

Big Data Tools
A data engineering plugin
Data Engineering Annotated Monthly – July 2021

August is a good time to start new things – some people are on vacation and have more spare time to read than usual, while others are back and looking for a quick refresher on what’s new in data engineering.
We’re launching this Annotated series to find interesting and useful content on different topics around data engineering, such as news, technical articles, tools, future conferences, and more. And yes, at the time of writing “we” is just me, Pasha. If you think I missed something worthwhile, feel free to ping me on Twitter and suggest a topic, link, idea, or anything else.
Without further ado, let’s get started with this inaugural issue of Data Engineering Annotated!
News
A lot of engineering is about learning new things and keeping a finger on the pulse of new technologies. Here’s what’s happening in data engineering right now.
Kotlin API for Apache Spark – A year after showing you the first preview, we released version 1.0. Apache Spark already has two official APIs for JVM – Scala and Java – but we’re hoping the Kotlin API will be useful as well, as we’ve introduced several unique features. For example, null-safe joins may be implemented only in a language with a null-aware type system, like Kotlin.
Beam 2.31.0 – Despite being a minor release, this has several breaking changes! The most notable change is the support of the latest Flink version, 1.13. The folks at Beam are moving forward and aren’t afraid to break things, as they’ve dropped support for Flink 1.10.
Dagster 0.12.0 – I’m a huge fan of Dagster’s naming. Their names are even fancier than Ubuntu release names – “Into the Groove” is an awesome one! They’ve added some interesting features in this version. My favorite is pipeline failure sensors – it’s brilliant how they allow you to run tasks when a pipeline fails! I believe Dagster is a great pipeline orchestrator, and who knows, maybe even the Next Big Thing in orchestration.
Data retention policies in lakeFS – lakeFS is an open-source solution for versioning your data. They have rolled out a new awesome feature: data retention policies. Who said you need to store all versions of your data and store it forever? Let’s delete everything we no longer need and free up the space for something more useful! Marie Kondo would be proud!
Row-access policies in Snowflake – Snowflake is one of the most well-known unicorns in the world of Big Data. While they might be basking in the glory of their success, they know they need to keep moving fast. In July they announced a new feature: row access policies. Now you don’t need smart logic to allow specific people to query and view specific information. No artificial multi-tenancy and so on – Snowflake does that for you!
Cassandra 4.0 Release – The first major release of NoSQL database in five years! Notably, they’ve added experimental support for Java 11 (finally) and virtual tables.
Future improvements
Data engineering technologies are evolving every day. This section is about what’s in the works for technologies that you may want to keep on your radar.
Row-level operations in Spark – For a long time, data engineering was built around append-only data, which is easy to manipulate, control, distribute, and synchronize. But things aren’t standing still, and new formats and types of quasi-mutable storage, such as Hudi, DeltaLake, and Iceberg are gaining popularity. Spark doesn’t work with internal data like it’s mutable – that is a prerogative of the underlying storage – but that’s all about to change! While we’re here, if you’re interested in the differences between mutable storage types, folks from lakeFS have performed a comparison.
Async sinks in Flink – Apache Flink may be one of the most popular on-premises streaming tools. It can put data virtually anywhere, but there is still some room for improvement. What happens if the system is under a peak load and the destination is not capable of handling it? Flink plans to add support for async sinks to address this question.
Rack-aware Kafka streams – Kafka has already been rack-aware for a while, which gives its users more confidence. When data is replicated between different racks housed in different locations, if anything bad happens to one rack, it won’t happen to another. However, a part of Kafka called Kafka Streams, a stream processing framework and a competitor to other streaming solutions, is currently not rack-aware. Of course, we want to preserve data as reliably as possible when processing streams, and the good news is that a Kafka Improvement Proposal (KIP) to fix this has already been approved.
Articles
This section is about inspiration. We’ll try to list the articles and posts that we find on the internet to help us all learn from the experience of other people, teams, and companies dealing with data engineering.
5 Reasons to Choose Pulsar Over Kafka – The author states his bias upfront, which is nice. This is the second installment of his discussion of Pulsar vs Kafka, and part one can be found here. The competition between Pulsar and Kafka is tight, so knowing the strengths and weaknesses of each solution is helpful if you want to choose wisely.
Building Data Pipelines Using Kotlin – Surprisingly, big companies are using Kotlin for data pipelines, too! Salesforce shares its experience of using Kotlin everywhere in data engineering but Spark, and we’re in touch about using the Kotlin API for Apache Spark, too!
Search Indexing With Kafka and Elasticsearch – Search indexing is a huge engineering problem and every company has its own approach. For example, companies like Google and Yandex have built their entire business around search. What if you’re not a search giant, but you still want to provide your users with a powerful yet easy-to-use search function? DoorDash’s solution to this problem involves Kafka, Elasticsearch, and a plethora of other technologies. Read the article to find out how they did it.
Tools
Building architecture diagrams with Mindgrammer – Data engineering is often about building the architecture of something. It takes a lot of brainpower to come up with an effective architecture, but you can’t keep the whole architecture in your head – that’s too difficult (and dangerous, too!). Architectures must be documented, but they can drift and change over time. If kept as text, they will become obsolete sooner rather than later and will be costly to maintain.
Enter Mindgrammer – a tool for keeping your diagrams as code. As an example, we’ve used Mindgrammer to visualize a part of the architecture of JetBrains’ data analytics platform. Note there are icons for most items in the major cloud providers’ ecosystems, for Kubernetes, and even for some on-premises services. Here is a diagram of JetBrains’ data access pipeline:
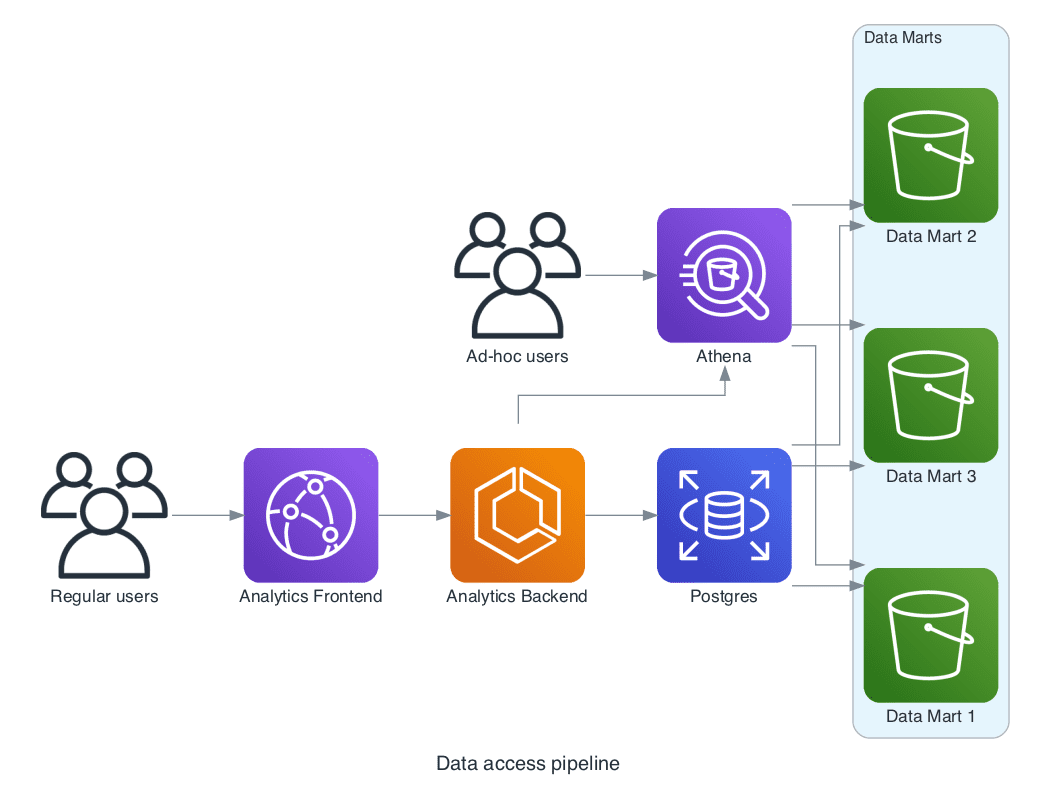
with Diagram("Data access pipeline", show=False, direction="LR"):
analytics_backend = ECS("Analytics Backend")
athena = Athena("Athena")
postgres = RDS("Postgres")
Users("Regular users") >> CloudFront("Analytics Frontend") >> \
analytics_backend >> [athena, postgres]
Users("Ad-hoc users") >> athena
with Cluster("Data Marts"):
data_marts = [S3("Data Mart 1"), S3("Data Mart 2"), S3("Data Mart 3")]
athena >> data_marts
postgres >> data_marts
Pretty handy, isn’t it?
Conferences
SmartData 2021 – This international conference on data engineering is organized by a Russian company, but aims to have at least 30% of the talks in English. Most of the topics, from data quality to DWH architecture, are hot! Check it out and see if you’d like to submit your talk!
That wraps up our Annotated this month. Follow JetBrains Big Data Tools on Twitter and subscribe to our blog for more news! You can always reach me, Pasha Finkelshteyn, at asm0dey@jetbrains.com or send a DM to my personal Twitter, or get in touch with our team at big-data-tools@jetbrains.com. We’d love to know what other interesting data engineering articles you come across!





