

Fleet
More Than a Code Editor
Fleet 后台探秘,第二部分 – 编辑器详解

在本系列博文中,我们将以多个部分为您介绍构建 Fleet 这款由 JetBrains 打造的下一代 IDE。
- 第一部分 – 架构概述
- 第二部分 – 编辑器详解
在本系列的第一部分中,我们概括介绍了 Fleet 架构。 在此第二部分中,我们将介绍编辑器幕后使用的算法和数据结构。
数据结构的聚合
请查看以下屏幕截图,其中展示了 Fleet 中的编辑器窗口

图中包含一行带有语法高亮显示的文本,以及一个提供特定变量用法相关信息的微件。 现在,人们可以通过多种方式显示这些信息,但编辑器方面的问题是它们并非只读。 除了数据可视化以外,数据还可以更新。 诸如更改函数名称这样简单的操作就可能会造成许多影响,例如影响语法突出显示、用法,当然还包括提供的任何其他功能,例如静态分析或实时编译。
为能提供良好的体验,我们需要确保编辑文本和随之呈现的可视化可以尽可能无缝衔接。 为了实现这一点,我们必须以有效的方式存储和处理数据。 然而,存储数据的方式并非只有一种。 事实上,上图就以多种方式存储数据,它们使用各自不同的数据结构,这些数据结构共同构成了我们所说的编辑器。 换言之,可以将编辑器视为数据结构的聚合器!
我们来详细介绍!
绳索全线贯通
对于熟悉处理大量文本的人来说,您可能已经知道使用字符串(即字符数组)进行存储的效率并不理想。 通常,对数组执行任何运算都意味着必须创建一个更大或更小的新数组,并将旧数组的内容复制到新数组。 这种方式很难保证效率。
效果更好且更加标准化的方式是使用绳索结构。 这种抽象数据类型背后的理念是将字符串存储在树上的叶节点中。
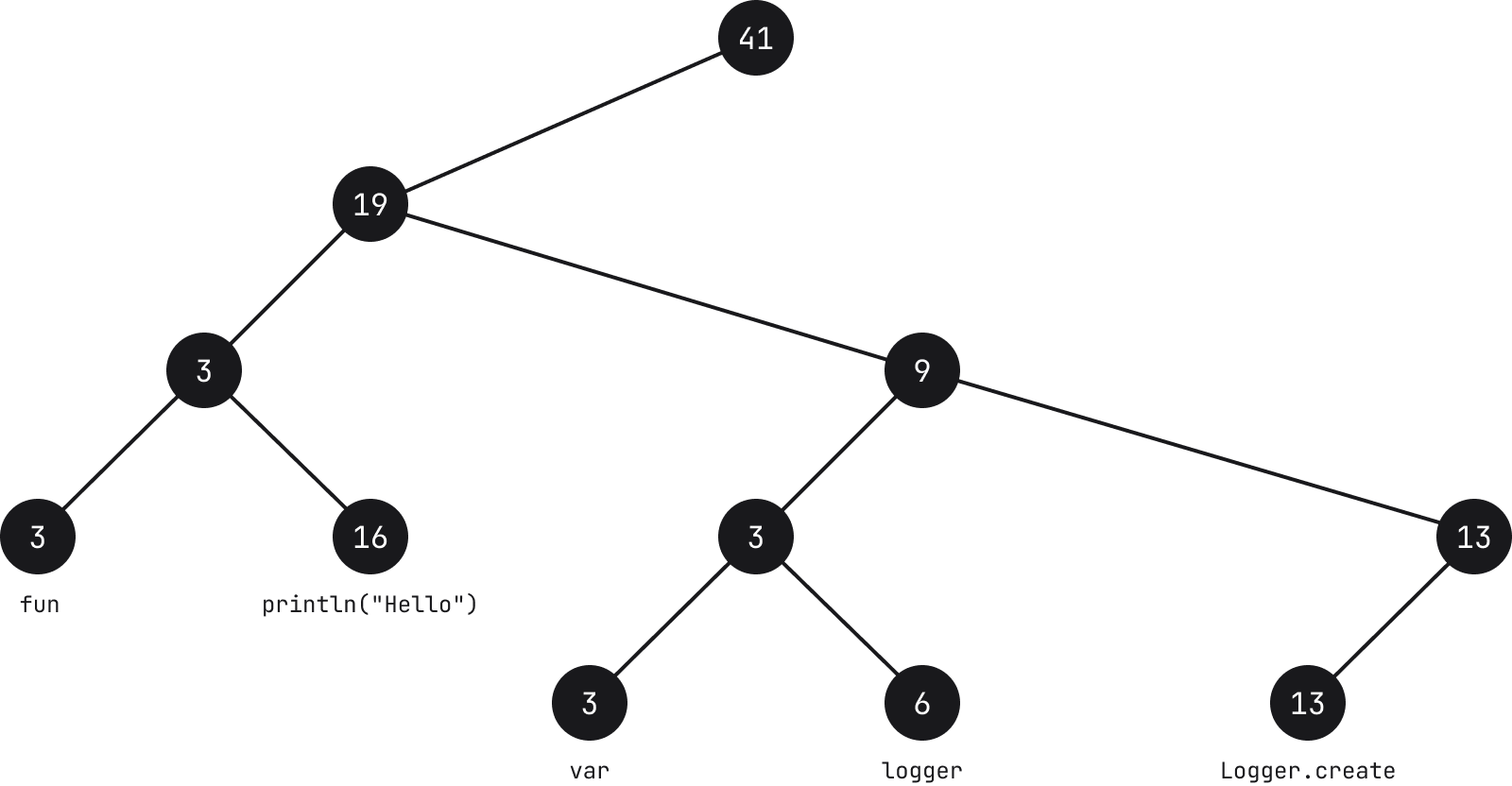
每个叶节点都包含一个字符串(请参阅下方注释)及其长度(称为权重)。 每个中间节点也包含一个权重,它是其左侧子树中所有叶节点的权重的总和。
注:叶节点上使用的文本只是一个示例,并不代表实际文本在 Fleet 中的分解方式。
在上面的示例中,如果我们以容纳字符 fun 的节点为例,则该节点的计数为 3,因为字符串长度为 3。 上移到父节点,计数也是 3,因为其左侧所有节点的权重之和为 3。 继续向上,该节点的父节点的计数则为 19,这是它左侧叶节点 3 和 16 的总和。
搜索、追加、移除、拆分字符串等常见操作的时间复杂度为 O(log N),其中 N 是字符串的长度。 运算从遍历树开始,鉴于节点信息,这种方式可以加快运算速度。 例如,如果我们要找到位置为 i = 30 的字符,从节点开始,用 i 减去(请参阅下方注释)权重值,如果 30 小于节点的权重(字符数),则我们向左查找。 另一方面,如果 i 大于权重,我们将向右查找。 随着我们向下移动且 i 值不断减小,当我们找到叶节点所容纳字符串为 i 的位置,该位置的字符就是我们所查找的字符。
注:根据使用的指标,可能并不需要减法运算。 重要的是,当我们沿着树向下查找时,我们会累积到该点的指标,并将其与我们正在搜寻的键进行比较。
在 Fleet 的绳索结构中插入或删除节点时,我们使用自平衡 B-Tree。 我们首先读取 64 个字符的块,一旦达到 32 个块,我们就创建一个节点并开始为第二个节点收集块。 每个节点包含两个数字 – 除了权重,我们还会存储行数(两者的组合就是我们所说的指标)。

通过存储行数,我们可以更快地导航到特定的偏移量。 在 Fleet 中,树的另一个特征是我们希望使之更宽,而非更深。
将区间树用于微件等
正如我们之前所看到的,一段代码可能不仅包含实际文本,还包含诸如用法等其他元素。

我们将这些元素称为微件,它们可以是行间微件(例如 Find Usages(查找用法)或 Run(运行)微件)、行后微件(例如出现在代码行之后的调试信息)或嵌入微件(例如变量和 lambda 的类型提示)。
微件本身只是一个标记元素,容纳微件的数据结构为区间树的变体,在某种程度上也是一种绳索结构。 在区间树中,节点容纳一个区间,权重对应于子树中区间的最大值。
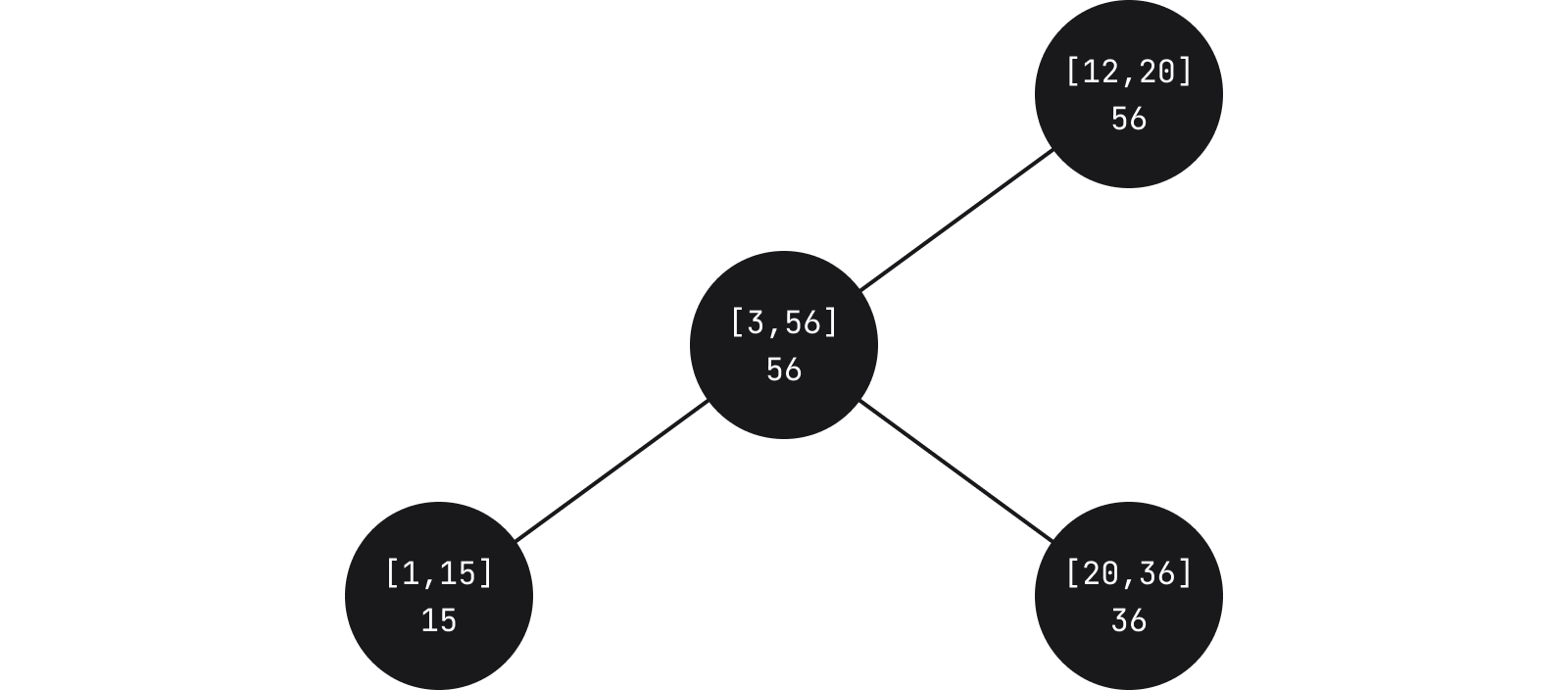
在 Fleet 中,每个节点都包含子节点的相对起点和终点。 叶节点又包含一个实际微件。 运行查询以查看是否需要根据某个特定坐标显示特定微件时,我们会遍历树,直至找到与我们所查询的区间存在交集的区间为止。
一个重要的方面是叶节点还包含微件 ID。 这意味着除了查询与特定区间的交集,对于任何微件,我们还可以查询以确定其实际位置。
Fleet 中采用了一种标准区间树的变体,我们允许节点重叠。 这有可能会导致搜索效率降低,但允许节点重叠可以创建平衡的树,并使树可以在我们输入时更新。
除了微件以外,Fleet 中的区间树还被用于跟踪文本光标、高亮显示文本以及文本中被我们称为定位标记的粘性位置。
将绳索用于词例和抽象语法树
处理源代码时,无论是编译器还是编辑器,您通常都会使用抽象语法树 (AST)。 工作方式为解析器分析源代码并创建一系列词例。 随后,这些词例将用于构建 AST。以如下代码为例
fun compileBundles(ship: JpsModule, model: JpsModel, src: SrcBundles): DstBundles
它将被分解为以下词例
[fun][ ][compileBundles][(][ship][:][ ][JpsModule][,][ ][model][:][ ][JpsModel][,][ ][src][:][ ][SrcBundles][)][:][ ][DstBundles]
其中,每组方括号都表示一个词例(请注意,空格也是词例)。 随后,这些词例将用于构建相应的 AST
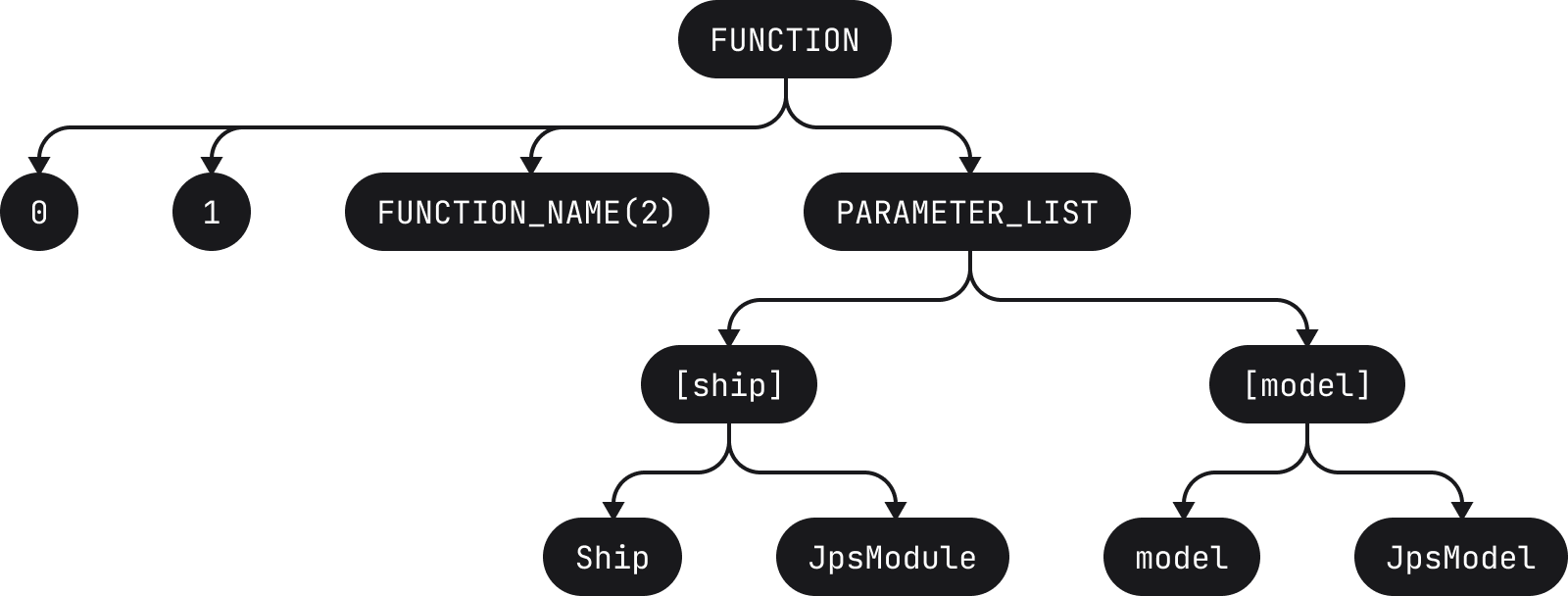
随后,AST 将被用于各种运算,例如语法高亮显示、静态分析等。 它是任何 IDE 的重要组成部分。
顺带一提,如果您有兴趣了解如何将某些代码转译成 AST,请了解一下这款超酷的在线 AST 浏览器(它提供了对多种语言的支持)
我们在编辑器中输入时,文本会发生变化,这意味着词例会发生变化,这转而需要构建新的 AST 以便提供上述功能。
在 Fleet 中,为了避免直接更新 AST,我们使用绳索结构将词例存储在叶节点中(实际上仅存储长度)。 举例来说,上文中的词例列表可以表示为以下树

当用户输入空格字符等内容时,树会更新(最左侧的叶节点的长度将增加 1,进而导致沿该路径的计数增加)
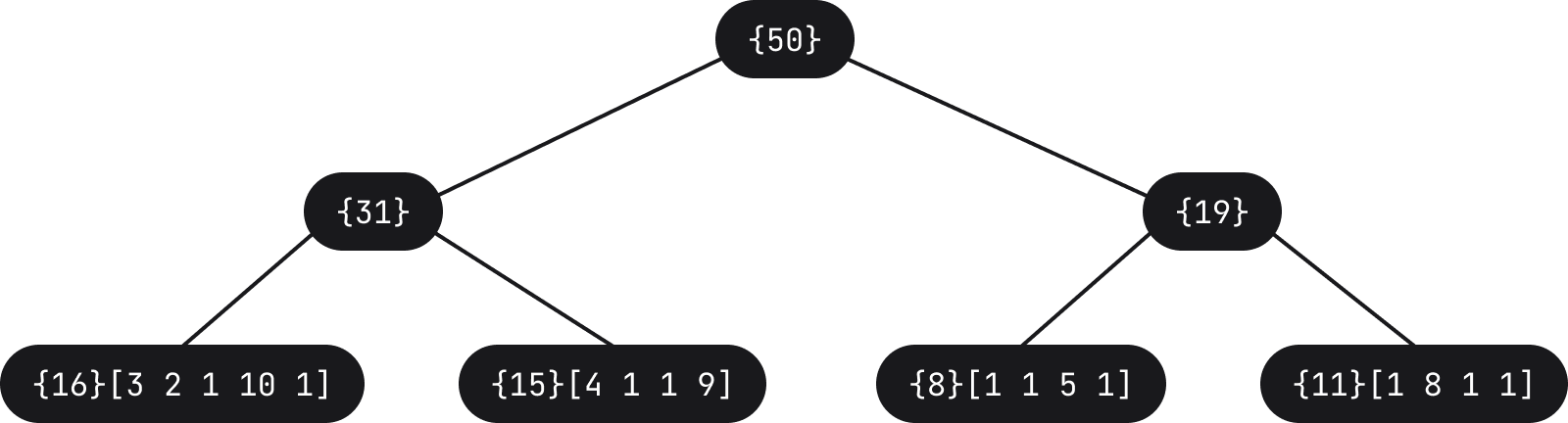
特定叶节点使新词例长度增大,转而会导致树的某些节点发生更新以调整权重。 随后,解析器会收到通知,强制它更新和重新解析 AST。 因此,AST 可能会有片刻不完全正确的情况,但在几乎不需要更新的编辑方面,用户体验要好得多。
将绳索用于渲染
下图是编辑器的另一个示例,但此次添加了一些附加元素,也就是将实际用法微件扩展为显示用法、自动换行以及诸如在滚动条中加入彩色竖线等其他元素。
要渲染上述内容,对于特定的 Y 坐标,我们不仅需要清楚显示哪行,还需要考虑到所有微件和自动换行的行。
有趣的事实:用法微件中渲染的编辑器使用与我们在本文中所探索的相同底层数据结构。 对于同一文件中的用法,构建和渲染此叠加编辑器使用了相同的绳索。
微件和自动换行信息也会存储为绳索结构。 虽然之前树的叶节点会容纳字符串及其长度,但在此例中,我们将使用叶节点来保存我们所谓的 SoftLine 对象。 这些是带有高度的文本块,被视为视觉线。 此例中节点的权重(我们称为指标)为 SoftLine 的高度和长度。 存储高度是为了能够支持视口查询。 此高度受位于它内部的中间行影响。 此外,当启用自动换行时,SoftLine 不会与实际行一一对应,而是可以跨越多行。
关于不变性的说明
值得一提的是,我们在 Fleet 中拥护不变性。 使用纯函数和不可变对象有很多好处。 纯函数不仅使我们能够更好地思考代码,而且还可确保调用函数不会在我们不知情的情况下导致系统的其他部分发生变化(即出现副作用)。 在数据方面,知道对象为不可变对象意味着它具备线程安全性,因此在尝试任何更新时不会出现竞争条件。 对于多线程环境,这提供了巨大的好处。
这种不变性理念也是使用绳索结构的运算的核心。 之前我们谈到了如何更新节点和树的叶节点。 这些都是以不可变的方式完成的 – 树上的任何运算都会产生与旧树共享结构的树的新副本,差别仅限从根到需要更改的单个节点。 鉴于树通常宽度较大而深度较小这一事实,这一路径将很短。 如果运算导致出现任何未引用的节点,将对这些节点进行垃圾回收。
这与我们在 IntelliJ 平台上使用读写锁定机制执行变更的方法截然不同。
总结
正如我们在这个关于如何构建 Fleet 的第二部分中所见,可供输入和浏览代码的编辑器看似简单,实则为十分复杂的多种不同数据结构的底层聚合,其中多为绳索结构。 如果您有兴趣详细了解绳索,请务必参阅绳索科学系列内容,它对我们在 Fleet 上所做的工作产生了重大影响。
祝您工作愉快,期待早日再次相见!
本博文英文原作者:




