

代码生成中的 BeamSearch

在上一篇专门讨论整行代码补全的文章中,我们探讨了整行补全插件的神经网络用于 Python 的词汇表。 然而,仅仅 16384 个词例,如 self.、or、s.append(、return value 和文章中描述的其他词例,甚至不足以生成一行。 我们需要一种能够将这些词例组合起来编写代码块的方式。 本文将讨论算法如何使用词汇表的元素构造更长的短语。
首先是自回归。
自回归
文本(和代码)生成基于多个概念,自回归是其中之一。 机器学习算法将现有文本或其中的一部分作为输入,预测词汇表中各个词例成为文本中下一个词例的概率。
这些概率的预测由基于 Transformer 的神经网络模型完成。 在本文中,我们将把这个模型视为一个黑盒,它会接收一系列词例并返回下一个可能词例的概率。 许多关于神经网络 Transformer 运作方式的文章都解释了这个黑盒的内部原理。 例如,有关 Transformer 的原始研究论文或专门针对 GPT-2 的插图说明。
本文不涉及 Transformer 的实现细节。 我们将探讨的是获得概率后算法的作用。
我们可以取最可能的词例,将其作为下一次推断迭代的上下文的一部分反馈给算法。 这使我们能够预测序列中的第二个词例,我们可以再次将其用作上下文的一部分。 因此,只有第一次迭代使用用户提供的输入,所有后续迭代都将输入与前面步骤的结果相结合。
首先,在人工自然语言示例上运行这些步骤。 William Blake 的“The Tyger”将是我们用来预测的文本:

此示例说明自回归过程可能是无限的。 在文本末尾添加更多词例,再将上下文窗口向前移动,达到了原始文本的任何部分都没有用作输入的情况。
在实际应用中,输入很少是训练集中元素的重复。 这意味着不那么清晰的输出,并且生成有意义的长文本的尝试会导致质量远低于 Blake 的诗。
好在我们的直接任务是只生成一小段代码,因此过程默认为五次迭代而不是无限次。 我们的模型最多需要 384 个上下文词例,因此在生成这五个新词例时,不会出现丢失原始输入的风险。
结果多样性和计算复杂性
直接的自回归有一个问题:它只生成一个词例链。 当模型高度自信并且除顶部结果之外的所有结果的组合概率可以忽略不计时,这可能还好。 “The Tyger”就是这种情况,在学校里背过这首诗的人都会立即想到下一个单词。
在实践中,许多延续通常是可能的,因此我们想要探索大量的选项。 这就是指数复杂性发挥作用的地方。 我们的词汇表包含 214 == 16384 个词例,算法提供了每个词例的概率。 下一步,考虑到两个词例的组合,我们有了 214 * 214 == 228 个选项。 要“写”一个由五个词例组成的序列,我们需要从 270 个变体中进行选择,这显然不现实。 搜索树的分支太多,无法完全遍历。
我们需要想办法进行宽度优先搜索,也要限制我们在树的每一层上花费的计算能力。 有几种可能的解决方案,其中一个是核采样 (Nucleus Sampling)。 不过,我们选择的是 BeamSearch 算法。 顾名思义,我们使用固定宽度的类激光光束探索领域。
这基本意味着在树的每个级别上选择固定数量的分支进行进一步探索。 我们只留下目前看起来最有可能的分支并切断其他所有内容。 来看看它是如何与 Python 词例一起工作的。
BeamSearch
假设我们开始实现一个 Python 函数来计算第 n 个斐波那契数。 我们使用的示例可能不是 AI 能力的最鲜明展示,但它能够表现我们在取自神经网络的难以解释的概率结果之上进行的构建。 首先是检查输入值是否为负并抛出异常(引发错误)。 运作方式如下:
n = int(input())
def fib(n):
if n < 0:
rai| <- caret here为了了解算法如何构成其建议,我们将使用插件开发者在调试模式下可用的信息。
我们的光束有六个项宽,这意味着算法在每一步仅选择六个最可能的词例组合。 我们将它们绘制为图表。 行宽将表示迭代中延续的相对概率。
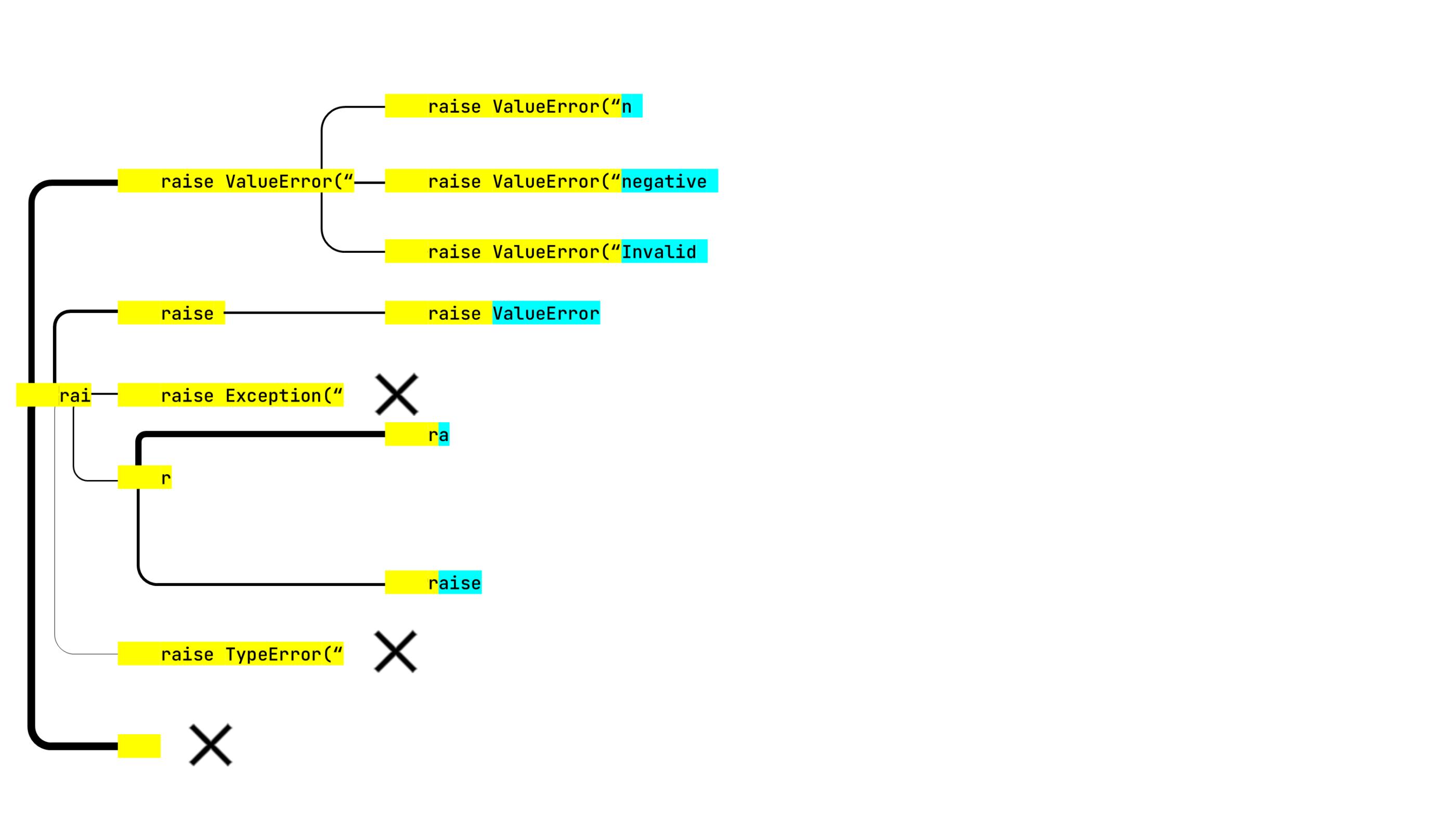
算法的第一步给出了以下结果:

r 和底部的空黄色矩形,它的概率最高。这是什么?
用户会在代码中的任何地方调用补全窗口,我们需要找到表示前缀的最佳方式,即用词汇表词例来表示行开始和调用位置之间的序列。 有时算法可以用它考虑的第一个词例覆盖整个前缀,但有时需要两个或更多词例。
我们想继续由两个缩进和 rai 组成的行。 所以上面提到的两个奇怪的项试图从缩进+缩进+ r 或者缩进+缩进开始,这两个都是词汇表中的词例。
到现在为止都没问题。 继续下一步。 我们将在黄色和浅蓝色之间来回切换,高亮显示用于构成建议的词例:
- 有许多以缩进+缩进开头的选项,因此在第一次迭代时延续的可能性很高。 但是,这些选项中没有一个单独看起来足以击败从其他起始词例构建的延续。 所以搜索停止探索这一行,我们用叉号标记,并带上其他两个选项。
- 有时较长的字符串可以用一个词例来表示,而它的子字符串需要两个或更多词例。 在这里,我们从上一步获得了 raise ValueError(“,但 raise ValueError 直到当前步骤才可用。
- 错误消息文本看起来都非常有希望。 然而,下一步就全错了:
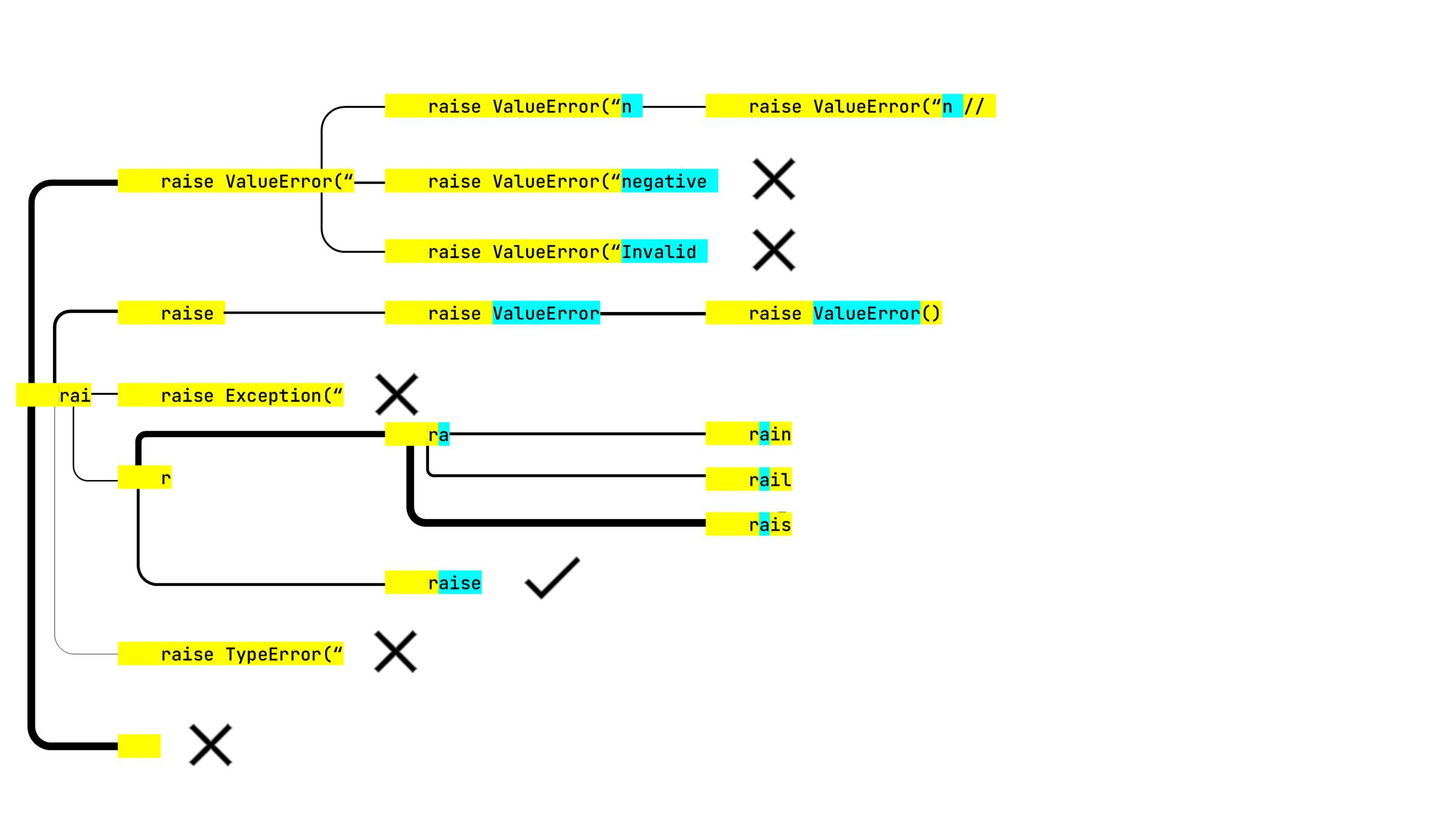
这两件事是相关的。算法注意到
raise 是一个词法正确的块,因此它可以停止探索这一行。此分析计入每个步骤的六个项。因此,另外只有五个选项。然而,我们在这一步也丢失了所有有希望的错误消息,但是另一个树分支生成了 raise ValueError(),这是次优的。 我们还有两个步骤可以探索其他概率。 Rail? Rain? Rais? 我们来看看。
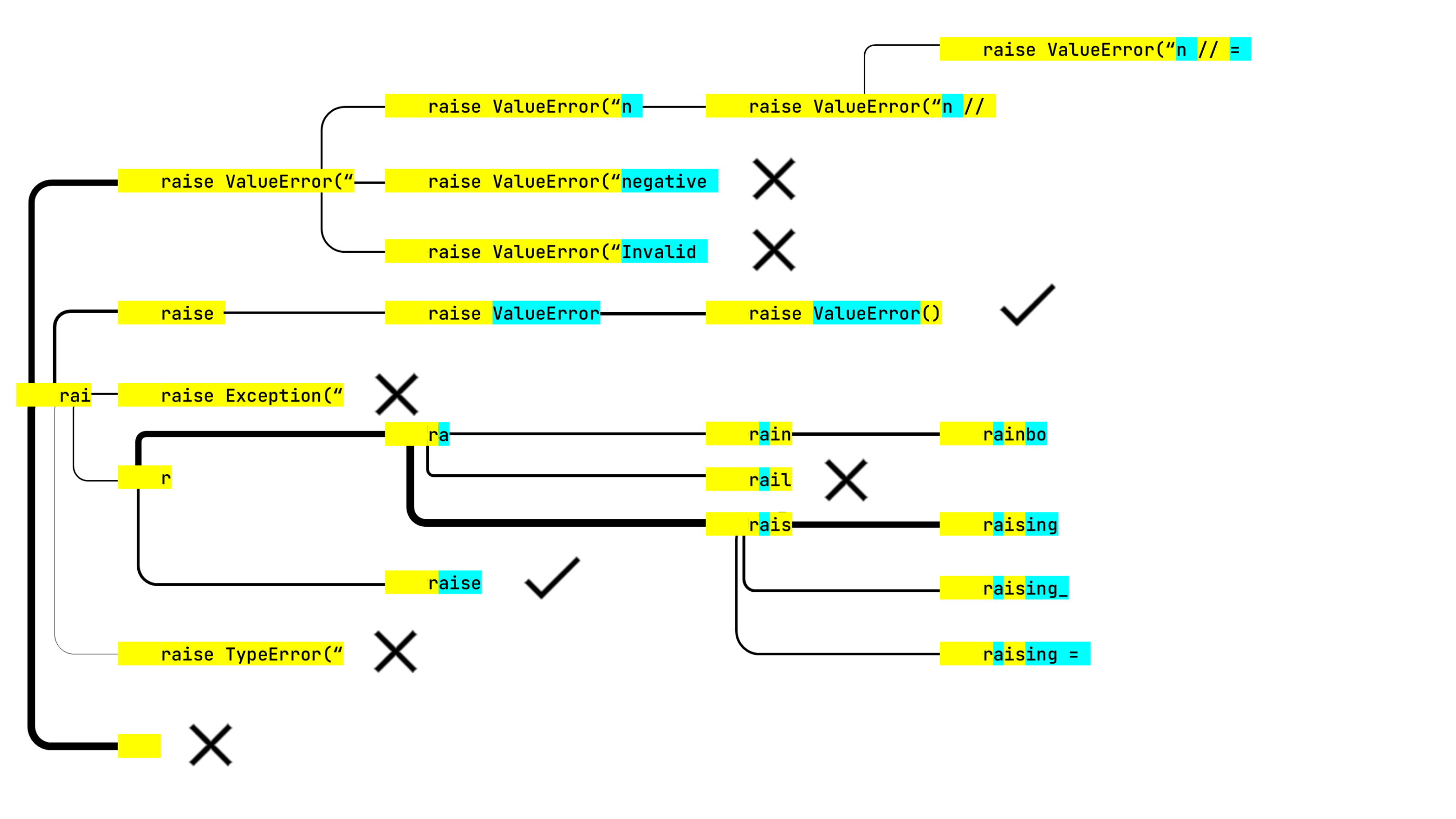
raise ValueError(“n // 是一个明显的死胡同,但神经网络却不这么认为,并继续构建这一行。从好的方面来说,
raise ValueError() 被选中了。算法有五行要在最后一步中分析。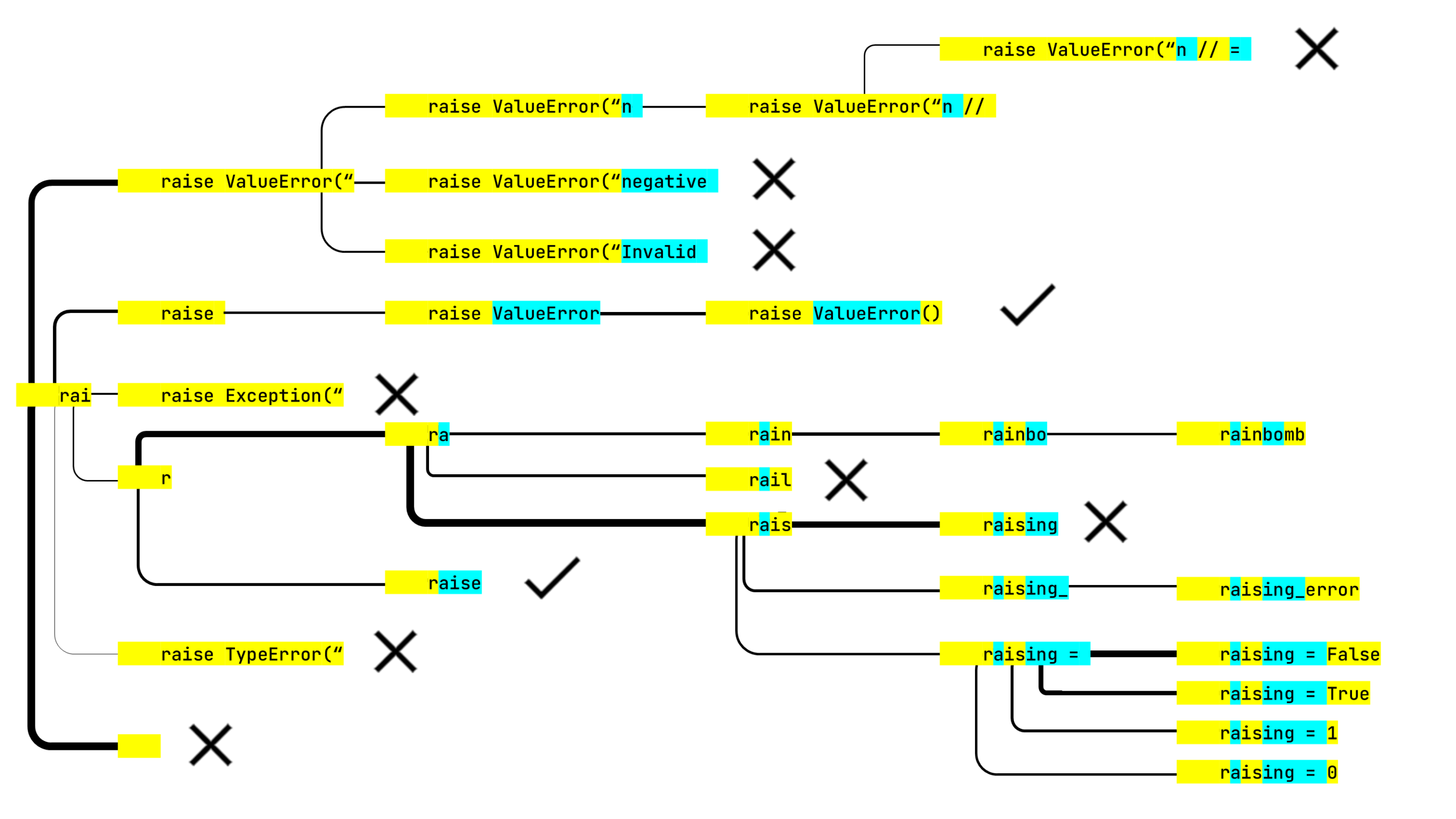
rainbo 会导向 rainbow。没人能想到结果会是
rainbomb。幸运的是,算法并没有认为这个选项的可能性足够向用户展示(本文读者除外)。在生成所有可能的建议后,算法会按概率对其排序。 在不久的将来,我们计划开始增强目标编程语言的词法完整结构,使中括号平衡并且关键字不会被拆分。
但是,我们不想完全禁止部分不正确的建议。 它们可能只是稍微不正确,让用户接受并继续编辑可能是有益的。
用于编写此说明的特定弹出窗口包含以下内容(如果您运行的是相同的代码,您看到的内容可能会有所不同,主要取决于可用的处理器资源):
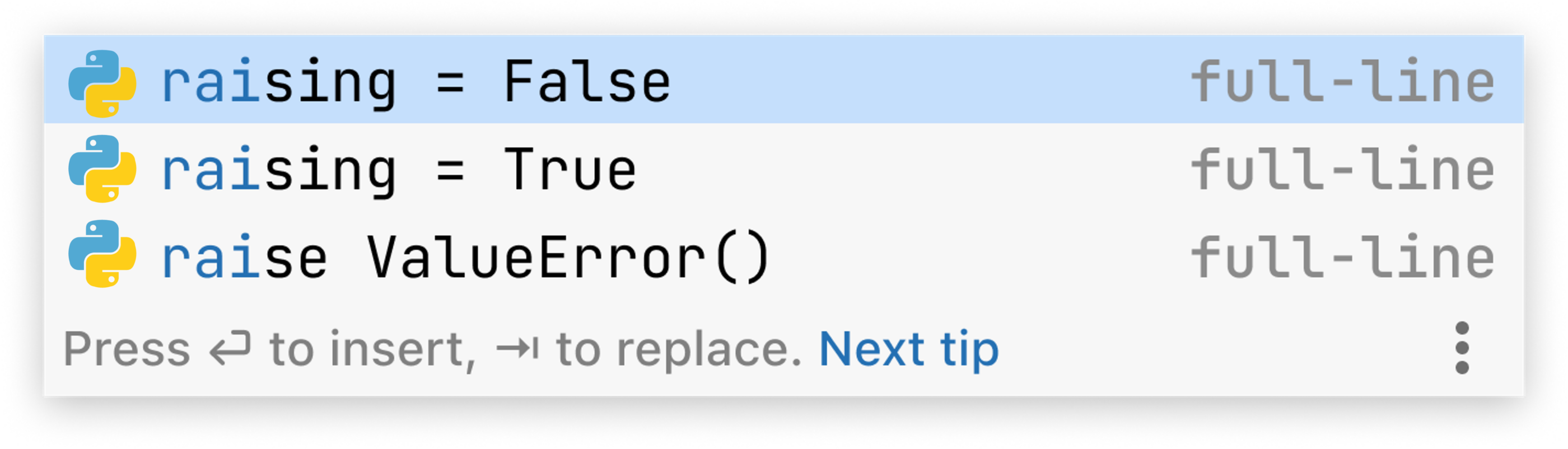
这看起来可能不是全面的成功,但对于实现 fib(n) 函数的开发者来说仍然是一个有用的结果。
BeamSearch 算法是一种相当简单的方式,可以限制树或图表中的宽度优先搜索的计算复杂度。 同时,它确保了结果之间一定程度的多样性。
为了进一步改进整行补全…
…我们需要用户提供更多反馈。 请试用 Python 的整行代码补全插件,把您的想法告诉我们。
本博文英文原作者:

