

Big Data World, Part 2: Roles

This is the second part of our ongoing series about Big Data. In this part, we’ll talk about the roles of people working with Big Data. All these roles are data-centric, but they’re very different. Let’s describe them in broad brushstrokes to better understand what people we target.
- Big Data World, Part 1: Definitions
- This article
- Big Data World, Part 3: Building Data Pipelines
- Big Data World: Part 4. Architecture
- Big Data World, Part 5: CAP Theorem
Table of contents:
Data Engineers
To describe the work of a data engineer, I like to use the metaphor of pipelines. Data engineers build pipelines from sources to destinations. When it comes to Big Data, it turns out that having lots of operational databases (DBs) and other data sources is necessary and unavoidable. Data works well only if it can be joined and processed.
In addition to building pipelines, data engineers are usually responsible for building data warehouses (DWH) – a way to store all of the data the company will need at some point in time. It’s not as simple as it might look because of the above-mentioned 3V scaling.
For example, imagine that you need to maintain the profiles of the users of your service. This profile will include many things, such as a list of transactions, data gathered from an aggregated clickstream, stable data that will rarely change, calculated metrics, recommendations, and many other things. It’s not a problem to store it for a single user, but keeping it for hundreds of thousands of users may be quite challenging. But it’s not the only challenge! Imagine updating them every day or querying them by random keys. Querying may be a real issue, even in traditional relational DBs.
To be honest, what I’ve just described is the whole separate class of systems – Data Management Platforms (DMP). Wikipedia says, “They allow businesses to identify audience segments, which can be used to target specific users and contexts in online advertising campaigns.”
Data engineers are usually a mix of software engineers, DBAs, and Ops. There are numerous tools that data engineers use daily:
- Batch processing tools (like Apache Spark)
- Stream processing tools (like Apache Kafka and Apache Flink)
- Columnar storages (like parquet or ORC)
- Query engines (like Presto or Apache Hive)
- MPP, massive parallel processing DBs (like Vertica)
- OLTP DBs (like Postgres and Oracle DBs)
- Orchestrators (Luigi, Apache Airflow, etc.)
- Object storages (S3, HDFS, etc.)
- IDEs (like IntelliJ IDEA with the Big Data Tools plugin)
The most popular languages among data engineers are Python and Scala.
There is one more focus for data engineers – automation. Everything should work by itself, including communication between departments.
The area of responsibility is so huge that what I’ve called data engineering here is usually separated into more specialist things: data architecture, data governance, ETL (extract-transform-load, a short name for the “pipeline”). In large companies, they will usually form separate departments just to make it easier to communicate.
Data scientists
Data scientists apply, well, data science. But what is data science? Let’s ask Wikipedia again: “Data science is an interdisciplinary field that uses scientific methods, processes, algorithms, and systems to extract knowledge and insights from structured and unstructured data.”
Data scientists usually apply statistical methods to explore and understand data. It’s a big deal when it comes to handling large amounts of data – the human brain just can’t remember and analyze that much data. There may be hidden correlations or patterns in multidimensional data, and data scientists are trying to find them.
In addition to gathering insights from data, data scientists are usually responsible for experimental analysis for two reasons:
- Statistics are needed to understand if the experiment gathered enough data to make conclusions based on it.
- It’s a purely mathematical task to understand if experiments have affected each other in some way.
Also, things like “Neural Networks”, “AI,” or “ML” are all more or less the responsibility of data scientists. Sometimes they select tools together with data engineers to make production support easier for everyone.
Of course, every huge product you may be aware of, like OpenAI, results from the work of many people with a very different profile of competencies, including data scientists and data engineers.
Usually, data scientists use data prepared (or at least transferred) by data engineers. Their tools are
- Neural networks (like PyTorch, TensorFlow, etc.)
- Notebook software (like JupyterLab, Google Colab, Apache Zeppelin, Datalore)
- Math libs (like NumPy, PyMC3, etc.)
