

使用 PyCharm 将 MySQL 数据库中的数据读入 pandas

在数据科学之旅中,您迟早会遇到需要从数据库中获取数据的情况。 然而,从将本地存储的 CSV 文件读入 pandas 到连接和查询数据库,这可能是一项艰巨的任务。 在一系列博文的第一篇中,我们会探讨如何将存储在 MySQL 数据库中的数据读入 pandas,并查看 PyCharm 中使这项任务更简单的一些功能。

查看数据库内容
在本教程中,我们会将一些关于航空公司延误和取消的数据从 MySQL 数据库读取到 pandas DataFrame 中。 这些数据是 Airline Delays from 2003-2016 数据集的一个版本,该数据集由 Priank Ravichandar 提供,以 CC0 1.0 授权。
使用数据库可能令人感到困惑的第一件事是无法简要了解可用数据,因为所有表都存储在远程服务器上。 因此,我们要使用的第一个 PyCharm 功能是 Database(数据库)工具窗口,它允许您在进行任何查询之前连接到数据库并对其进行全面内省。
为了连接到我们的 MySQL 数据库,我们首先要导航到 PyCharm 的右侧,然后点击 Database(数据库)工具窗口。
在这个窗口的左上方,您会看到一个加号 (+) 按钮。 点击这个按钮就会出现下面的下拉对话窗口,我们将在其中选择 Data Source | MySQL(数据源 | MySQL)。
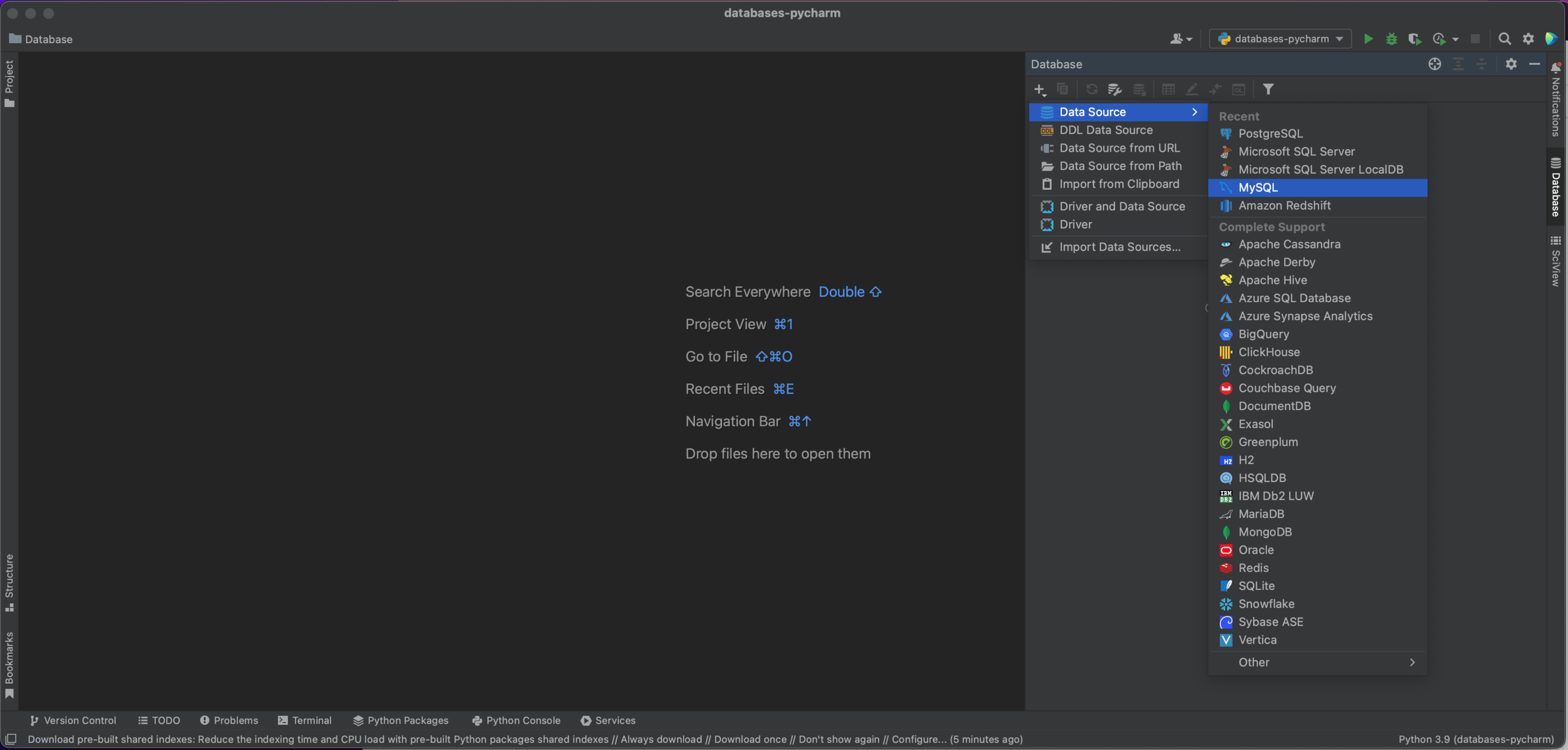
我们现在有一个弹出窗口,它将允许我们连接到我们的 MySQL 数据库。 在这种情况下,我们使用的是本地托管的数据库,因此,我们将 Host(主机)设为“localhost”,将 Port(端口)设为默认的 MySQL 端口“3306”。 我们将使用“用户和密码”作为 Authentication(身份验证)选项,并在 User(用户)和 Password(密码)中输入“pycharm”。 最后,在 Database(数据库)中输入我们的数据库名称“demo”。 当然,要连接到您自己的 MySQL 数据库,您将需要特定主机、数据库名称,以及您的用户名和密码。 请参阅文档了解全部选项。
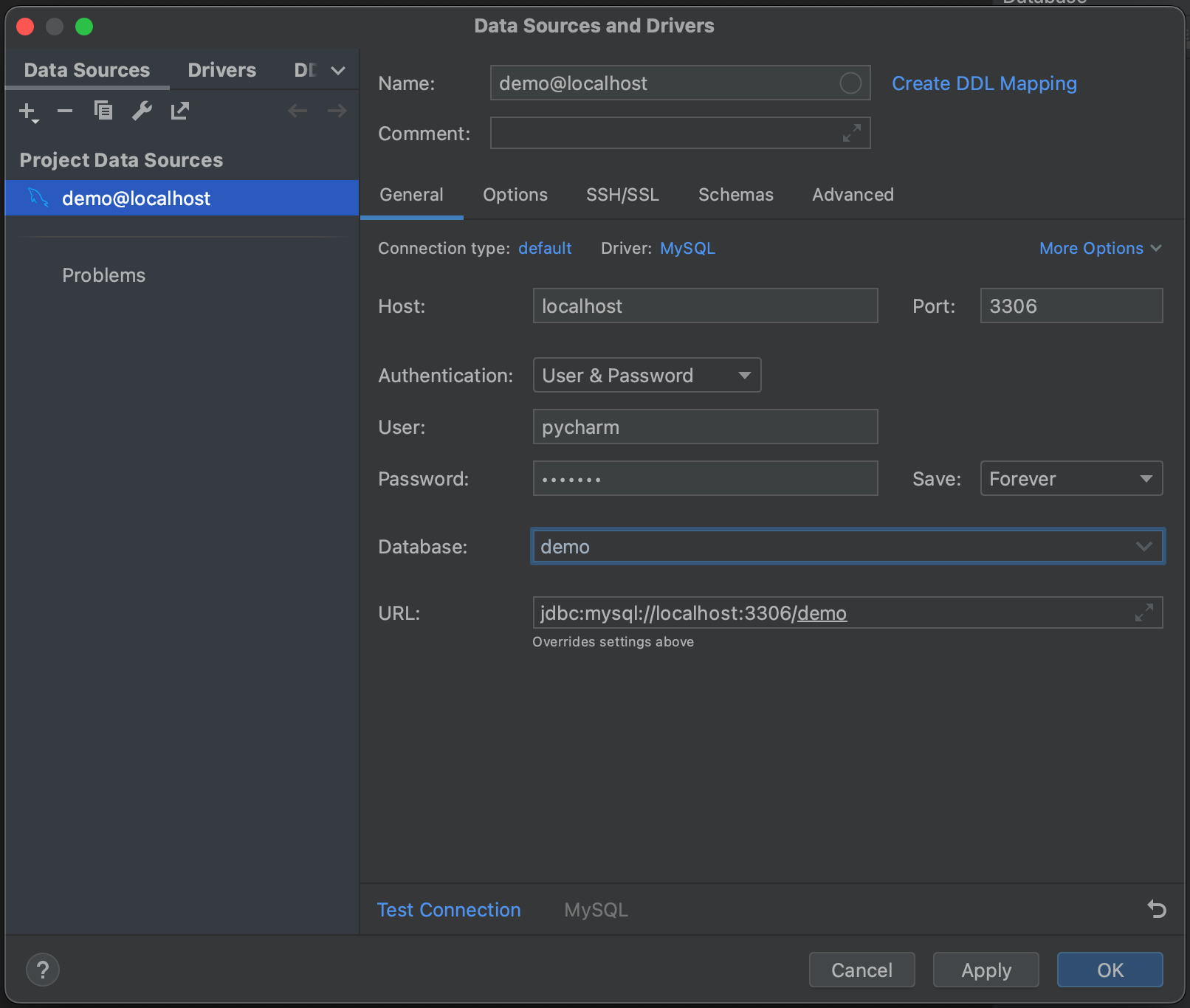
接下来,点击 Test Connection(测试连接)。 PyCharm 提示我们没有安装驱动程序文件。 继续,点击 Download Driver Files(下载驱动程序文件)。 Database(数据库)工具窗口一个非常好的功能是,它会自动为我们找到并安装正确的驱动程序。
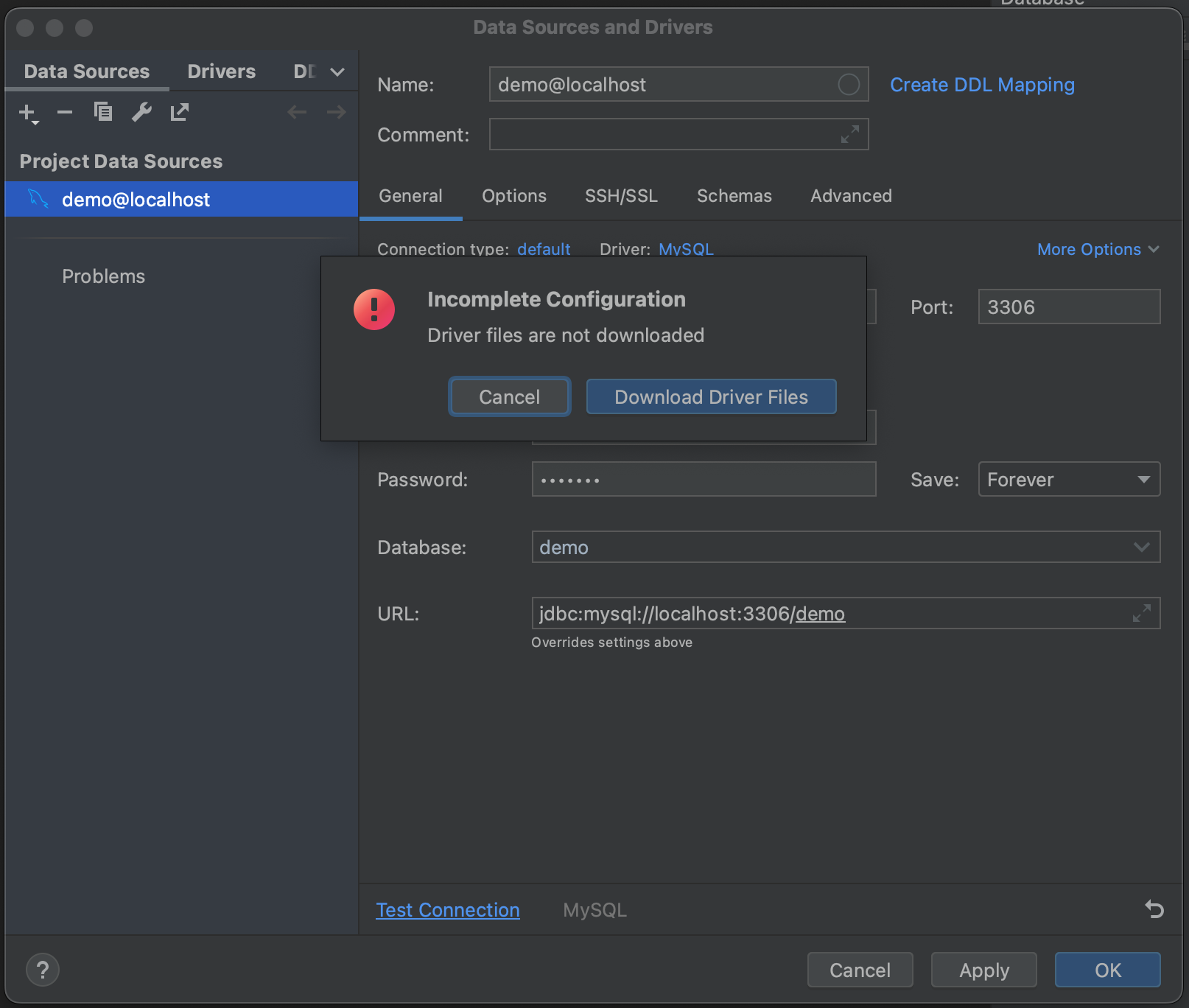
成功! 我们已经连接到我们的数据库。 我们现在可以导航到 Schemas(架构)选项卡,并选择我们想要内省的架构。 在我们的示例数据库中,我们只有一个(“demo”),但在您有非常大的数据库的情况下,可以通过只内省相关数据库来节省时间。
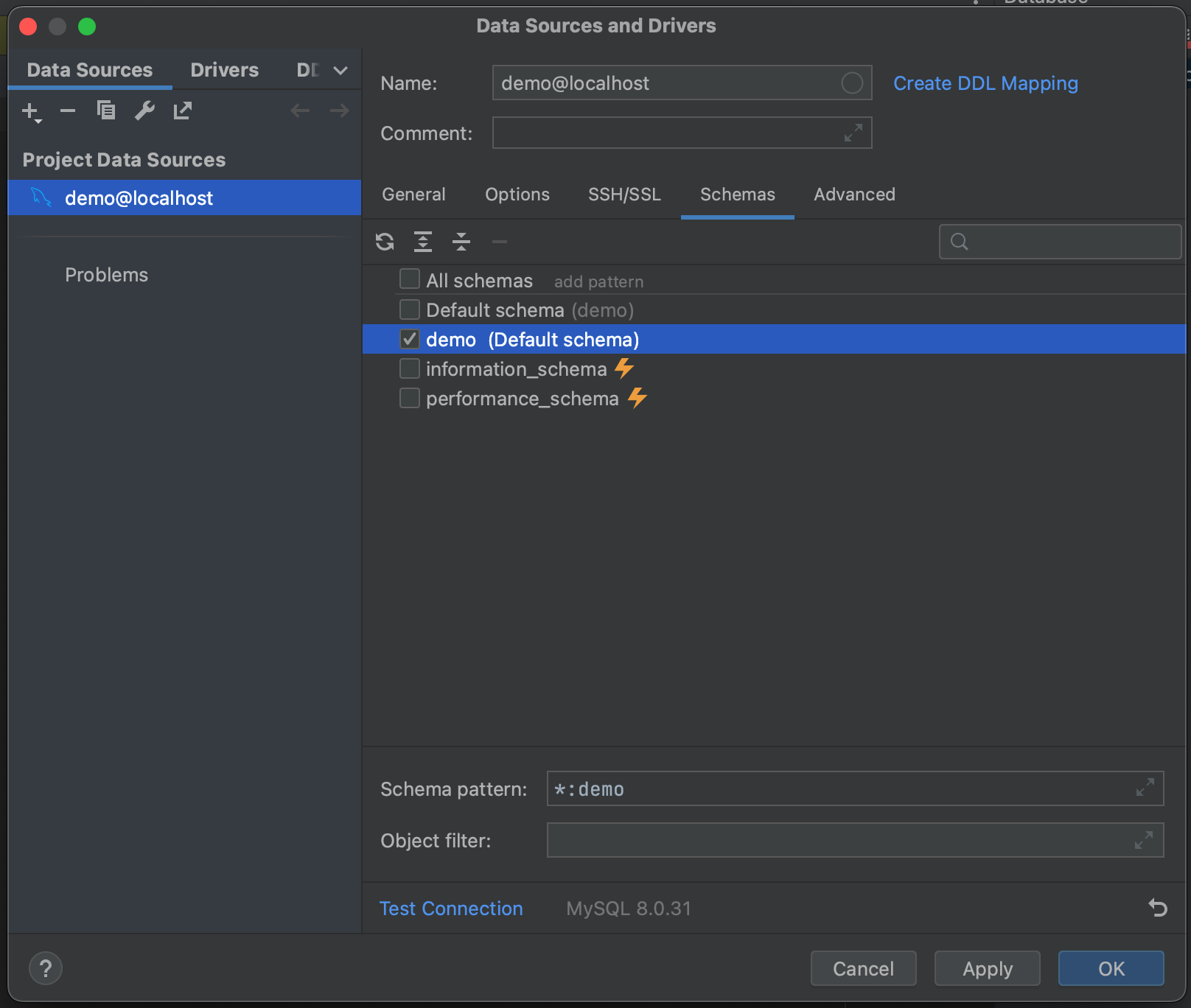
所有这些都完成后,我们就可以连接到我们的数据库了。 点击 OK(确定),然后等待几秒钟。 现在可以看到,我们的整个数据库已被内省,直到表字段级别及其类型。 这使我们在运行查询之前就能对数据库中的内容有一个很好的了解。
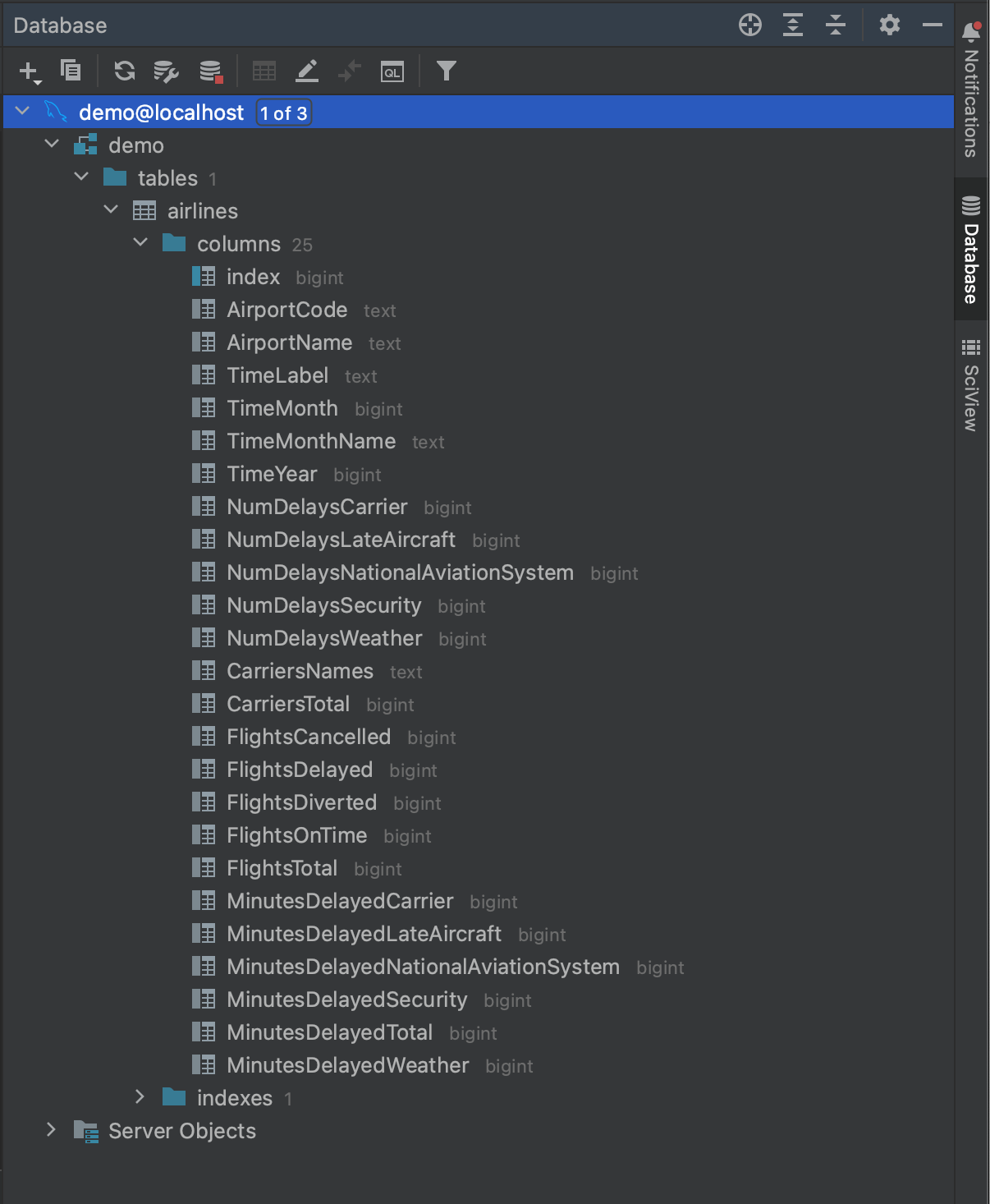
使用 MySQL Connector 读入数据
现在,我们已经知道数据库中的内容,可以准备进行查询了。 假设我们想要查看 2016 年至少有 500 次延误的机场。 通过查看内省的 airlines 表中的字段,我们看到我们可以通过以下查询获得这些数据:
SELECT AirportCode,
SUM(FlightsDelayed) AS TotalDelayed
FROM airlines
WHERE TimeYear = 2016
GROUP BY AirportCode
HAVING SUM(FlightsDelayed) > 500;
我们使用 Python 运行这个查询的第一种方式是使用一个叫作 MySQL Connector 的软件包,它可以从 PyPI 或 Anaconda 安装。 如果需要关于设置 pip 或 conda 环境或安装依赖项的指导,请参阅链接的文档。 一旦安装完成,我们将打开一个新的 Jupyter Notebook 并导入 MySQL Connector 和 pandas。
import mysql.connector import pandas as pd
为了从我们的数据库中读取数据,我们需要创建一个连接器。 这是通过 connect 方法完成的,我们向该方法传递访问数据库所需的凭据:host、database 名称、user 和 password。 这些是我们在上一节中使用 Database(数据库)工具窗口访问数据库时使用的相同凭据。
mysql_db_connector = mysql.connector.connect( host="localhost", database="demo", user="pycharm", password="pycharm" )
我们现在需要创建一个游标。 这将用于执行我们对数据库的 SQL 查询,它使用在我们的连接器中存储的凭据来获得访问权限。
mysql_db_cursor = mysql_db_connector.cursor()
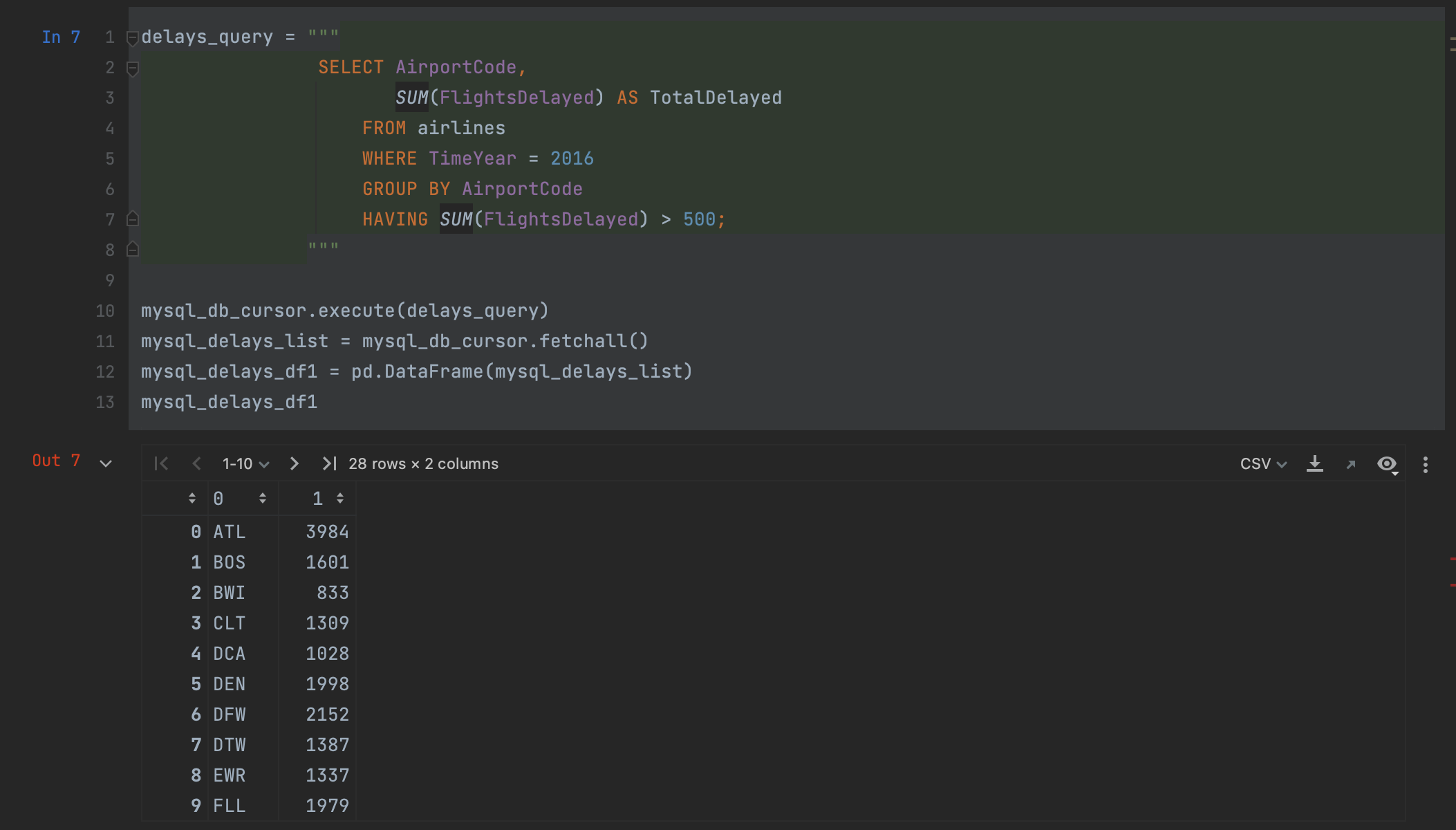
我们现在可以执行查询了。 我们使用游标中的 execute 方法来执行查询,并将查询作为实参传递。
delays_query = """
SELECT AirportCode,
SUM(FlightsDelayed) AS TotalDelayed
FROM airlines
WHERE TimeYear = 2016
GROUP BY AirportCode
HAVING SUM(FlightsDelayed) > 500;
"""
mysql_db_cursor.execute(delays_query)
然后,我们使用游标的 fetchall 方法检索结果。
mysql_delays_list = mysql_db_cursor.fetchall()
不过,在这一点上我们有一个问题:fetchall 以列表形式返回数据。 为了将其读入 pandas,我们可以将其传入一个 DataFrame,但是我们会失去列名。如果我们想要创建 DataFrame,则需要手动指定列名。
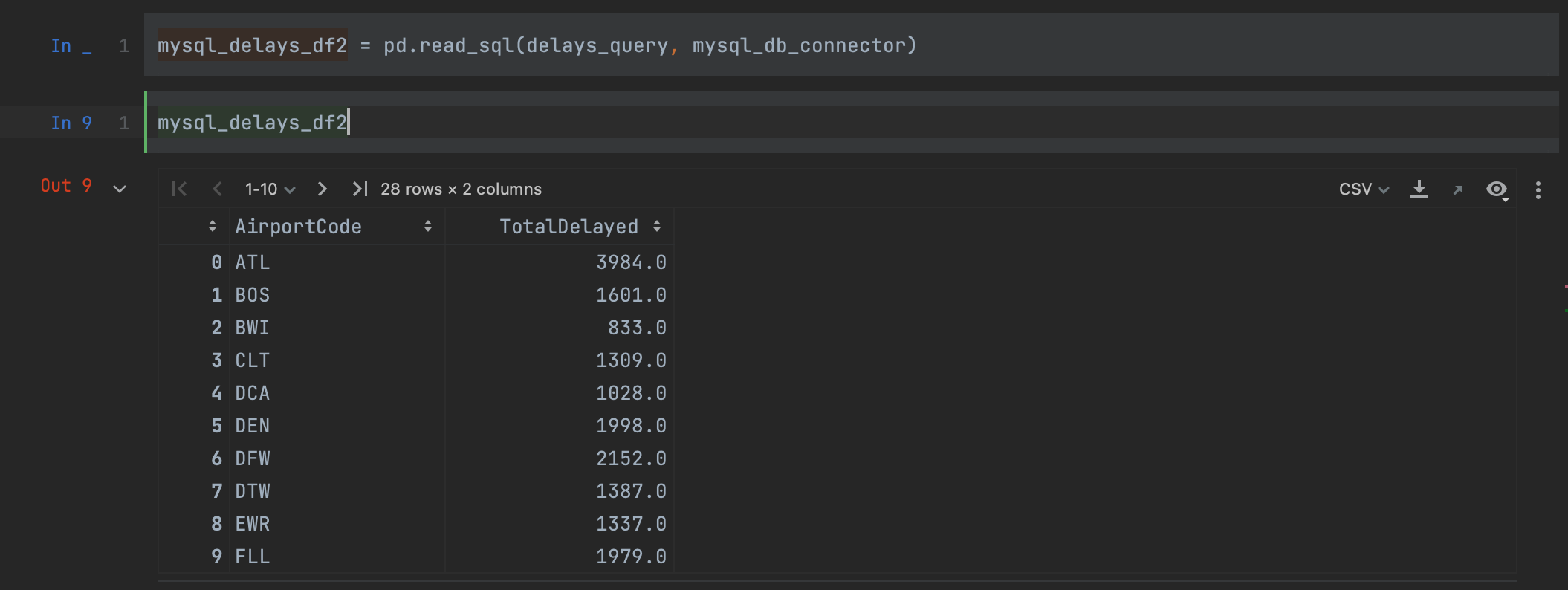
幸好,pandas 提供了一种更好的方式。 我们可以使用 read_sql 方法,一步将我们的查询读入一个 DataFrame,不需要创建游标。
mysql_delays_df2 = pd.read_sql(delays_query, con=mysql_db_connector)
我们只需要将我们的查询和连接器作为实参传递,以便从 MySQL 数据库中读取数据。 查看我们的 DataFrame,我们可以看到我们获得了与上面完全一样的结果,但这次列名被保留了。
您可能已经注意到 PyCharm 有一个不错的功能,这个功能可以将语法高亮显示应用于 SQL 查询,即使查询包含在 Python 字符串中也可以。 稍后在本博文中,我们将介绍 PyCharm 允许您使用 SQL 的另一种方式。
使用 SQLAlchemy 读入数据
使用 MySQL Connector 的另一种方式是使用一个叫作 SQLAlchemy 的软件包。 这个软件包提供了一种一站式方式,可以连接到包括 MySQL 在内的一系列不同的数据库。 使用 SQLAlchemy 的一个好处是,查询不同数据库类型的语法在不同的数据库类型中保持一致。如果您正在使用大量不同的数据库,无需记住一堆不同的命令。
首先,我们需要从 PyPI 或 Anaconda 安装 SQLAlchemy。 然后,我们导入 create_engine 方法,当然还有 pandas。
import pandas as pd from sqlalchemy import create_engine
我们现在需要创建我们的引擎。 这个引擎允许我们告知 pandas 我们使用的是哪种 SQL 方言(在我们的示例中为 MySQL),并向其提供访问我们的数据库所需的凭据。 这些都以一个字符串的形式传递,即 [dialect]://[user]:[password]@[host]/[database]。 我们来看看这对我们的 MySQL 数据库来说是什么样子:
mysql_engine = create_engine("mysql+mysqlconnector://pycharm:pycharm@localhost/demo")
创建引擎后,我们只需要再次使用 read_sql,这次将引擎传递给 con 实参:
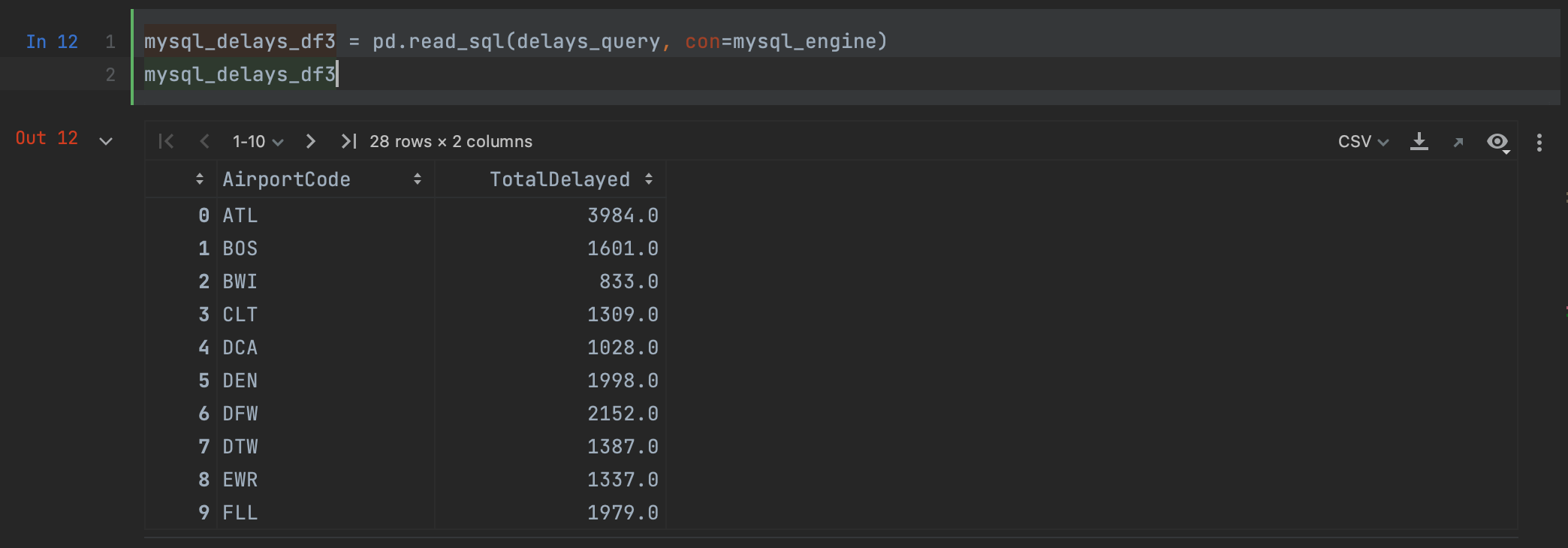
mysql_delays_df3 = pd.read_sql(delays_query, con=mysql_engine)
如您所见,我们得到的结果与在 MySQL Connector 中使用 read_sql 时相同。
使用数据库的高级选项
现在,这些连接器方法对于提取我们已经知道自己想要的查询非常好用,但是如果我们想在运行完整查询之前预览我们的数据会是什么样子,或者想知道整个查询会花多长时间,该怎么办? 又到了 PyCharm 大显身手的时候了,它提供了一些使用数据库的高级功能。
如果我们回到 Database(数据库)工具窗口,右键点击我们的数据库,我们可以看到在 New(新建)下,我们可以创建一个 Query Console(查询控制台)。
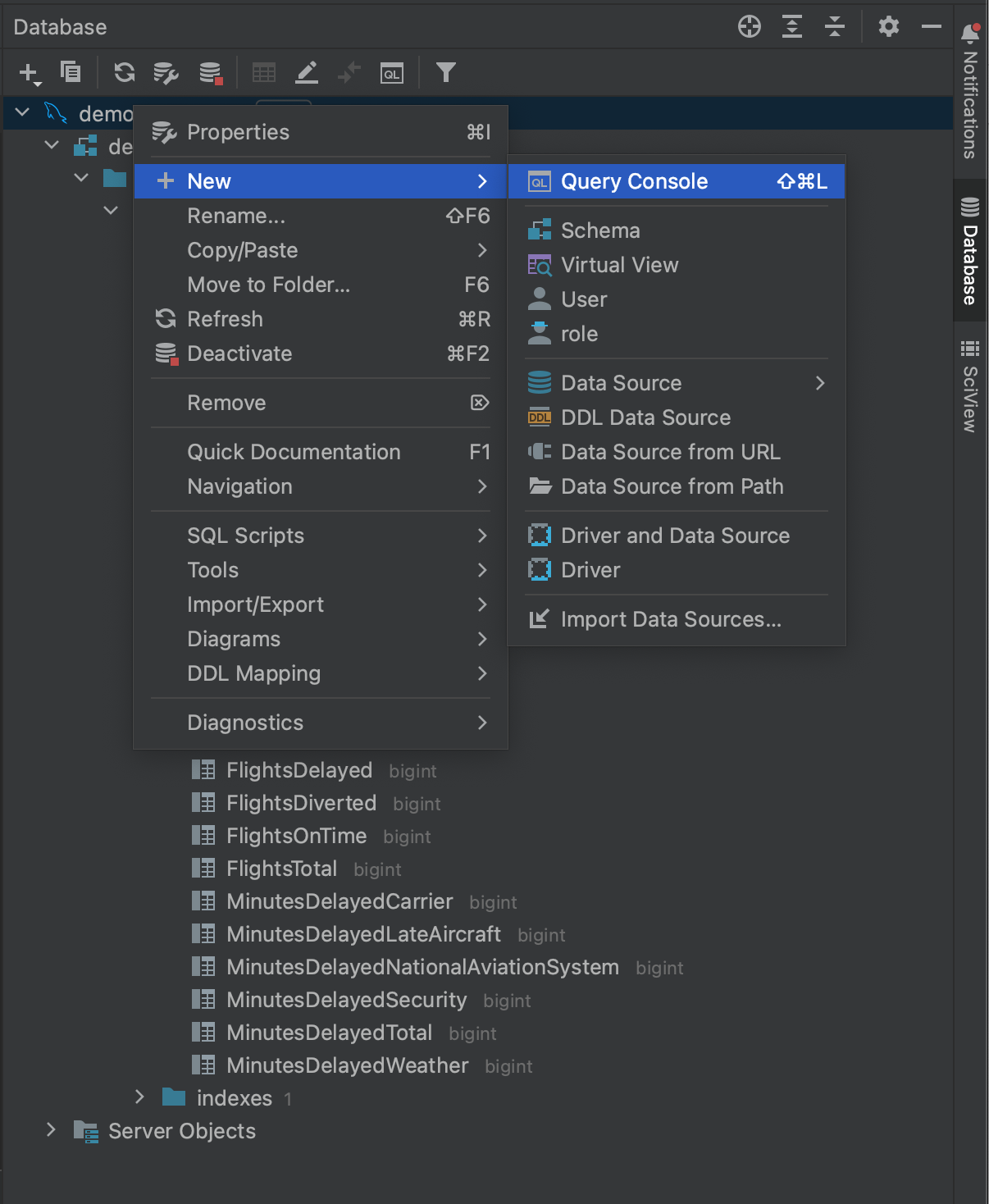
这允许我们打开一个控制台,我们可以用它在原生 SQL 中对数据库进行查询。 控制台窗口包括 SQL 代码补全和内省,这样,您可以更轻松地创建查询,然后再将查询传递给 Python 中的连接器软件包。
高亮显示您的查询,并点击左上角的 Execute(执行)按钮。
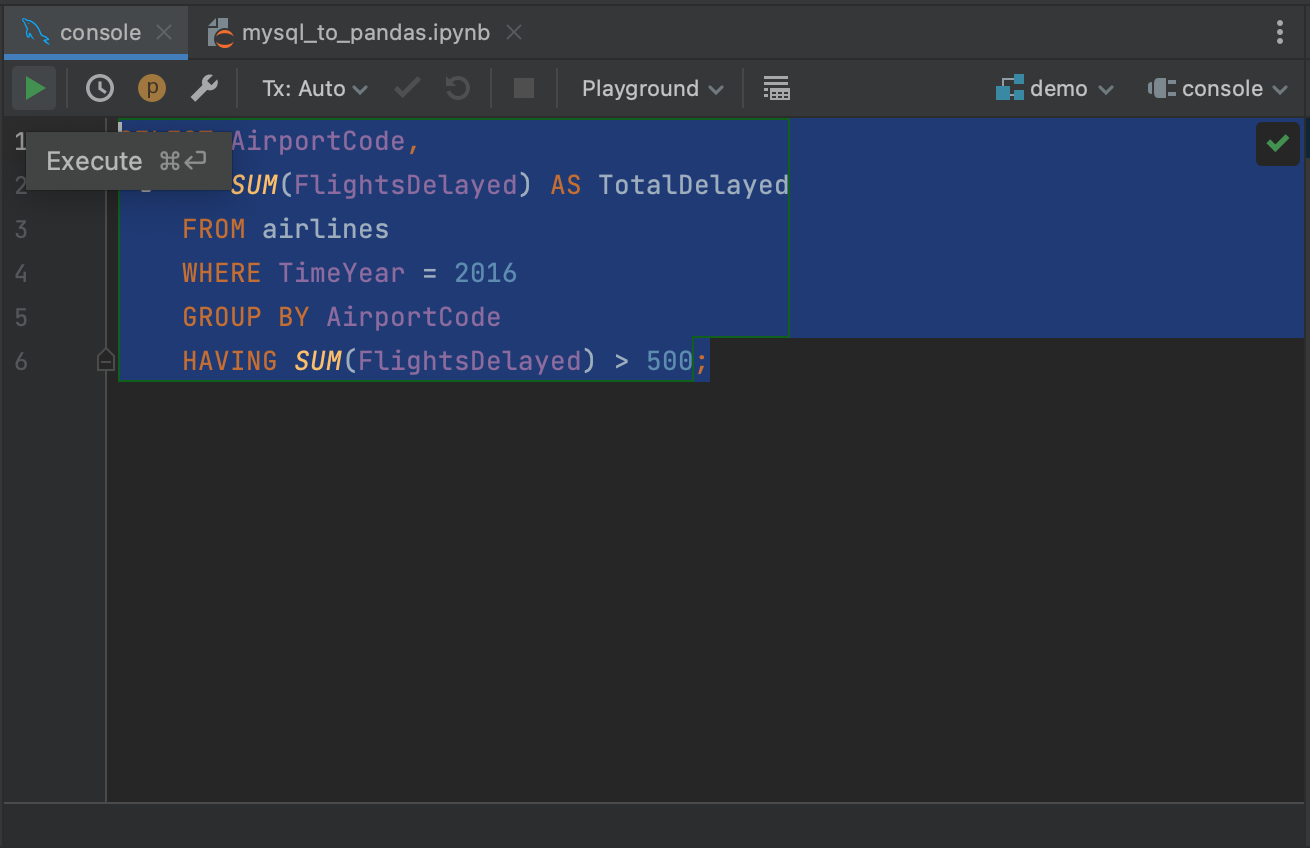
这将在 Services(服务)选项卡中检索我们查询的结果,您可以从这个选项卡检查或导出查询。 对控制台运行查询的一个好处是,最初只从数据库中检索前 500 行,这意味着您可以了解大型查询的结果,而不必提取所有数据。 您可以调整检索的行数:转到 Settings/Preferences | Tools | Database | Data Editor and Viewer(设置/偏好设置 | 工具 | 数据库 | 数据编辑和查看器),并更改 Limit page size to:(将页面大小限制为:)下的值。
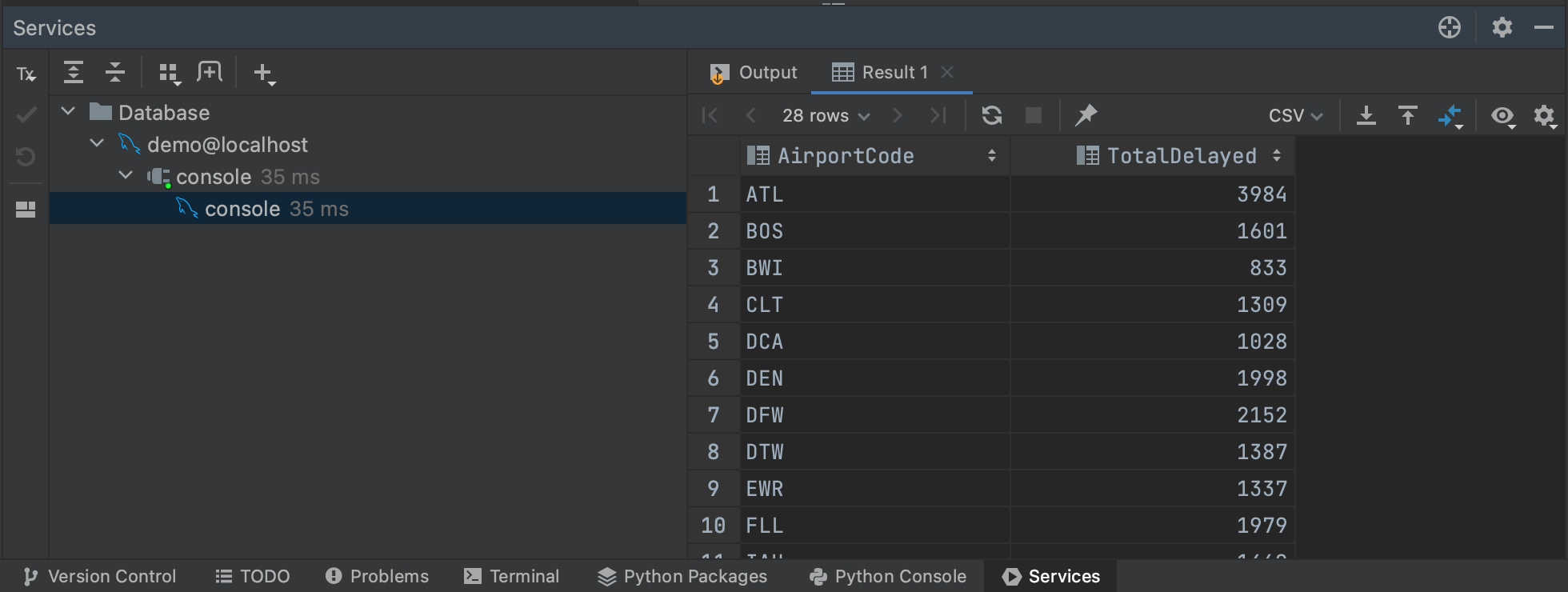
说到大型查询,我们也可以通过生成一个执行计划来了解我们的查询将需要多长时间。 如果我们再次高亮显示我们的查询,然后点击右键,我们可以从菜单中选择 Explain Plan | Explain Analyse。 这将为我们的查询生成一个执行计划,显示查询计划器为检索结果所采取的每一个步骤。 执行计划是它们自己的主题,我们并不需要了解我们的计划所告诉我们的一切。 与我们的目的最相关的是 Actual Total Time(实际总时间)列,在这里我们可以看到在每个步骤中返回所有行需要多长时间。 这让我们能够对整个查询时间有一个很好的估计,以及预判我们查询的任何部分是否可能特别耗时。
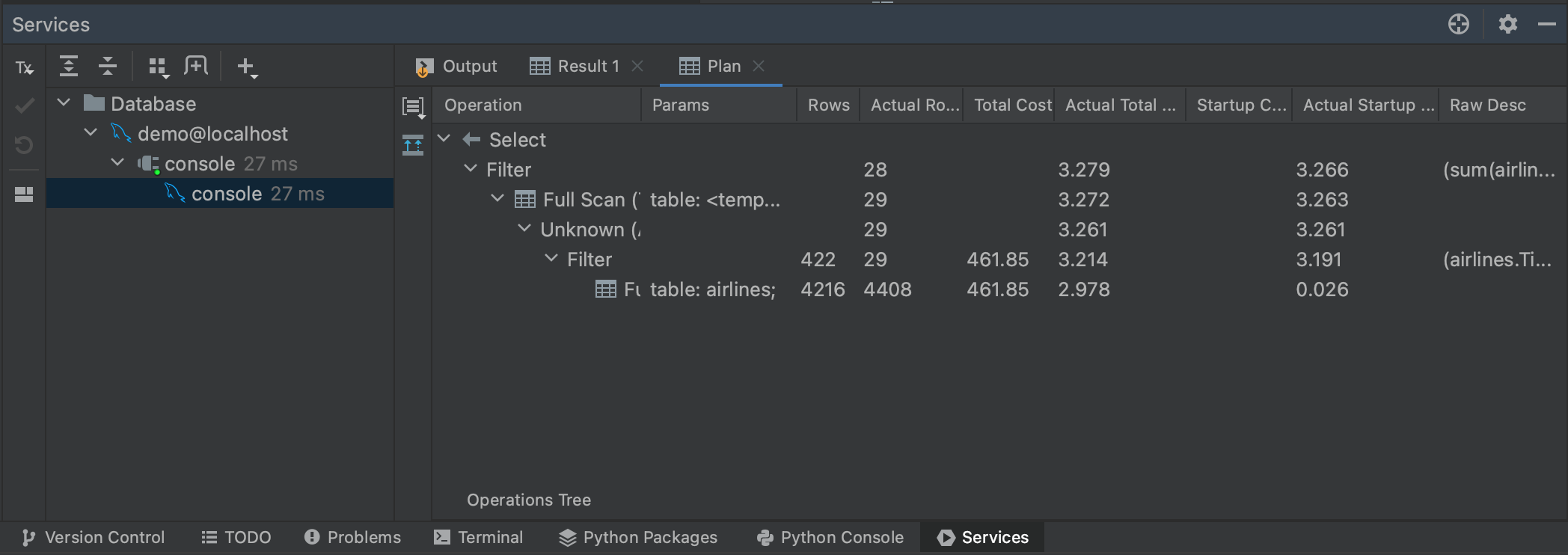
您也可以通过点击 Plan(计划)面板左侧的 Show Visualization(显示可视化)按钮来可视化执行。
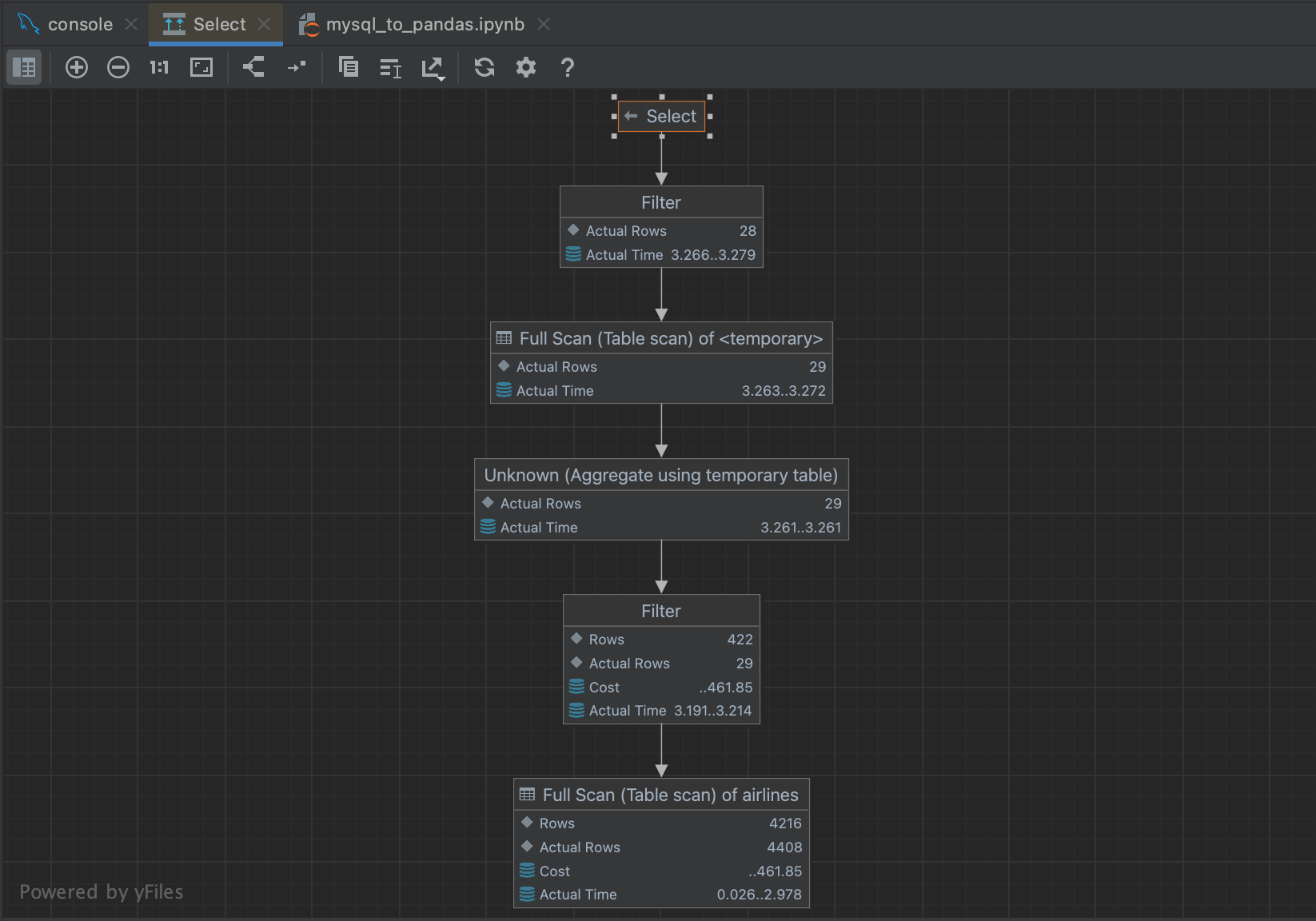
这将弹出一个流程图,让您更轻松浏览查询计划器正在进行的步骤。
将数据从 MySQL 数据库中读入 pandas DataFrames 非常简单。PyCharm 提供了很多强大的工具来让使用 MySQL 数据库变得更简单。 在下一篇博文中,我们将了解如何使用 PyCharm 将数据从另一种流行的数据库类型 – PostgreSQL 数据库 – 读入 pandas。
本博文英文原作者:





