

.NET Tools
Essential productivity kit for .NET and game developers
我们如何使用 dotMemory 优化 dotMemory

dotMemory 是 JetBrains 推出的一款 .NET 内存分析器。 我是 Ilya,我协助开发工具。
我要讲一个经典的内部测试故事,在故事里我们用自己的工具 dotMemory 和 dotTrace 优化了 dotMemory 的一种算法。 我们还使用 dotTrace 对其进行了更多改进,并使用 BenchmarkDotNet 完成了优化过程。
我要感谢 1 和 2 这两篇文章的作者,他们启发了我分享这个故事。
最开始,一位同事在 Slack 中给我发送消息,告诉我他在 dotMemory 的支配树上遇到了问题。 树的数据计算时间太长了,他实在等不到进程结束。 好在问题是内部的,我们收集内存快照并展开了调查。
在本地机器上重现问题时,我们发现内存使用以每秒 1.17 GB 的速度快速增长,迫使进程开始使用交换文件。 发生这种情况通常就意味着无法在合理的时间范围内收到结果。 接下来,该用 dotMemory 解决 dotMemory 中的问题了。
进程完全耗尽物理内存后,快照会难以捕获, 甚至操作系统也不再稳定。因此,我们决定在内存使用开始快速增长时捕获快照,但物理内存还有一些剩余。 dotMemory 控制台分析器是完成这项工作的最佳工具:

此命令以分析模式启动 dotMemory.UI.64.exe。 它会在“private bytes”量达到 20 GB 时立即捕获快照,并在分析完成后在 dotMemory 中打开快照。 在我们的情况中,我们不得不手动停止分析(否则我们最终会再次交换)。 我们一直等到数据足够,然后按 Ctrl+C。
现在有了快照,我们在 dotMemory 中将其打开。 首先,分析支配树 – 我的同事无法获得的支配树,我在快照中得到了:

内存中充斥着大约 6000 万个 CompactDominatorTreeNode+Builder 对象,每个对象都包含一个字典。 显然,对于大多数字典来说,大小 < 容量,这意味着大量内存被浪费了。
我们必须看看这些字典的用途,也许我们不需要这么多? 我选择了 CompactDominatorTreeNode+Builder 节点并导航到它的声明(使用上下文菜单或按 Ctrl+L)。 这将我导航到我的 IDE (Rider) 并打开了相应的类。 运行 Find Usages(查找用法)将我带到了 CompactDominatorTree.Build 方法,其中包含支配树压缩算法。
介绍一点背景:首先,dotMemory 构建一个支配树,如下所示。 对于每个对象,它会搜索专门保留它的对象并保存该保留对象,如果没有,则保存表示缺少此类保留对象的标记。 树可能会变得非常大,没有必要“按原样”向用户展示。 因此,dotMemory 在树的每一级按对象类型对树节点进行分组。 CompactDominatorTreeNode+Builder 表示正在构建的紧凑(压缩)树的节点,字典用于按类型对节点进行分组。
算法以“下级→上级”格式接收树,每个对象都与其支配上级匹配。 它按顺序遍历快照中的所有对象。 每有一个支配上级尚未被处理的对象,紧凑树中就会创建一个新的组节点。 当前节点成为组节点中的下级节点(现有节点或新创建的节点)。
使用这种方法,树以任意顺序遍历,每个节点都必须存储一个字典,字典按类型对节点进行分组。 在大多数情况下,这都不是问题,因为紧凑树比包含所有对象的树要小得多,并且没有显著的内存过度使用。 但是这个快照属于极端情况,因为即使是紧凑的树也很大。
现在的问题是,“我们怎样才能使用更少的字典?”,如果我们只有一个带组合键的字典,该怎么办? 这将迫使我们必须执行分解,再次导致内存过度使用或更复杂的计算。 我们不得不考虑其他方案。
我们退后一步,更全面地分析问题。 使用不同的方式遍历树如何?比如广度优先搜索? 这种方式看起来很可行。 一个具有常规键的字典就足够了。 这样,每当我们构建完成紧凑树的新级别,我们都会清除字典,从而可以在下一次迭代中重用它。
不过注意:“下级→上级”格式不适合广度优先搜索,因为检索给定节点的下级节点的计算开销过大。 我们需要不同的输入树格式。 好在我们已经有了一个备选方案:dotMemory 也能将支配树存储为“上级→下级”邻接列表。 这意味着,我们可以在不增加计算复杂性的情况下更改算法以使用广度优先搜索。
我们进行了相应编辑并运行。 我们看到内存使用的增长速度比以前慢得多,从每秒 1.17 GB 变为仅仅每秒 7 MB,但该进程仍然未能完成而且再次开始使用交换文件。
我们回到绘图板。 我们捕获了另一个快照并将其打开。 新的支配树看起来像这样:

这次仅紧凑树就占用了 16 GB。 这个大小合理吗? 也许我们还可以用更经济的方式存储这棵树?
我们按类型对节点进行分组以查找我们有多少个节点:
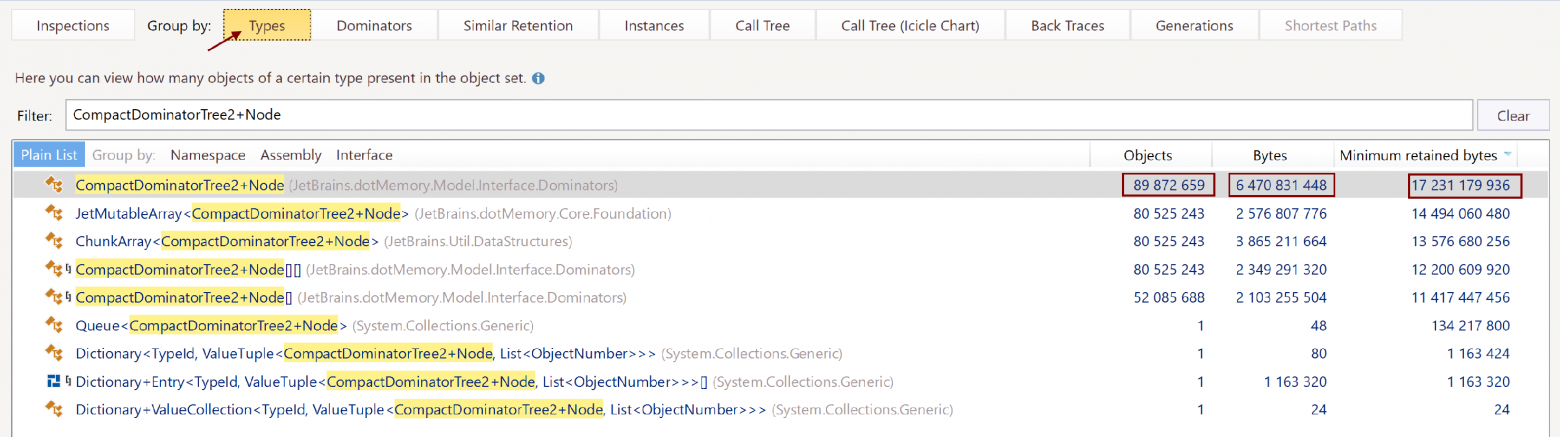
在 16 GB 的总大小中,树的 9000 万个节点仅占用 6 GB。 这有些可疑。 我们导航到 CompactDominatorTree2+Node 声明的代码:
public sealed class Node
{
public DfsNumber DfsNumber { get; } // 8 bytes
public TypeId ObjectsType { get; } // 4 bytes
public int ObjectsCount { get; } // 4 bytes
public int RetainedObjectsCount { get; } // 4 bytes
public ulong RetainedBytes { get; } // 8 bytes
public bool IsContainedInSet { get; } // 1 byte
public Node Parent { get; } // 8 bytes
internal JetArray<Node> ChildrenImpl { get; } // 8 bytes
// we have omitted unnecessary details
}
这里的有效负载只有 45 字节,但加上标题和对齐,一个 Node 对象就占用了 72 字节。 它保留的更多,平均 192 字节。 为了查看详细信息,我们切换到 Instances(实例)选项卡,使用查询 CompactDominatorTree2+Node !g !a 筛选内容(!g 排除泛型,!a 排除数组)。 这是一个随机实例:

实例详情:

这可是好些开销。
现在,我们可以清楚地看到 JetMutableArray 并不是为大型树存储下级节点的最有效方式。 我们想到的第一个解决方案当然是优化下级节点的存储。 例如,我们可以将它们存储在标准数组中。 但我们选择了一条更激进的道路。
大型数据结构在 dotMemory 中很常见。 例如,对象图被存储为邻接列表,使用两个通过整数数组索引相互引用的结构数组。 这很有趣,因为在 dotMemory 中,我们刚刚停止使用托管数组而转移到我们自己的基于内存映射文件的实现。 这有助于我们在访问元素时实现最小开销(C 中的原生内存索引形式),以及加载和保存数组的快速方式(完全在操作系统级别),并且在序列化/反序列化时没有开销。 另外,即使没有我们的参与,这些数组的片段也可以从内存中卸载,帮助我们在顺序遍历数组时释放物理内存。
我们决定在紧凑支配树上使用相同的方式。 我们还将 IsContainedInSet 特性变成了一个位标志,并消除了没有使用的 Parent 属性。 最后,我们为树节点得到了以下结构:
[StructLayout(LayoutKind.Sequential, Pack = 4)]
public readonly struct Node
{
public readonly TypeId ObjectsType;
private readonly uint _objectsCount;
public int ObjectsCount => (int)(_objectsCount & 0x7FFFFFFF);
public bool IsContainedInSet => (_objectsCount & 0x80000000) != 0;
public readonly int RetainedObjectsCount;
public readonly ulong RetainedBytes;
public readonly DfsNumber DfsEnter;
public readonly Range<uint> Children;
}

值得注意的是,通过这种顺序表示,我们甚至可以只使用一个指向下级节点的整数链接。 不过,我们使用了一个范围,该范围允许我们按 RetainedBytes 升序对构建树的下级节点进行排序以帮助我们构建旭日图。 对于上面显示的表示,节点 #1、#2 和 #3 的顺序可能会改变。
我们屏住呼吸,运行了程序。 成了! 内存使用峰值仅为 12 GB。 支配树成功构建,耗时 55 分钟 – 仍然比我们期望的要长,但可以接受。 快照现在总共包含 2.75 亿个对象,紧凑树包含 2 亿个节点。
这显然是一个好结果。 我们一开始无法将大小降至 32 GB 以下,计算需要很长时间,现在,它已经降到 12 GB 并能在 55 分钟内就绪。 然而,我们还是感觉我们可以做得更好。 55 分钟绝对算不上理想。 我们决定查明这些时间都用在了哪里。 进入 dotTrace:

好在我们不需要等待进程完成,记录几分钟的性能就足够了。 我们使用 --timeout=3m 键在 3 分钟后自动停止分析。 我们打开快照,应用筛选以识别正在执行我们任务的线程,这是长时间保持完全加载的线程。 调用树是这样的:

令人震惊的是,92% 的时间显然都被 Dictionary.Clear 占用了! 我们简直不敢相信。 Clear 在标准库字典上怎么会表现得如此糟糕? 原来,问题是字典在算法的第一次迭代中已经膨胀到了 22K 的巨大元素,而随后的迭代通常只涉及几十个元素。 Dictionary.Clear 的计算复杂度与 Capacity(不是Count)成正比,特别是 buckets.Length,它与 Capacity 成线性关系。 这意味着我们在不断清除空元素! 事实证明,选择清除和重用字典时,我们对模型进行了过多的优化。
再退一步,我们现在尝试了最直接的方式 – 为每次迭代创建一个新字典。 我们再次启动秒表,运行代码,这次充满期待。 哇! 1 分 46 秒! 垃圾回收器上的负载增加了,但它分布均匀并且管理良好,我们使用 dotTrace 验证了这一事实。就是这样。 我们在不到 2 分钟的时间内处理了 2.75 亿个对象,内存使用峰值仅为 12 GB。 我们相当高兴,准备好将优化的代码提交到仓库。
后来,我们决定再做一次测试。 我们在不同的快照上运行了旧算法和新算法,比较性能。 我们找到了一个大小相同但拓扑不同的快照,旧算法也可以处理,然后把它馈送给两种算法。 令我们大吃一惊的是,新算法比旧算法慢了 33%,尽管计算复杂度没有变化。 但这就是另一个故事了,我们以后再讲。 如果您有兴趣,请在下方留言或直接联系我们!
本博文英文原作者:




