

IntelliJ IDEA
IntelliJ IDEA – the Leading IDE for Professional Development in Java and Kotlin
 Promo image
Promo image
IntelliJ IDEA
IntelliJ IDEA 2025.3
IntelliJ IDEA 2025.3 Is Out Now!
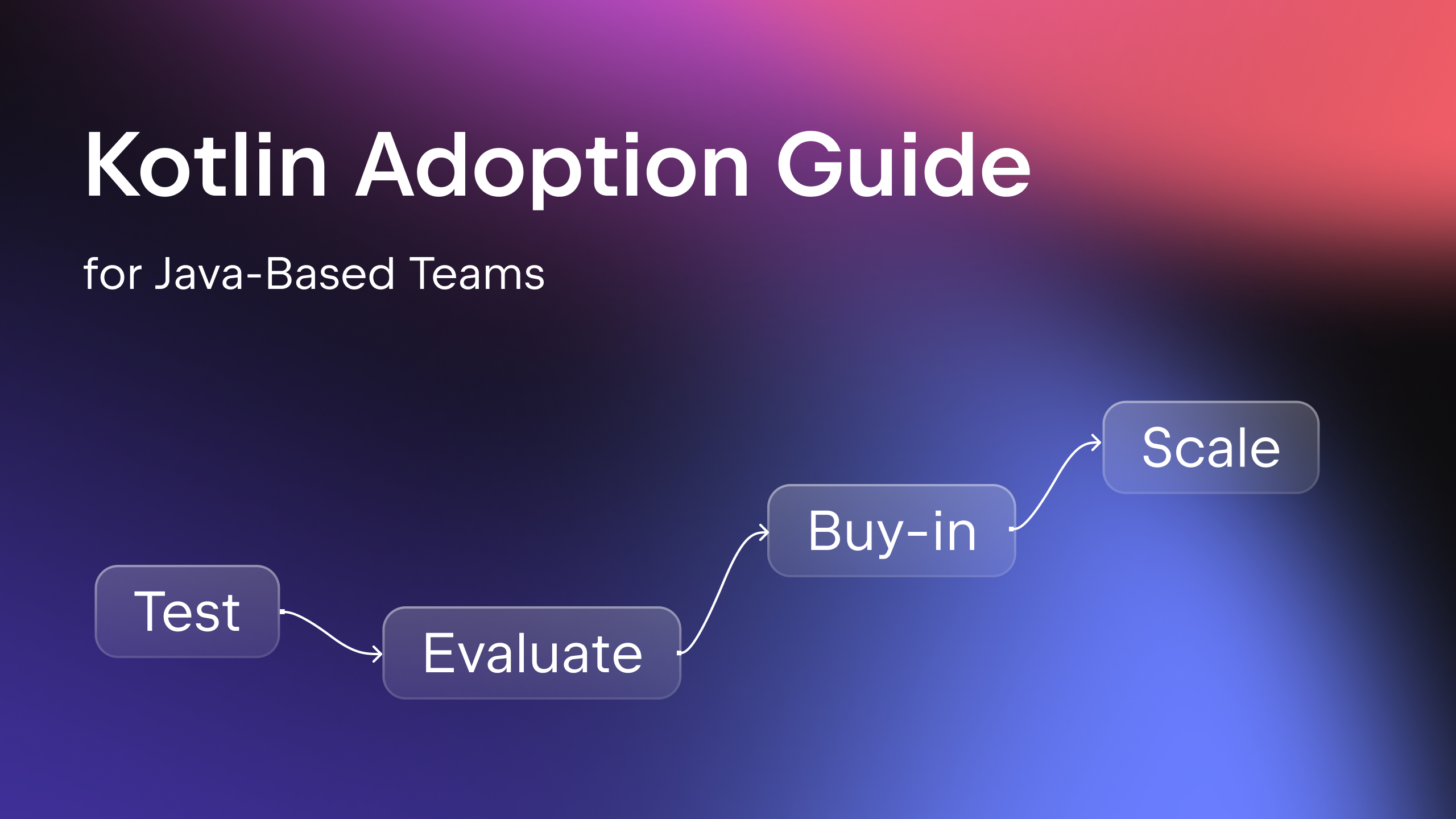
IntelliJ IDEA 2025.3 has arrived! This version brings significant updates designed to streamline your productivity and help you confidently adopt the latest innovations across the Java ecosy…





















Subscribe to IntelliJ IDEA Blog updates