

Big Data World, Part 4: Architecture

This is the fourth part of our ongoing series on Big Data, how we see it, and how we build products for it. In this installment, we’ll cover the second responsibility of data engineers: architecture.
Related posts:
- Big Data World, Part 1: Definitions
- Big Data World, Part 2: Roles
- Big Data World, Part 3: Building Data Pipelines
- This article
- Big Data World, Part 5: CAP Theorem
Table of contents:
As we discussed in Big Data World, Part 2: Roles, data engineers are responsible for building the architecture of data warehouses. But what does that mean exactly? The term “architecture” is overused in engineering and actually has many different meanings. In data engineering specifically, it has two: the architecture of storage and the architecture of data processing.
Storage architecture
In traditional backend engineering, the storage layer is usually quite simple and contains up to three components: databases, caches, and file storage. A database is usually just a single entity, be it SQL or NoSQL, relational or not-relational.
In data engineering, however, we have to use many different types of storage. This is because data should be stored on several layers, with different requirements for each.
One of the most popular storage architectures is the Data Warehouse.
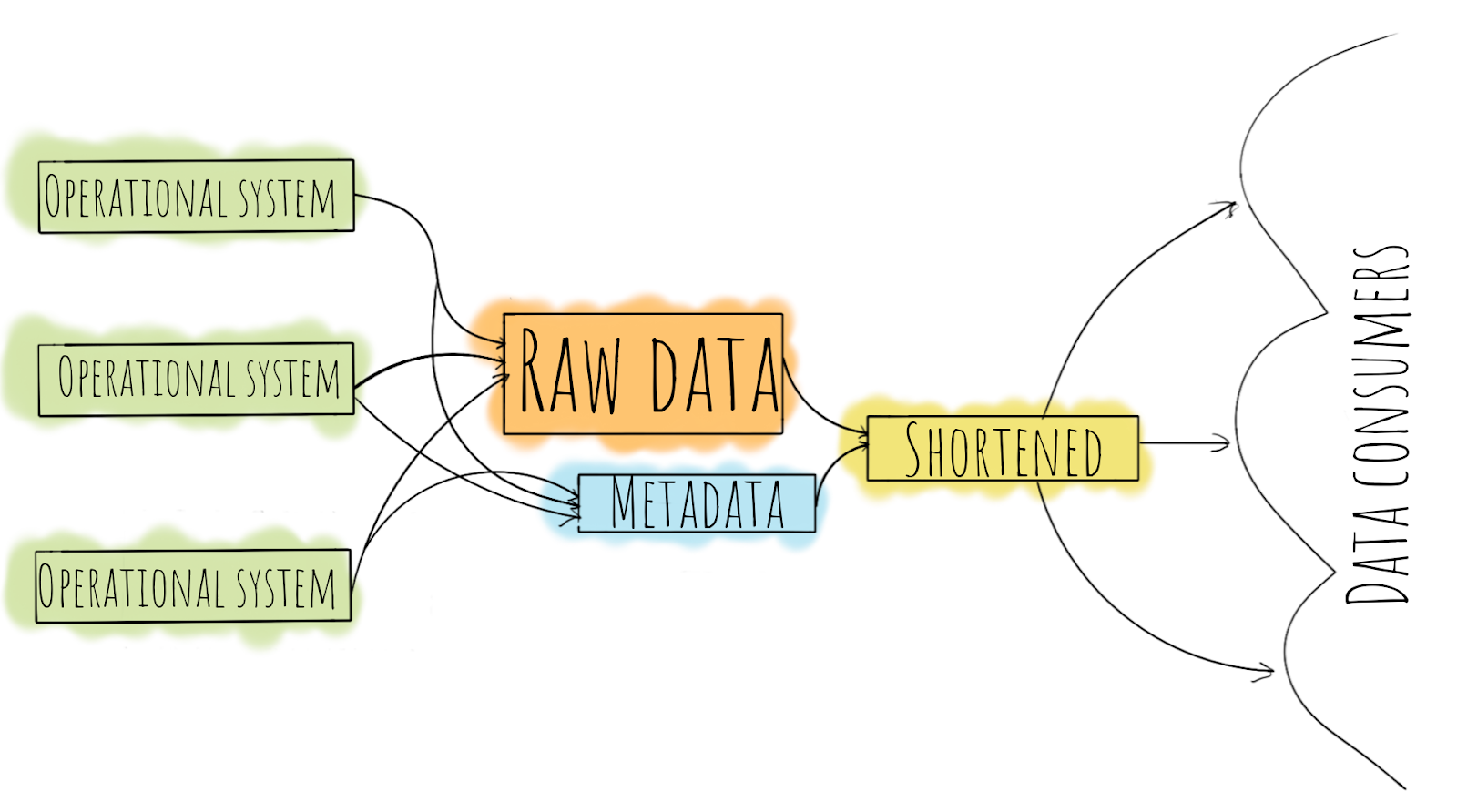
Everything starts with operational systems, be they e-commerce, bank, or anything else. Data from operational systems goes to the raw data store as is. It may be consistent or not, clear and verified or not – but whatever shape it’s in, we save the data so we can process it in any defined logic as many times and to as many destinations as we need.
Besides data, we usually want to save some metadata, such as when a snapshot of an operational database is taken or when a message comes to an event store.
After the raw data is collected, it needs to be cleaned, verified, aggregated, and put into the shortened/aggregated data store. After the data is aggregated, it is ready to be used by business consumers, who can be either single individuals or whole departments. Data in this form should be suitable for building desired reports or for other business needs, like customer segmentation.
This is only a basic and simplified description of what a Data Warehouse is. A more detailed description can be found on Wikipedia.
The Data Warehouse system is not the only popular solution though. Other examples include:
What’s more, enterprises typically create their own hybrid storage models to better meet their needs.
As you can see, there are several ways to organize the data storage layer, but the data storage layer is only part of the system. Data doesn’t simply say put in storage – it moves around. As previously described in Big Data World, Part 2: Roles, data moves through a pipeline, and we can’t understand this activity without addressing data processing architecture.
Data processing architecture
The requirements for data and the patterns of its usage directly depend on the business cases. Still, two types of data can be found everywhere today: live-streaming data and historical data.
How should we work with this data? Our solutions will be reliable only if we use as much data as possible, and for solutions that address the short term, it usually should be almost real-time data.
While working with collected data is also interesting, I would like to simultaneously focus on the processing of real-time data. There are several approaches to handling real-time and collected data at the same time, but the two dominant ones are Kappa and Lambda architectures.
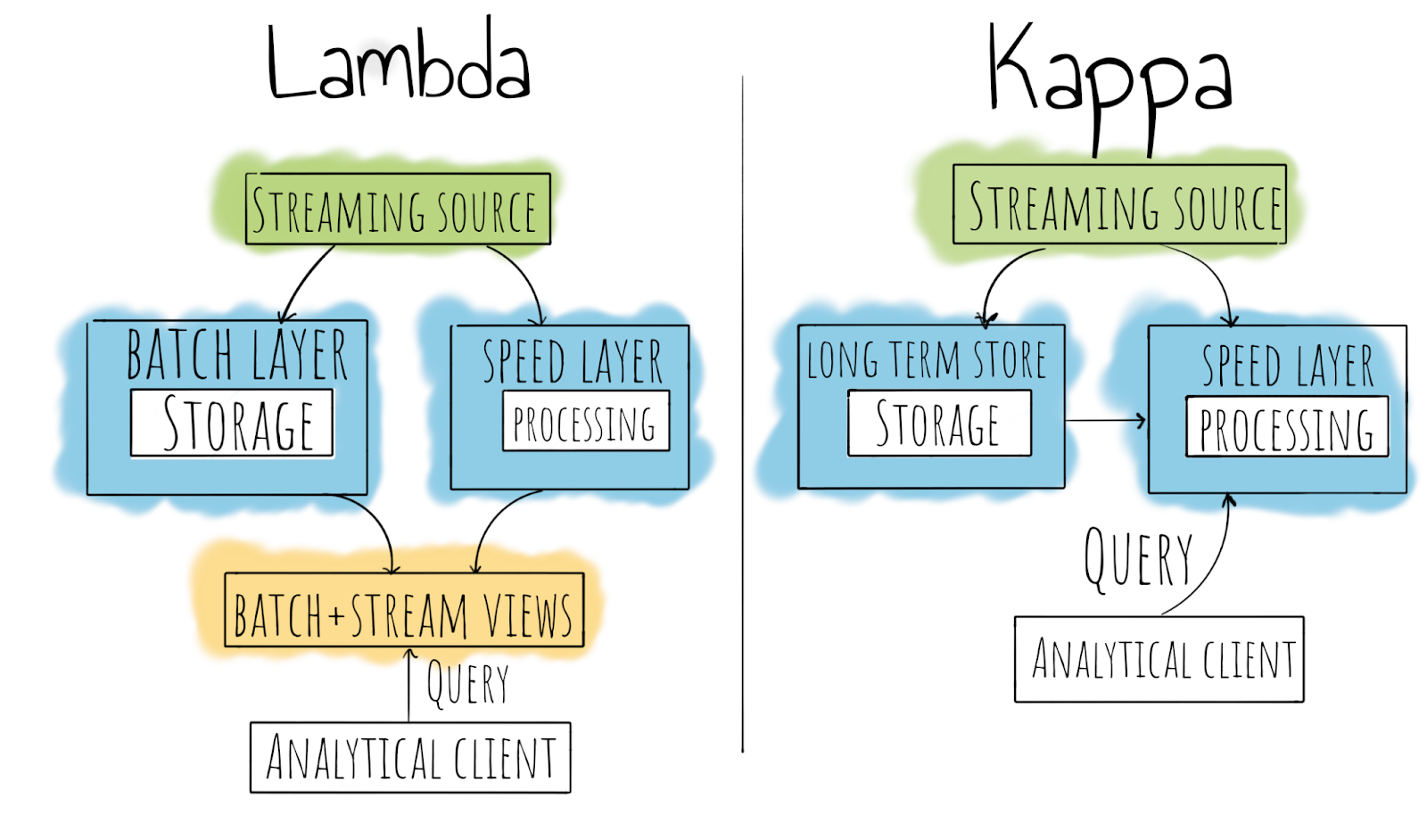
What are we seeing here? Let’s first define several terms:
Speed layer – the layer responsible for real-time data processing. Usually, it works with some tradeoffs between precision and data-processing speed.
Batch layer – the layer responsible for the storage of master data. This data can never be modified and is stored in append-only mode.
Analytical client – a consumer of data, which can be an automated system or a human.
The arrows on the picture are processing mechanisms or pipelines that are responsible for transforming and transferring data, as discussed in Big Data World, Part 3: Building Data Pipelines.
Now, let’s quickly describe what’s going on in the image.
In the Lambda architecture, we’re streaming data from the streaming source(s) to the batch and speed layers. This data then forms the batch and streaming views that customers can query.
That sounds interesting and achievable, but this architecture has one potential issue: if we’re using different tools on the batch and stream layers (which is almost a certainty), then we have to implement the processing logic twice. And that might make maintenance very hard, with more engineers required to support such a system.
The Kappa architecture is simpler: the main idea behind it is that all the data always passes through the speed layer and is being stored on the batch (long-term store) layer. But this architecture also introduces new challenges: in the absence of a batch data view, we need to scale the stream processors.
But why do we need to have a batch layer in the Kappa architecture at all? Well, if the computation logic changes, we will be able to recompute all the data from the long-term store, which de facto stores event logs from the streaming source; while for an analytical customer, nothing changes.
Further reading about streaming data processing architectures:
You may have noticed that during all this post I didn’t mention any specific technology. That is because architecture patterns are basically technology-agnostic. But of course, when we talk about the real architecture of a real business, the choice of technological stack will be important for sure.
Technological stack
When speaking about the Lambda and Kappa architectures, there is always a streaming source. Indeed, not so many technologies can play this role. The most popular ones are Apache Kafka and Apache Pulsar for on-premise solutions, or vendor-specific solutions when the solution is hosted in the cloud.
Every warehouse has its own storage layer, and here the range of technologies to choose from is just enormous. Every cloud provider has lots of storage for different needs: object storage, file storage, relation storage, MPP (massively parallel processing) databases, and more. Building an architecture is the perfect way to learn more.
Conclusion
Big data architecture is a very broad field, with plenty of ready-to-use architectural patterns and technologies for data engineers to work with. Their choice will ultimately depend on their own business needs and the needs of their customers. And in fact, this might be the perfect place for you to stop, think, and do some research in order to determine the best possible solution to meet your requirements, which should prove to be a challenging and rewarding task.
Whatever technologies you choose, though, chances are we already support them in JetBrains products. For example, you can query JDBC-capable data sources with the help of JetBrains DataGrip, or you can use the Big Data Tools plugin to look at what’s in your object storage.




