.NET Tools
Essential productivity kit for .NET and game developers
Dependency injection doesn’t strictly require frameworks – Code smells series

This post is part of a 10-week series by Dino Esposito (@despos) around a common theme: code smells and code structure.
Last week, we looked at using constructors vs. factory methods, and how sometimes factories can help make our code more readable. In this post, let’s look at the concept of dependency injection to help make services available in our code, as well as make it more extensible.
In this series:
- Sharpen your sense of (code) smell
- The simple case of special string types
- Join data items that want to go together
- Easy conversions and readability
- Put it down in layman’s terms
- Every method begins with “new”
- Dependency injection doesn’t strictly require frameworks
- Super SuperClasses
- Null pointers: an opportunity, not an exception
- You ain’t gonna use it!
Dependency injection
Dependency Injection (DI) is a widely used development pattern that serves the primary purpose of making services available to application code. Whenever a class needs the services of some external code (e.g., an instance of another class), you have two options. You can create a fresh new instance of the desired class directly in the calling code, or you can assume that someone will be passing you a valid instance of the service you need.
In other words, the contract between the class you’re writing and whoever happens to use it is such that users need to provide the class with the tools it needs to work – injecting its dependencies.
For many years, few people paid enough attention to writing loosely coupled code. Loosely coupled code is code that does not work in a standalone context or in a disconnected software island. Instead, loosely coupled code is simply code where connections exist, but are strictly ruled and occur under the umbrella of clear contracts. Here’s a canonical example:
public class BusinessTask
{
public void Perform()
{
// Perform task
PerformTaskInternal();
// Get the reference to the logger
var logger = new Logger();
// Use the (located) dependency
logger.Log("Done");
}
private void PerformTaskInternal()
{
}
}
public class Logger
{
public void Log(string message)
{
var writer = new DefaultWriter();
writer.Write(message);
}
}
public class DefaultWriter
{
private readonly TextWriter _writer = new StringWriter();
public void Write(string message)
{
_writer.Write(message);
}
}
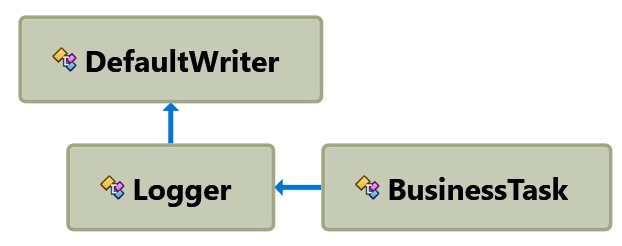
The class BusinessTask makes internal use of a Logger class which, in turn, requires an instance of the TextWriter class. All necessary instances are created in place, right where they are needed. The code works beautifully!
But if you need to grow it bigger (e.g. scale it up or out in some way), at some point it becomes problematic. It also becomes problematic to test it appropriately. The issue is that dependencies are not encapsulated and well treated. If you ask ReSharper to draw the diagram of dependencies (from the ReSharper | Inspect menu), you get the following:
There are two main patterns to address the issue. One is Service Locator and the other one is Dependency Injection. The Service Locator pattern works nicely with legacy code that you’re just trying to update to the next level. A service locator is a sort of centralized “instantiation-as-a-service” platform. A very common programming interface is like this:
var obj = ServiceLocator.GetInstance(typeof(ISomeType));
Internally, the service locator implementation will figure out whatever is necessary to create a valid instance of the specified type. To refactor your code to Service Locator, you just need to analyze known dependencies and abstract them out to a locator.
Even in small code bases, the help of an inspecting tool is crucial to doing a good job in a reasonable time. A tool like ReSharper will make it a breeze to find occurrences of types.
Dependency Injection (DI) is a different pattern that serves the same purpose. Compared to Service Locator, DI is more intrusive, as it requires changes to the public interface of involved classes. For this reason, the rule of thumb is going with Service Locator if working on legacy code, and using DI for new code or code that can be significantly refactored and undergo radical changes.
The key to DI is to rely on interfaces rather than on specific implementations. To do that, you can extract an interface from all dependencies in our example: Logger and DefaultWriter. Again, it’s a quick task for a tool like ReSharper. We can use the context menu (Refactor | Extract | Extract Interface) or use the Refactor This action (Ctrl+Shift+R).
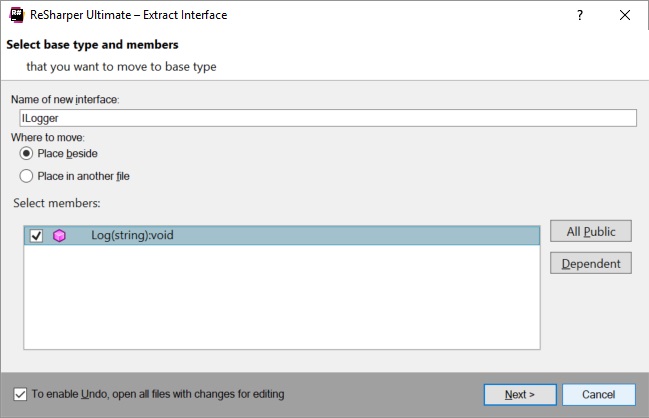
When you complete the wizard, you will have a Logger class that implements an ILogger interface.
public interface ILogger
{
void Log(string message);
}
The next step is making BusinessTask depend on ILogger, rather than a specific implementation type such as Logger.
Programming BusinessTask to an interface rather than an implementation makes the class inherently more flexible from a customization and testability perspective. Ideally, with a DI approach you could refactor BusinessTask as:
public class BusinessTask
{
private readonly ILogger _logger;
public BusinessTask(ILogger logger)
{
_logger = logger;
}
public void Perform()
{
// Perform task
PerformTaskInternal();
// Use the (located) dependency
_logger.Log("Done");
}
private void PerformTaskInternal()
{
}
}
An ILogger instance is now required to instantiate a BusinessTask object, and obtaining an instance of the logger object is no longer a problem of the BusinessTask. Any necessary code is moved outside the class.
To complete the exercise, you should perform the same steps on the DefaultWriter class and inject a dependency in the Logger class.
See the point? At the end of your work, in order to create an instance of BusinessTask, you first need to create an ILogger; and in order to create an ILogger, you need an IDefaultWriter. It may soon become a (long) chain. An Inversion-of-Control (IoC) framework just saves you from the burden of having to deal with all those instantiations manually.
However, for relatively flat dependency diagrams, you can opt for “poor man’s DI”:
public class BusinessTask
{
private readonly ILogger _logger;
public BusinessTask() : this(new Logger())
{
}
public BusinessTask(ILogger logger)
{
_logger = logger;
}
public void Perform()
{
// Perform task
PerformTaskInternal();
// Use the (located) dependency
_logger.Log("Done");
}
private void PerformTaskInternal()
{
}
}
Poor man’s DI consists in the definition of an additional constructor that accepts the type(s) to inject. The default constructor calls into this additional constructor providing an instance of a concrete type. The basic function of DI is fulfilled, but more advanced functions of an IoC are clearly missing.
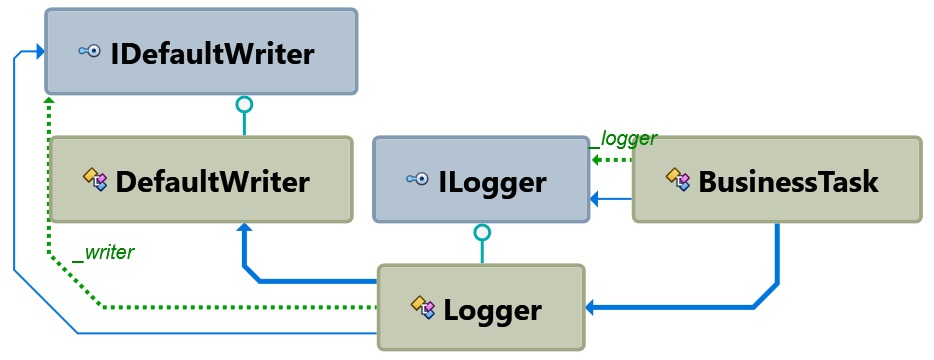
Refactored in this way, your code is inherently more extensible and, on a larger scale, easier to deploy.
Next week, we will look more closely at inheritance and composition.
Download ReSharper 2018.1.2 or Rider 2018.1.2 and give them a try. They can help spot and fix common code smells! Check out our code analysis series for more tips and tricks on automatic code inspection with ReSharper and Rider.