- Plotting libs (like Matplotlib, Plotly, etc.)
- Feature engineering tools (like MindsDB)
- BI (Business intelligence) tools and frameworks (like Superset, Redash)
The most popular languages among data engineers are Python and R.
A data scientists’ work has one amusing trait – it’s research. As with many research tasks, you never know if or when you’ll be successful with your current approach. This trait sometimes moves the focus from writing production-grade supportable code to writing quick experiments to gather results ASAP. As we all know, nothing is more permanent than temporary. And it’s where ML engineers come in.
It’s important to understand that the responsibility of a Data Scientist is not only analysis and research. They also build quite complicated systems. For example, there are lots of neural network libraries, but it’s not enough to know their APIs. TO build a production-ready solution Data Scientists usually have to architect a multi-layer neural network, which solves the concrete problem in concrete SLO (Service Level Objective). And there are such tasks all around — building scientific tools, usable in real production s not only about science, but it’s also about engineering skills and understanding of business.
ML engineers
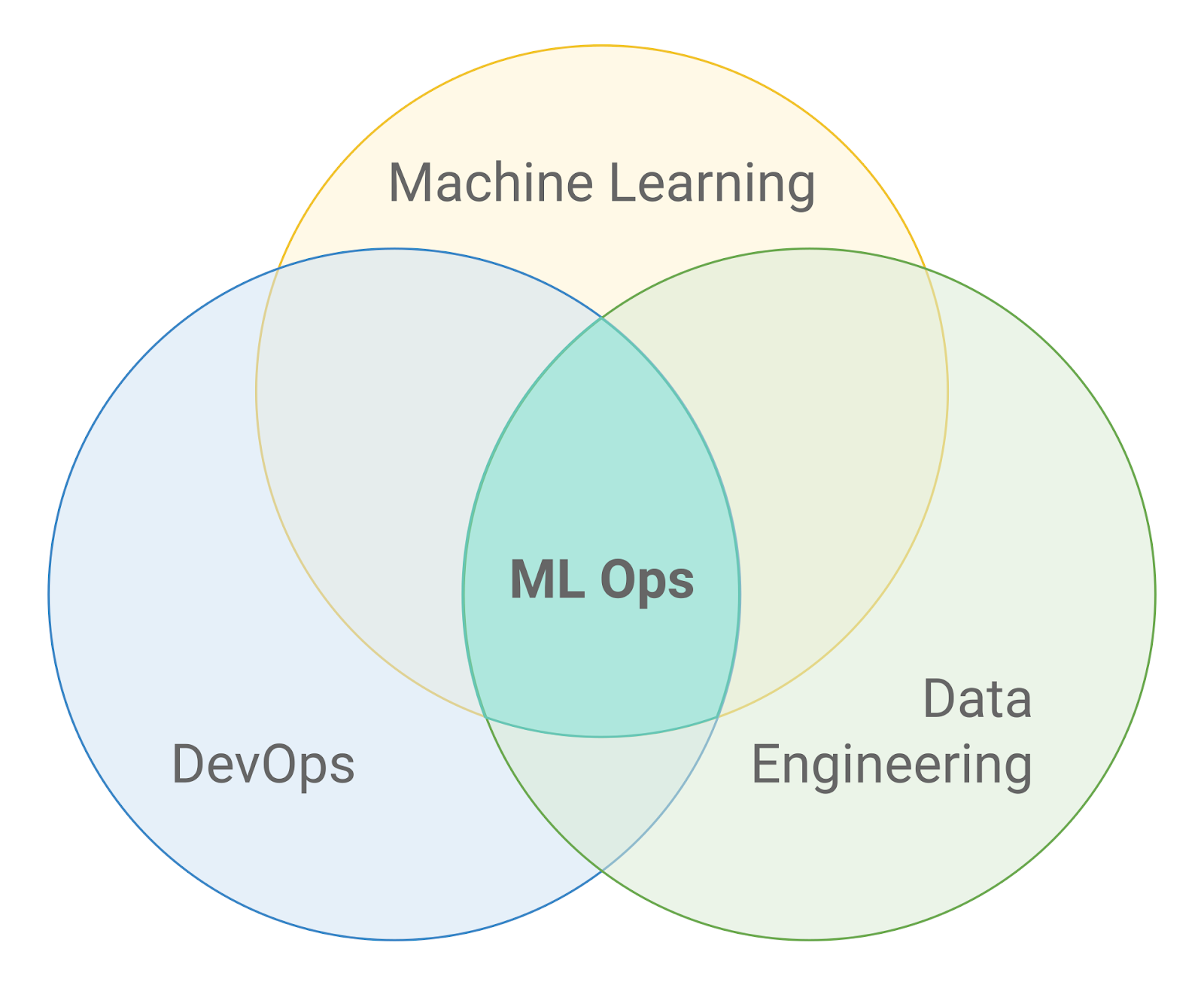
The picture above demonstrates where ML Ops exists in terms of the intersection of other fields. And ML engineers are those who work there. Their area of responsibility is to make ML work closer to an engineering discipline. There is an excellent blog post from Google describing how to make it a reality and what challenges there are while productizing ML. But let’s look into the roots – where did the issue come from?
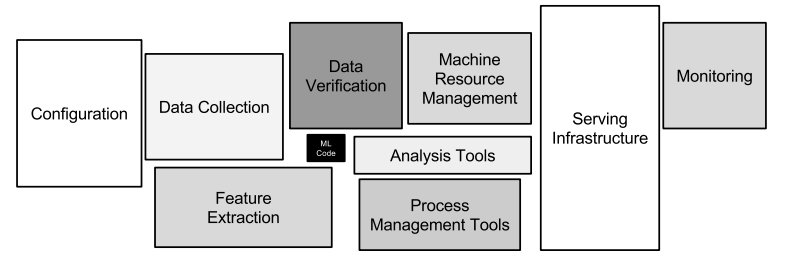
Everybody who starts learning data science learns how to write ML Code, but there are so many things that should be done to make the code ready for production! Code should be deployed, monitored, work reliably, and be available. Before code even starts working, data should be collected and prepared.
ML engineers should configure every ML application in a known and predictable way. Data should be versioned (and this is a huge difference from regular software engineering).
ML engineering is a very new specialization, even compared to other jobs around data, and that’s why there are lots of new tools appearing almost daily. Popular tools which ML engineers work with are:
- Data versioning tools (like DVC)
- Model serving software (like MLflow)
- Deployment tools (like Kubeflow)
- Monitoring tools (like MLWatcher)
- Privacy-preserving tools (like PySyft)
The most popular language among ML engineers is Python.
It’s important to understand that the roles of Data Scientist, Data Engineer, and ML Engineer are only examples. There may be only one person responsible for all of the data, acting as both scientist and engineer, in a small company. In a huge company, there will be many subcategories for both – for example the separate role of data governor.
Conclusion
Big data gives us a lot of new opportunities! There are a lot of options for development and self-realization. It almost doesn’t matter what you’re doing right now – it almost certainly can be used in data. There is work for mathematicians, engineers, and ops. QA in data is challenging and exciting, too.
In addition to the extraordinary technical challenges of building a state-of-the-art system, Big Data also allows broading the horizons of tooling and also for reusing tools in new ways. There is no way to remember all the tools available on the Big Data market, much less use or try all of them. And this is interesting too – if you are curious, data is your way to allow yourself to make or try something entirely new!
Please share your thoughts in the comments or on our Twitter.
Useful links:
- Awesome Data Engineering learning path
- Awesome production machine learning list
- Continuous delivery for machine learning
- MLOps: Continuous delivery and automation pipelines in machine learning
- JetBrains Tools for Data Science & Big Data
- Big Data Tools plugin




