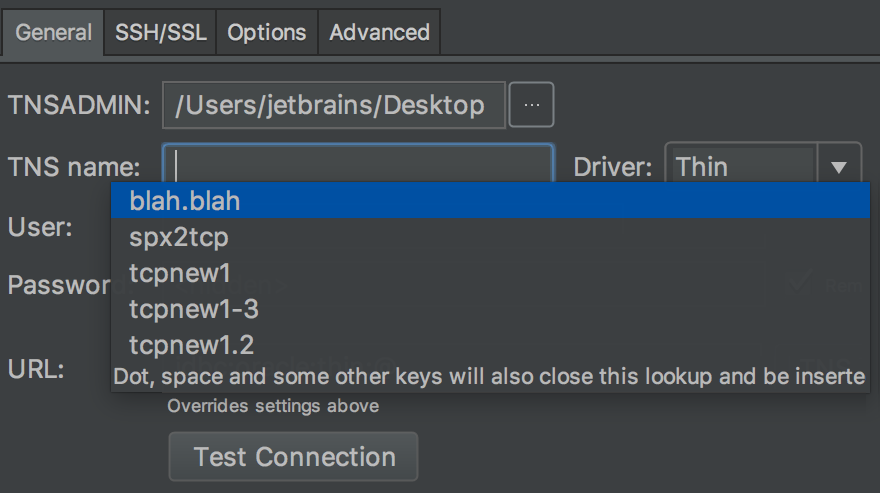
TNS names are correctly parsed from tnsnames.ora file in Oracle. This means that the completion is available in this field of the connection window.
Other enhancements
– Zero-latency typing is now enabled by default
– Icons for synonyms are seen in structure view and completion
– It’s possible to use routine parameters in LIMIT in MySQL
– Customized colors are used for syntax highlighting of regular expressions
That’s all for today. Your feedback is welcome in our twitter, forum, and the issue tracker. Let us know what you think about DataGrip 2017.1!
Your DataGrip Team
_
JetBrains
The Drive to Develop