

Fleet
More Than a Code Editor
Fleet 后台探秘,第五部分 – 代码补全的故事

在本系列博文中,我们将以多个部分为您介绍构建 Fleet 这款由 JetBrains 打造的下一代 IDE。
在本系列的第三部分和第四部分中,我们探讨了状态管理中涉及的复杂抽象架构概念,以及它们如何在 Fleet 的分布式组件之间进行同步。接下来,我们将研究更熟悉的代码补全功能,看一看它是如何在 Fleet 中实现的。
Fleet 在代码补全领域并不是一项巨大突破,但其架构和分布式特性在各处都留有印记。想象一下:一个典型 Fleet 用户,有幸(或不幸)使用多种编程语言。这类软件开发者会在 Go 和 JavaScript 上苦苦挣扎,更喜欢 Kotlin 和 Rust,还要在文本文件中记笔记。有没有哪种代码补全解决方案能够涵盖所有情况呢?我们来找出答案。
最终用户看到的代码补全
我们先来做一些文本记录。看一看到目前为止的代码补全:
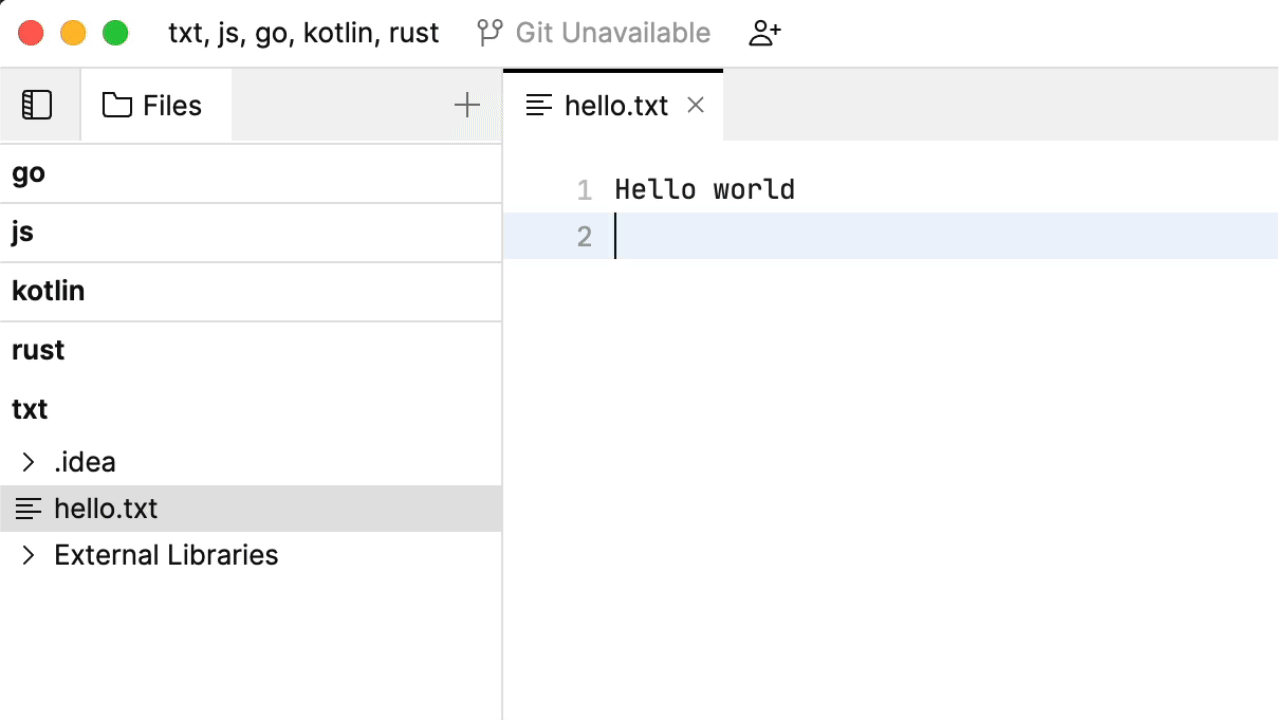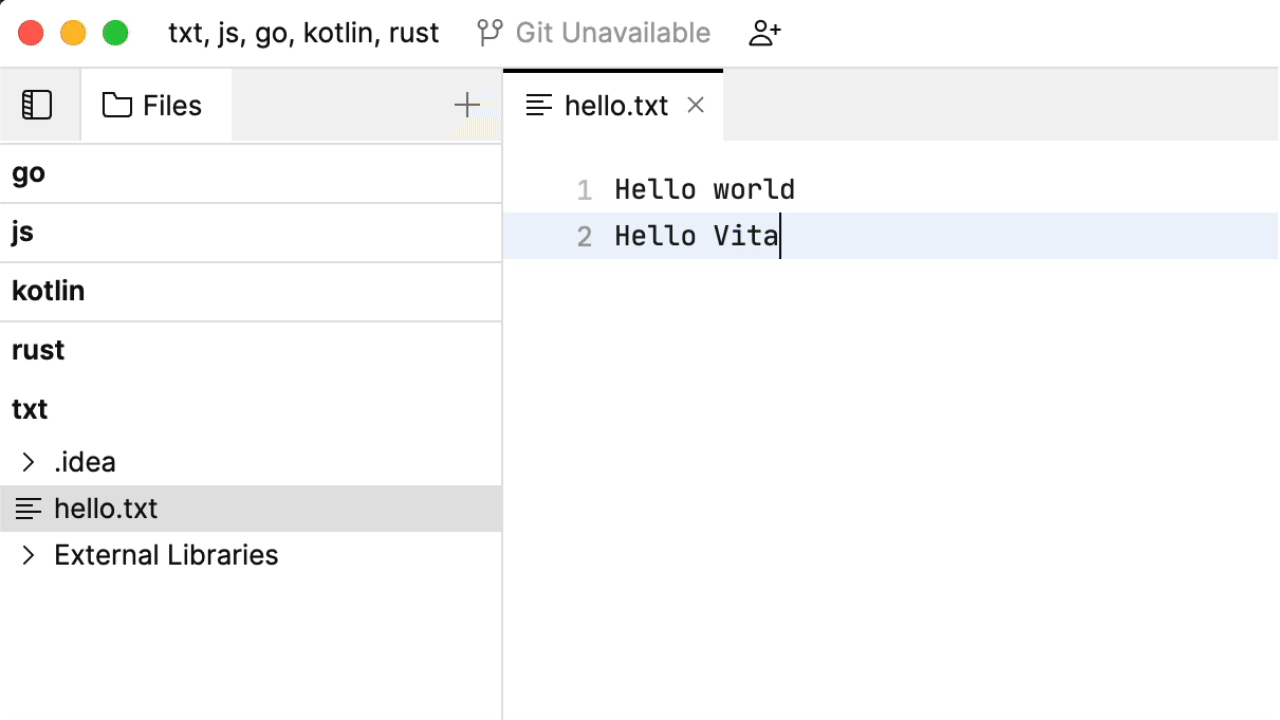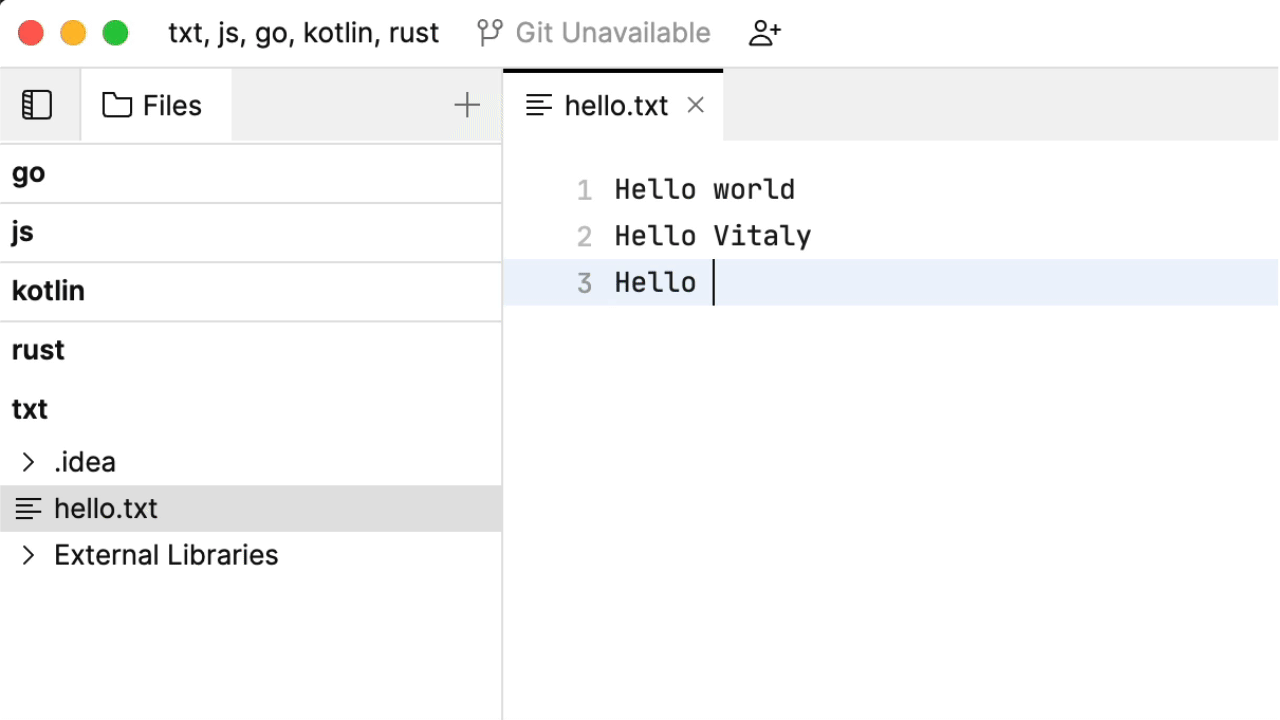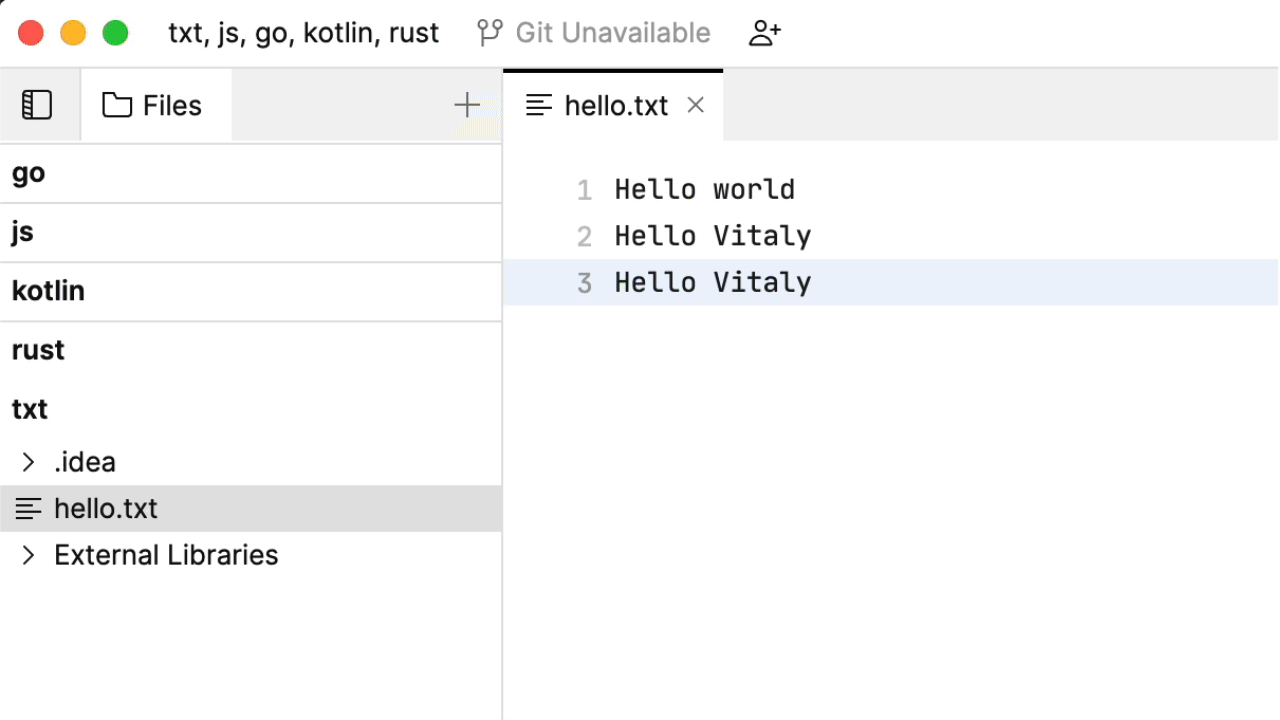
这种行为内置于 Fleet 的编辑器中:它会分析文档,考虑哪些单词是代码补全的良好候选。听起来还算合理,虽然您可能以为是机器学习在根据您先前记下的其他笔记来施展魔法。
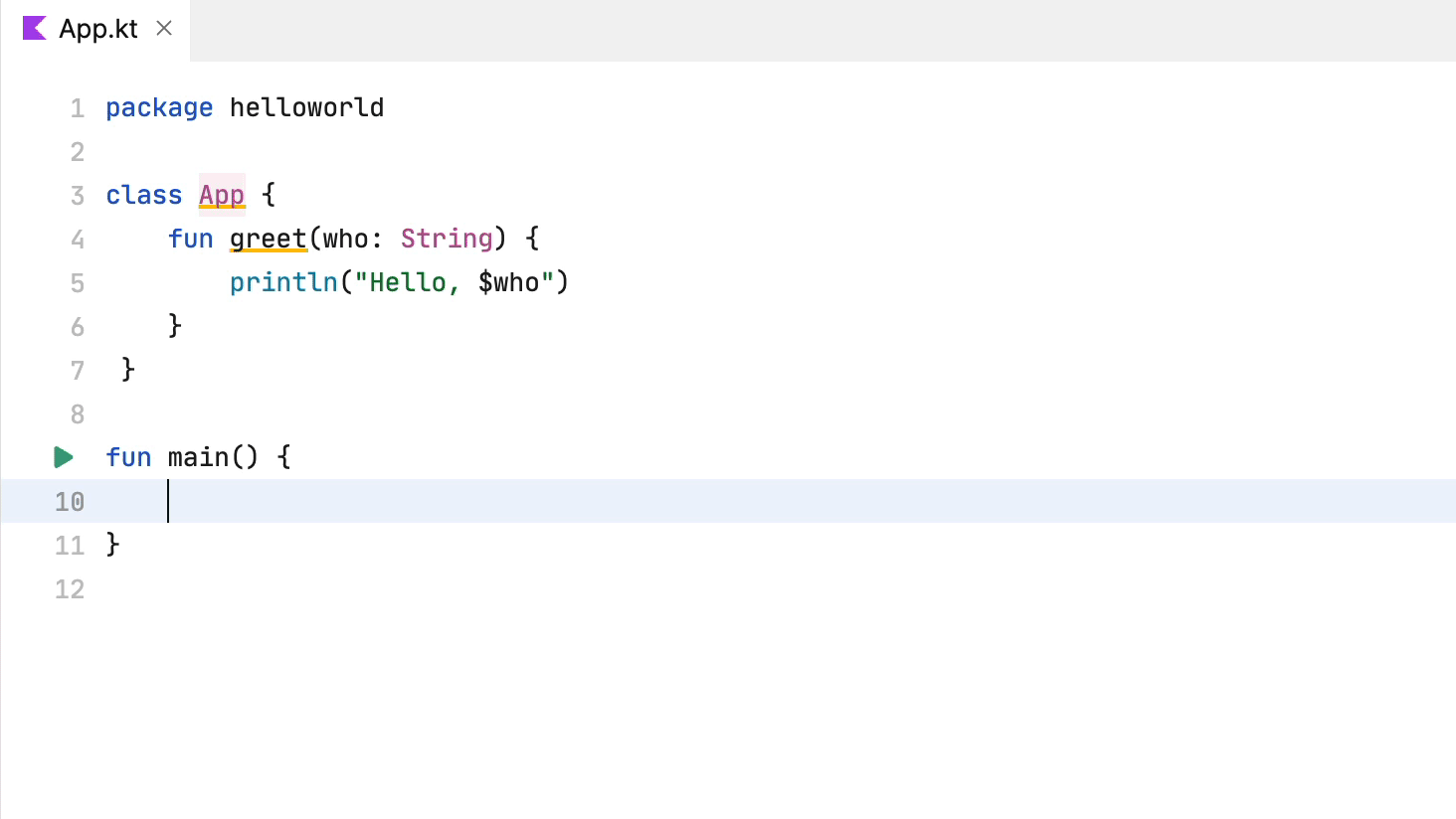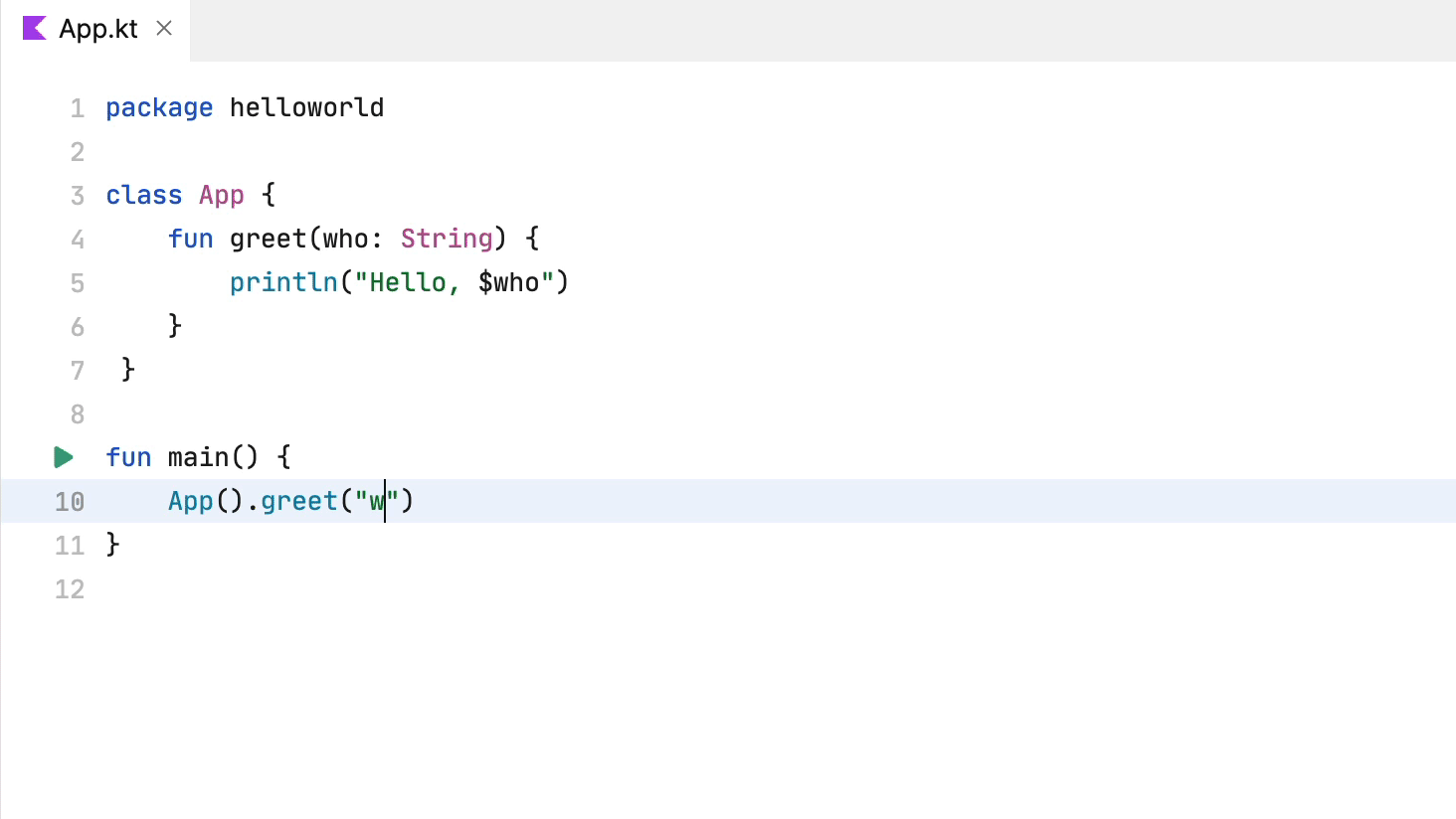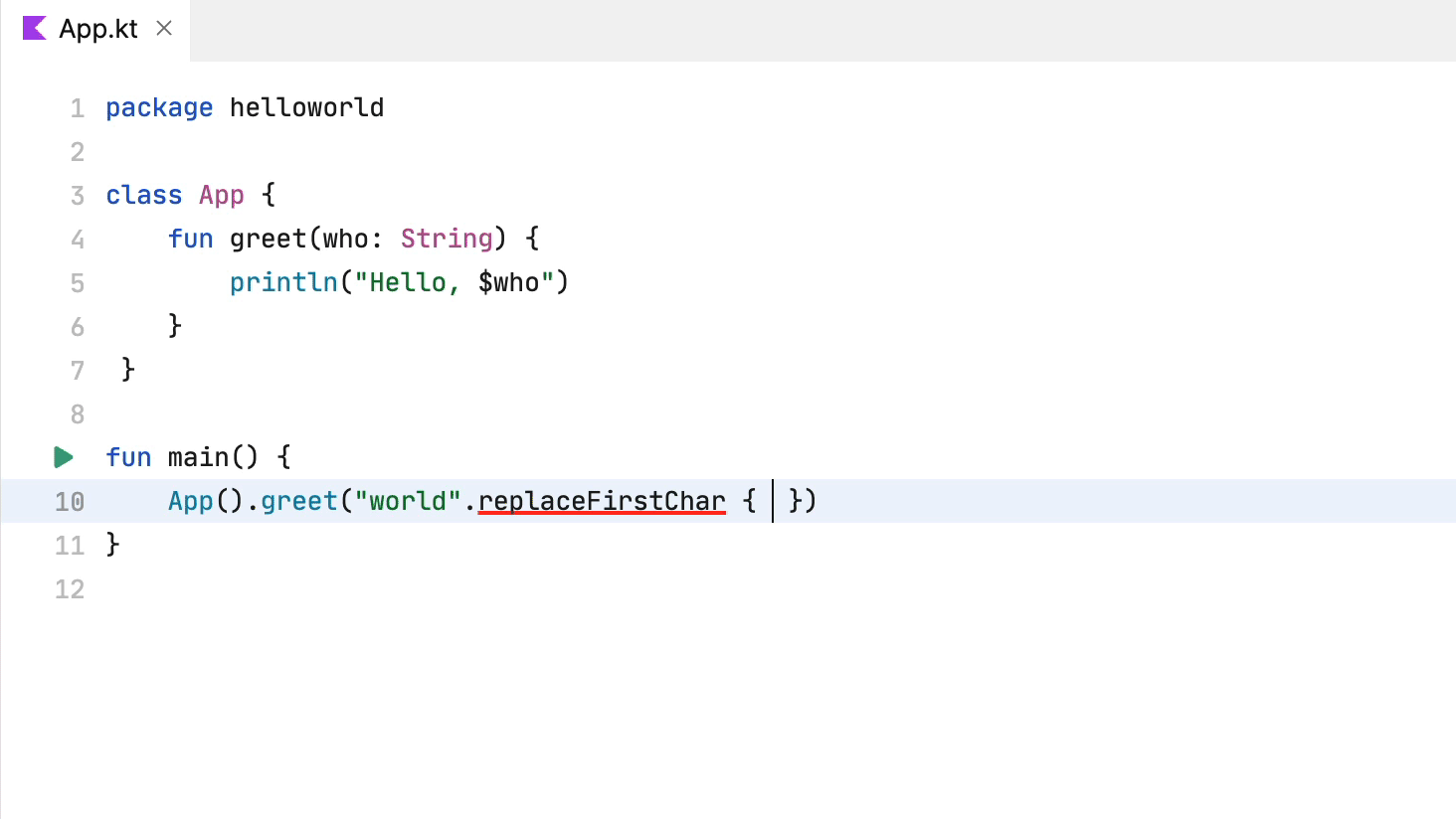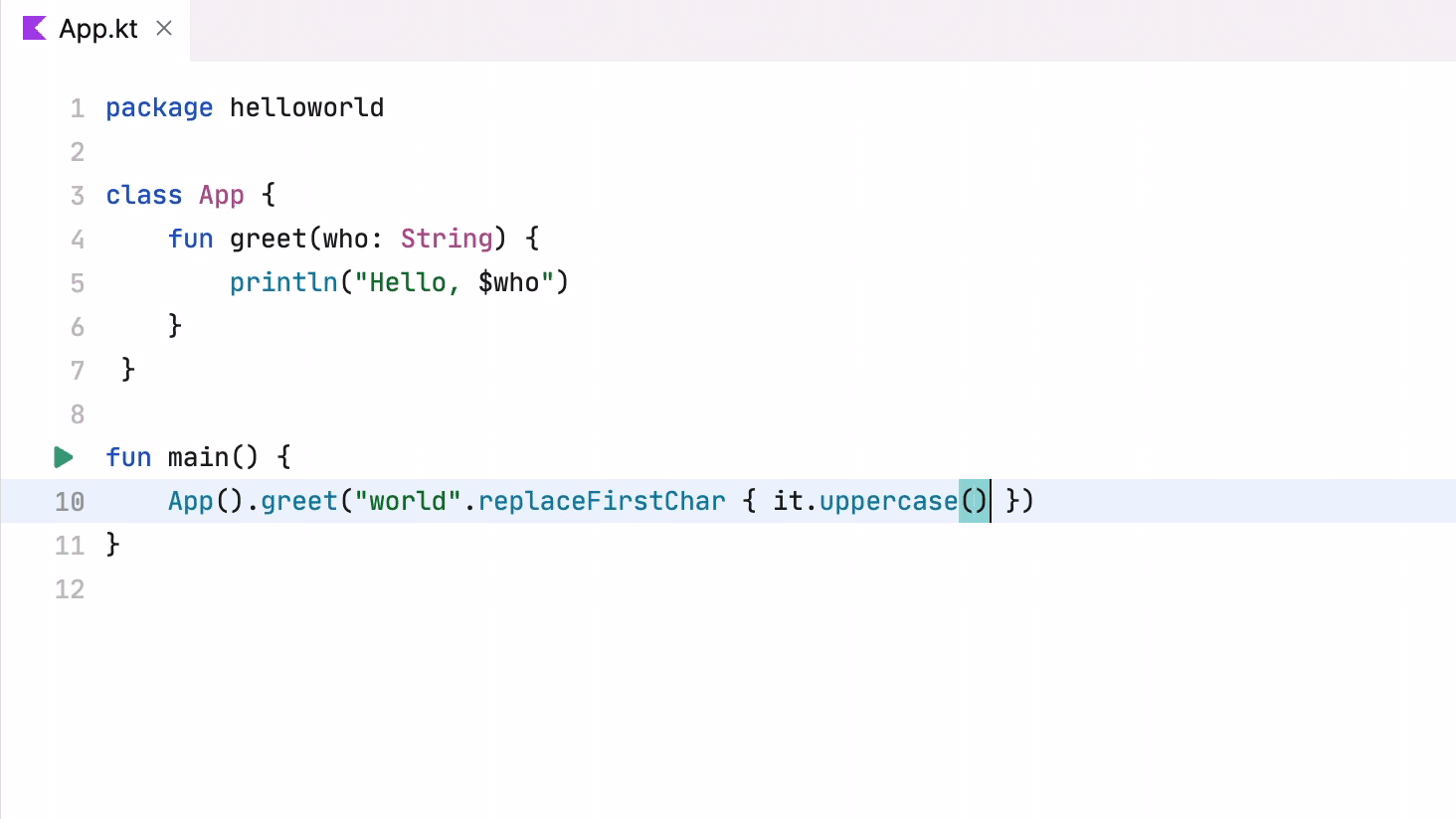
接下来,我们转向 Kotlin 编程。
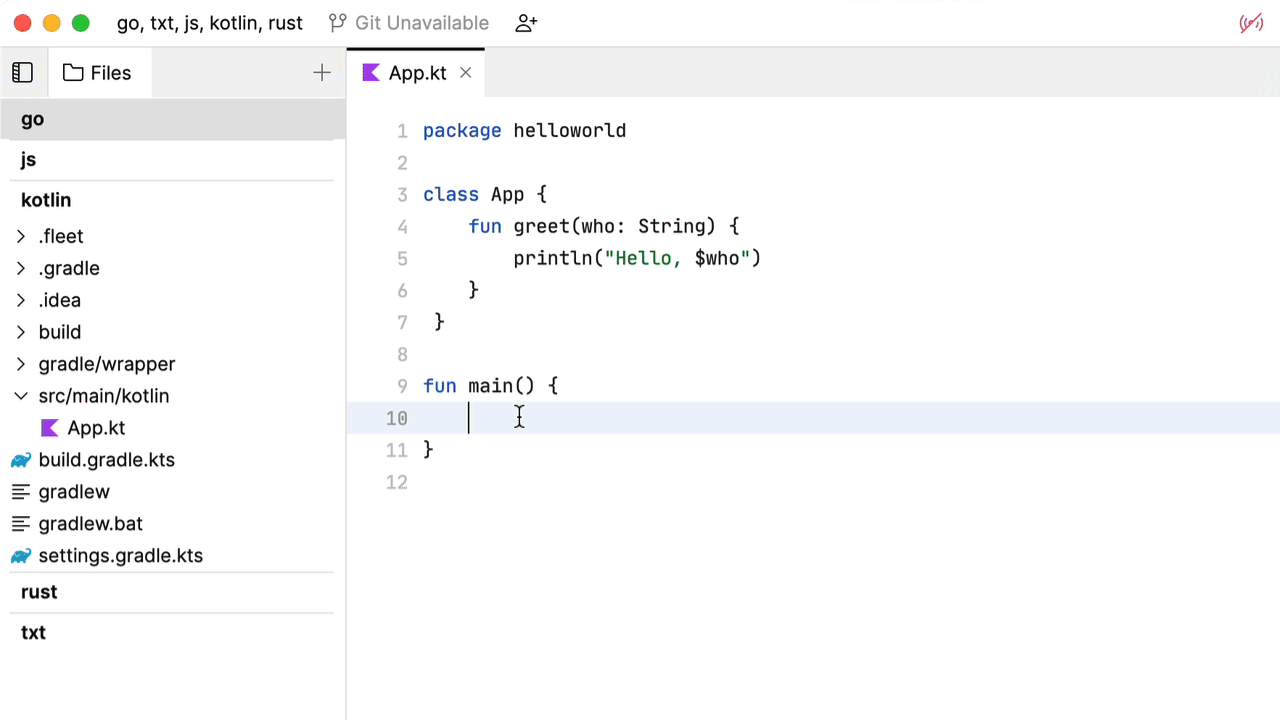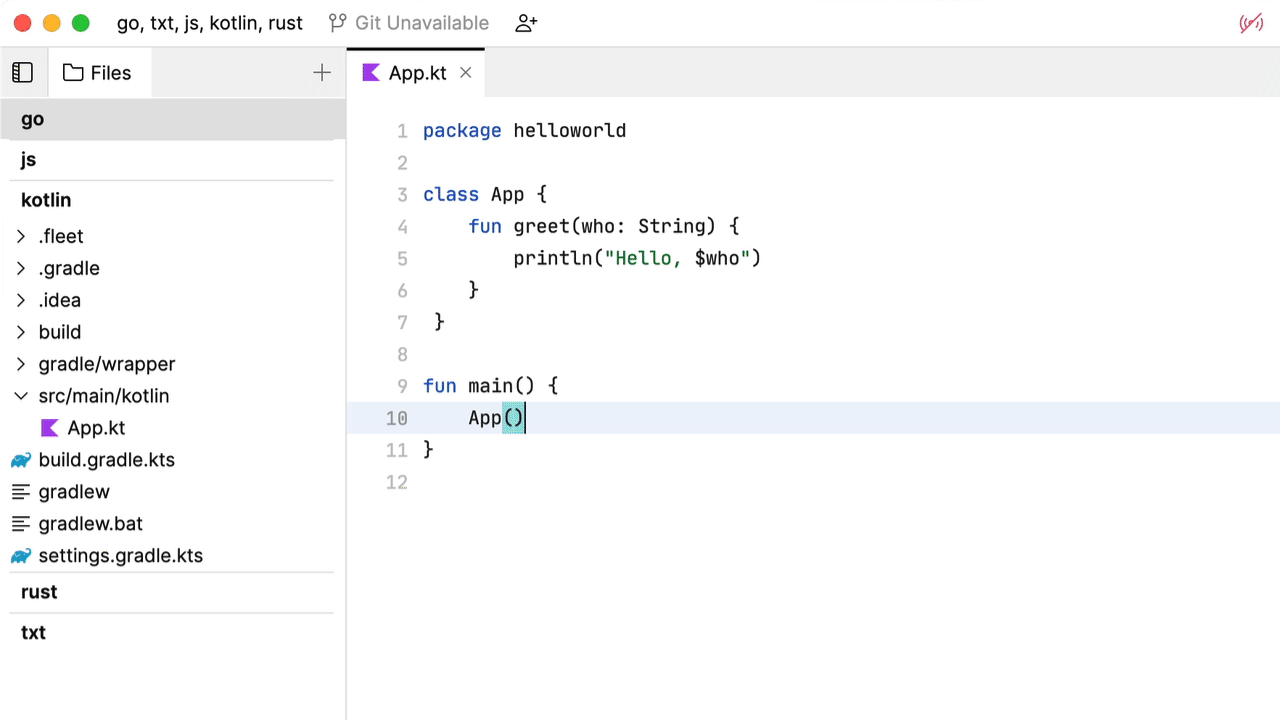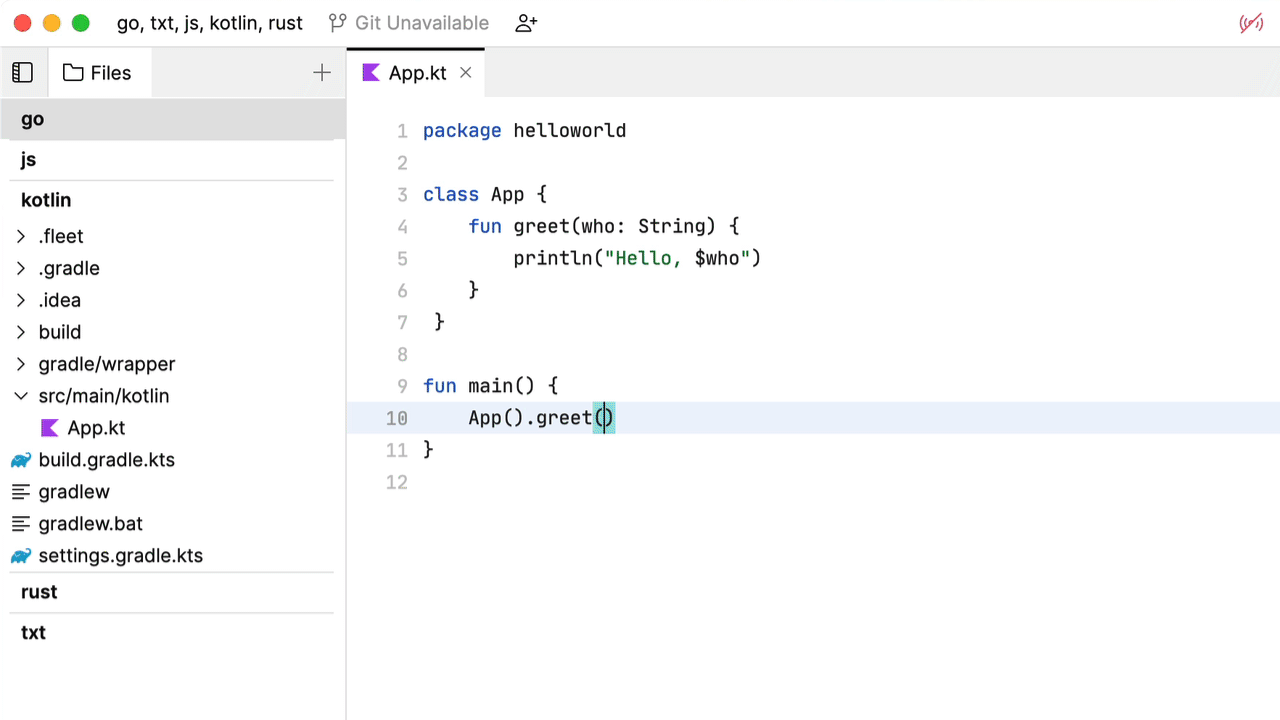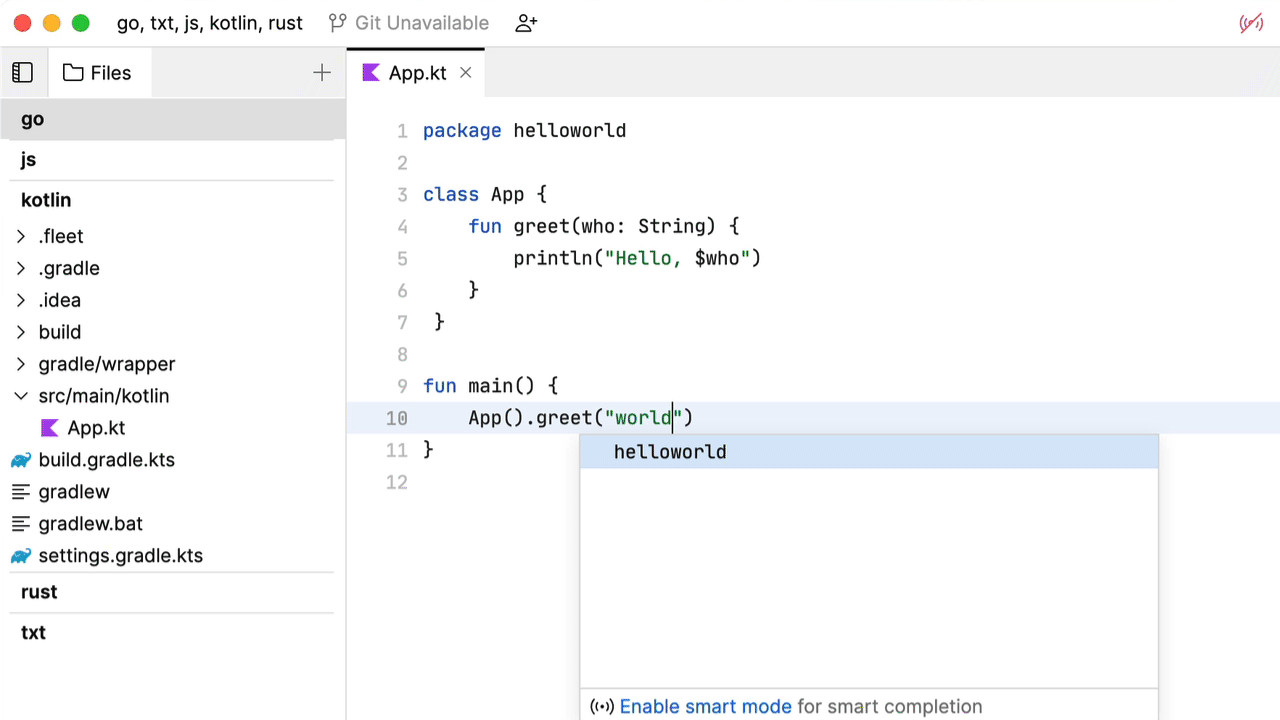
这种补全行为并没有什么特别突出的地方。基本上就是文本记录中的相同算法。Fleet 建议我们启用智能模式。将其启用。
看起来好多了:我们得到了基于代码分析的准确建议。问题是,谁在负责提供这些补全项?显然不是编辑器,因为我们需要大量关于代码本身和它可能使用的库的信息。
注意,补全不一定追加代码。事实上,它会更改代码。在以下示例中,代码补全移除了点字符并添加了大括号:

使用代码补全也可以从预定义代码段生成通用代码段。在以下示例中,我们在智能模式下编写 Rust。输入 for 并按 Ctrl-空格键即可插入以下代码段:

补全结果是一些模板文本,带有几个由文本光标表示的占位符。我们可以使用 TAB 键继续移动。插入代码段相当枯燥。Fleet 无需分析代码即可执行此操作。此功能可以在编辑器中轻松实现。探索这些示例,可以看到补全结果在很大程度上依赖于智能模式。不过,即使没有智能模式,我们还可以使用别的东西。我们还可以看到一些基本代码追加,以及代码重构或以占位符插入复杂代码段。现在,来看看后台发生了什么。
内部分析
下图很好地展示了 Fleet 中代码补全的工作原理。
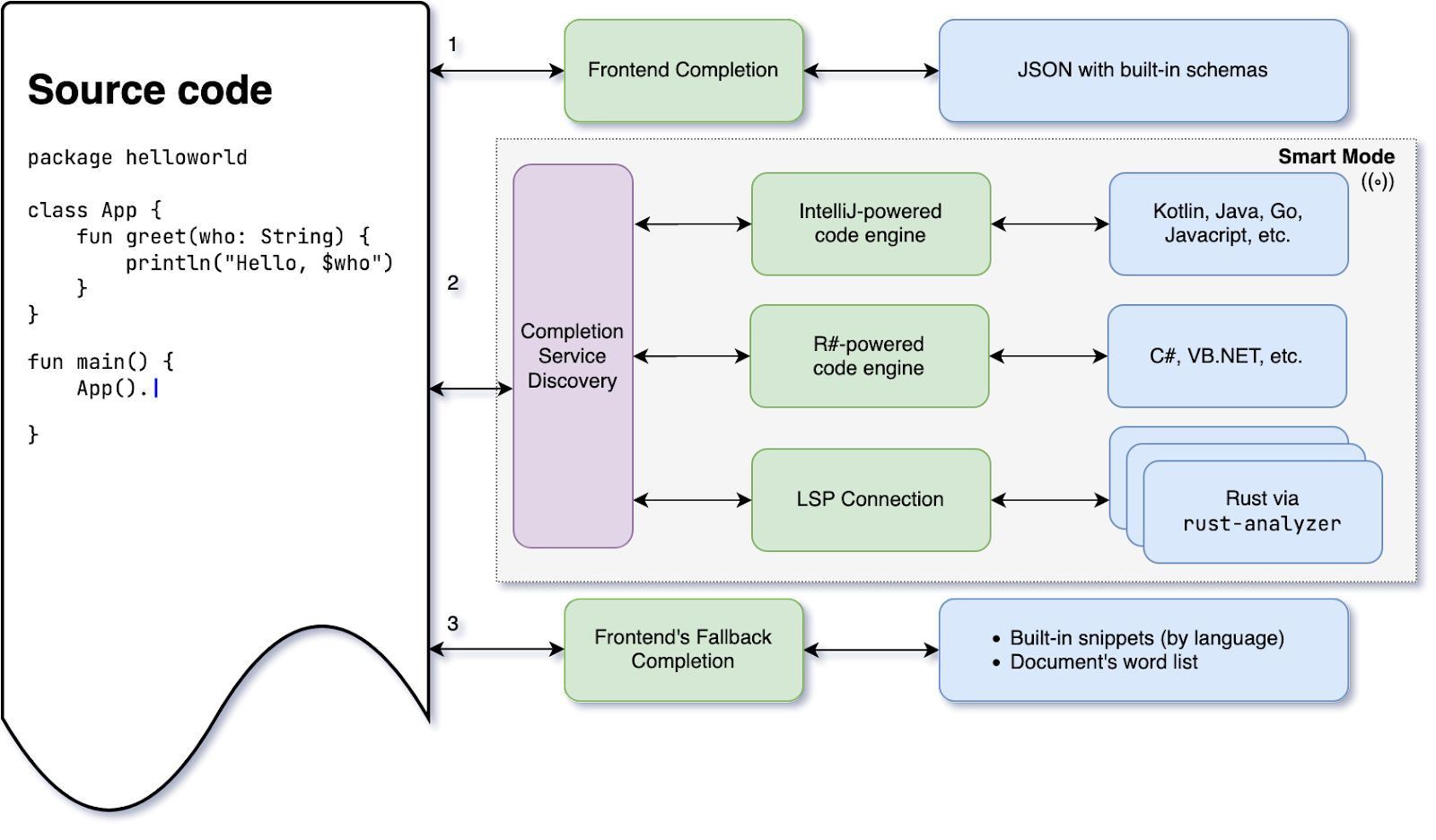
在某些情况下,Fleet 的前端可以自己提供代码补全。有多个预定义 JSON 方案适用于补全,例如 settings.json,这是一个具有 Fleet 设置的文件。启用智能模式后,我们可能会开始看到由 IntelliJ IDEA 或 ReSharper 或大量 LSP(语言服务器协议)服务器驱动的全面补全引擎。Rust-analyzer 是 Fleet 支持的第一个 LSP 服务器。Fleet 项目进展顺利,因此未来还会有其他项目。
IntelliJ IDEA 后端和 LSP 服务器提供的代码补全是其服务的一部分。它们还提供许多其他服务,包括维护缩进规则和报告代码中的编程错误等。对于部分编程语言,拥有多个后端引擎没什么问题。未来,Fleet 用户将能够选择任何偏好的引擎。
代码补全可以分解为多个组件:
- 对于特定源位置可用且合理的补全项。
- 负责提供补全项的补全服务引擎。
- 统一不同补全服务的补全 API。
- 负责将补全项交付给用户并应用所选项的补全会话。
这些值得更深入的讨论。
补全项
补全项是指用于从当前源代码位置继续的一个可用选项。
Fleet 中有三种补全项:
- 基本补全项是应该追加到当前光标位置的文本。
- 代码段是带有占位符的模板。 插入源代码文件后,代码段支持占位符间导航,并基于其他占位符中输入的内容动态建议补全项。 这些代码段提供的功能与 IntelliJ IDEA 中的实时模板相同。
- 声明式插入是一组编辑指令(如插入、移除、替换),应当应用于代码以完成代码补全操作。
特定类型的补全项会定义:补全项列表中显示的内容,应用后对代码执行的操作,特定代码建议的优先级,等等。根据种类,补全项的应用可能多少有些琐碎。如果补全需要不能以声明式方式表达的复杂代码操作,Fleet 将要求后端在后端执行补全,而不是在 Fleet 的编辑器中执行。
应用补全项的过程不会更改文档内容。它只会生成一组应当应用于该内容的操作。这是通向 Fleet 状态管理的第一座桥梁。然后,这些文本操作将在考虑 Fleet 的分布式特性的情况下被应用。
补全项不会凭空出现。必须有服务根据当前源代码位置和当前文档版本生成它们。由于这样的服务可能不止一项,我们需要一个 API 来统一这些服务的访问。
补全 API 和补全服务
Fleet 的补全 API 很精简,可用于:
- 获取给定源代码位置的补全项。
- 补全当前语句,如果只有一种可行方法。
- 为我们应用补全,如果我们有更重要的事情要做。
- 清理补全引擎使用的资源。
Fleet 如何知道哪些补全服务可用?会使用发现服务吗?阅读过往期博文的读者可能会想到使用状态管理引擎。任何补全服务都只是被加载到 Fleet 状态的实体。事实上,通常 Fleet 中的任何功能都以某种实体的形式出现。
这些服务实体知道它们支持哪些文档类型。Fleet 会查找状态,选择第一个负责当前文档类型的状态。如果没有找到,Fleet 将使用预定义代码段或文档单词列表,如上图所示。通过加载和卸载这些实体(阅读:启用和禁用对应插件),最终用户可以控制补全代码的内容。
目前为止,Fleet 中有两个主要补全服务:
- 一个负责从 IntelliJ IDEA 后端获取补全项。
- 另一个从 LSP 连接获取补全项。
它们都会实现补全 API,可供 Fleet 统一地使用。我们不会在这里说明这些服务是如何产生补全项的,这不在 Fleet 的相关范围内。Fleet 终究只是一个文本编辑器。
补全会话
代码补全是一个具有时效性的过程。用户启动后,Fleet 就要找到合适的补全服务并将其启动。收到的项目必须在弹出窗口中显示。用户做出选择后,所选项必须被应用到所有位置(工作区和所有前端)。
实际过程通常更为复杂。首先,获取高质量的补全项需要时间,而等待它们全部准备就绪是不现实的。提供的形式是项目流。Fleet 获得项目的新部分后,负责显示的组件就要被更新。
其次,用户可能会在请求代码补全后继续输入。从头开始重启补全操作效率太低。为每个输入的字符调用后端也成本过高。Fleet 可以通过筛选和重新排序来更新接收的补全项列表。重新排序相当麻烦。它是通过数个能够反映前缀匹配的额外优先级特征实现的。
最终,用户如果对建议不满意,可以取消补全。
补全会话是 Fleet 状态下的另一个实体,负责管理以上所有内容和其他内容。例如,它会处理可能已经过时的源代码位置,因为其他用户可能正在使用另一个 Fleet 前端同时编辑同一个文档。
有时候,真的很难相信这能奏效。再看第一部分的屏幕截图,注意代码补全会话附带的 UI 详细信息。完成代码补全以及在模板中编辑和填充占位符时,警告和错误不断出现。同时,大量数据流经工作区和前端之间的网络。分布式事务在下面展开。真的很神奇。
总结
代码补全只是 Fleet 功能的一小部分。现在,真的很难想象没有这个功能的世界。虽然有些人喜欢在 Google 文档中编写程序,特别是那些相信这能够锻炼编码能力的人。但我们其他人还是更乐意使用代码补全。
在大多数情况下 Fleet 都不够智能,不知道向用户建议什么。它将使用其他工具,例如 IntelliJ 后端或 LSP 服务器。Fleet 专注的是在以不同语言编辑源代码时提供最佳体验。它运用自身的所有状态管理机制来帮助用户更有效地工作。
这不是本系列的最后一篇博文。在下一部分中,我们将分析 Fleet 中使用的 UI 框架。我们叫它 Noria。敬请关注!
本博文英文原作者:




