

Big Data World, Part 3: Building Data Pipelines

This is the third part of our ongoing series on Big Data, how we see it, and how we build products for it. In this installment, we’ll cover the first responsibility of the data engineer: building pipelines.
Related posts:
- Big Data World: Part 1. Definitions.
- Big Data World: Part 2. Roles.
- This article
- Big Data World: Part 4. Architecture
- Big Data World, Part 5: CAP Theorem
Table of contents:
As we discussed in the previous part, data engineers are responsible for transferring data and for the architecture of DWH, among other things. This sounds quite simple. But in reality, the best way to accomplish these tasks is not always obvious.
What a pipeline is
To a certain extent, everything in development may be represented as a data pipeline. In backend development, it may look like this:

This looks like ETL (Extract, Transform, Load), right? We’re not extracting anything, but the meaning is the same!
And our usual CI pipelines (simplified) look like this:

And considered in this way, a CI server is an ETL tool too, of course.
But in data engineering, things become lots more complex. There are lots of sources, lots of sinks (places where we put our data), lots of complex transformations, and lots of data. Just imagine having dozens of operational databases, a clickstream from your site coming through Kafka, hundreds of reports, OLAP cubes, and A/B experiments. Imagine, as well, having to store all the data in several ways, starting with raw data and ending with a layer of aggregated, cleaned, verified data suitable for building reports.
You can already hear the sound of the data engineer’s baton knocking as they prepare to conduct this orchestra. Indeed, all these processes need to be orchestrated by data engineers, and just as an orchestra is composed of a variety of instrumentalists – the process of transferring data requires distinct pipelines.
There actually are two levels of pipelines: in orchestrators and in ETL tools.
Orchestrators
These pipelines are being united into entities, called DAGs (directed acyclic graphs). DAGs can look like the one below, but they can also be much more complex:
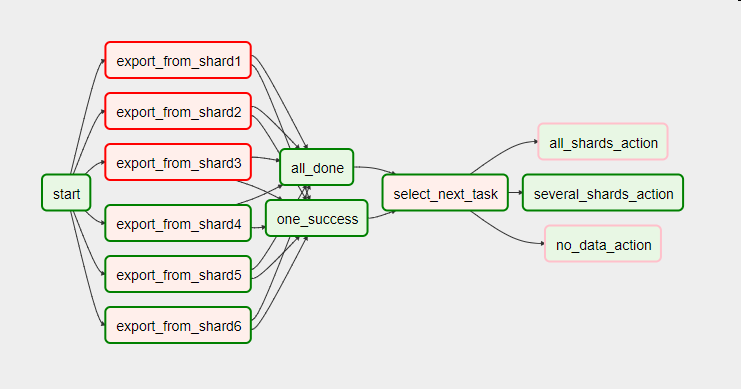
This is why one of the main instruments in a data engineer’s toolbox is an orchestrator – it makes building complex pipelines relatively simple.
The most popular orchestrators are Apache Airflow, Luigi, Apache NiFi, and Azkaban. They all do basically the same thing: they launch tools in the required order, performing retries if something goes wrong.
Now let’s consider the lower level of pipeline-building
ETL Tools
As we’ve mentioned, orchestrators usually just call other tools – typically tools for building more localized ETL pipelines. ETL tools are particularly interesting because they often operate with DAGs, as well.
For example, Apache Spark is one of the most popular ETL tools (despite it being a general-purpose distributed computations engine). One of the popular usage patterns is to move data from one place to another (from sources to sinks), transforming this data on the way, and this work may also be represented as a DAG:
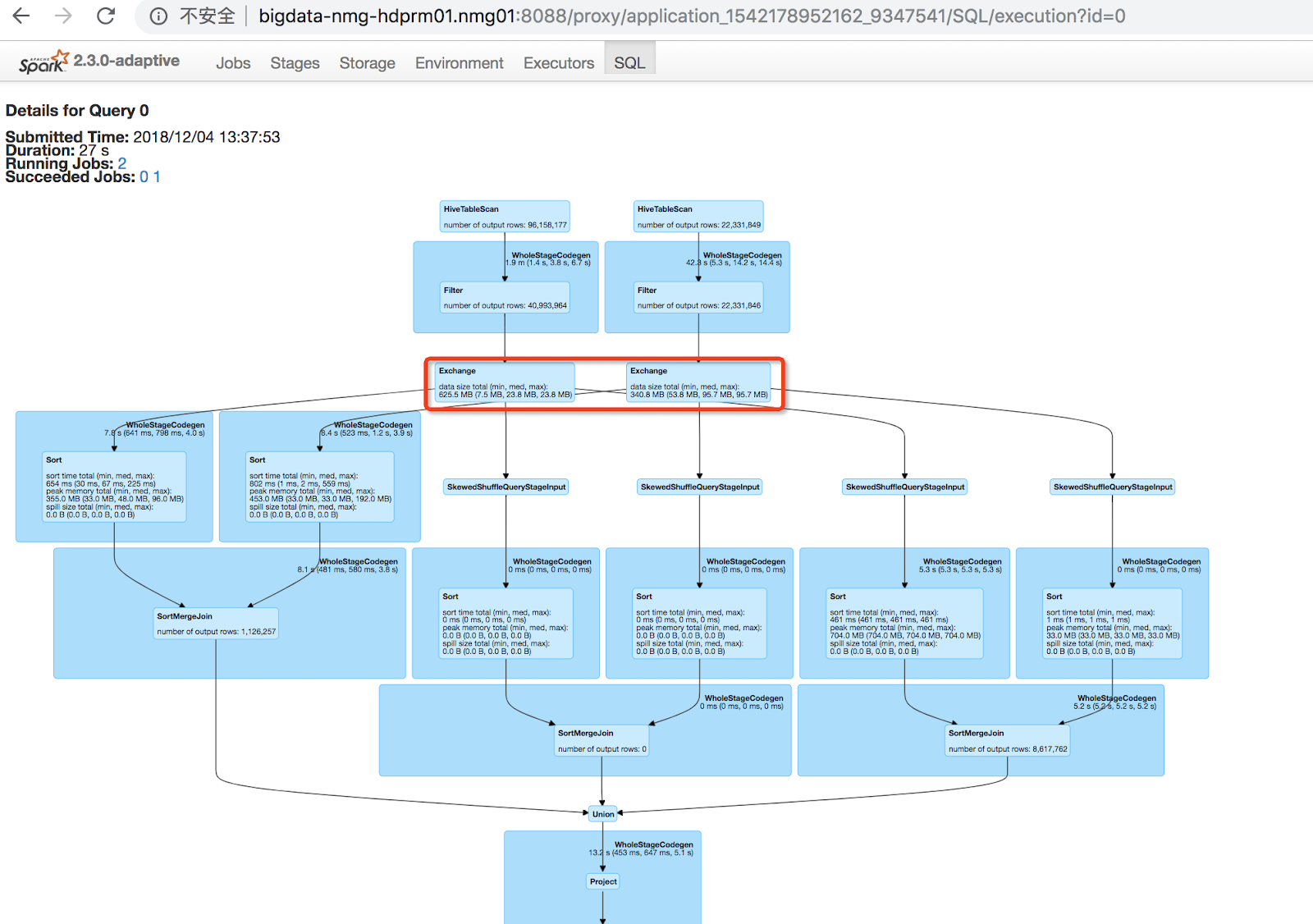
Here we can see that there are 2 inputs, 1 output, and multiple intermediate processing stages, including operations we are all familiar with, like “join”. Also, on this graph, we can see how data flows through nodes, along with the amount of data processed and the time each node takes.
These DAGs can be very complex, and they are usually more complex than the ones orchestrators operate on. So, in some sense, data engineers orchestrate orchestrators working with pipelines of pipelines.
Batch vs stream processing
Generally speaking, ETL tools may work in 1 of 2 ways: either batch or stream processing.
With batch processing, a task is run one time, gets some data, processes it, and then shuts down. With stream processing the process is run continually, obtaining data as soon as it appears in the source.
Presented in this way, it may seem like stream processing should always be used with streaming sources, like Kafka. Surprisingly, this is not necessarily the case. One popular exception to this rule is relational databases. There are 2 ways to extract data from them. The first, more popular, and obvious way is to read all the required data from the database in one batch. But it is also possible to stream changes from the database using special tools, for example, Debezium.
Apache NiFi
You may be getting the impression that there are two distinct worlds: the world of orchestrators and the world of ETL tools. And then there is the distinction between stream and batch processing, as well. But in reality, there is actually an outlier. Apache NiFi is an orchestrator and ETL tool at the same time. It can also work in both batch and streaming modes (with some limitations, of course).
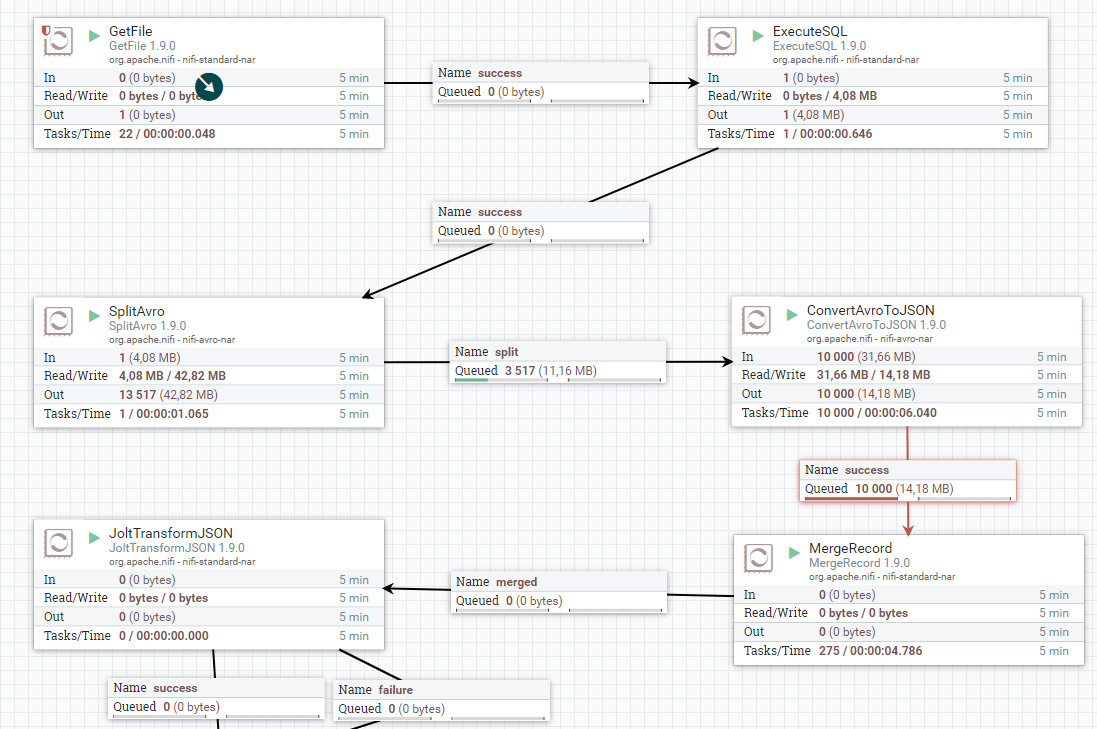
Apache NiFi was created by the NSA in 2006 (and was initially named NiagaraFiles), and it was designed with the goal of making it possible for non-programmers to write data pipelines. In 2014 it was transferred to Apache Software Foundation as a part of the NSA’s technology transfer program.
But the goal remains the same: allow users who are not particularly technical to create complex data pipelines. And it really works. Of course, a system like this has its own limitations, and users may need to implement things that aren’t supported by NiFi out of the box. That’s fine, Apache NiFi is built in an extensible way, so developers can implement the modules that a customer needs, and these modules can be reused everywhere.
Conclusion
Building pipelines is a complex task that is both analytical and technical. However, it is the only way to give our customers (internal and external) access to the data they need in the form they prefer.
Pipelines are generally built with the help of orchestrators, which call other ETL tools, but sometimes the whole pipeline may be built with a single tool like Apache NiFi.
If you’re interested in our tools for building pipelines, you may want to check out the Big Data Tools plugin, which is currently integrated with multiple storage providers and also with Apache Spark.
Subscribe to JetBrains Blog updates





