

DataGrip 2021.2 EAP is Open!

Hello! We’re starting our EAP program for DataGrip 2021.2. We would really appreciate you trying out these new features and sharing your feedback with us – it helps us make the release better! Let’s go!
DDL data source
Generation from a real data source
It is now possible to generate a DDL data source based on a real one. The DDL files will be created on the disk and the new data source will be based on them. That way you’ll always be able to regenerate these files and refresh the DDL data source.
Let’s take a look at how it works.
The new menu item Dump to DDL data source is added to the SQL Scripts context menu.
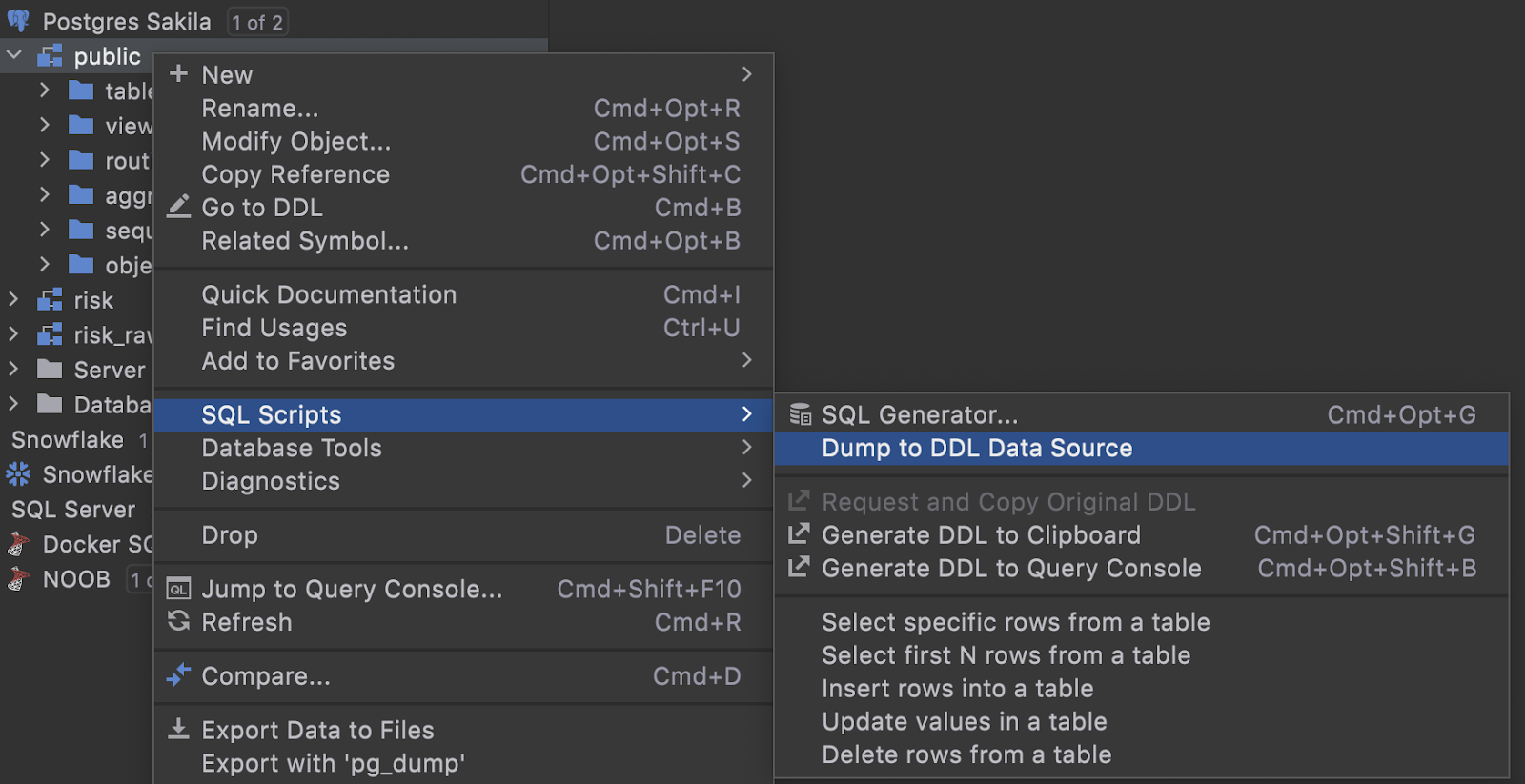
In the open dialog, you need to specify the folder where the newly created files will be stored.
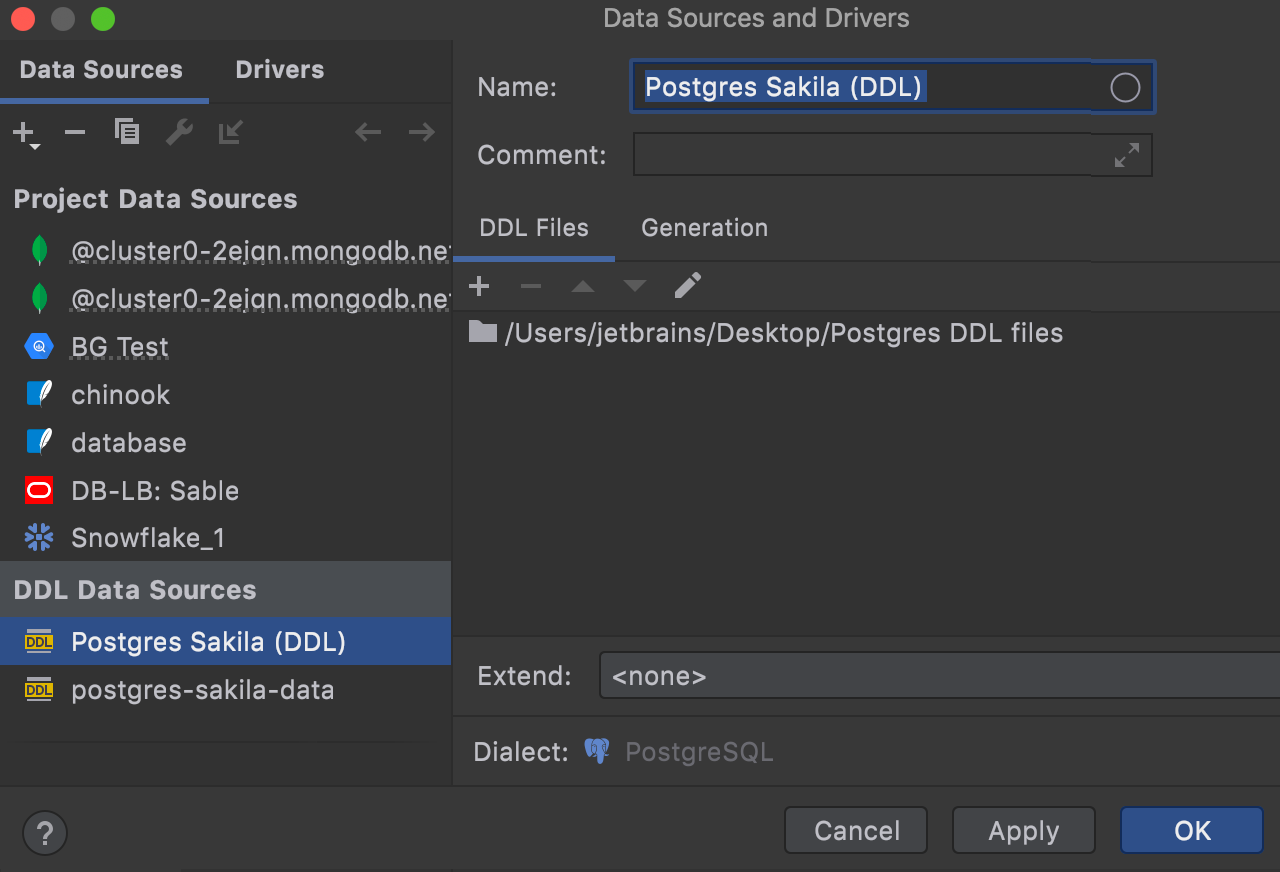
In the Generation tab, specify the options on how these DDL files should be generated.
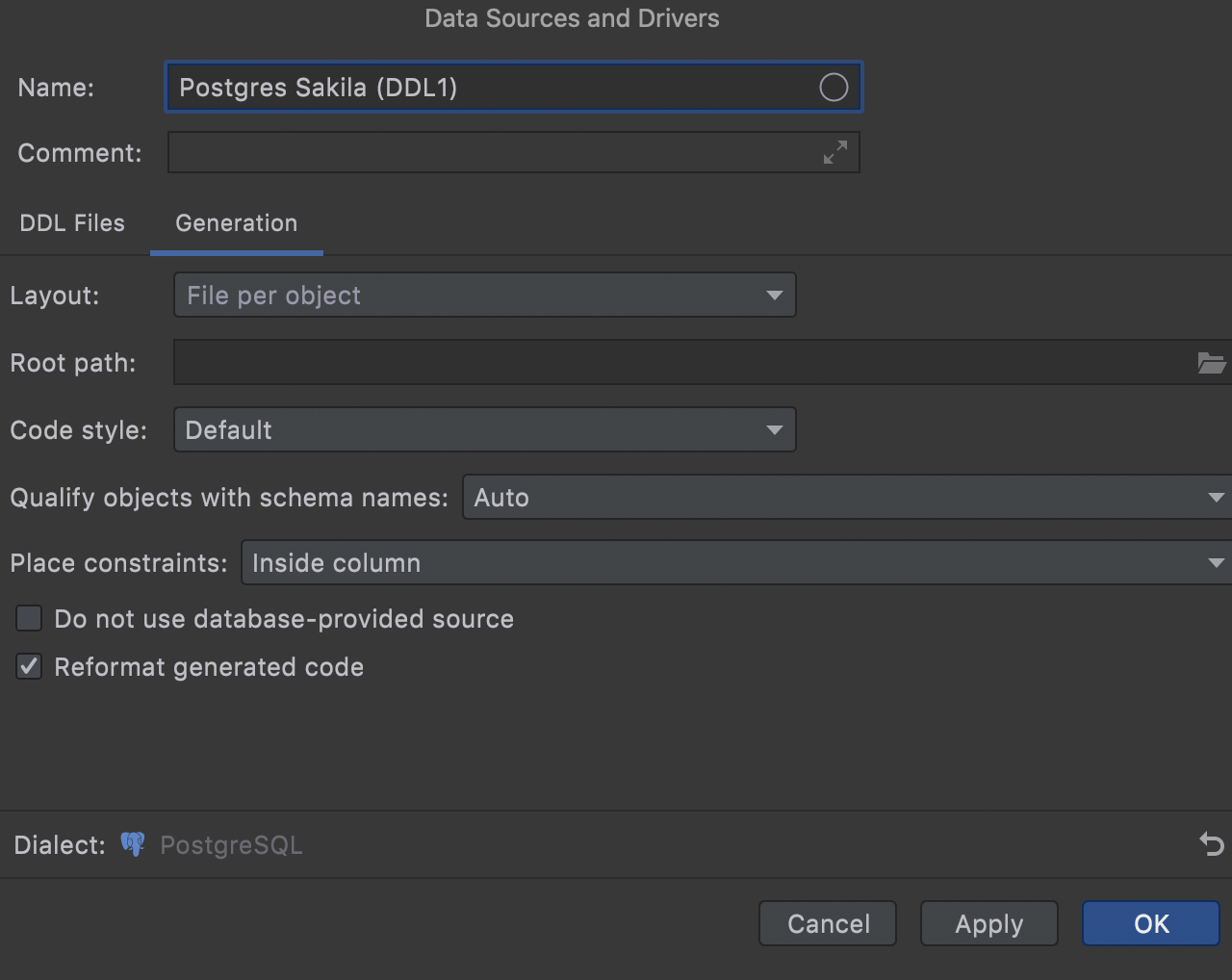
After clicking OK the DDL data source is created.
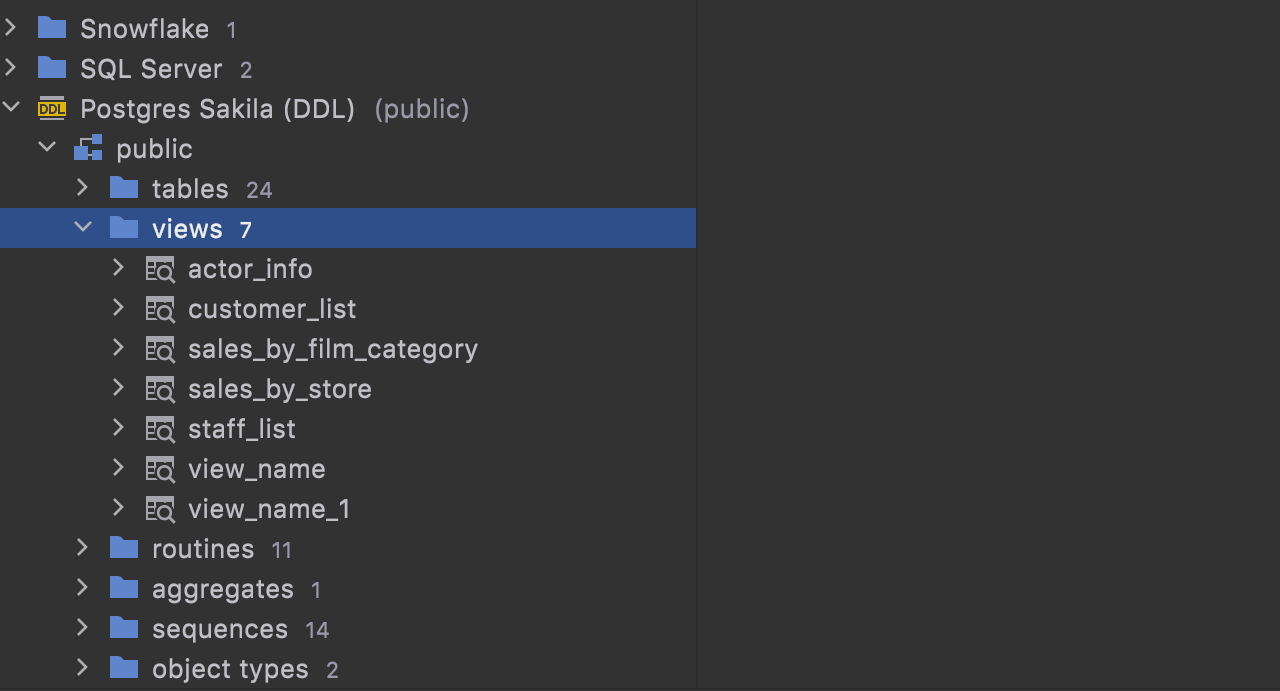
And the folder with the new files is automatically attached to your project.
DDL data source generation is another step in our long-term development of seamless database versioning. With this feature, you can keep your DDL files under a VCS system and regenerate them every time your database structure is updated.
Creating objects
Starting in this version, you can create objects in a DDL data source via the UI. The corresponding files will be created on the disk.
Diagrams
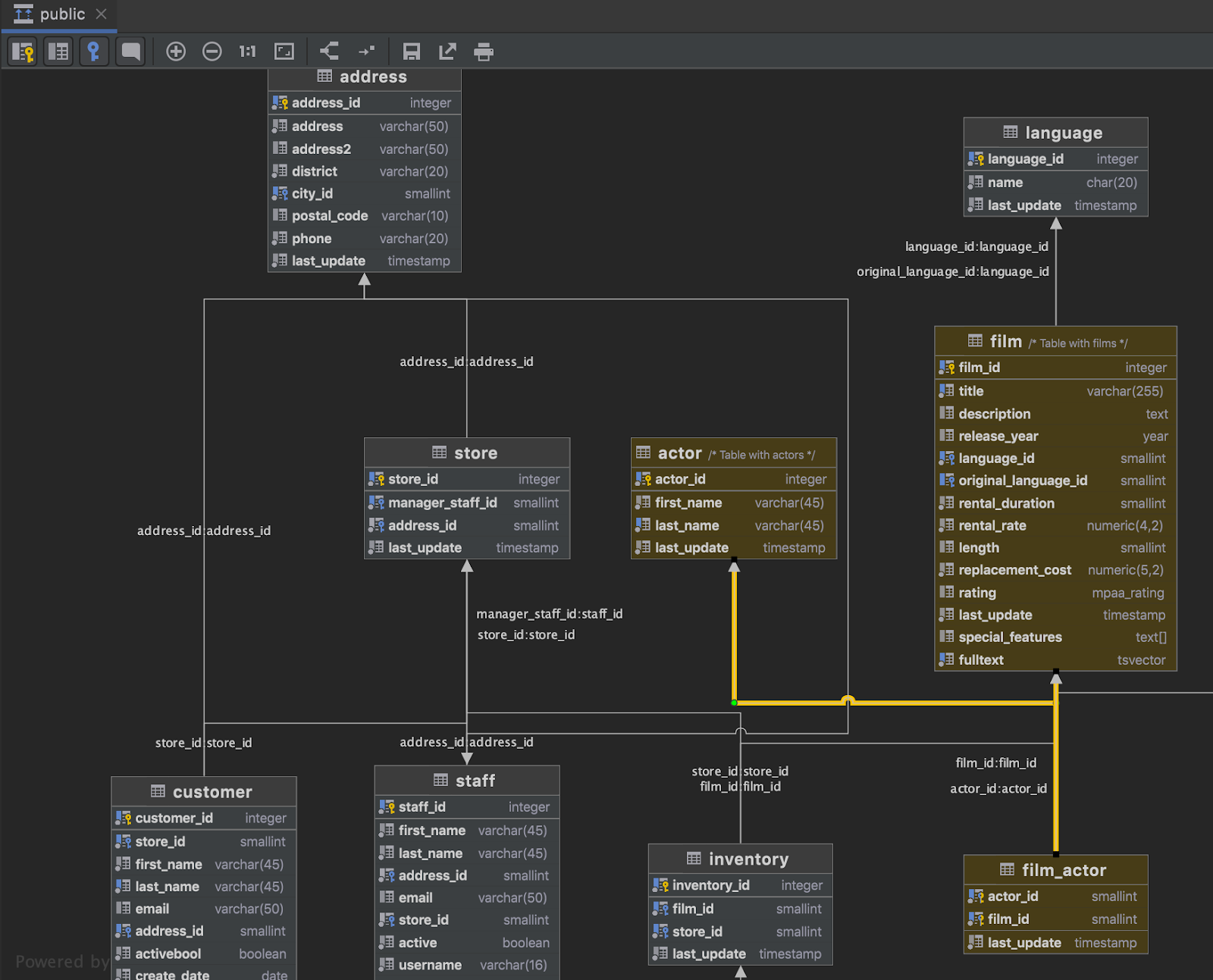
Two important features have been added to diagrams:
– Table comments are now visible
– Colors of tables are also displayed on the diagram
Introspection
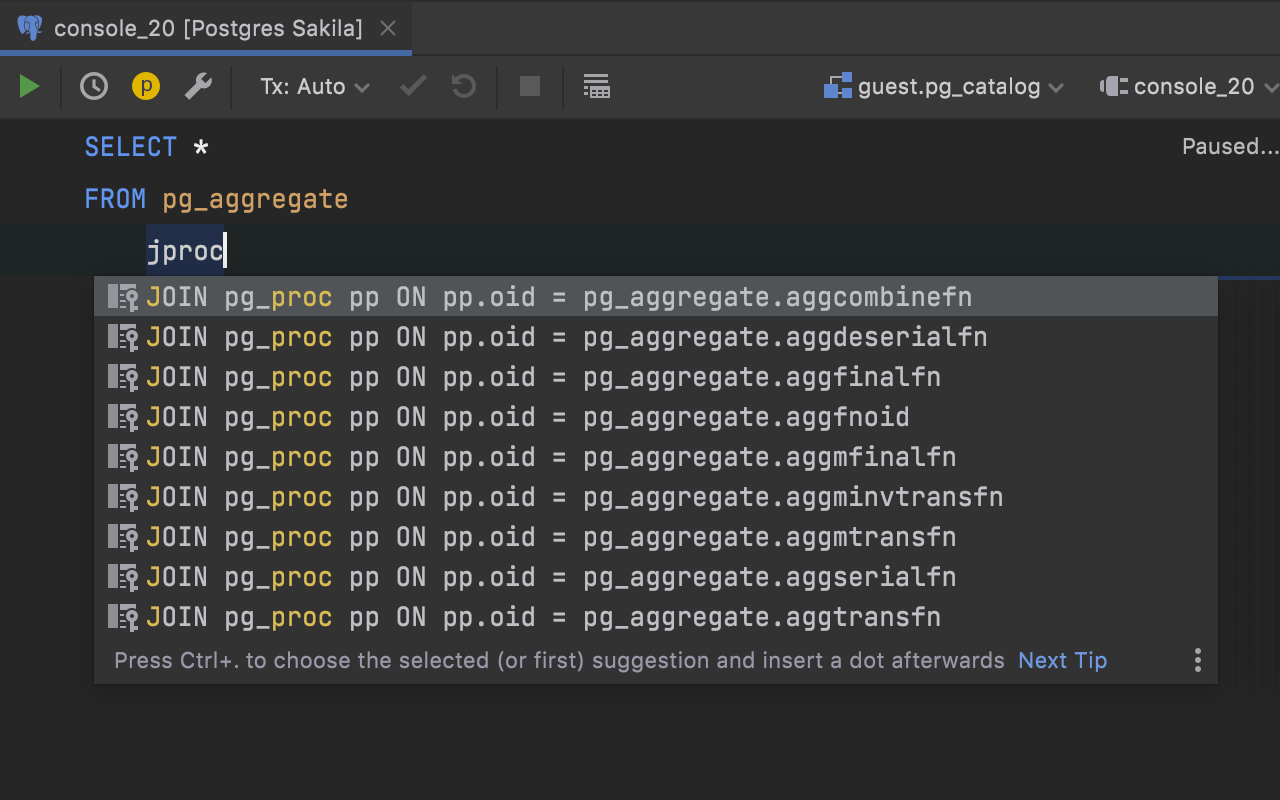
[PostgreSQL] Virtual foreign keys for pg_catalog
Some time ago, we announced the mechanism for creating virtual foreign keys. Now we’ve used this mechanism and covered pg_catalog with virtual foreign keys. This brings a couple of improvements.
First, the JOIN completion helps you when querying system tables:
Second, navigation by data in system tables works:
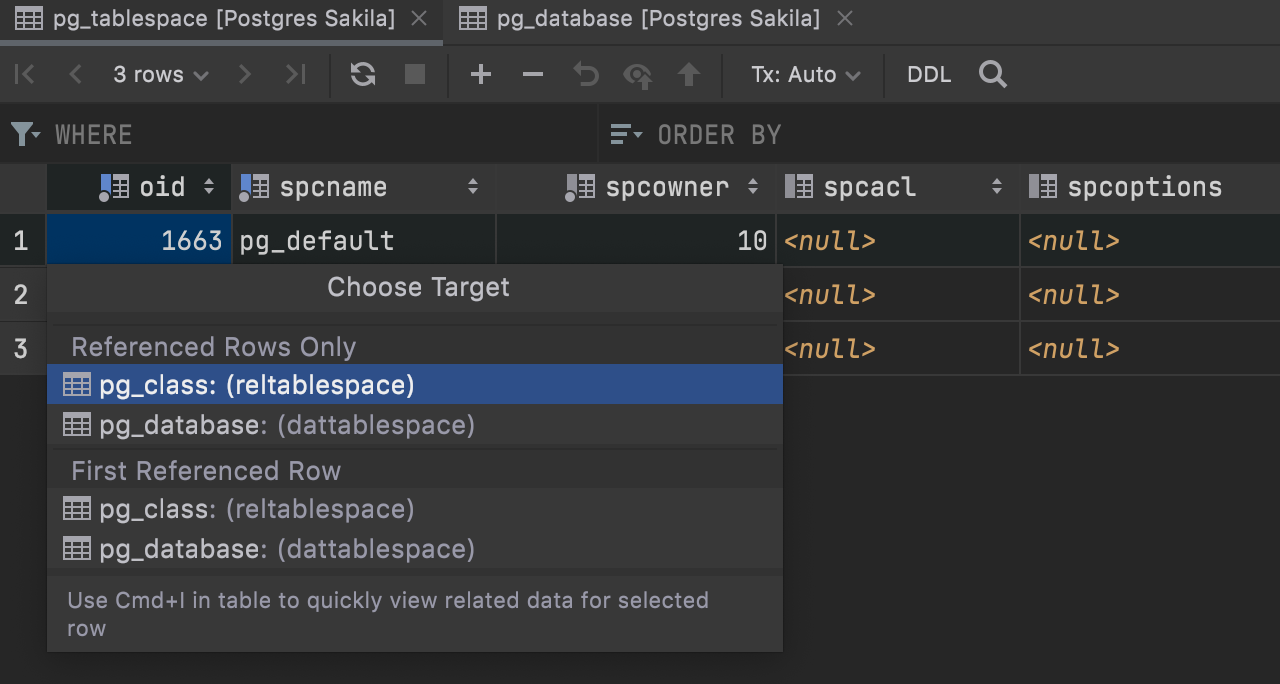
[Oracle] Tablespaces
We added support for tablespaces, data files, and temporary files. They are now introspected:
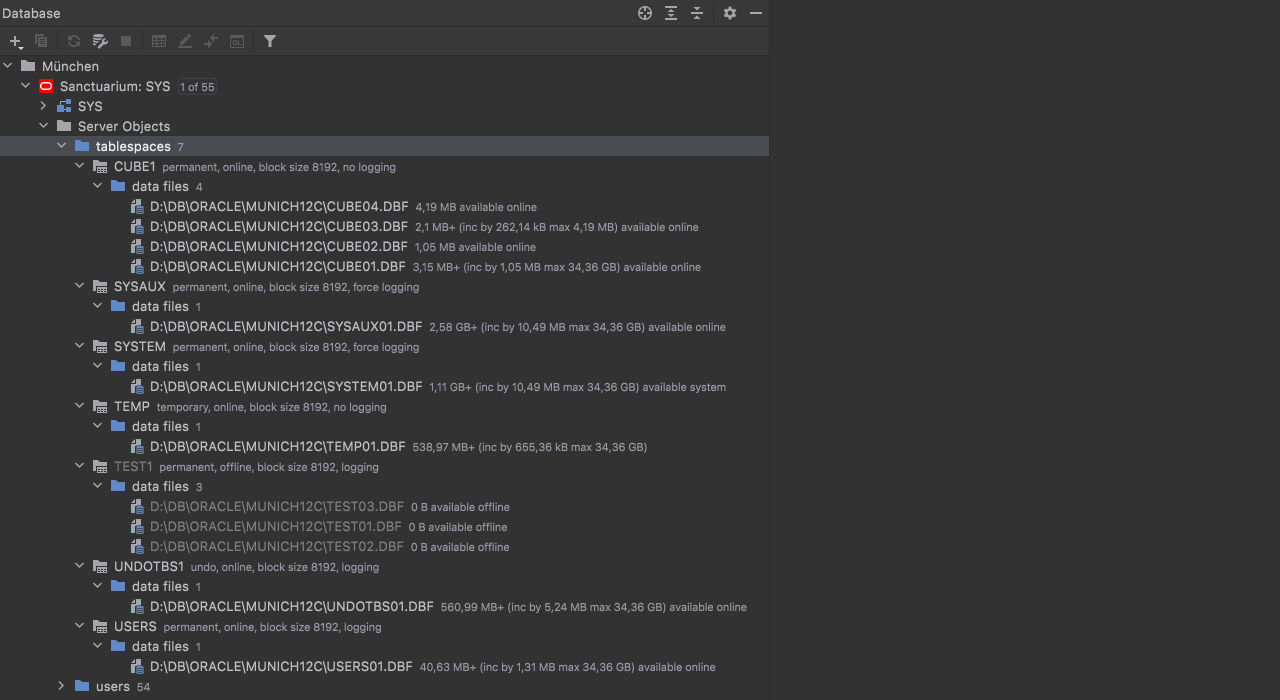
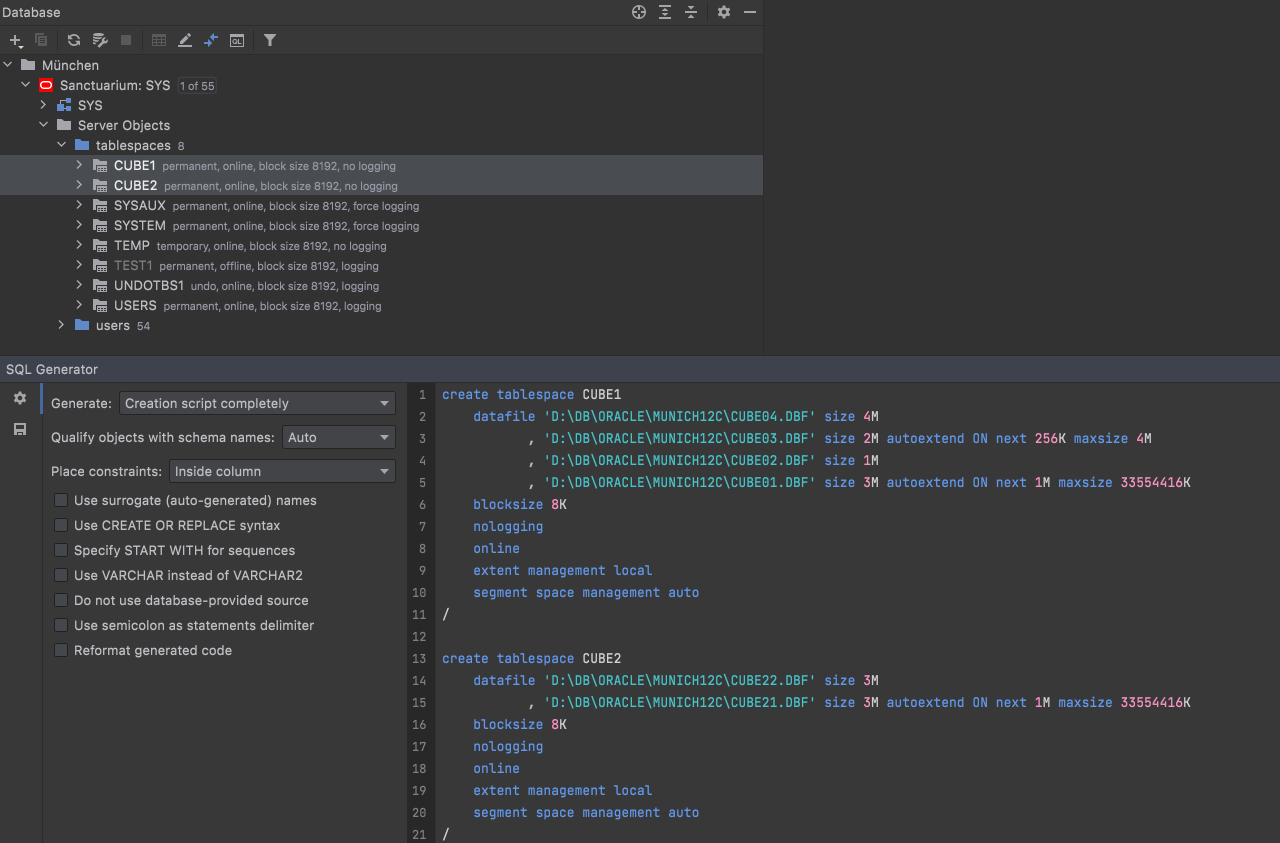
And included in DDL generation:
SQL editor
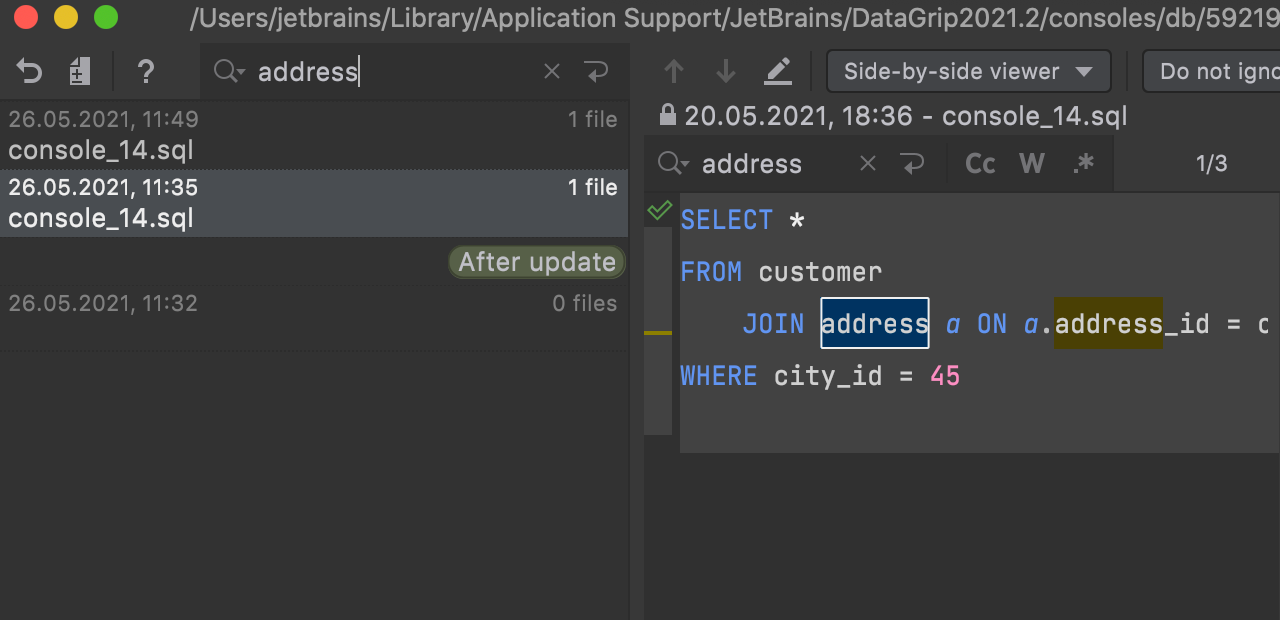
Search in Local History
Now if you are looking for a particular revision in the local history, you can use text search for help!
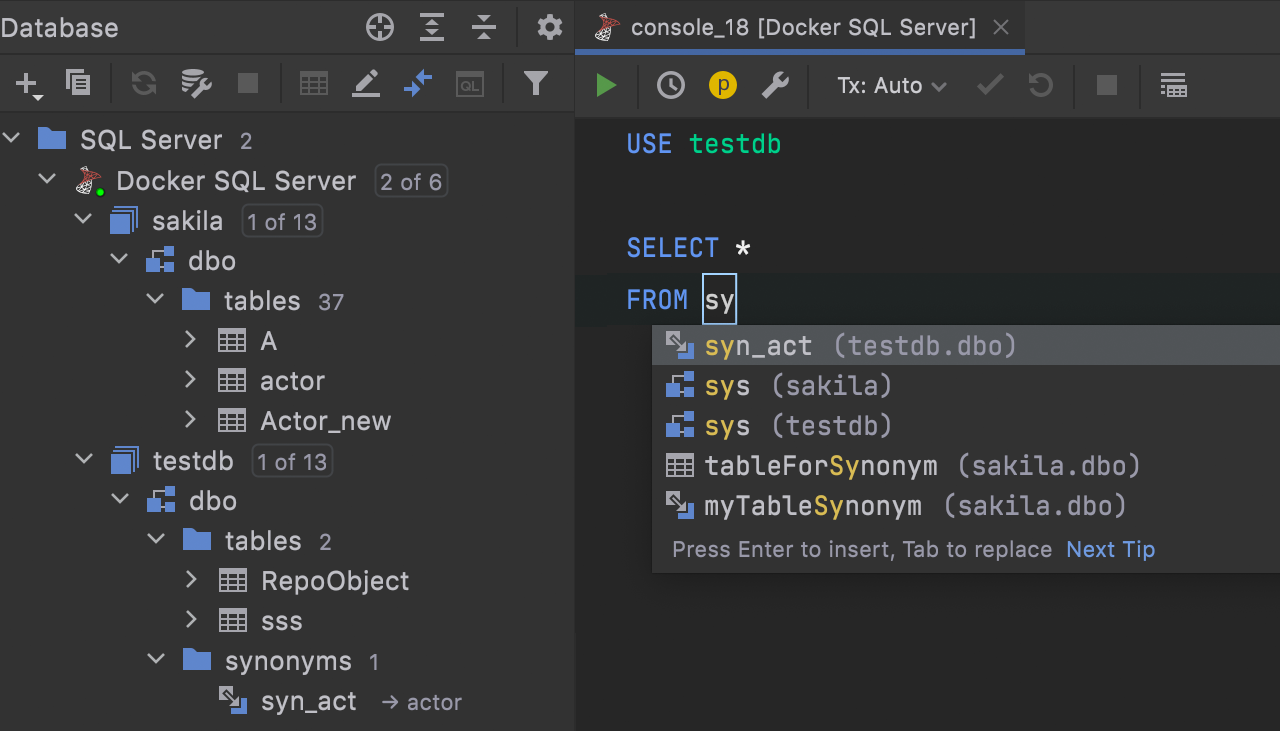
[SQL Server] Completion for cross-database synonyms
Code completion for cross-database synonyms is now available.
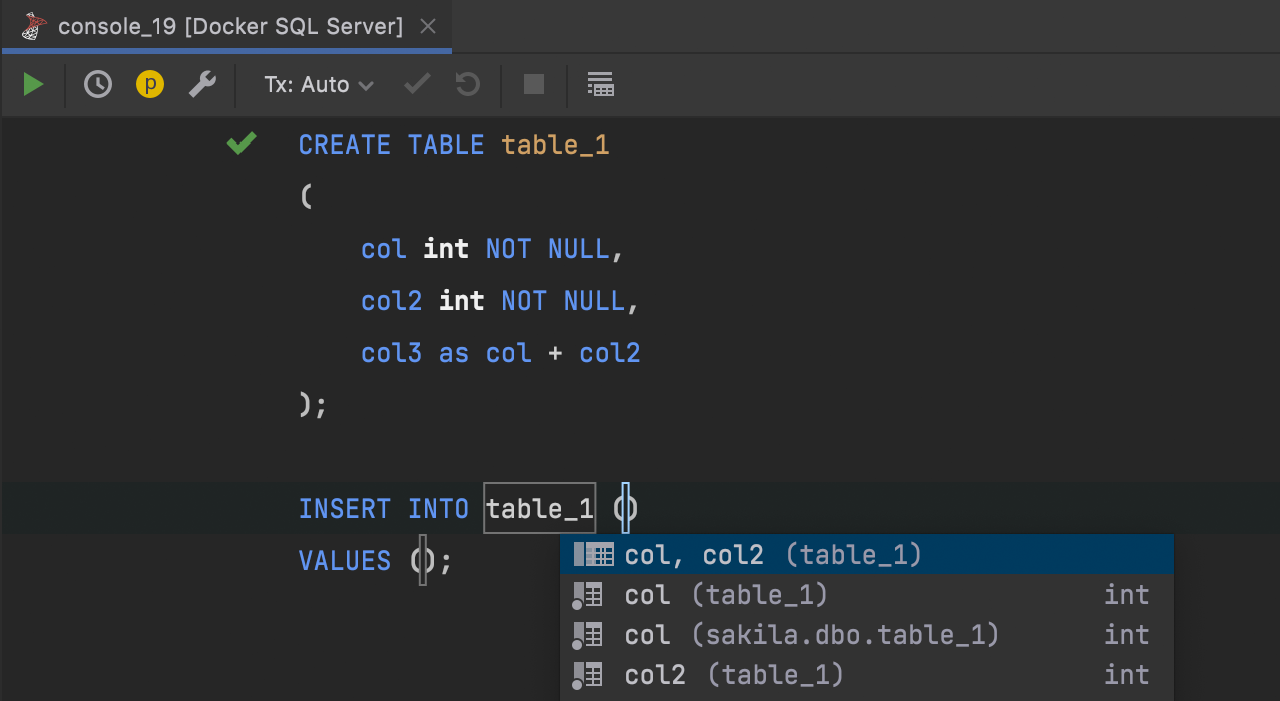
INSERT completion and computed columns
Computed columns are taken into account when completing INSERT statements – they are not included in the suggested item.
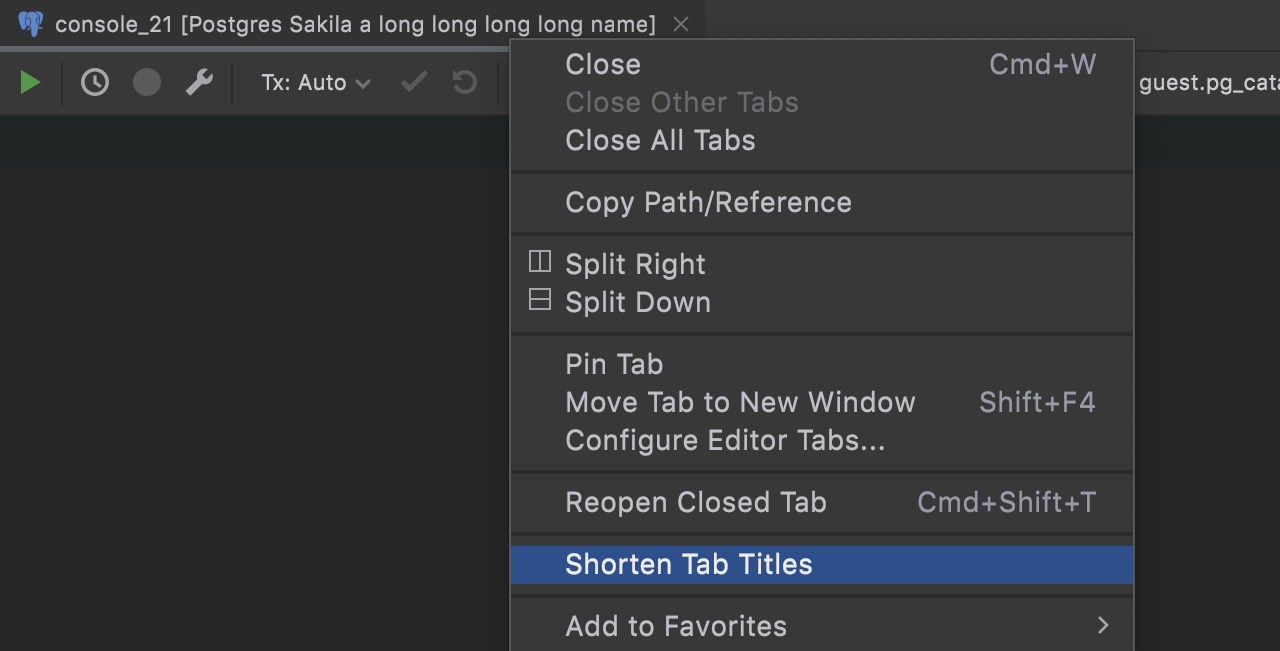
Long tab names are back
After receiving some feedback from users who didn’t like the shortened tab names, we introduced the option to change them back. If you prefer long tab names, you can simply uncheck the Shorten Tab Titles option.
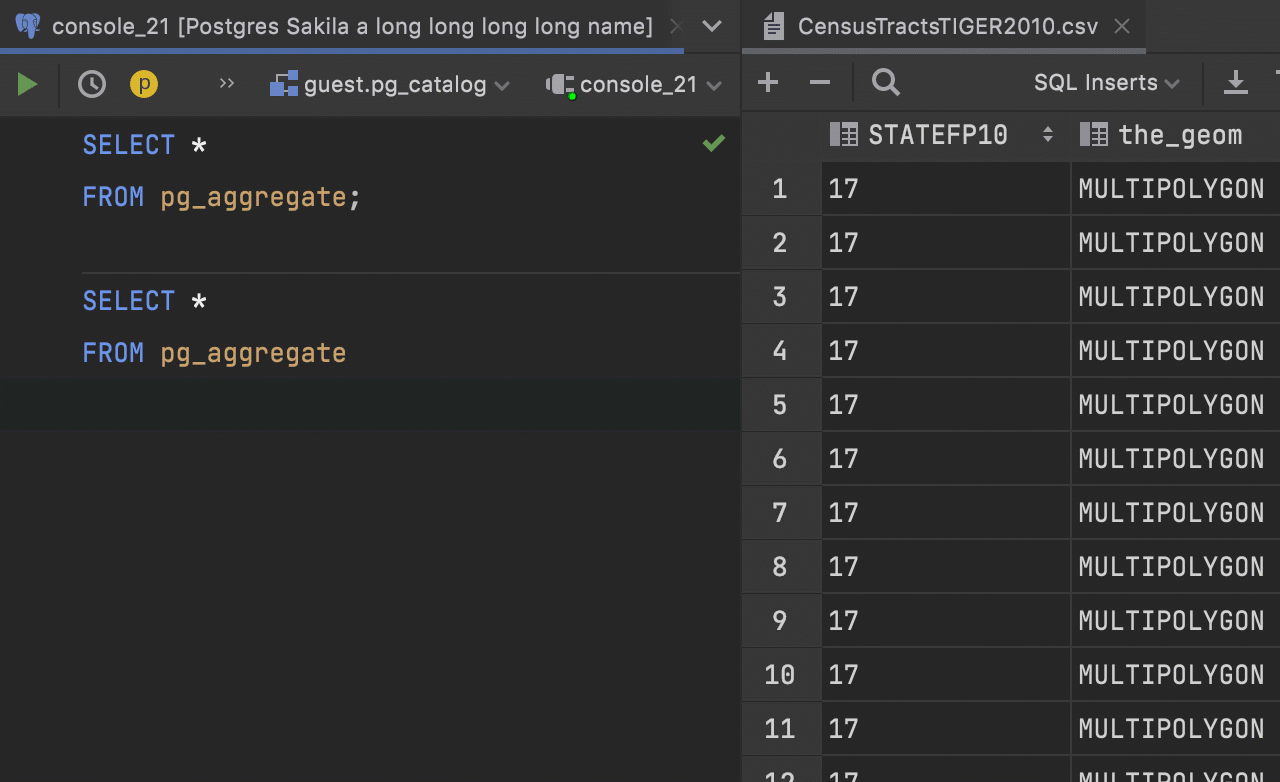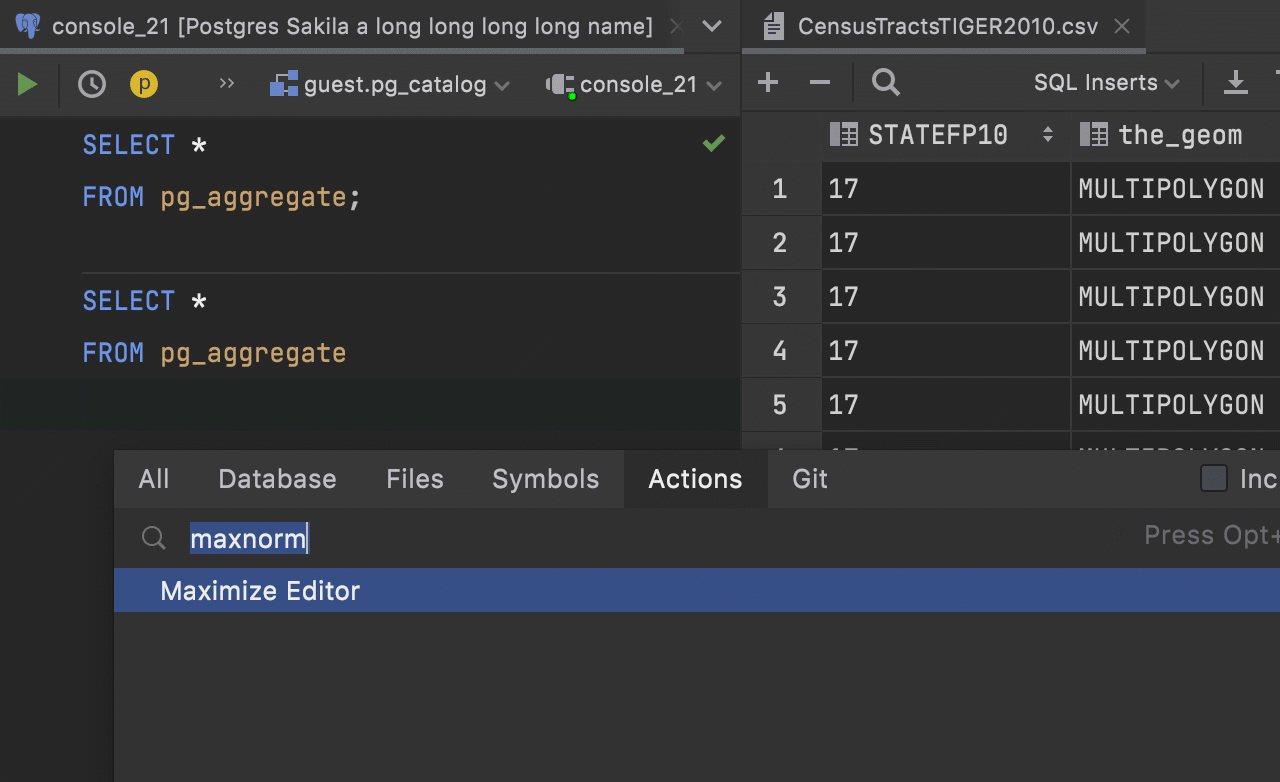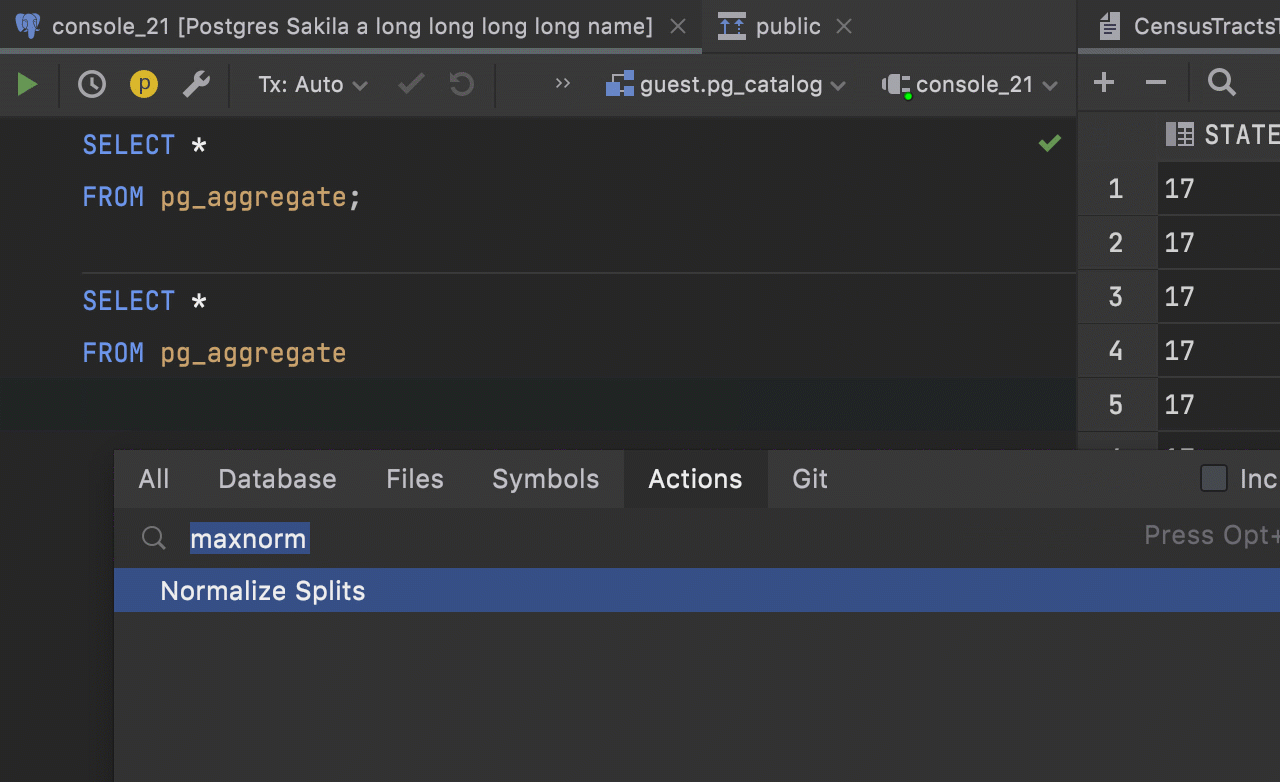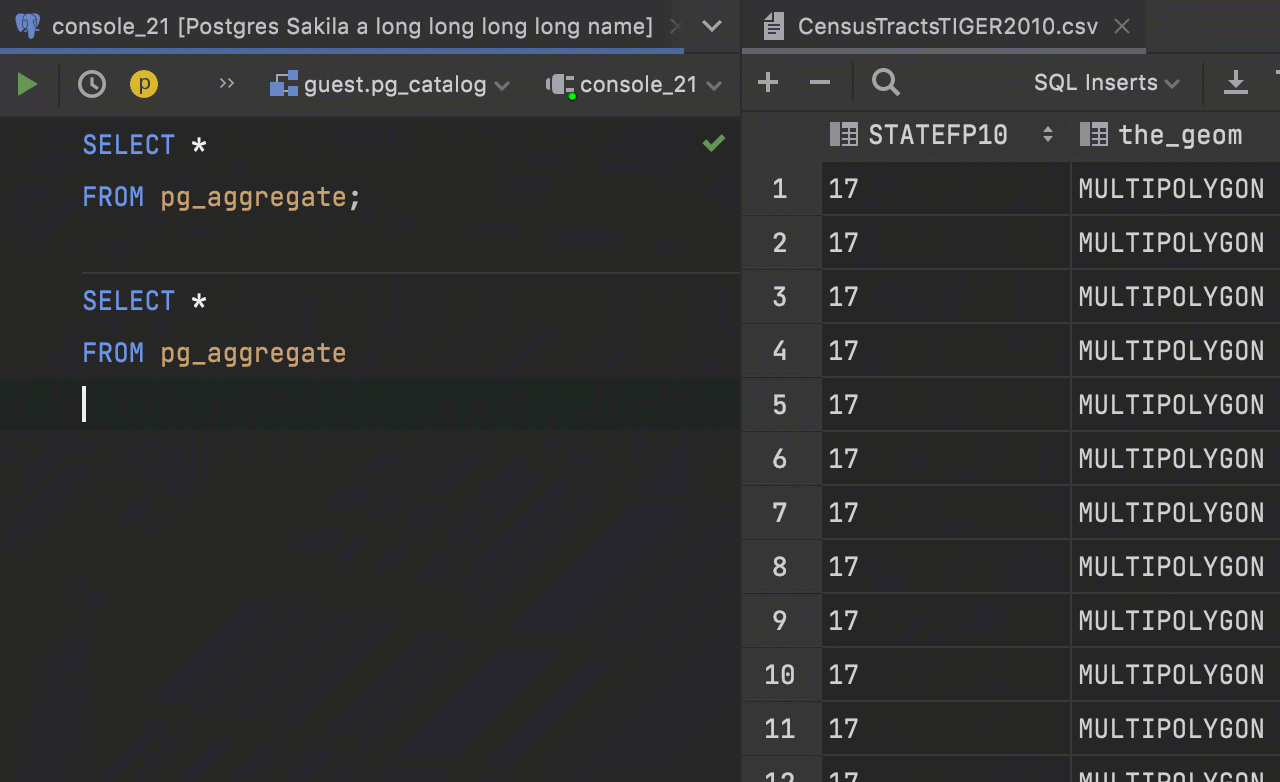
Maximize Editor / Normalize Splits action
For a long time we had the Hide All Tool Windows action, which could be called by double clicking on a tab or with the Shift+CtrlCmd+F12 hotkey. Many users treated it as a Maximize Editor action and it worked as such!
After we introduced the split mechanism, the situation became more complicated: should this action hide the split tabs or not? So we did the following:
– Hide All Tool Windows action doesn’t hide the split tabs.
– The new action Maximize Editor / Normalize Splits maximizes the current tab, but doesn’t hide the tool windows.
Working with data
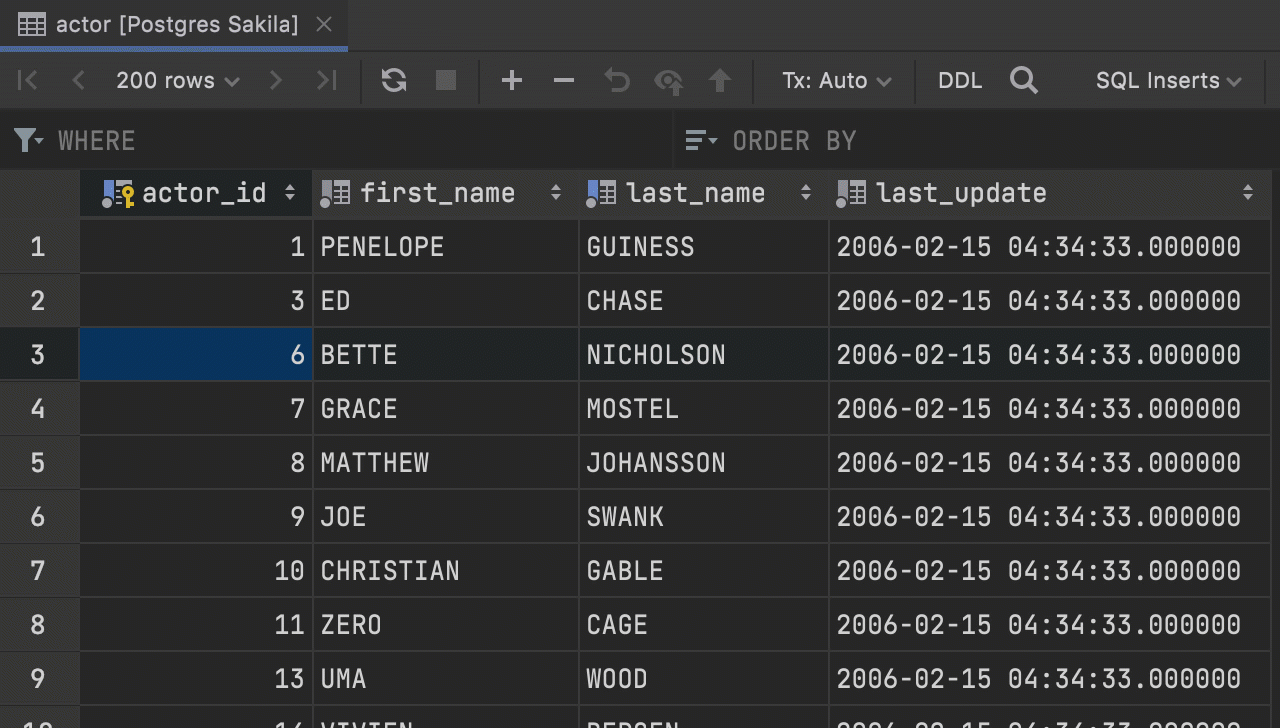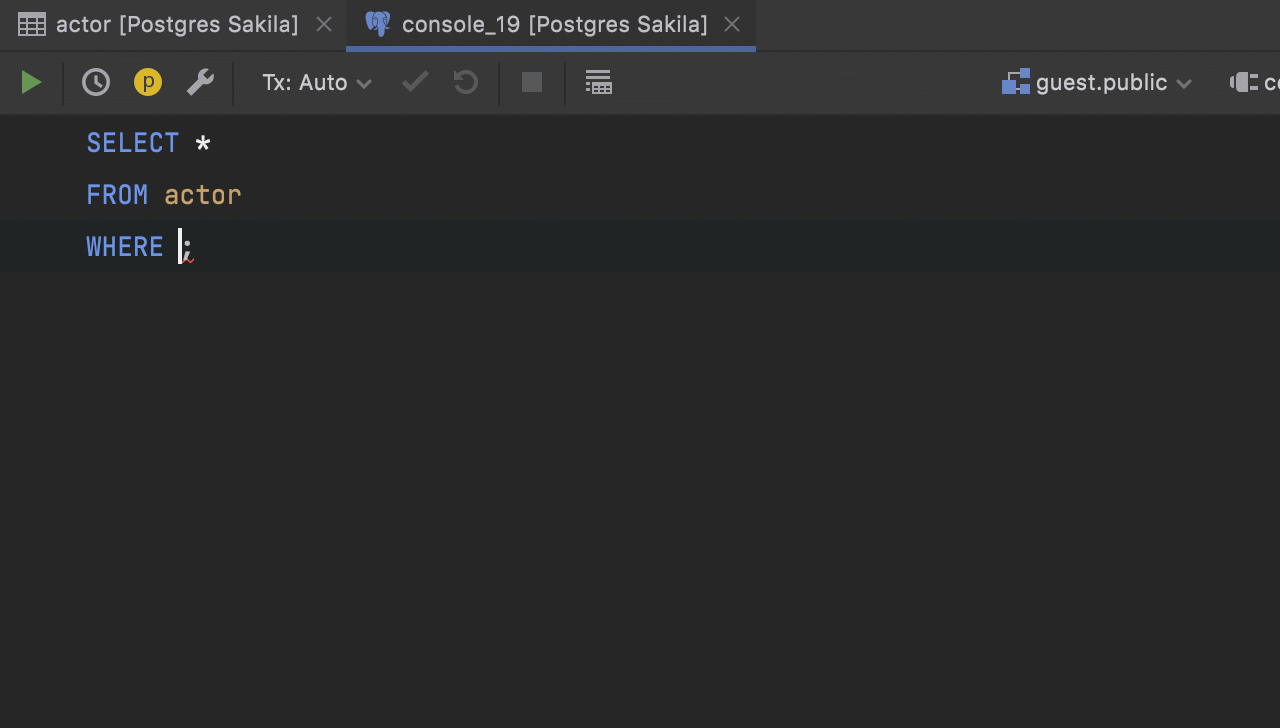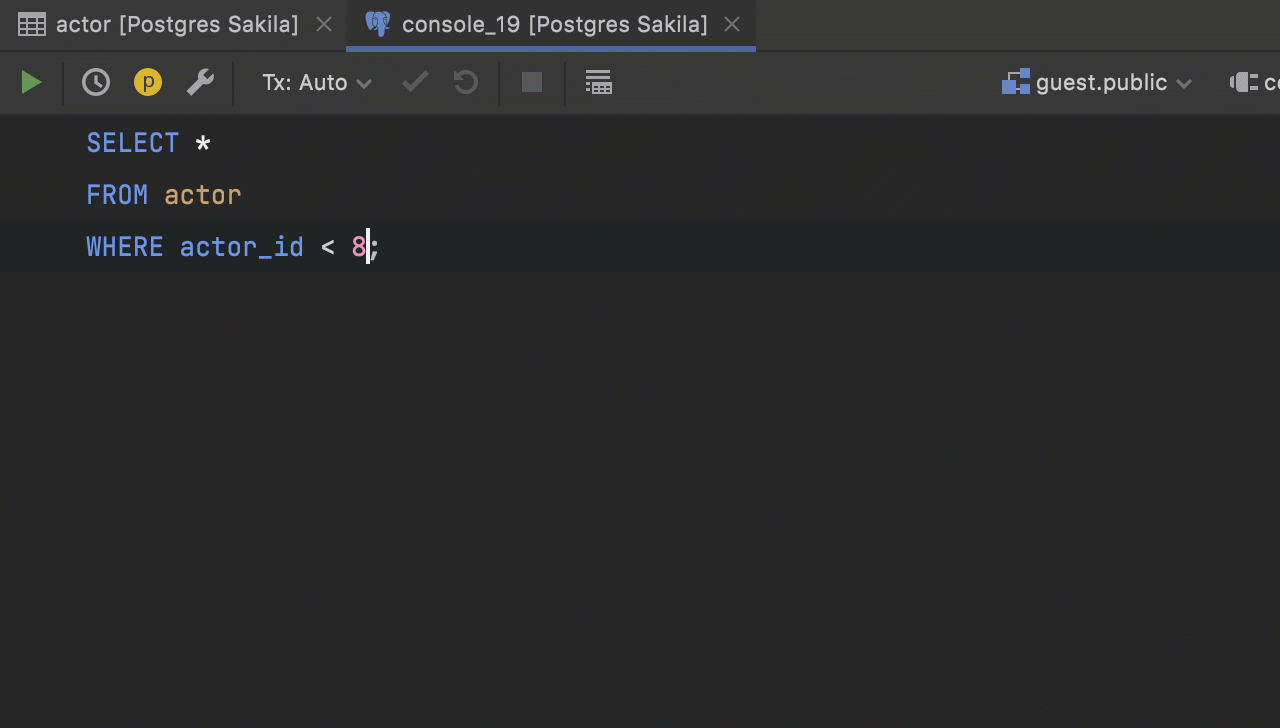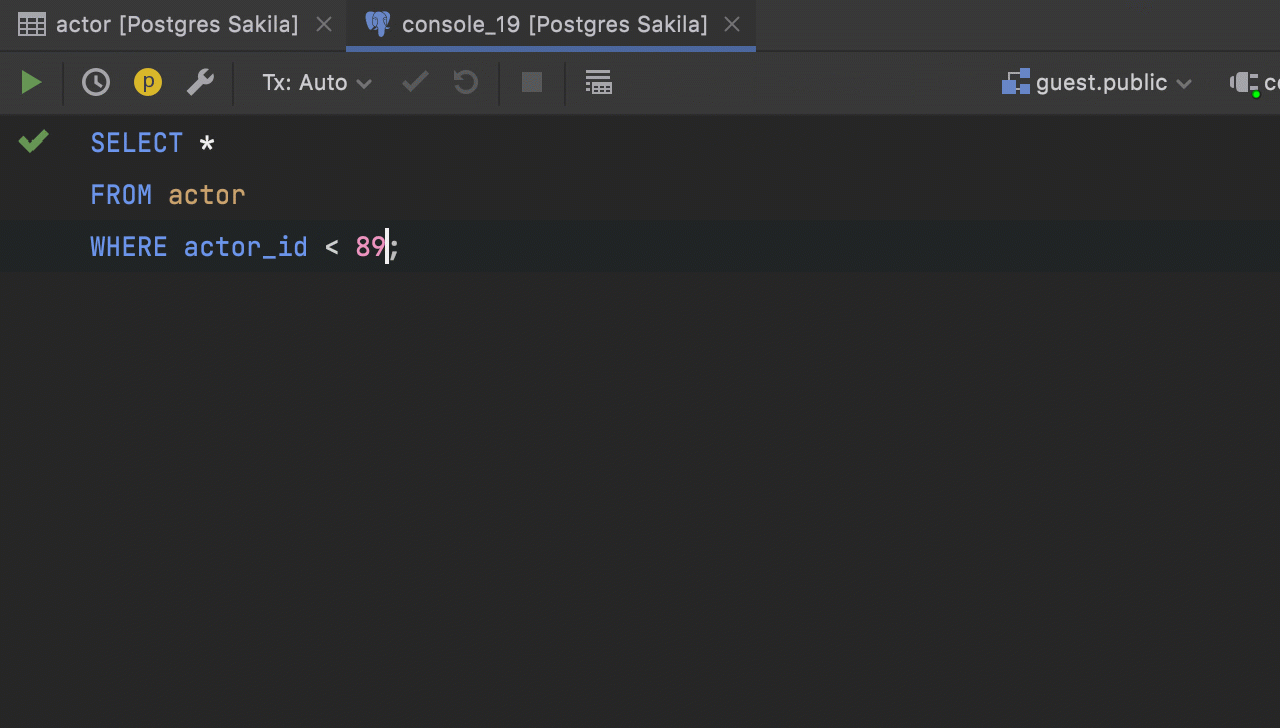
Context live templates from the data editor
Introduced in the previous release, context live templates now work from the data editor. If you’re working with a table and you wish to query it, you can easily do so with the help of the SQL scripts action!
Qualification in navigation by foreign keys
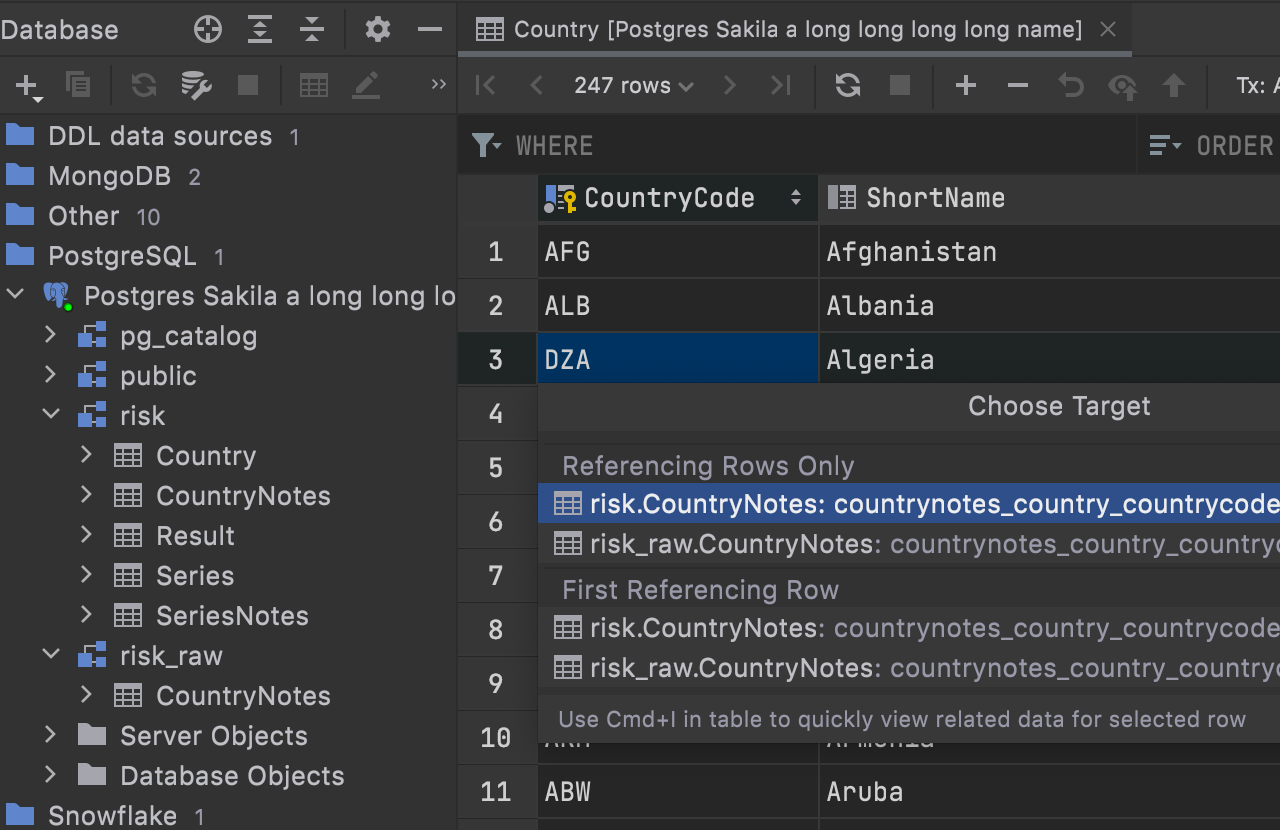
If you have foreign keys pointing to the objects in another schema and these objects have the same names, they will be displayed as qualified in the foreign keys navigation UI:
Option for additive sorting
The recently introduced Alt+Click for additive sorting (instead of just Click) wasn’t convenient for some users. If you are one of them, you can now change the value here:
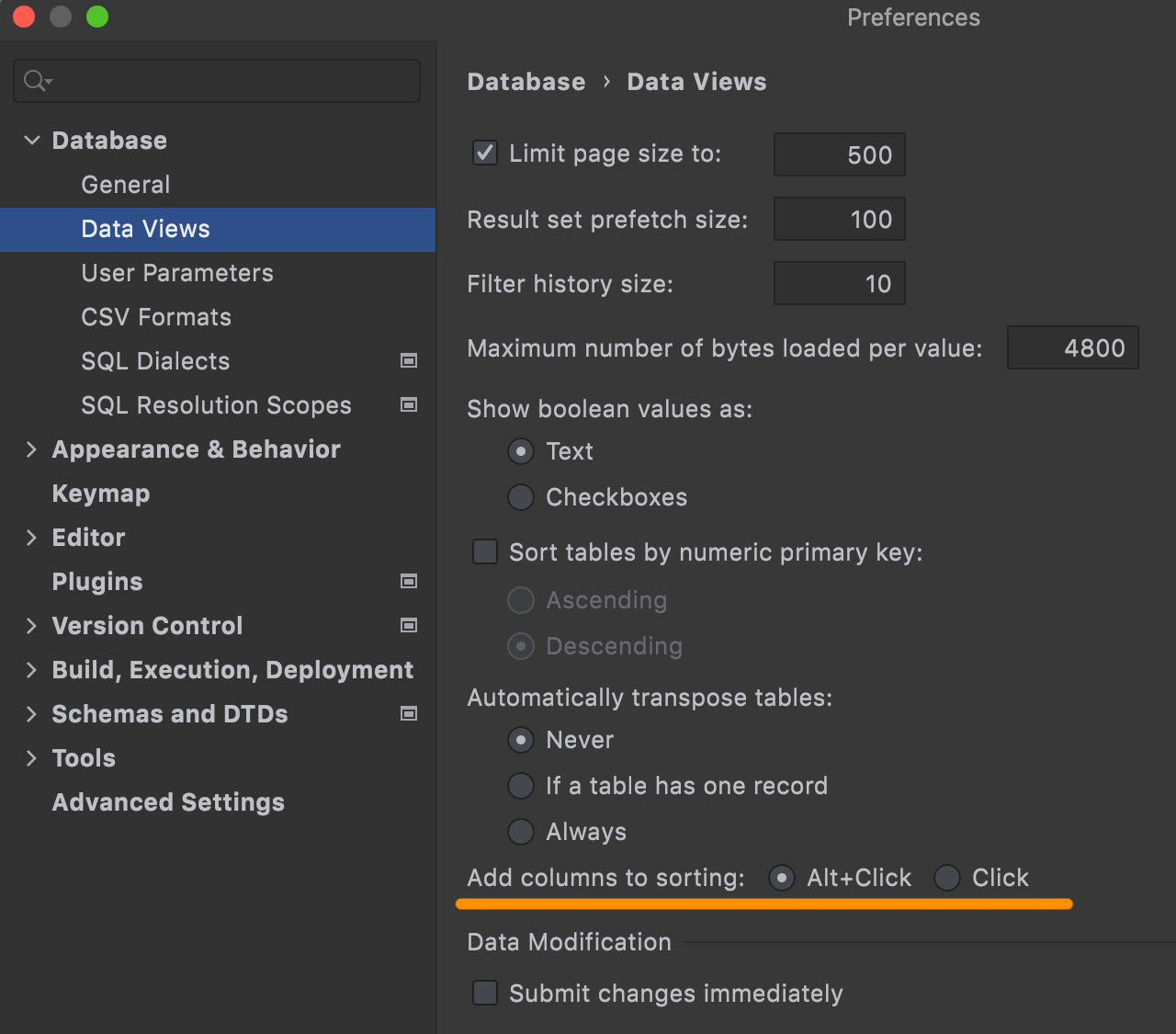
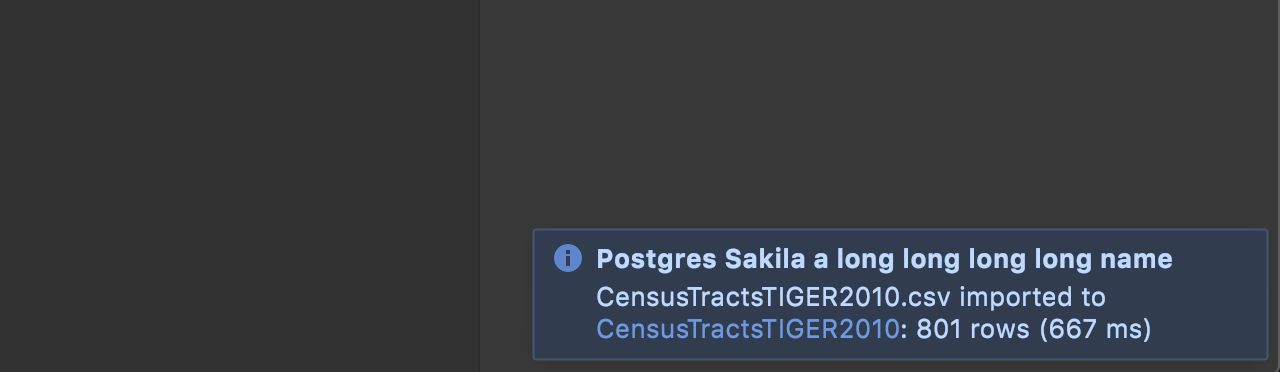
Table link after import
When you finish an import, a link to the new table appears in the notifications.
Other
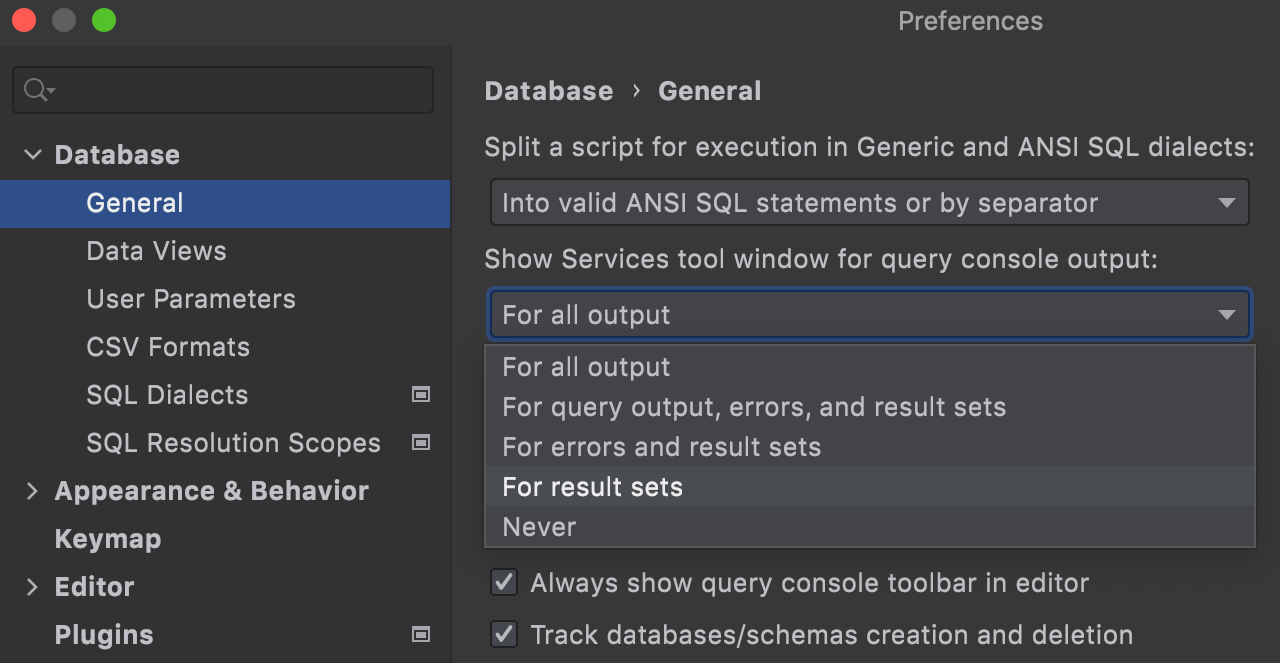
Managing the popping up of Services tool window
When a query returns no data, there’s no need for the Services tool window to appear if it was hidden already. Now you can define which operations make the Services tool window appear on your own.
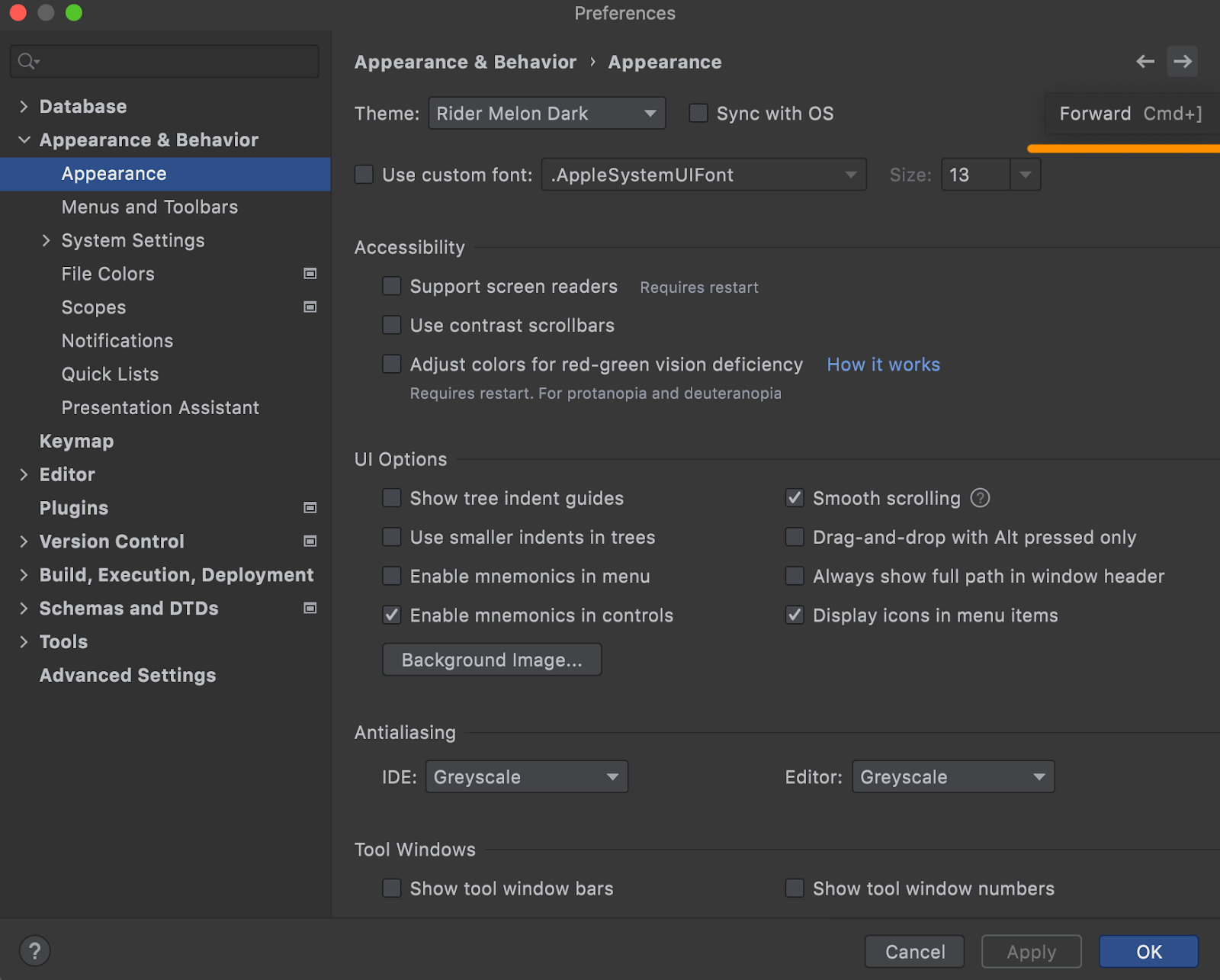
Back and forward buttons in Settings
These buttons make it easier to navigate in the Settings window and not get lost there.
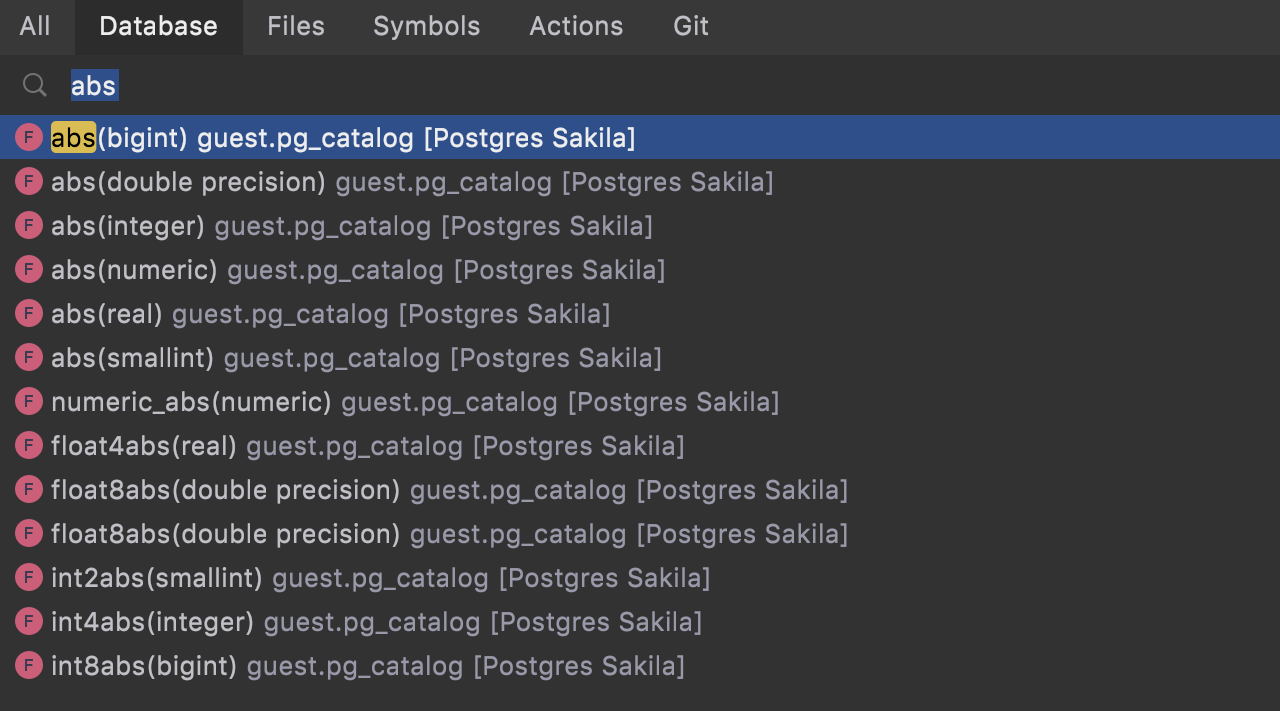
Signatures in navigation
Now when you are searching for a function, procedure, or operator, we show the signature in the Go To window. This helps when you use overloading heavily!
Quality improvements
General
DBE-12079: [PostgreSQL] We’ve reworked the introspector. The main effect of the new introspector for the end-user is no more object duplicates!
DBE-13164: No more freezing when typing JOIN statements along with using virtual foreign keys.
Import/Export
DBE-13259: Export of numeric fields doesn’t fail if there are non-numeric values.
DBE-11370, DBE-13139, DBE-12536: Import became faster for PostgreSQL, Redshift, Exasol, Hive, Clickhouse, DB2, and HSQL.
DBE-11370: Import became faster with the help of multi-insert statements for Hive, Clickhouse, DB2 and HSQL.
Data editor
DBE-12545: ORDER BY field size is saved.
DBE-13055: Time zone is always shown for values with the timezone.
DBE-9814: [Oracle] DATE type values don’t display time if no time is set.
DBE-12679: [Oracle] Filtering by DATE field is possible.
DBE-12716: [DB2] Filtering by binary, blob, char for bit data, and varchar for bit data fields is possible.
That’s all for today. Your feedback is welcome on our Twitter or forum. We also have a quick way for you to report issues straight from DataGrip: click Help | Report problem… to create a new issue in our issue tracker.




