

Big Data World, Part 6: PACELC

This is the sixth installment of our ongoing series on Big Data, how we see it, and how we build products for it. In this episode, we’ll cover the PACELC theorem. It is an extension of the CAP theorem, which describes trade-offs in distributed systems that exist before partition happens.
- Big Data World, Part 1: Definitions
- Big Data World, Part 2: Roles
- Big Data World, Part 3: Building Data Pipelines
- Big Data World, Part 4: Architecture
- Big Data World, Part 5: CAP Theorem
- This article
After reading Big Data World, Part 5: CAP Theorem, you might think that this theorem hardly helps in actual development. If the whole storage layer is, say, CP, the best thing you can achieve in the entire system is CP. Also, network partitioning is not something an engineer can actually change. But what if I told you that nothing is as it seems when positioning a system between C, A, and P?
PACELC theorem
The PACELC theorem is an extension of the CAP theorem, stating that if there is partitioning (P) in the network, you should choose between availability (A) and consistency (C), else (E), you should select between latency (L) and consistency (C).
Do you still remember the example with DB replication from our previous article?
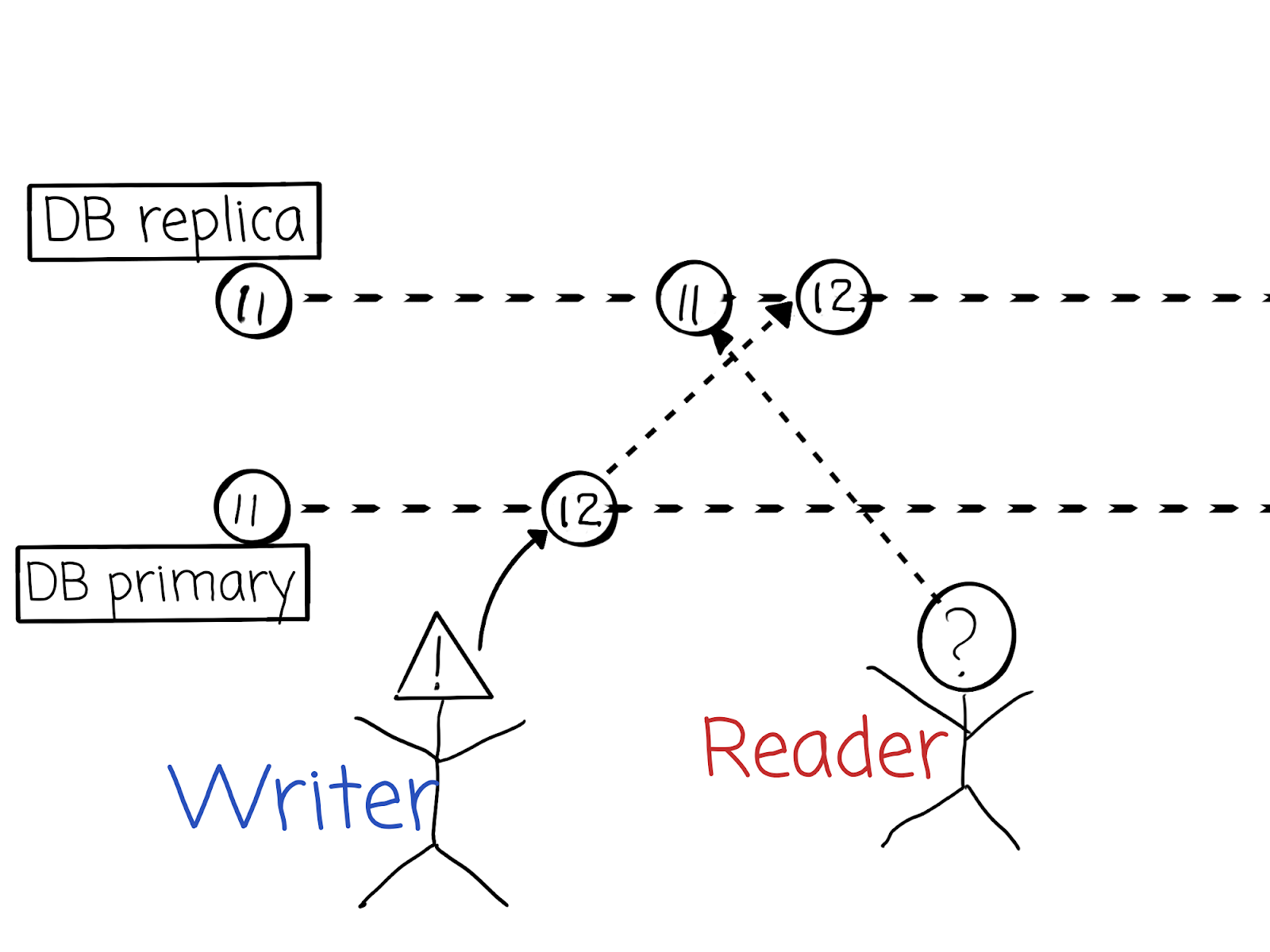
Let’s reiterate shortly: traditional relational DBs are linearizable (i.e. CAP-consistent) only if they are single-node or are being replicated synchronously. What does synchronous replication imply when there is no partitioning? It means that any commit will take more time, because every node should acknowledge this commit. We can even say that the response time depends linearly on the number of nodes to which we’re replicating synchronously. The response time could even become unacceptably high for a client if there are too many nodes. And this is the price of consistency: higher consistency requires higher latency.
Of course, dependency is not always linear. Popular consensus protocols, such as Raft and Paxos, do not require replication to all nodes for consistency to be achieved. If you’re interested in understanding how the Raft protocol works, there is a beautiful visual description in The Secret Lives of Data. Also, there is a whole family of Wikipedia articles on consensus.
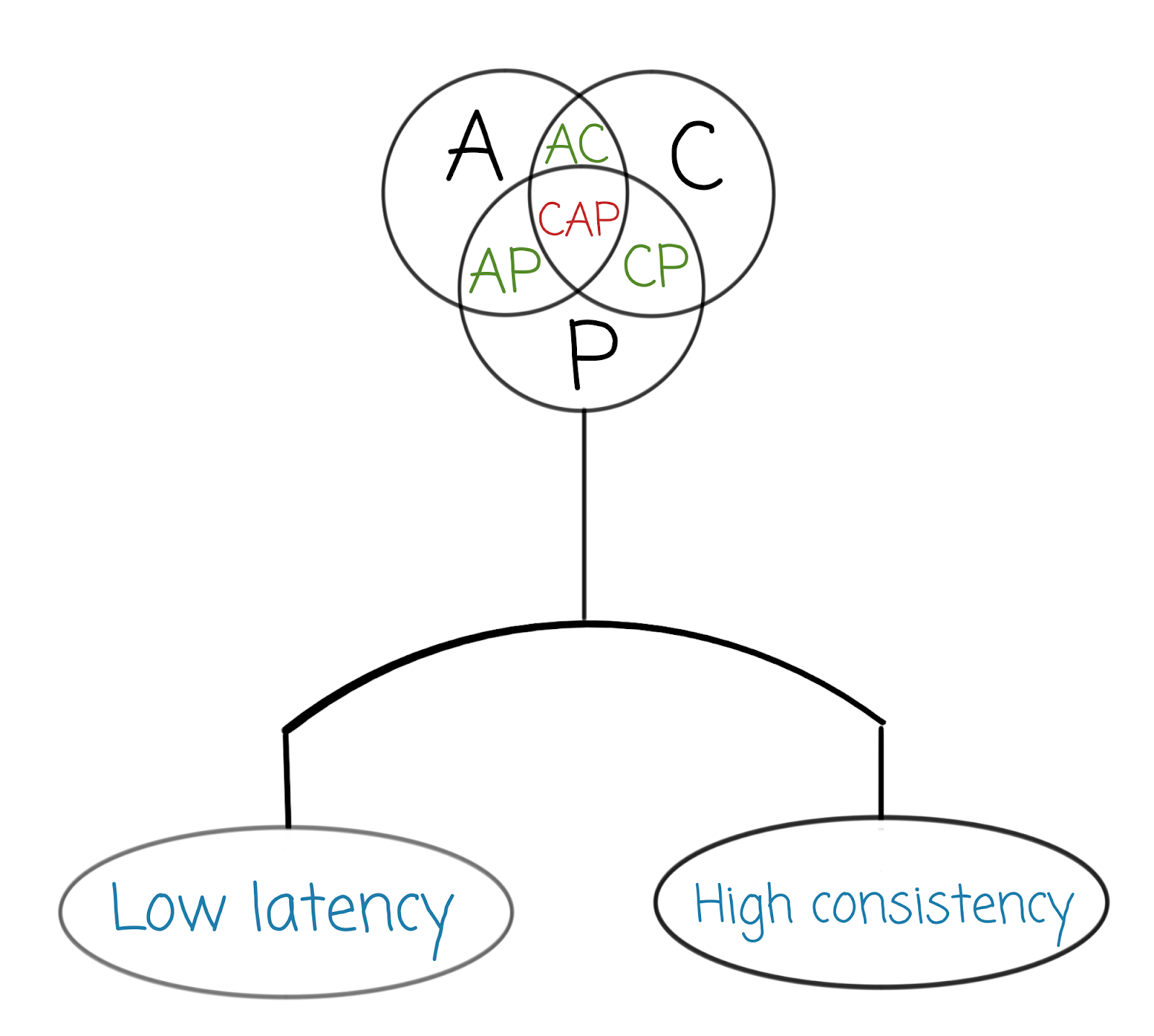
Why is it important? It looks intuitive when you think about it – there is always some trade-off between consistency and latency. But sometimes, it’s easy to forget that even a reliable and consistent system won’t respond momentarily. And the bigger our system is, the more time it will require to write data there, and the harder it is to fulfill our SLO (service level objectives).
Considering this, it’s hard to imagine the extreme difficulty in building reliable and consistent storage like Amazon S3. Remember, it not only stores objects that are more or less stable, but also stores metadata, which is volatile. This metadata should be consistent, too, or it could be a massive security breach for user data.
Conclusion
When we create the architecture for our data storage, it is essential to remember that it probably won’t be CAP-consistent, but any given layer probably will be. It is important to understand our goals and do performance tests to understand what we can guarantee to our users and how it will change when the amount of data inevitably grows.
As usual, at JetBrains we’re committed to building tools that will work with any data source, regardless of its latency. So far these include:
- DataGrip
- Big Data Tools plugin for our IDEs




