

从神经网络的角度看 Python

JetBrains Python 整行代码补全插件现已推出公测版。 我们想谈谈一些用于创建插件的技术和算法,并分享我们收集的有关 Python 编程的统计数据。
什么是“整行代码补全”?
代码补全的作用是向用户建议下一个键入的单词。 如果您对代码补全还不熟悉,可以阅读我们的系列介绍文章(一、二、三、四)。
整行代码补全通过建议更大的代码段来扩展服务。 它还可以为您填写方法调用形参或编写错误消息文本。 在用户体验方面,它类似于普通的代码补全,并使用相同的弹出窗口呈现结果:
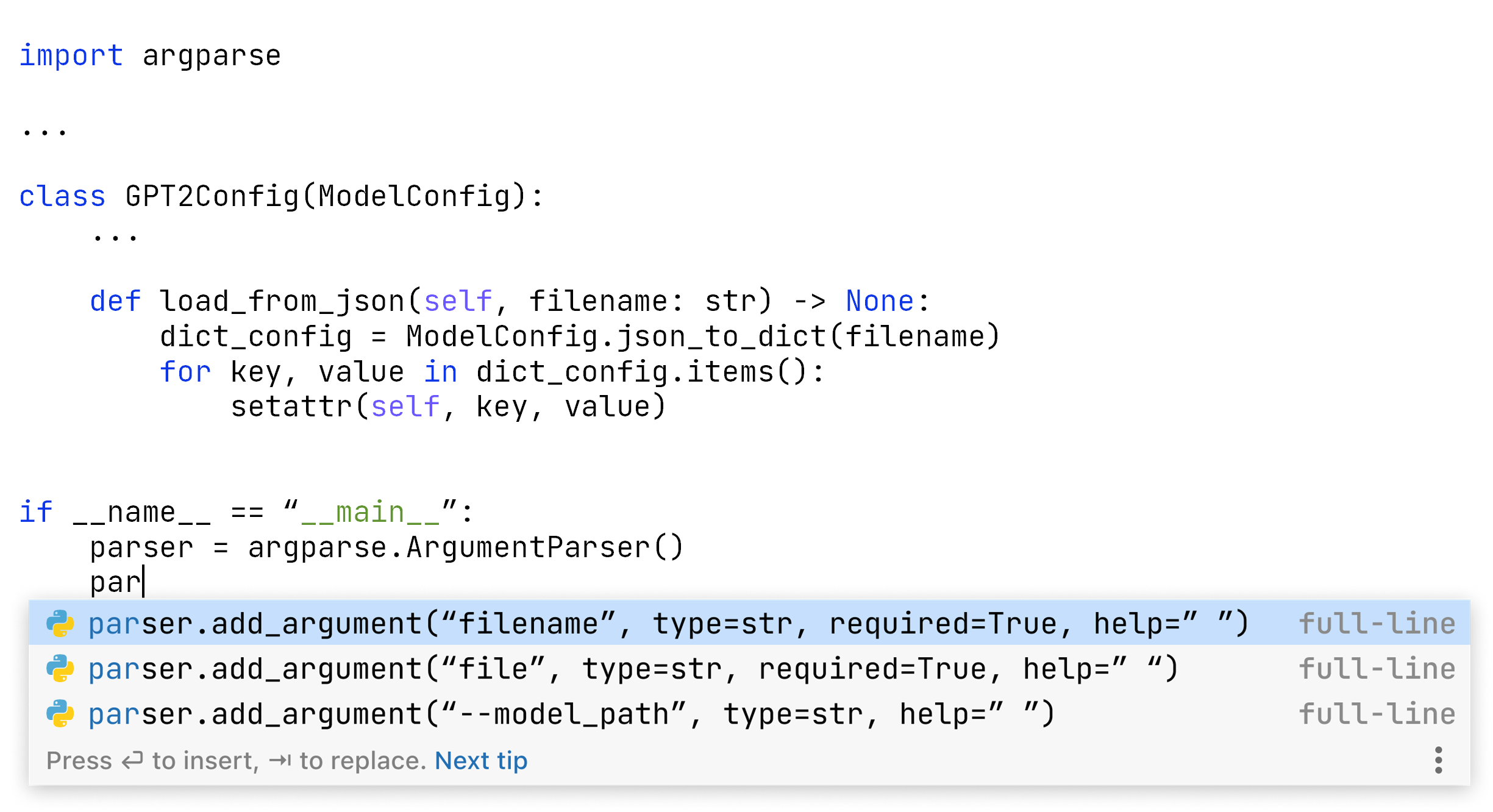
但是,这种扩展补全形式背后是截然不同的技术。
标准代码补全使用静态分析确定从当前位置可见的类、方法、字段变量和关键字,然后应用机器学习选择最佳推荐。 从预定集合中选择最佳条目是判别建模的形式。 整行补全则提供了由多个“单词”组成的新代码块。 编写代码看起来像是一个创造性的过程,并且计算量更大。 这是生成建模的形式。 神经网络是一种典型的生成建模工具,我们也在使用。
我们想带您进行一次整行代码补全引擎的幕后导览,并从几个有趣的方面展示它的工作原理。 今天的问题是:神经网络如何看待您的程序?
搭配编程语言的算法使用自然语言处理中的多种技术。 神经网络不操作原始语言的字词,而是使用来自特殊词汇表的一系列词例。 算法使用字节对编码流程构建词汇表。 我们首先来看一个简单的英语示例,然后看看它在 Python 中是如何工作的。
自然语言中的字节对编码
算法在训练阶段开始时构建词汇表,从用于训练的文本中收集统计数据。 此后,词例集不再变化,并在利用阶段的所有处理中保持固定。
想象一下,唯一可用于训练的英语是这句话:

暂且不论古老的智慧如今是否仍然适用。 重点在于这句话包含多个重复单词,这将有助于我们理解算法。 我们可以从中获得什么样的词例来供进一步使用? 我们使用训练句子中的所有单个字母(符号)初始化词例列表:
[i, f, y, o, u, a, l, w, s, d, h, t, g, e]
顺便一提,Unicode 将每一个都编码为一个字节,因此这里的符号和字节是相同的。
我们不包括空格,而是将其用作自然的词例中断。 这个细节稍后会变得很重要。
初始化后,我们迭代扩展词汇表。 我们找到两个现有条目最常见的串联,将其称为新词例。 在我们的示例中,“you”和“always”重复了四次,但我们还不能添加它们,因为它们都不是两个条目的串联。 我们需要一步一步来,第一个候选是“yo”。 新词例被定义后,它就变得不可拆分,我们不能单独使用它的各个部分。 因此,“ou”永远不会成为词例,因为这需要拆分“yo”。

我们重复这一步,找到其他频繁的词例串联并将它们添加到词汇表中。 在处理仅出现两次的其他符号对(例如“wh”和“at”)之前,算法将到达“you”和“always”。 大小为 32(2 的幂)的词汇表可能如下所示:
[i, f, y, o, u, a, l, w, s, d, h, t, g, e, yo, ys, al, ays, ways, you, always, at, wh, what, if, il, id, ot, wil, do, did, ge]
我们添加的每个词例都是其他两个词例的串联,这也因此叫做对编码。
在这里梳理一下对词例的理解,避免造成混淆。 我们将语言的词汇元素称为“单词”。 我们将通过字节对编码获得的词汇表条目称为“词例”。 有些词例可能不是单词(例如 ays)。 有些单词也可能不是词例(例如:will 和 get。 我们在添加它们之前停止了词汇表的创建)。
神经网络接受输入并根据词例而不是单词生成输出。 需要的计算资源取决于词汇表有多大。 这种方式允许我们将大小限制为任何所需的值,而不是使用所有语言单词。
输入中的词例数量对于质量和性能也很重要。 算法可以只考虑需要为其生成延续的文本片段(“上下文”)。 如果我们使用更多扩展词例,可以将更大的文本块作为输入。 幸运的是,搭配编程语言为此带来了额外的选择。
从自然语言到编程语言
自然语言处理系统的作者通常使用单词边界作为词例之间的硬边界。 “John Smith”序列在英语中比“Trantor”更频繁,特别是非虚构文本。 然而,“Trantor”理论上有机会成为极大词汇表中的一个词例,因为它是一个单词。 作为两个单词,“John Smith”没有这样的选择。 自然语言的词例通常不会跨越单词边界。
对于编程语言,我们从词法分析器中获得了词例的自然分离:单词在您可以插入空格的地方结束。 变量、常量和语言关键字是分开的。
对于编程语言,我们认为可以做得更好。 来看以下典型 Python 短语:
for i in range(
它包括许多不同的词法元素,包括两个语言关键字、一个变量和一个函数。 尽管如此,我基于自己(非常不熟练)的 Python 技能认为,for i in range(
解决方法是通过换行符而不是词法元素来限制词例。 我们的目标是实现整行代码补全,那么,显然要使用完整的行作为最大词例。
我们的词汇表大小限制是 16,384,还是 2 的幂。 我们已经使用覆盖 99.99% 文本的 Unicode 字符初始化了该过程,并开始处理具有许可许可证的 Python 仓库。
在以下部分中,您将了解 16,384 个最流行的 Python 结构。
词汇表中的错误
我们通过目视检查词汇表发现了一些系统性问题。 根据统计,还应该有一些条目,但添加它们有一些弊端。
第一个惊喜:中文
出现在字节之后的 600 多个词例主要是流行的非拉丁脚本语言(如汉字)的 Unicode 符号。 中文本身是一个惊喜,而字符的含义看起来是合理的。
例如,出现次数最多的是 的。 这个汉字最主要的用途相当于英语所有格的“s”。 据统计,这是最常见的汉字。 有些汉字在我们的数据集中非常流行,但在语言本身中不太常见。 例如,数 和 码,以及 网 。 在编程领域,这显然说得通。 我们只需要弄清楚为什么这些汉字会出现在我们的词汇表中。
非拉丁字符,包括中文、俄语、日语、韩语,有时还有阿拉伯语,来自 Python 文档字符串。 事实证明(没想到吧!),人们经常用母语编写文档。
将非拉丁字符纳入词汇表可能弊大于利,因为它们占据的空间更适合用于更流行的编程语言结构。 通过这些字符,我们可以更好地支持 Python 中允许的 Unicode 变量名。 然而,为了避免代码混淆,人们很少使用它们。
第二个惊喜:缩进
如果我们对行首流行关键字的词汇表进行 grep,例如 return,会出现另一个麻烦:
return return return return return
(以及许多匹配项)
有价值的 return 语句片段也出现在各种前导缩进中,因此我们在词汇表中获得了以下词例的多个副本:
return self.return Truereturn Falsereturn 0return None
保留这些副本似乎不切实际。 当我们调用补全时,文本光标很少出现在行首。 IDE 会跟踪缩进,当用户开始键入 return 时,可能就已经处在正确的位置。 因此,带有前导空格的 return 语句被使用的几率可以忽略不计。
另一方面,它也节省了上下文的长度。 每个缩进的 return 都将只是一个词例而不是多个。
Import
另一个让我们停下来思考的问题是涉及流行框架(例如 TensorFlow、PyTorch 和 Django)的 import 语句,例如:
from tensorflow.python.framework import opsfrom django.conf import settings
此类 import 通常在每个文件中(一般接近开头)出现一次。 此外,常规代码补全和自动导入机制都已经相当出色。 另一方面,通过它可以在生成补全建议时考虑更大的代码块。 对于是否需要这些长 import 作为词例,这仍然是一个值得探讨的问题。
深入研究数据
也许本部分的关键要点是对数据进行目视检查的重要性。 在统计数据处理和机器学习驱动算法的中间结果中,可能存在测试未能覆盖但对人类专家来说显而易见的系统性问题。
统计 + 启发法通常比单统计要好得多。
流行符号对
终于到了二符号组合。 调查它们为什么能登上榜首很有趣。 一些来自最常见的语言关键字,而另一些则是命名惯例和编程习惯的产物。
您能猜出 Python 中最常见的二符号组合吗(当然双空格除外)? 是逗号 + 空格,比如:,
seself.self.infor i in range(rereturn。onte= =oror、for 和 import。
复杂符号组合
跨边界词例
s[ 和 s.append( 这两个非常流行的词例完美描述了在 Python 中的列表操作。 我们通常用复数形式的名词来命名列表:days、goods、items、lines。 这些词例展示了统计的力量和美感:它们跨越了 Python 词法元素的边界,展现了我们在代码中说英语的方式。
范围
for i in range(
此外,还有一个更长的流行语句:
for i in range(len(
顺便一提,i 是唯一一个同样流行的名称。 j 和 k 等并没有位居前列。
Return 语句
程序员使用什么作为函数的结果? 以下频率并不奇怪:
return Falsereturn Truereturn None
它们彼此非常接近,但都在 return self.return 0
return []return super(return datareturn valuereturn notreturn len(self.
最后一个词例通过组合 return len(self.return len( 不在词汇表中。
类
有没有与单词类的组合能够跻身前 16384? 这里突出的领先者是 class Test
class Meta:class Base
包含 class 的其他有意义的词例不处理类名:
classifierclassificationissubclass(@classmethodBase class for
最后两个来自文档。
总结
神经网络使用词汇表来表示输入程序并构建建议。 代码生成算法是未来文章的主题,程序表示现在已经可用。
如果我们取一段简单的 Python 代码段并运行分词器,我们可以看到它与神经网络一样:

分词器将这 3 行转换为 15 个词例。 基于 GPT-2 的模型最多可容纳 1,024 个条目;我们的使用限制为 384。 在我们的训练集中,单行的中值长度是 10 个词例,比上面的示例要长一些。 我们可以估计,模型使用略低于 40 行的上下文来生成预测。
这个示例还展示了不同神经网络的“思维”与人类相比有何不同。 我们知道第一行和第二行中的 args 代表相同的东西。 但是,算法把它们看作了不同的东西,甚至拆分了第二个。 这符合设计!
尝试 Python 整行代码补全插件
浏览词例词汇表非常有趣,但开发词汇表只是朝着更高产品目标迈出的一小步。 我们计划讲述更多技术故事,介绍神经网络如何生成代码以及我们如何针对用户笔记本电脑规格调整其性能。
同时,我们希望您能试一试我们的 Python 整行代码补全插件:
https://plugins.jetbrains.com/plugin/14823-full-line-code-completion
本博文英文原作者:

